資料的存盤
- 🌹前言
- ?資料型別匯總
- 🎁整型家族
- 🙈浮點型家族
- 🦝自定義型別
- 🐱?🏍指標型別,
- 🐥空型別
- 🕸大小端位元組序說明
- 🧠出現大小端位元組序的原因
- 🐉位元組序的概念
- ?大小端位元組序
- 👩?🍳百度系統工程師筆試題(通過編程判斷該編譯器為大端存盤還是小端存盤)
- 🧣問題分析
- 🎒代碼演示
- 🎮代碼分析
- 🧶整型資料在記憶體中的存盤
- 💣原碼、反碼、補碼
- 🔨截斷與整型提升
- 🎉整型資料存盤練習
- 🏆浮點型資料在記憶體中的存盤
- 🎨證明整數和浮點數的存取方式不同
- 🍦IEEE標準形式
- 🍚IEEE存盤標準規定
- 🥛IEEE讀取標準規定
- 🍃總結
🌹前言
我們在敲代碼的時候總是會定義各種變數,對各種資料進行存盤,比如int a = 10;就是將10這個資料存放進變數a中,而變數a,就是我們在記憶體中申請開辟的一塊空間,
在記憶體中如何開辟空間給變數的問題博主已經在函式堆疊幀里用反匯編的方式將其原理剖析了,具體可看圖解函式堆疊幀 - 函式堆疊幀的創建及銷毀,
本文將進一步剖析在已經開辟好存盤單元的情況下,各種資料是如何存盤的,
在了解資料如何存盤之前,應該先了解我們常見的資料型別,
?資料型別匯總
在C99標準中,我們可將資料型別劃分為以下幾大類,
- 整型家族
- 浮點型家族(實型家族)
- 自定義型別(構造型別)
- 指標型別
- 空型別
下面一一介紹這五種型別的基本情況,
🎁整型家族
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
注:在C99之后的標準規定,將char型別資料劃分為整型家族,因為字符在記憶體中會將其轉化為ASCII碼值進行存盤,
如上所示,所有的整型家族都被分為有符號整型和無符號整型,并且signed都是可以被省略的,換言之,signed int完全等價于int,其他以此類推,但其中有一個例外: char型別和signed char并不等價,只寫一個char ch = 0;我們將無法分辨這個ch變數到底是有符號字符型還是無符號字符型,他完全取決于編譯器,但經博主測驗,大部分編譯器下char型別都被編譯器翻譯為有符號的char型別,
在C99中還引入了long long - 長長整型,用法和long型別一致,但C語言語法規定,sizeof(long)<= sizeof(long long),而long型別所占記憶體大小為4/8位元組,所以long long型別所占記憶體空間大小一定為8個位元組,
🙈浮點型家族
float
double
浮點型家族只有float和double這兩種型別,float型別所占空間大小為4byte,double型別所占空間大小為8byte,
他們之間的區別除了所占空間大小不同之外還有精度的區別,float稱為單精度浮點型,有效精度為小數點后6位,而double型別稱為雙精度浮點型,精確到小數點后15位,但其有效數字只有11位左右,
🦝自定義型別
> 陣列型別
> 結構體型別 struct
> 列舉型別 enum
> 聯合型別 union
這里可能會有很多人無法李姐為什么陣列型別也被劃分為自定義型別,這里稍微做一些解釋,
我們知道陣列型別的變數定義形式:資料型別+陣列名+[陣列大小];
如:
int arr[10] = { 0 };
這里可能會讓很多人產生誤區,認為arr陣列的型別是int型別,也就把這條陳述句理解為是int型別的、陣列名為arr的陣列大小為10的陣列,其實不然,這個陣列的陣列名確實是arr,但其資料型別是int [10],這里可能讓大部分人無法接受,
舉個簡單的例子即可解釋:
我們知道,sizeof運算子是用來計算所占記憶體空間大小的,其運算元既可以是變數名,也可以是變數型別,
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
int main()
{
int a = 10;
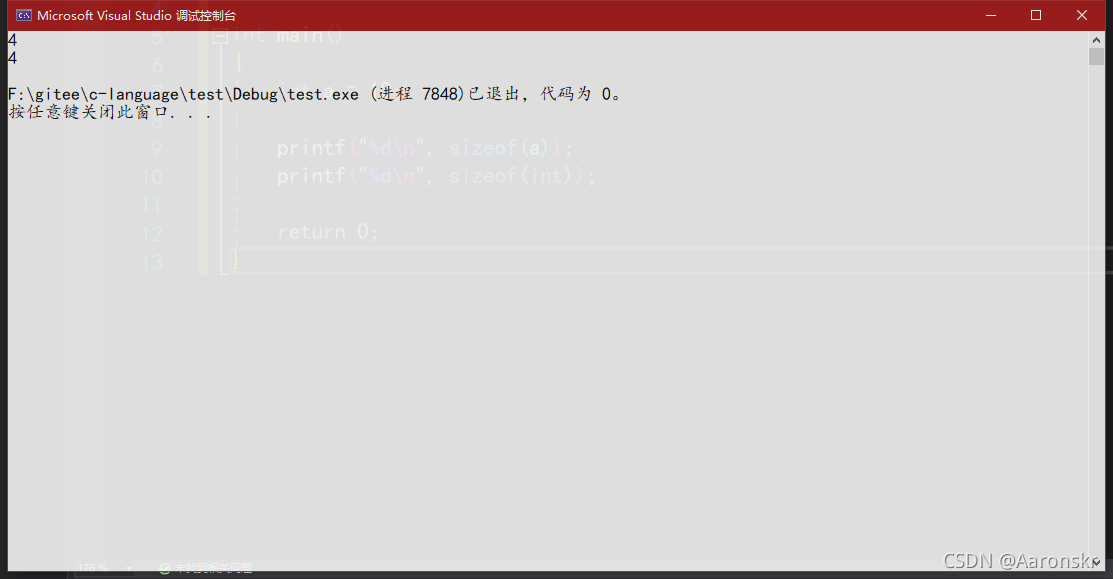
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(int));
return 0;
}
這兩種寫法都正確,列印結果為:
而對于陣列,運算元也同樣可以是陣列名或者陣列型別:
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
int main()
{
/*int a = 10;
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(int));*/
int arr[10] = { 0 };
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(int[10]));
return 0;
}
其列印結果為:
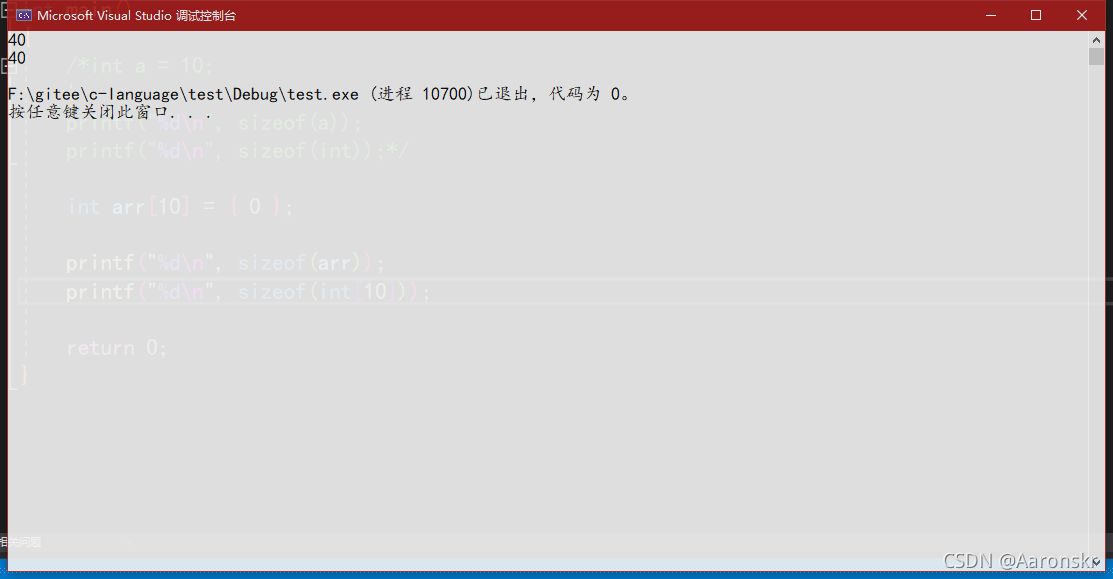
這么一來,就驗證了int [10]是陣列型別,
知道了這點,解釋為什么陣列型別是自定義型別就更清晰了,用上面解釋的結論就可以知道,int arr[10]和int arr[9]的陣列型別不同,并不都是int型別的,陣列大小是我們程式員人為規定的,所以可以把他劃分為自定義型別,
其他的自定義型別比較明顯,這里就不一一解釋,
🐱?🏍指標型別,
指標型別很特殊,
我們常說的指標有兩個含義:
- 某一個變數的地址,也就是其在記憶體中的編號,我們可稱其為指標,
- 用于存放地址(編號)的變數,我們稱其為指標變數,常簡稱指標,
指標型別的定義方式為:
資料型別+*(用于標識指標型別)+指標變數名
常見的指標型別有:
int* pi;
char* pc;
float* pf;
void* pv;
這里著重介紹一點,指標變數賦值大部分都是取出某變數地址存放進指標變數,如int pc = &c;
但有一個例外:
int main()
{
char* pc = "hello world";
printf("%c\n", *pc);
return 0;
}
這里之間將一個字串常量賦值給指標變數pc,我們知道,字串常量時放在常量區的,他的值不可修改,并且這里的字串加上隱藏的’\0’總共是12個位元組,而我們的指標變數根據平臺的不同只能是4/8個位元組,怎么都不可能放的下這個字串常量,所以這么理解是錯誤的,
我們將其列印看看結果:
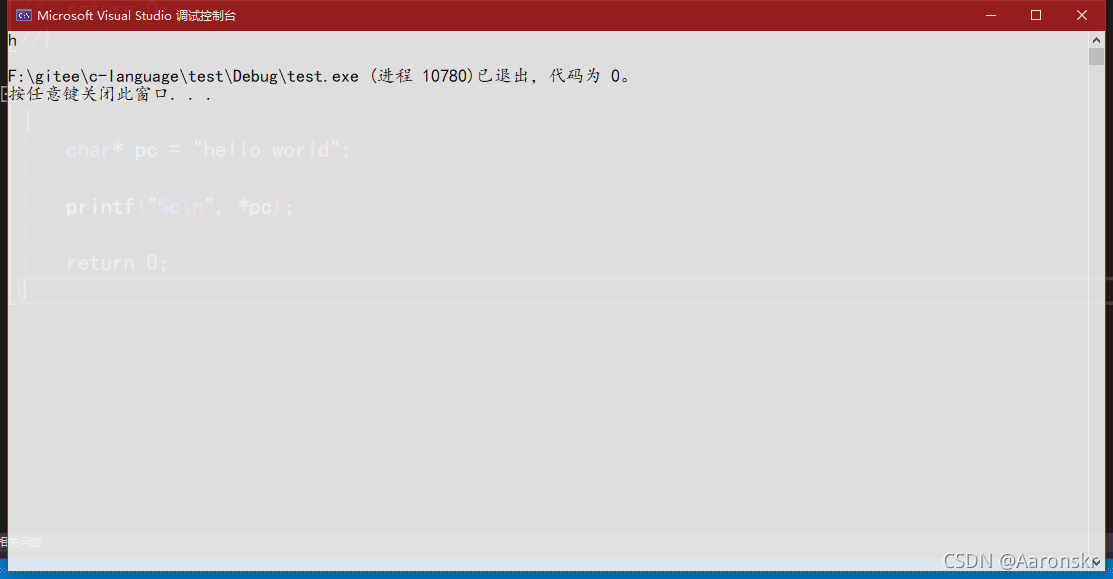
列印結果為單字母h,這么一來其實就解釋的通了,將整個常量字串賦值給指標變數,其實并不會把整個字串放進去,而是把整個字串的首地址賦給指標變數,比較指標存放的就是地址,這和將字符陣列名賦值給指標變數類似,存放的都是首元素地址,
🐥空型別
void 用于表示空型別(無型別)
通常應用于函式的回傳型別、函式的引數、指標型別,
下面舉幾空型別的例子幫助理解:
- 回傳型別:
void test(int x)
{
printf("%d\n", x);
}
int main()
{
int a = 10;
test(a);
return 0;
}
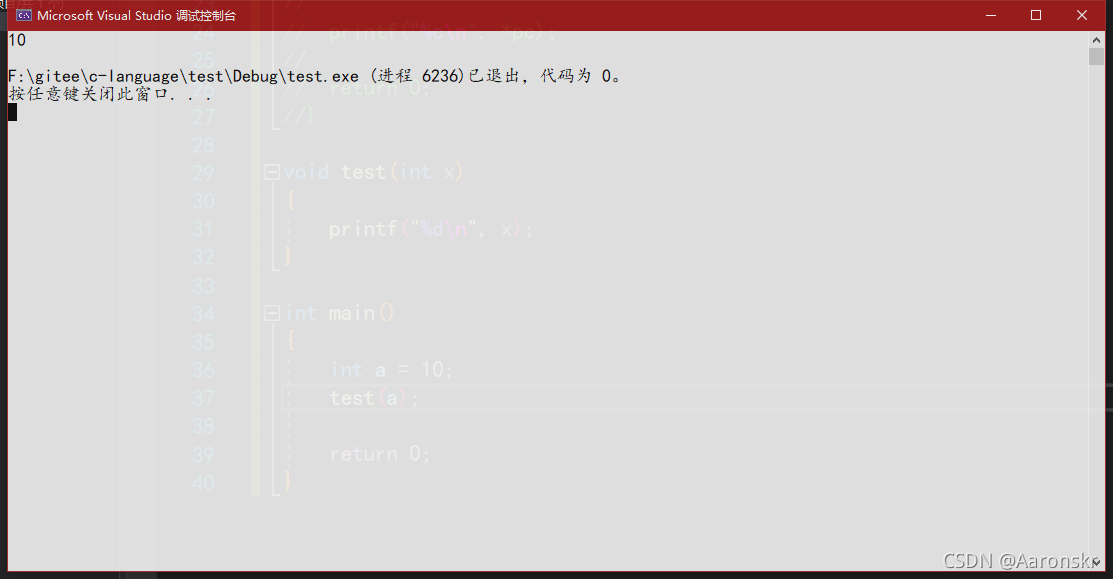
這里test函式的回傳型別就是void,
- 函式的引數:
int test(void)
{
return 1;
}
int main()
{
int ret = test();
printf("%d\n", ret);
return 0;
}
這個代碼就是將函式的引數置為空,表示不允許主調函式傳參,如果非要傳參,編譯器將給出警告,
int test(void)
{
return 1;
}
int main()
{
int a = 10;
int ret = test(a);
printf("%d\n", ret);
return 0;
}
- 指標型別:
void* pc;
表示定義一個指標pc,但他什么都不指向,作為一個空指標存在,
🕸大小端位元組序說明
我們知道不管是什么樣的資料,最終都會被編譯器編譯為二進制機器碼進行存盤,并且我們的記憶體是以位元組為最小存盤單元劃分而進行存盤的,那么就存在了一個問題,資料以位元組為單位進行存盤的時候,是以怎樣的順序進行存盤的呢?這就引出了大小端位元組序的概念,
🧠出現大小端位元組序的原因
為什么會有大小端位元組序模式之分呢?這是因為在計算機系統中,我們是以位元組為單位的,每個地址單元都對應著一個位元組,一個位元組為8bit位,但是在C語言中除了8bit的char型別之外,還有16bit的short型別,32bit的long型別(要看具體的編譯器,64位平臺long型別為64位),另外,對于位數大于8位的處理器,例如16位或者32位的處理器,由于暫存器的寬度大于一個位元組,那么必然存在著一個如何將多個位元組安排的問題,因此就導致了大端存盤模式和小端存盤模式,
例如:一個16bit位的short型別變數x ,在記憶體中的地址為0x0010,變數x 的值為0x1122 ,那么0x11為高位元組,0x22為低位元組,對于大端模式,就將 0x11放在低地址中,即0x0010中,0x22 放在高地址中,即0x0011中,小端模式,剛好相反,我們常用的X86(32位平臺)結構是小端模式,而KEILC51則為大端模式,很多的ARM,DSP都為小端模式,有些ARM處理器還可以由硬體來選擇是大端模式還是小端模式,
🐉位元組序的概念
位元組序,即位元組順序,又稱端序或尾序,在計算機科學領域中,指「存盤器」中或者「數字通信鏈路」中,組成多位元組的位元組排列順序 ,在幾乎所有的機器上,多位元組物件都被存盤為連續的位元組序列 ,例如在C語言中,一個 int型別的變數x地址為0x100,那么其對應的地址運算式&x的值為0x100 且 x 的4個位元組將被存盤在存盤器的0x100, 0x101, 0x102, 0x103位置,位元組的排列方式有2個通用規則,
- 順序排列 - 大端位元組序
- 逆序排列 - 小端位元組序
上面的文字描述也許過于抽象,接下來用較為容易理解的方式分別簡單的介紹大端位元組序和小端位元組序的概念,
?大小端位元組序
所謂大小端位元組序,就是將多位元組資料中的高低位元組位按不同順序存放在記憶體中的高低地址處,相當于順(逆)序存放,接下來博主將把上述抽象概念劃分逐一介紹:
- 首先理解什么叫做多位元組資料,
我們知道一個資料根據大小不同被劃分為不同的資料型別,各資料型別所占位元組數不同,我們也就據此根據資料位元組大小來將其存放于不同的資料型別中,
比如字符型別 - 其擴展之后的ASCII碼值為0~255,我們知道一個位元組是8位,按照無符號字符型的理解也就是從00000000 ~ 11111111,剛好是0 ~ 255,所以字符型別被稱為單字符型別資料,
而十六進制數,如:0x11223344則為多位元組資料,其中有4個位元組,分別是0x11、0x22、0x33、0x44,像這樣的資料則被稱為多位元組資料,
- 理解什么叫做多位元組資料的高位元組位,
在一個二進制序列中,
如:01010110101001011010100101101001
我們把前方高亮部分的0101稱為高位元組位,把后端加洗掉線的1001 部分稱為低位元組位,以此區分,
其實很好理解,因為最后一個1的的權重為20,也就是2的0次方,而第一個0的權重為231,也就是2的31次方,以此來區分高低位元組位也是很不錯的選擇,
接下來介紹大小端位元組序的存盤方式:
大端位元組序
所謂大端位元組序,就是將處于高位元組位的資料存放在記憶體的低地址處,將處于低位元組位的資料存放在記憶體的高地址處
如今給一資料:0x11223344
在記憶體中的存放形式為:
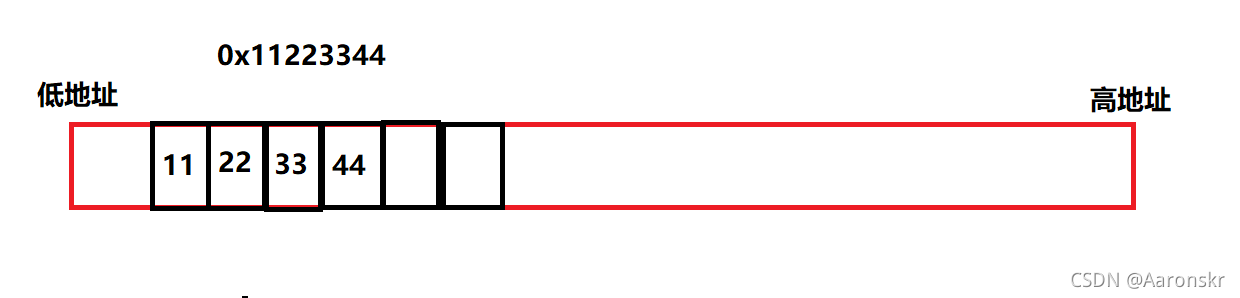
以這樣的形式存放的模式,就稱為大端存盤模式,這樣的存放順序,也就被稱為大端位元組序,
小端位元組序
所謂小端位元組序,就是將處于高位元組位的資料存放在記憶體的高地址處,將處于低位元組位的資料存放在記憶體的低地址處
今給一資料:0x11223344
在記憶體中的存放形式為:

以這樣的形式存放的模式,就稱為小端存盤模式,這樣的存放順序,也就被稱為小端位元組序,
在博主使用的VS2019編譯器上,采用的就是小端位元組序:
例:
int main()
{
int a = 0x0000ff40;
return 0;
}
除錯 - 記憶體視窗(&a):
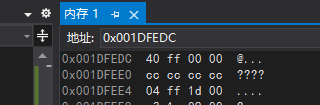
0x001DFEFC就是該代碼中a變數的地址,存放情況為40 ff 00 00,
也就是小端存盤模式,
👩?🍳百度系統工程師筆試題(通過編程判斷該編譯器為大端存盤還是小端存盤)
百度2015年系統工程師筆試題:
請簡述大端位元組序和小端位元組序的概念,設計一個小程式來判斷當前機器的位元組序,(10分)
該題前半部分在上文其實已經解決了,這里博主將分析問題,并實作代碼,
🧣問題分析
要判斷編譯系統到底是大端存盤還是小端存盤,其實并不復雜,
如0x11223344
如果是在大端存盤模式下:
存盤方式為:11 22 33 44
如果是在小端存盤模式下:
存盤方式為:44 33 22 11
所以其實只需要知道第一個位元組的內容到底是11還是44就可以判斷了,
但這樣的資料太過于復雜,不如換簡單一點的數字,比如1,
1的高位元組位就是00,低位元組位就是01,比較好判斷,
🎒代碼演示
int check_sys(int x)
{
return *(char*)&x;
}
int main()
{
int a = 1;
//約定:
//如果是大端,回傳0
//如果是小端,回傳1
int ret = check_sys(a);
if (ret)
{
printf("是小端存盤模式\n");
}
else
{
printf("是大端存盤模式\n");
}
return 0;
}
運行結果:
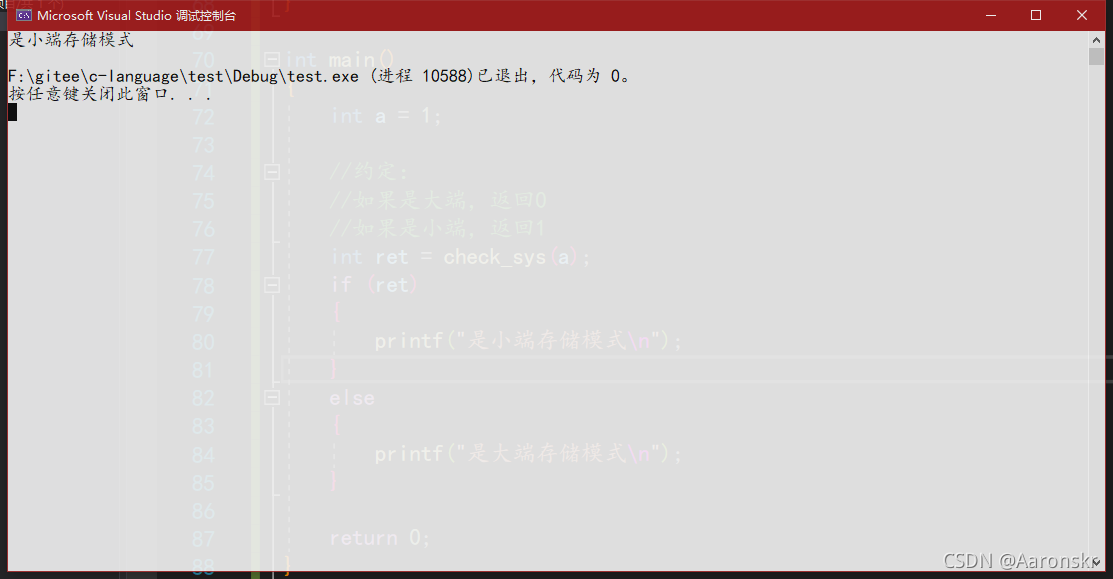
之前也分析了,我的編譯器VS2019是小端存盤模式,所以代碼的結果正確,下面分析代碼,
🎮代碼分析
-
想要在4個位元組中拿到第一個位元組,只需要在取地址時將整型強制型別轉換為字符型即可,拿到存放第一個位元組的地址后對其解參考便可拿到第一個位元組資料,
-
如果拿到的是01,說明存盤方式是01 00 00 00,也就是小端存盤模式,反之則為大端存盤模式,
這里如果有沒有講清楚的地方,歡迎評論區留言或者私信博主解決嗷,
🧶整型資料在記憶體中的存盤
資料在記憶體中的存盤遵循一定的法則,而整型資料和浮點型資料在記憶體中所遵循的法則是不同的,這里我們先介紹整型資料在記憶體中是如何存盤的,
介紹整型資料的存盤需要先引進一個概念:原反補碼,
💣原碼、反碼、補碼
計算機中的有符號數有三種表示方法,即原碼、反碼和補碼,三種表示方法均有符號位和數值位(或稱有效位)兩部分,符號位都是用0表示“正”,用1表示“負”,而數值位,三種表示方法各不相同,在計算機系統中,數值一律用補碼來表示和存盤,原因在于:使用補碼,可以將符號位和數值域統一處理;同時,加法和減法也可以統一處理,
而補碼其實是針對負數存盤設定的,對于無符號數來說,其反碼和補碼都和原碼相等,
原碼:
所謂原碼,就是將資料直接翻譯為二進制序列,
拿32位平臺舉例,最高位作為符號位,正數的符號位為0,負數的符號位為1,后面的31位稱為有效位,以不同的權重計算出不同的數字,最低位的權重為20,其次為21,以此類推,
如:
13的原碼為:00000000000000000000000000001101
-3的原碼為:10000000000000000000000000000011
反碼:
反碼,顧名思義,就是將原碼的二進制序列按位取反,但這里需要注意,并不是將所有的二進制位都按位取反,符號位是特殊獨立出來的,他表示一個數的正負,隨意取反可能會遭遇意想不到的結果,
所以反碼應該通過原碼除符號位,其他位按位取反獲得,
(注:正數的反碼和原碼相等,)
如:
13的反碼為:00000000000000000000000000001101
-3的反碼為:11111111111111111111111111111100
補碼:
整數在記憶體中的存盤存的都是補碼,所以要通過上面的反碼求出補碼,補碼的獲取規則是原碼按位取反(除符號位)再加一,
(注:正數的補碼和原碼相等,)
如:
13的補碼為:00000000000000000000000000001101
-3的補碼為:11111111111111111111111111111101
因為整數在記憶體中的存盤形式是補碼,所以引出原反補的意義就是求出補碼,而補碼的計算公式為:補碼 = 原碼按位取反(除符號位)再加一
這里我們通過VS2019編譯器進行驗證記憶體中存盤的是資料的補碼:
int main()
{
int a = 13;
//原碼:00000000 00000000 00000000 00001101
//反碼:01111111 11111111 11111111 11110010
//補碼:01111111 11111111 11111111 11110011
int b = -3;
//原碼:10000000 00000000 00000000 00000011
//反碼:11111111 11111111 11111111 11111100
//補碼:11111111 11111111 11111111 11111101
return 0;
}
編譯器下除錯 - 記憶體 - &a:
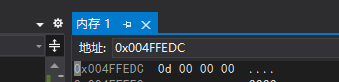
記憶體中存盤的是:0d 00 00 00
為小端存盤模式,00001101轉換為十六進制就是0d,
編譯器下除錯 - 記憶體 - &b:
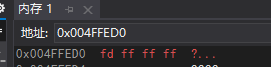
記憶體中存盤的是:fd ff ff ff
為小端存盤模式,1111 1111轉換為十六進制就是ff,1111 1101轉換為十六進制就是fd,
如此說來,在記憶體中真的存放的就是補碼,所以為了弄清楚整型資料在記憶體中的存盤,必須牢牢掌握原反補的概念,
🔨截斷與整型提升
我們知道int型別的變數所占空間大小是4個位元組32個bit位(32位平臺下),而char型別的變數所占空間大小是1個位元組8個bit位,那我要怎么將一個整型的資料存放在一個char型別的變數里呢?這里教大家一個很有用的辦法,那就是沒辦法,32個位元位是不可能放進8個小格子里的,所以就會發生所謂的截斷,
我們知道,一個char型別只能存放8個位元位,那如果我要將char型別的資料以%d的形式列印,也就是看做32位資料將其列印,那有要怎么做呢?再教大家一個辦法,那依然是沒辦法,所以編譯器只能對char型別的資料進行整型提升,
接下來簡單講解截斷和整型提升的原理,
截斷
假設我有一個32位二進制序列:
01010011001000110001000100100011
這是一個非常大的數字:
有一個char型別的空間:
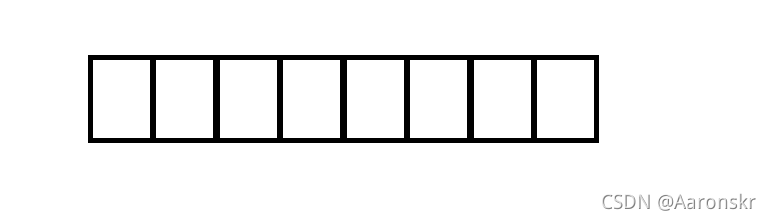
在把32位數字往里放的時候會發現放不下,便會發生截斷,只保留低八位的數字,其他24位數字直接舍棄,
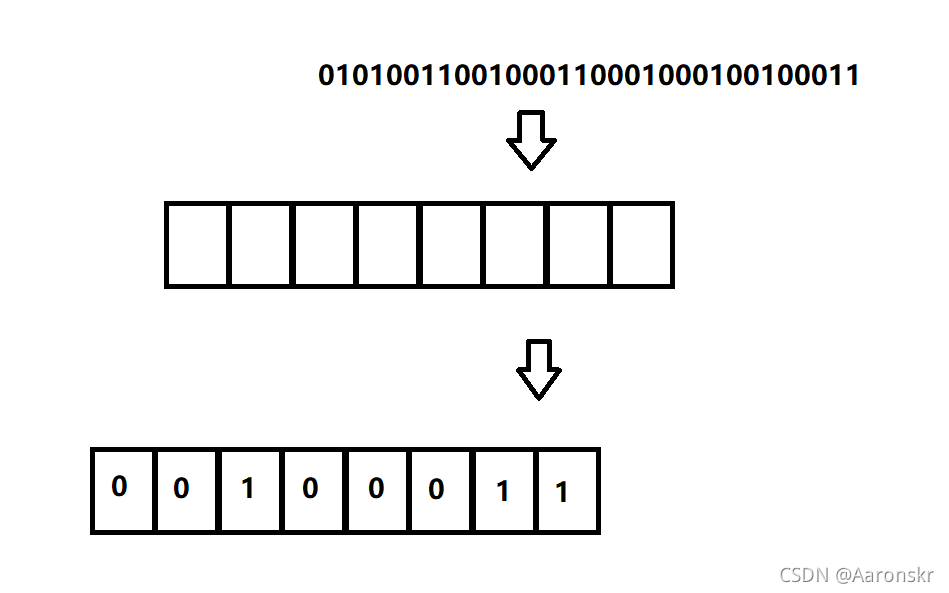
最終存放的結果為:
這就是截斷的程序,
整型提升
當我要將char型別的資料以%d的形式列印時,我們知道,%d是列印有符號整型,列印的是32位0/1序列的最終結果,但我們的char型別里只存放了8位,這個時候就會發生整型提升,
整型提升規則:
- 如果對無符號數進行整型提升,則在前面補24位0,
- 如果對有符號數進行整型提升,則判斷該數在當前的二進制0/1序列的首元素,相當于符號位,
- 如果是0,則全補0
- 如果是1,則全補1
如:
今有一8位無符號數,
unsigned char a = 148;
首先我們寫出該數的二進制序列,
10010100 - 148
由于變數a是無符號型別的,所以不管該二進制序列首元素是0還是1,都將全部補0
獲得:
00000000000000000000000010010100
最終列印的結果就是148
🎉整型資料存盤練習
對以下代碼分析輸出結果:
1.
//輸出什么?
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d b=%d c=%d\n", a, b, c);
return 0;
}
首先VS2019編譯器對char型別的處理為默認認為是有符號的char,所以變數a和變數b屬于同一型別,
先計算出-1的補碼,
int main()
{
//-1
//原碼:10000000000000000000000000000001
//反碼:11111111111111111111111111111110
//補碼:11111111111111111111111111111111
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d b=%d c=%d\n", a, b, c);
return 0;
}
三個變數都是char型別,所以存盤時都將發生截斷,
int main()
{
//-1
//原碼:10000000000000000000000000000001
//反碼:11111111111111111111111111111110
//補碼:11111111111111111111111111111111
char a = -1;
//存盤的補碼:11111111
signed char b = -1;
//存盤的補碼:11111111
unsigned char c = -1;
//存盤的補碼:11111111
printf("a=%d b=%d c=%d\n", a, b, c);
return 0;
}
現在要將三個變數以%d形式列印,則會發生整型提升,
- 而對于變數a和變數b來說,存放的是有符號的char,根據第一個二進制位決定提升的數為1,所以
變數a和變數b整型提升后的結果為:
11111111111111111111111111111111
- 而對于變數c來說,它是無符號的char,直接全部補0,所以
變數c整型提升后的結果為:
00000000000000000000000011111111
因為提升后的c符號位是0,所以原反補碼均相等,
而按%d形式列印需要將補碼轉化為原碼后轉化為十進制進行列印,
所以:
int main()
{
//-1
//原碼:10000000000000000000000000000001
//反碼:11111111111111111111111111111110
//補碼:11111111111111111111111111111111
char a = -1;
//存盤的補碼:11111111
//提升后的補碼:11111111111111111111111111111111
//提升后的反碼:10000000000000000000000000000000
//提升后的原碼:10000000000000000000000000000001
signed char b = -1;
//存盤的補碼:11111111
//提升后的補碼:11111111111111111111111111111111
//提升后的反碼:10000000000000000000000000000000
//提升后的原碼:10000000000000000000000000000001
unsigned char c = -1;
//存盤的補碼:11111111
//提升后的補碼:00000000000000000000000011111111
//提升后的反碼:00000000000000000000000011111111
//提升后的原碼:00000000000000000000000011111111
printf("a=%d b=%d c=%d\n", a, b, c);
return 0;
}
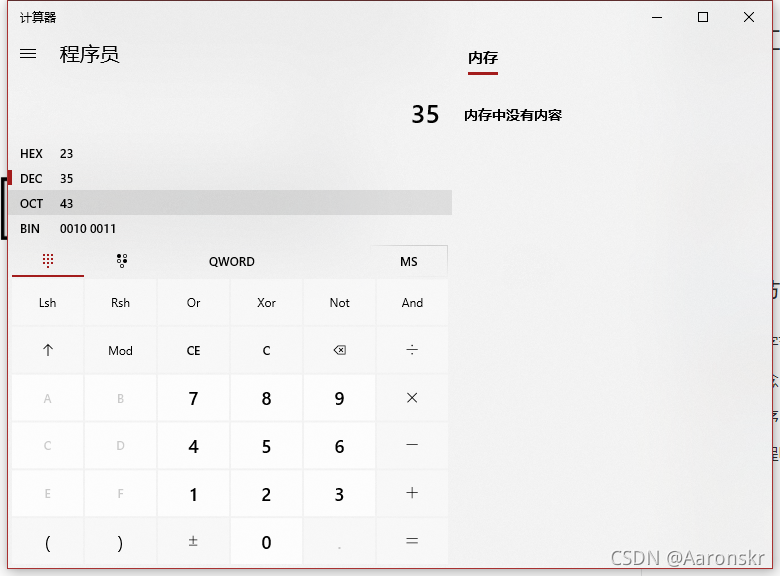
這么一來,列印的結果就應該是-1 -1 255
列印結果:
- 下面程式輸出什么?
2.
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}
這道題的變數a是有符號的char型別的,
首先計算出-128的原反補碼,
int main()
{
char a = -128;
//-128
//原碼:10000000000000000000000010000000
//反碼:11111111111111111111111101111111
//補碼:11111111111111111111111110000000
printf("%u\n", a);
return 0;
}
將01111111111111111111111110000000這樣一個二進制序列存放進a中將會發生截斷,
截斷之后a中存放的結果為:10000000
這時以%u的形式列印,也就是以無符號整型的形式列印,要進行整型提升,而變數a是一個有符號的char型別,第一個元素是1,所以整型提升24個1,
int main()
{
char a = -128;
//-128
//原碼:10000000000000000000000010000000
//反碼:11111111111111111111111101111111
//補碼:11111111111111111111111110000000
//截斷的結果:10000000
//整型提升后的結果:11111111111111111111111110000000
printf("%u\n", a);
return 0;
}
這時要將提升之后的補碼轉換為原碼后以十進制的形式進行列印,
而%u的形式將把補碼中的符號位看做是有效位,所以其原反補都是一樣的,
int main()
{
char a = -128;
//-128
//原碼:10000000000000000000000010000000
//反碼:11111111111111111111111101111111
//補碼:11111111111111111111111110000000
//截斷的結果:10000000
//整型提升后的結果:11111111111111111111111110000000
//補碼:11111111111111111111111110000000
//反碼:11111111111111111111111110000000
//原碼:11111111111111111111111110000000
printf("%u\n", a);
return 0;
}
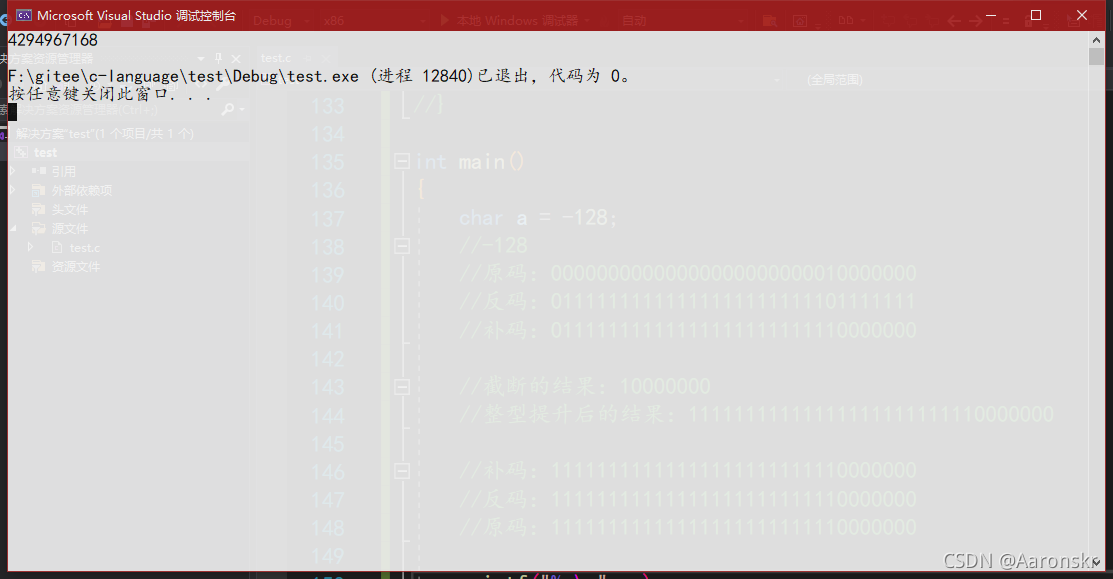
而11111111111111111111111110000000的值應該是4,294,967,168
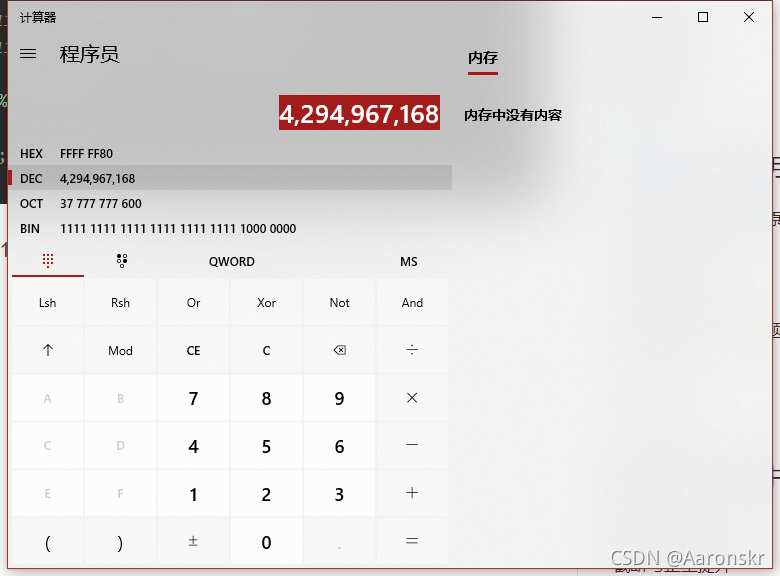
所以輸出結果:
3.
int main()
{
char a = 128;
printf("%u\n", a);
return 0;
}
還是一樣,先求出128的補碼,由于128是正數,所以其原反補都是相同的為:
00000000000000000000000010000000
存放進變數a中將發生整型截斷:
10000000
而變數a為有符號的char型別,所以整型提升為
11111111111111111111111110000000
變數a以%u形式列印,則把符號位看成有效位,則此時原碼反碼補碼相同,直接進行計算,11111111111111111111111110000000的十進制形式為4,294,967,168
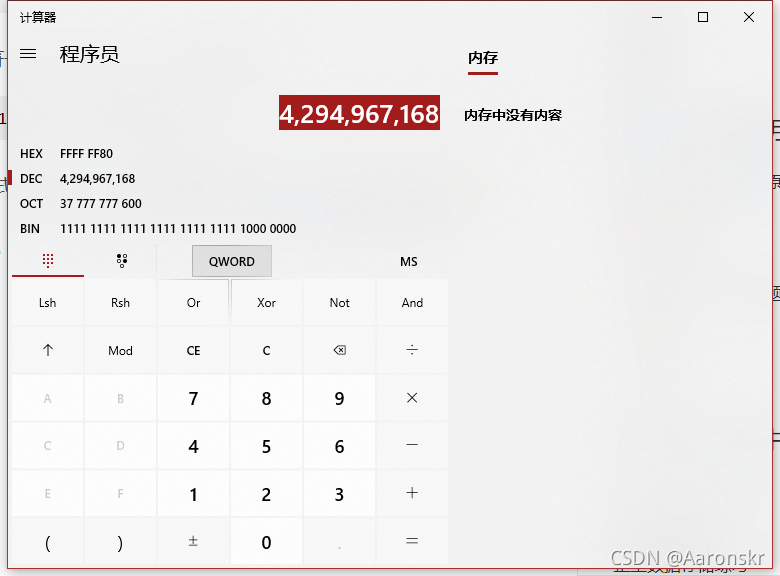
所以列印結果為:
4.
int mian()
{
int i = -20;
unsigned int j = 10;
//按照補碼的形式進行運算,最后格式化成為有符號整數
printf("%d\n", i + j);
return 0;
}
還是先把-20和10的補碼計算出來,但是這里的i和j都是整型變數,所以不會發生截斷和整型提升,
int mian()
{
int i = -20;
//-20
//原碼:10000000000000000000000000010100
//反碼:11111111111111111111111111101011
//補碼:11111111111111111111111111101100
unsigned int j = 10;
//10
//補碼:00000000000000000000000000001010
//按照補碼的形式進行運算,最后格式化成為有符號整數
printf("%d\n", i + j);
return 0;
}
資料的計算是按照二進制補碼的形式進行計算的,最后的結果再根據列印要求或者存盤要求進行調整更改,
計算的結果:
int mian()
{
int i = -20;
//-20
//原碼:10000000000000000000000000010100
//反碼:11111111111111111111111111101011
//補碼:11111111111111111111111111101100
unsigned int j = 10;
//10
//補碼:00000000000000000000000000001010
//計算:
//11111111111111111111111111101100
//00000000000000000000000000001010
//11111111111111111111111111110110 - 補碼相加的結果
//按照補碼的形式進行運算,最后格式化成為有符號整數
printf("%d\n", i + j);
return 0;
}
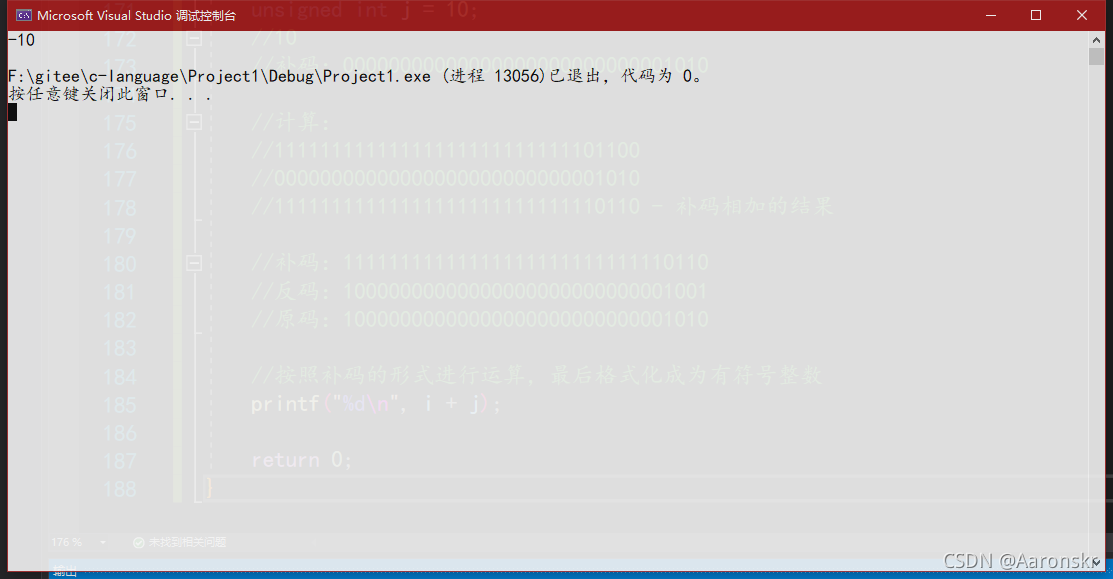
要求按%d的形式列印,則將計算的結果轉化為原碼以有符號十進制數列印,
補碼:11111111111111111111111111110110
反碼:10000000000000000000000000001001
原碼:10000000000000000000000000001010
計算結果為-10
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
}
程式分析:
變數i從9開始自減到0時,都可以正常進入程式列印的值就是
9 8 7 6 5 4 3 2 1 0
在列印完0之后,變數i再自減1,變成-1,按道理來說應該跳出回圈,但我們注意,這里的變數i為無符號整型,而-1的補碼為11111111111111111111111111111111,所以會被決議為一個特別大的正整數:4294967295,
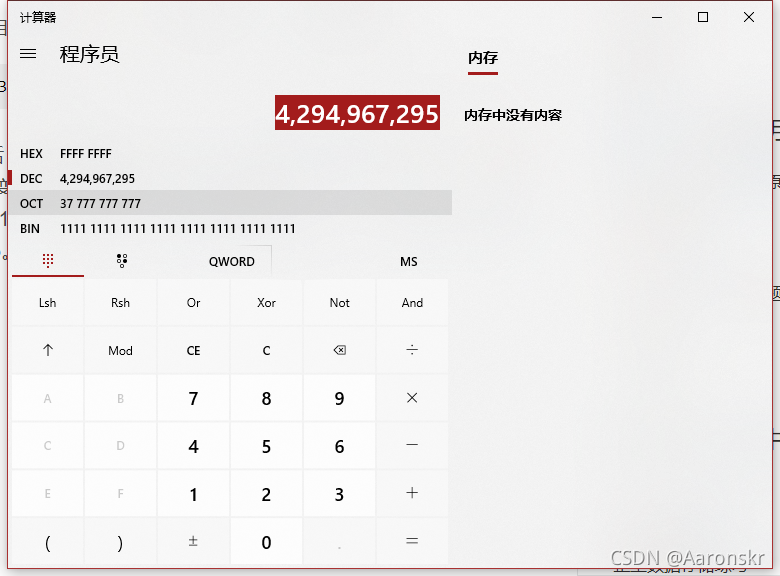
那么他也符合回圈控制條件(i >= 0),所以回圈會繼續4294967295次,而一直自減到0的時候,再次自減又變成-1,有被決議為4294967295,所以該程式將無限回圈下去,
這里博主隨便截兩張列印結果的圖供大家參考,
6.
#include <string.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
程式分析:
根據代碼可知陣列中第一個存放的數應該是-1,第二個是-2,以此類推,

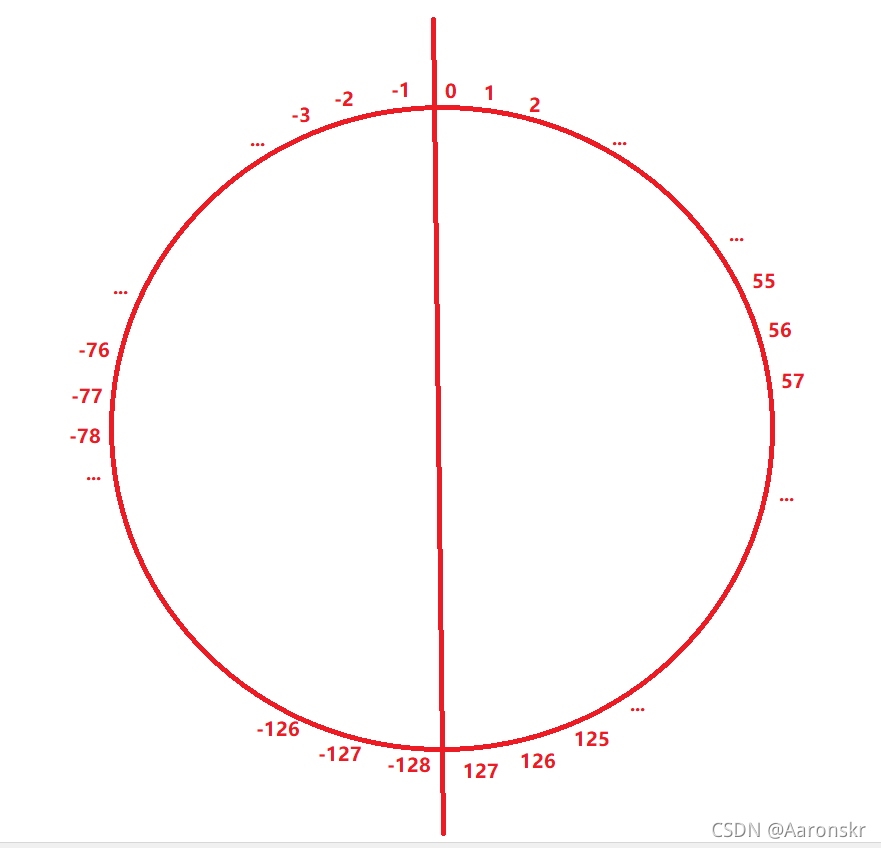
但是這個陣列是char型別的,我們知道char型別可存放的資料范圍是-128~127,所以這些資料一直自減到-128之后,如果再自減就會放不下了,但是這里有一個小知識點,
通過畫圖給大家講解,

-
這個圖中放的是char型別補碼對應十進制的全部情況,二進制位從0開始補碼加1,即十進制從0開始加1計算,最終計算到127,
-
11111111為-1的補碼,往上減1計算得到-2,再減1就是-3,以此類推可計算到-127,
-
而10000000這個二進制序列是無法計算的,所以系統直接將其賦為-128,
綜合以上三點可知,char型別的補碼其實是以從-1,-2,…,-127,-128,127,126,…,2,1這樣的方式連續的,
畫成圖的形式為:
由以上兩個圖可知,記憶體中的資料存放為:

其實這又是一個無限回圈的存放,一直存放滿1000個資料為止,
而列印的是字串長度,使用的是strlen函式,strlen函式遇到\0就停止計算,所以計算的結果應該為128 + 127 = 255,
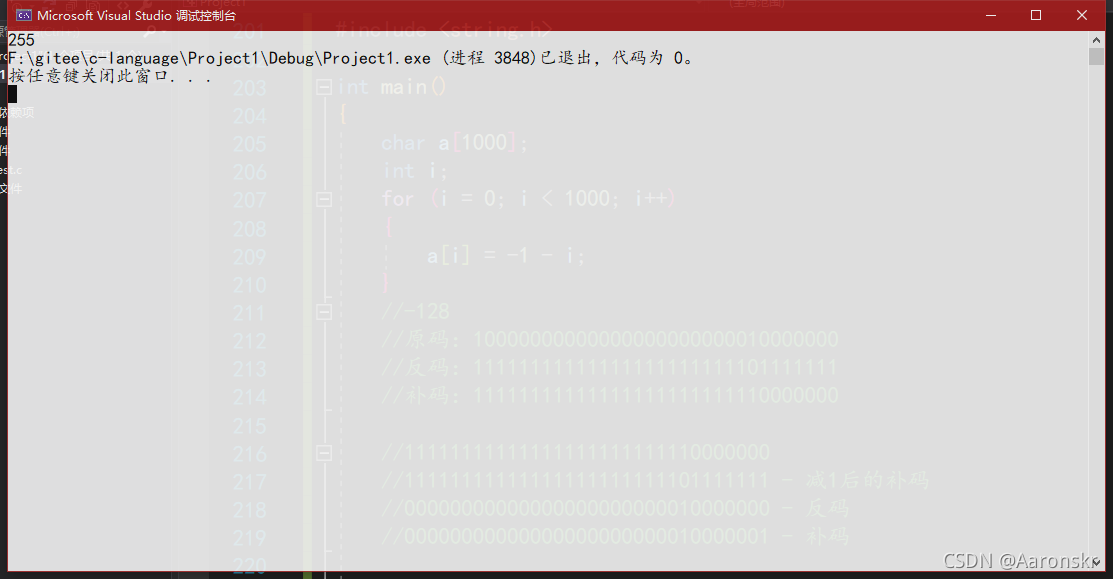
7.
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
程式分析:
首先定義了一個全域變數:無符號整型i,
無符號的char型別范圍是0~255,所以代碼前面會列印255個"hello world\n",這一點肯定沒錯,
而255作為無符號數在記憶體中的補碼是:
00000000000000000000000011111111
自增1之后的結果是:
00000000000000000000000100000000
將這個數存放于變數i中必然是存不下,所以會發生截斷,
只保留低八位存盤,所以變數i現在存盤的是00000000,也就是0,是一個無符號數,原反補相同,并且符合回圈條件,所以回圈又開始了,
經過上述分析,該代碼的結果應該是一個無限列印的死回圈,
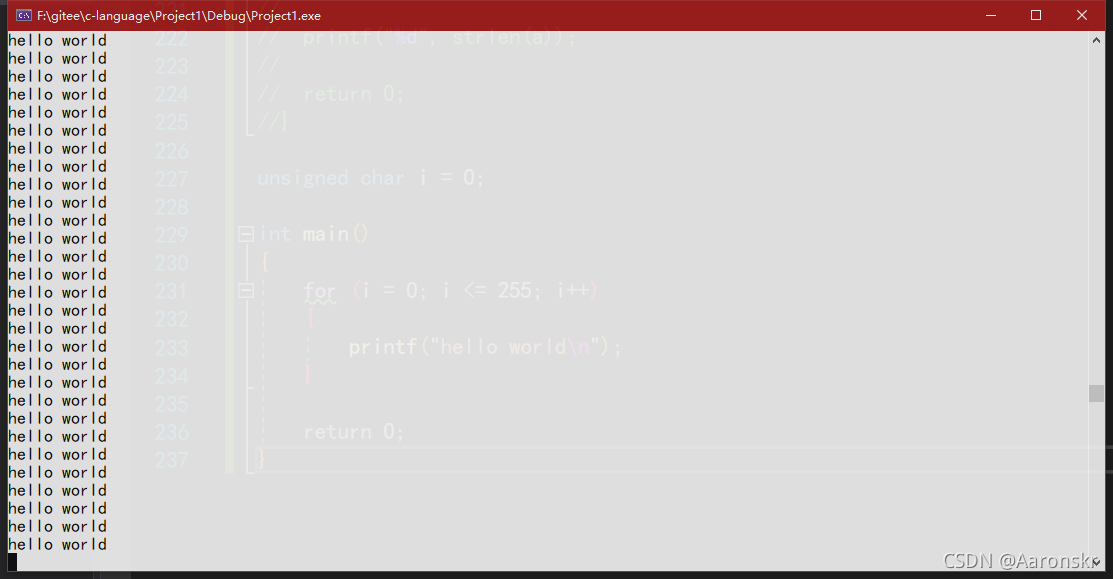
🏆浮點型資料在記憶體中的存盤
首先我們先見一下常見的浮點型資料有哪些?
3.14159
1E10
浮點型資料型別:
- float
- double
- long double
long double是在C99標準中引入的,比較老舊的編譯器都不支持這種寫法,
浮點數表示的范圍:在"float.h"檔案中可以查看,
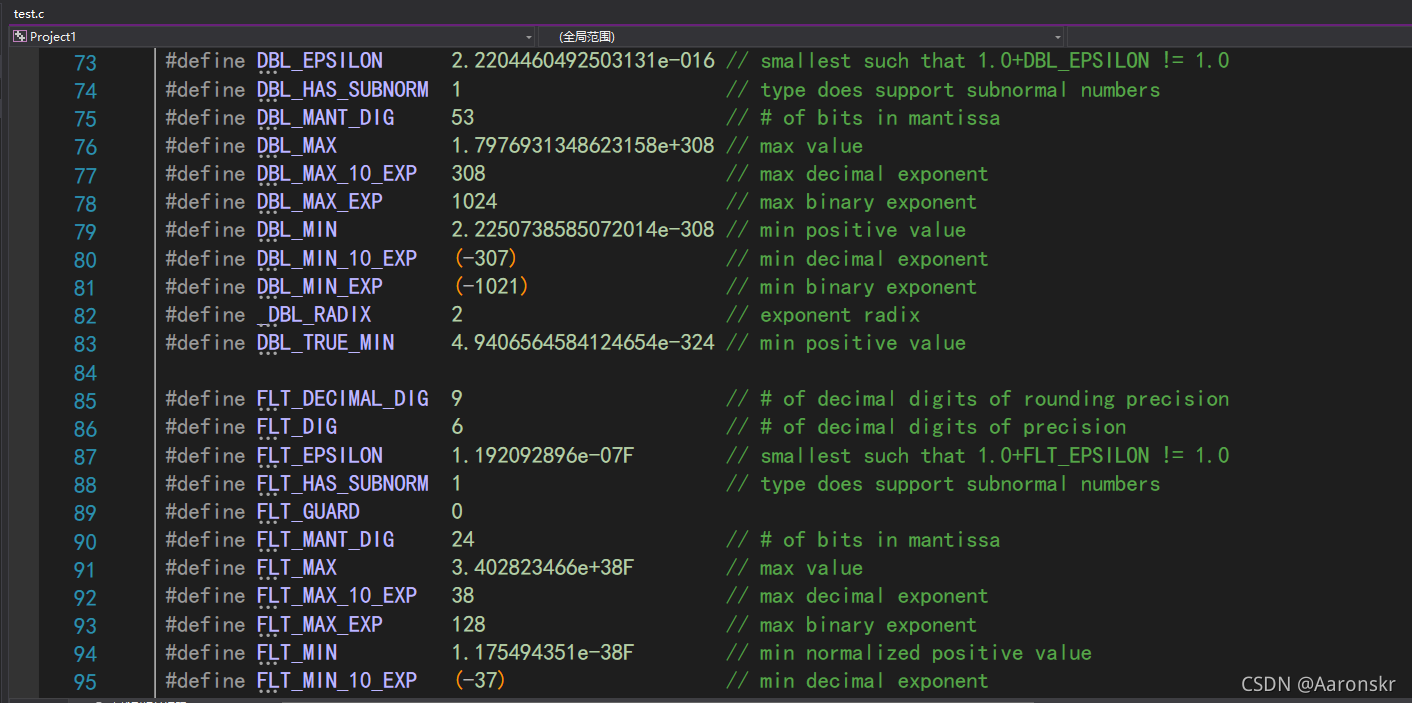
在此檔案中即可查看浮點型資料的范圍大小,
接下來介紹浮點型資料在記憶體中的存盤方式,
🎨證明整數和浮點數的存取方式不同
浮點數存盤的例子:
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值為:%d\n", n);
printf("*pFloat的值為:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值為:%d\n", n);
printf("*pFloat的值為:%f\n", *pFloat);
return 0;
}
列印結果為:
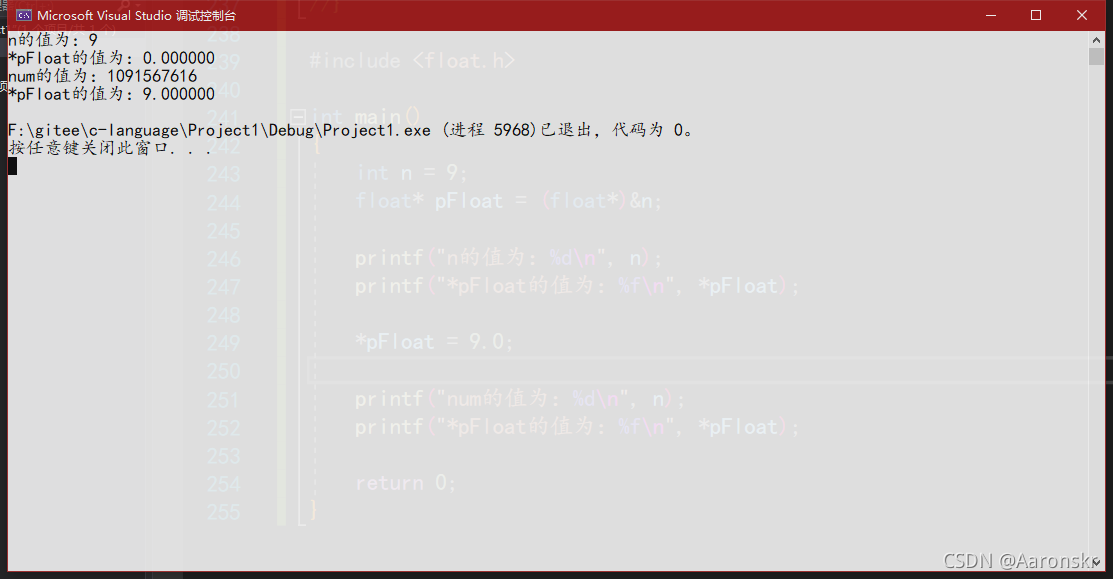
-
將9存放進int型別的變數i中,所以第一個列印是9,這很容易理解,而用float型別的指標對其解參考得到的值卻是0;
-
用float指標型別將記憶體中的值覆寫為9.0,以整型的方式列印出來是我們不知道的值,而用float型別指標解參考得到了9.0,
以上例子證明了整型資料和浮點型資料的存盤方式是截然不同的,接下來就
開始研究浮點型資料在記憶體中到底是以怎樣的形式進行存盤的,
🍦IEEE標準形式
根據國際標準IEEE(電氣和電子工程協會)754,任意一個二進制浮點數V可以表示為下面的形式:
- (-1)S ? M ? 2E
- (-1)s表示符號位,當s = 0時,V為正數;當s = 1時,V為負數,
- M表示有效數字,M必須大于等于1,且小于2,
- 2E表示指數位,
舉兩個例子:
- 十進制數3.75,先將其轉化為二進制數011.11
二進制數011就是十進制數3,小數點后面的第一個1表示1.0 / 21,第二個1表示1.0 / 22
轉換為IEEE標準形式為(-1)0 ? 1.111 ? 21
此時S = 0,M = 1.111,E = 1
- 十進制數-0.5,現將其轉化為二進制數-0.1
二進制數0就是十進制數0,小數點后面的1表示1.0 / 21,
轉換為IEEE標準形式為(-1)1 ? 1.0 ?2-1,
此時S = 1,M = 1.0,E = -1
==注意:==小數點后面的數都是按照1.0 / 2n的形式相加得到的,所以很多數其實是得不到準確值的,
🍚IEEE存盤標準規定
- IEEE 754規定:
- 對于32位的浮點數,最高的1位是符號位s,接著的8位是指數E,剩下的23位為有效數字M,
- 對于64位的浮點數,最高的1位是符號位S,接著的11位是指數E,剩下的52位為有效數字M,
畫圖說明:
- 對于單精度浮點數:

- 對于雙精度浮點數:
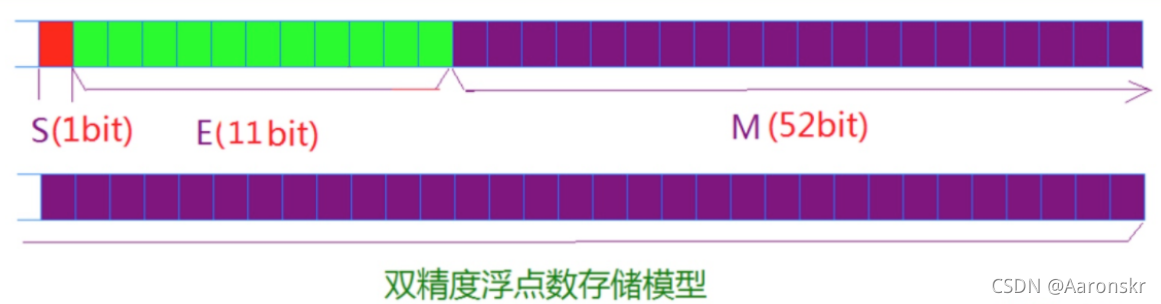
- IEEE 754對有效數字M和指數E,還有一些特別規定,
對于M(有效數字)的規定:
前面說過,1 ≤ M < 2 ,也就是說,M可以寫成1.xxxxxx的形式,其中xxxxxx表示小數部分,
IEEE 754規定,在計算機內部保存M時,默認這個數的第一位總是1,因此可以被舍去,只保存后面的xxxxxx部分,比如保存1.01的時候,只保存01,等到讀取的時候,再自動把第一位的1給加上去,這樣做的目的是節省1位有效數字,以增加M的精度,
以32位浮點數為例,留給M的空間只有23位,將第一位的1舍去以后,等于可以保存24位有效數字,
對于E(指數部分)的規定:
至于指數E,情況就比較復雜,
首先,E為一個無符號整數(unsigned int),這意味著,如果E為8位,它的取值范圍為0 ~ 255;如果E為11位,它的取值范圍為0~2047,但是,我們知道,科學計數法中的E是可以出現負數的,所以IEEE 754規定,存入記憶體時E的真實值必須再加上一個中間數,對于8位的E,這個中間數是127;對于11位的E,這個中間數是1023,比如,210的E是10,所以保存為32位浮點數時,必須保存為10 + 127 = 137,即10001001,
加上127或者1023進行存盤的原因是取出該數的時候就需要減去127或者1023,這樣E就可以得到負數的情況,
🥛IEEE讀取標準規定
指數E從記憶體中取出還可以再分成三種情況:
- E不全為0或不全為1
這時,浮點數就采用下面的規則表示:
即指數E的計算值減去127(或1023),得到真實值,再將有效數字M前加上第一位的1,
比如:
十進制數0.5的二進制形式為0.1,由于規定整數部分必須為1,即將小數點右移1位,則為(-1)0 ? 1.0 ? 2(-1),其階碼(指數部分)為-1 + 127 = 126,表示為01111110,而有效位部分1.0去掉整數部分為0,補齊0到23
位00000000000000000000000,則其二進制表示形式為:
0 01111110 00000000000000000000000
- E全為0
可以理解為E為全0時,該數被決議為0,
因為,當E為全0時,說明以IEEE標準形式寫出的式子的指數部分是-127或者-1023,也就是說符號位和有效位要乘以1.0 / 2127或者乘以1.0 / 21023的數,而這個數非常小,近乎為0,所以在記憶體中取出該數時通過一些辦法直接將其翻譯為0,
- E全為1
這時,表示±無窮大(正負取決于符號位S);
原因是,如果E全為1,則指數位計算的是128,2128次方是一個非常大的數字,所以這里我們可以認為他是正負無窮大,
舉個簡單的例子,如十進制數-12.75,轉換為二進制數為:-1100.11,轉換為IEEE標準形式為(-1)1 ? 1.10011 ? 2 3,此時的S = -1, M = 1.10011,E = 3
以單精度浮點型為例,將其存入記憶體的方式為:把S放在第一位作為符號位,E加上127,即3 + 127 = 130轉化為二進制數10000010,把M的整數部分去掉,將小數部分存盤,E和M不夠的位全部補0,
即
1 10000010 10011000000000000000000
在VS2019編譯器上測驗:
int main()
{
float f = -12.75;
return 0;
}
除錯 - 記憶體 - &f:

編譯器的形式為十六進制
將其翻譯為二進制為:
00000000 00000000 01001100 11000001
而我們剛才的計算結果是:
11000001 01001100 00000000 00000000
可以發現,和我們寫的正號相反,這說明浮點型資料在記憶體中存盤也遵循大小端位元組序規則,且這里遵循的是小端位元組序,
最后,我們在來看最開始給出的那道例題:
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值為:%d\n", n);
printf("*pFloat的值為:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值為:%d\n", n);
printf("*pFloat的值為:%f\n", *pFloat);
return 0;
}
程式分析:
- 第一次賦值時,將9賦值給n,屬于整型資料存盤,
其二進制序列為:
000000000000000000000000000001001
第一次列印為整型列印,輸出為9
第二次列印為浮點型列印,就要以浮點型資料的方式取出:
0 00000000 000000000000000000001001
第一部分為S(符號位),第二部分為E(指數位(需要減去127/1023)),第三部分為M(有效位(小數部分))
符號位為0,說明是正數,指數位為全0,減去127后得到-127,放在指數部分是2-127,即1.0 / 2127,是一個非常小的數,無論M(有效位)為多少,這里都將翻譯為0,所以第二次列印結果輸出為0.0,
- 第二次賦值時,是以浮點型存盤方式進行賦值,
十進制數9.0,轉換為二進制數為1001.0,轉換為IEEE標準格式為(-1)0 ? 1.001 ? 23,
其中S = 0,M = 1.001,E = 3
進行二進制存盤時,第一位放符號位,后8位放E+127的二進制序列,其余位放M的小數部分,
即
0 10000010 00100000000000000000000
第三次列印結果為將這個二進制數翻譯為十進制,
即1091567616?
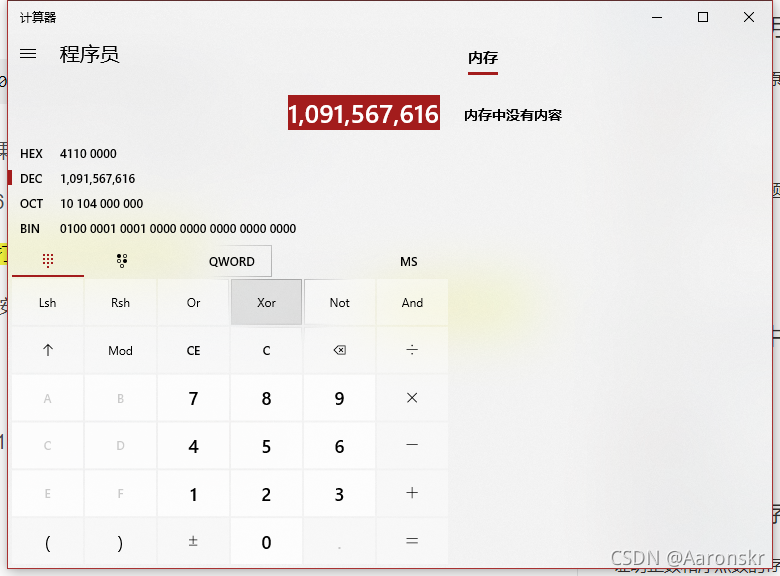
所以,第三次列印結果為1091567616?
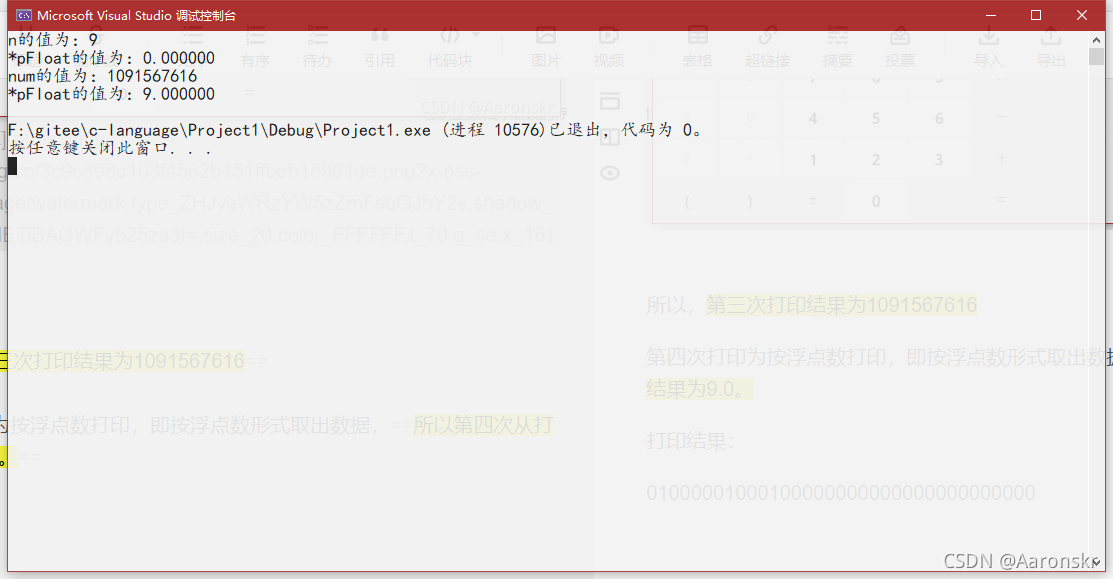
第四次列印為按浮點數列印,即按浮點數形式取出資料,所以第四次從列印結果為9.0,
列印結果:
🍃總結
本文內容較多,首先介紹了各個資料型別,又介紹了編譯器中的大小端存盤模式,接著講解了2015年百度系統工程師的一道筆試題,在整型資料記憶體存盤中介紹了原反補、截斷和整型提升的概念,并進行了7道題目的訓練,最后根據IEEE協會講述了浮點型資料在記憶體中的資料,可謂干貨慢慢,建議大家收藏下來慢慢看,
最后我是Aaron,希望今天的博文對各位有幫助,別忘了三連支持哇~
👍點贊👍 + 👀關注👀 + ?收藏?
如果以上內容有任何不懂的地方歡迎評論區留言或者私信博主哦~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/308748.html
標籤:java