一、前言
上篇文章中我們成功撰寫并啟動了第一個selenium腳本,那Selenium是怎樣知道我們想要操作哪個元素的呢?
這篇文章將為你講解Selenium的頁面操作原理和高效的元素定位方法,
(PS:個人在用的人工智能學習網站推薦給大家:captainai,覺得不錯請三連支持一下)
文章目錄
- 一、前言
- 二、Selenium是如何操作頁面元素的?
- 三、高效的定位方法和Xpath定位講解
- 1. 利用瀏覽器工具
- 2.Xpath定位簡單介紹
- 1. 絕對定位
- 2. 相對定位
- 3. Xpath代碼解釋
- 1. `//`和`/`的區別和含義:
- 2. `*`的含義
- 3. `[]`的含義
- 4. Xpath的模糊匹配和條件匹配
- 四、總結
二、Selenium是如何操作頁面元素的?
Selenium首先會查找我們給予的元素地址是否存在,如果存在則進行我們指定的操作,
例如上篇文章中的這行代碼,它用于在百度搜索框輸入曲鳥 csdn:
# 在輸入框輸入:曲鳥 csdn
driver.find_element(By.XPATH, '//*[@id="kw"]').send_keys('曲鳥 csdn')
代碼解釋:首先,我們通過【driver.find_element】方法,給予了兩個引數:
1.定位的方法:Xpath;
2.元素地址://*[@id="kw"];
通過這兩個引數得以讓Selenium能夠找到百度的搜索框元素,再通過【send_keys】方法傳遞想要輸入的內容曲鳥 csdn,Selenium就會在其進行輸入,
上面的例子使用的定位方法是Xpath,除此之外Selenium還支持七種(共八種)定位方法:
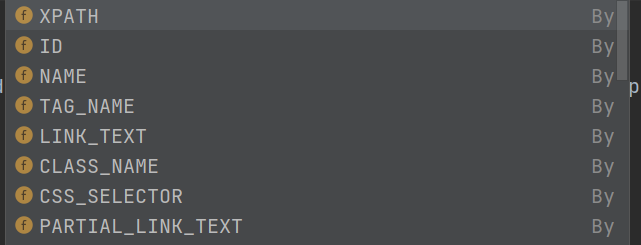
是不是感覺有點多?但我們無需全部掌握它們!
我們無需花太多精力在學習定位上,雖然我們的每個自動化操作都需要進行元素定位,但瀏覽器的除錯工具已經可以幫我們獲取元素地址了,
有小伙伴會說,通過工具定位出來的元素地址一長串是否會影響除錯和體驗呢?
其實擔心是多余的,首先元素地址不同于代碼,它不需要具備可讀性!只要能夠定位成功且有一定的穩定性就行了!其次,如果你為了減少元素地址的長度,而花時間去手寫元素地址的話,這個時間會是通過工具定位的數倍!自動化測驗本就需要高效的完成腳本,減少自動化用例撰寫的時間占比,從而達到高效自動化的目的,現在為了元素地址的可讀性來增加自動化撰寫的時長是得不償失的!并且現在隨著react、vue的普及,前端組件化應用的越來越多,通過【id、name、class】這些定位方式已經不太適用了 (前提是開發不愿意加唯一標識(唯一的【id、name】等)的情況下) 所以完全沒必要花大量的時間去搞懂八種定位,只需要簡單了解即可,
另外一點,Xpath定位很強大,花時間搞懂Xpath遠比花時間去學習完八種定位要高效的多!
三、高效的定位方法和Xpath定位講解
1. 利用瀏覽器工具
【Chrome】瀏覽器自帶了定位方式的獲取工具,按下F12(右鍵滑鼠,點擊"檢查")也可以,按圖中的步驟操作就可以獲取到需要操作的元素地址
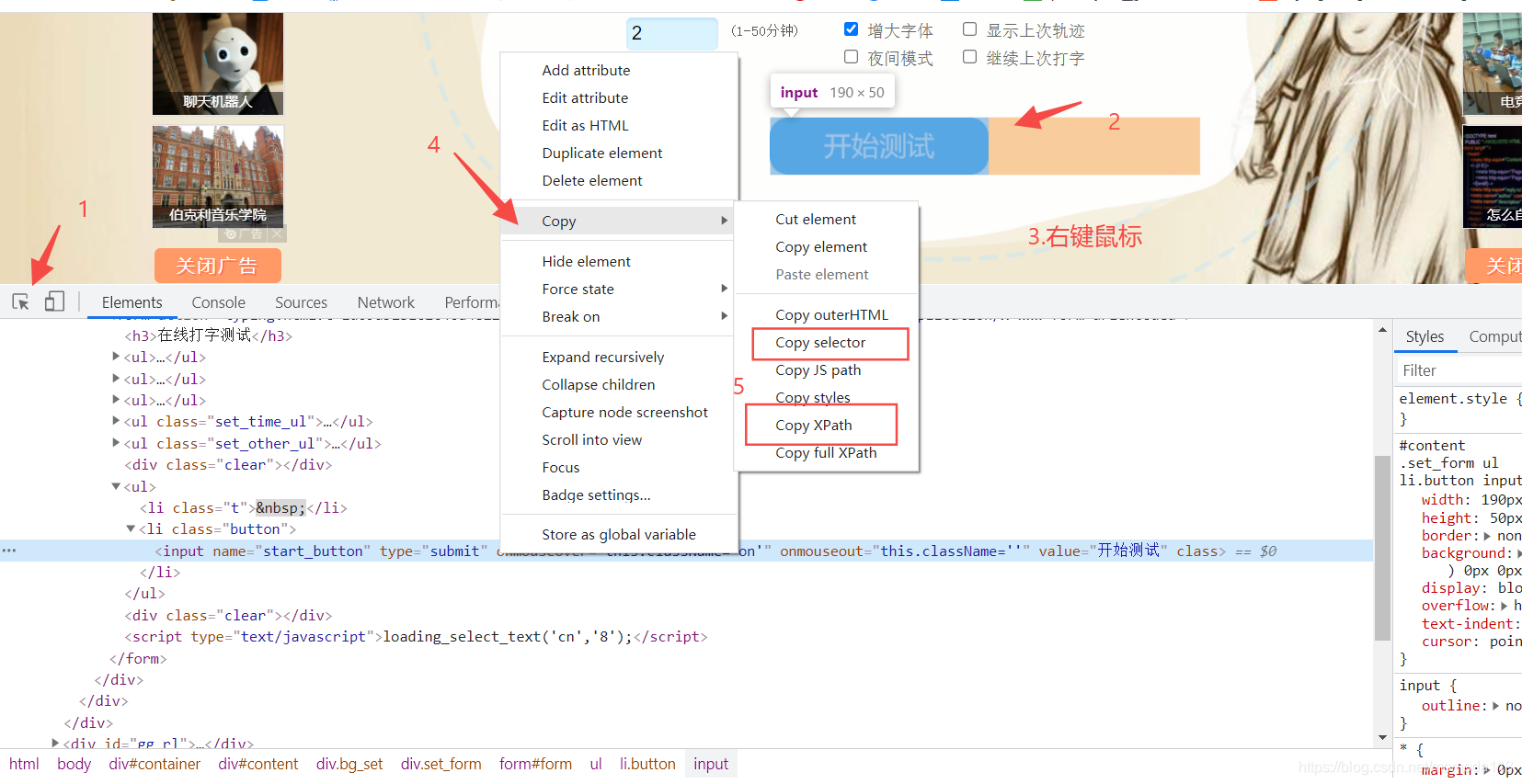
但在我們實際應用程序中,會出現定工具獲取的Xpath定位地址,代碼跑起來定位不到的情況!這種情況一般可能是因為元素的id是動態的(重新訪問頁面元素的id會變)或者所屬層級沖突(操作頁面步驟的順序改變導致層級優先級不同)這個時候就可以借助Xpath的高級運用(文本關鍵字匹配,條件匹配等)來解決,
2.Xpath定位簡單介紹
1. 絕對定位
通過【Chrome】自帶的定位工具,選擇【Copy full XPath】得到的就是xpath絕對路徑 (非特殊情況不建議使用,使用相對定位即可)
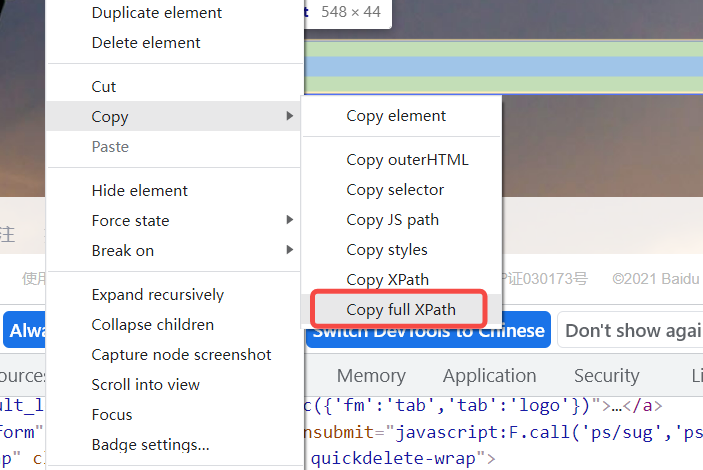
路徑代碼
/html/body/div/div[2]/div[5]/div[1]/div/form/span[1]/input
2. 相對定位
通過【Chrome】自帶的定位工具,選擇【Copy XPath】得到的就是xpath相對路徑 (推薦使用)
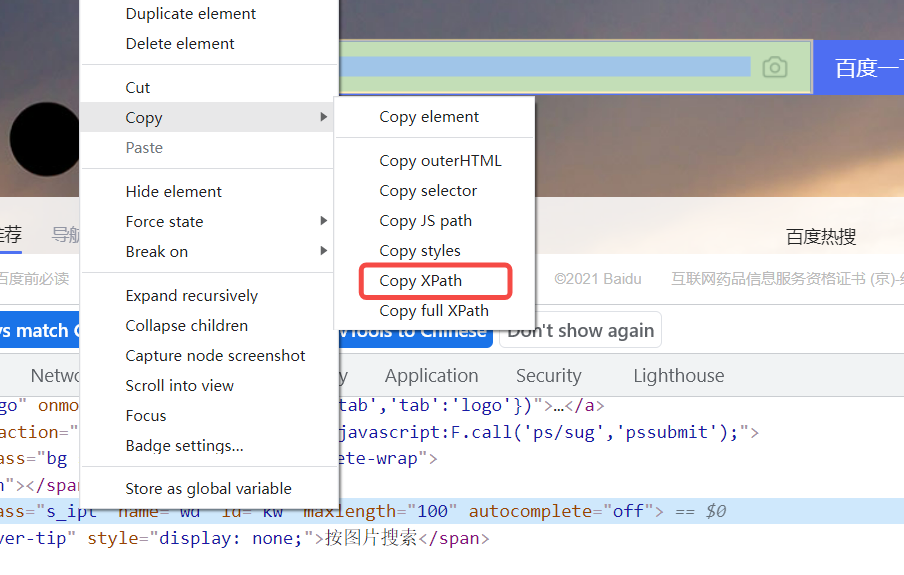
路徑代碼
下面的代碼會查找id等于kw的元素:
//*[@id="kw"]
3. Xpath代碼解釋
1. //和/的區別和含義:
//代表會在所有節點去進行查找,如果要指定層級或逐層查找的話可以使用/,
舉個例子:
下面的xml代碼含義:一個班級下有兩個學生【曲鳥 男】、【張三 女】:
<class>
<student>
<name>曲鳥</name>
<gender>男</gender>
</student>
<student>
<name>張三</name>
<gender>女</gender>
</student>
</class>
1)現在我們想獲取第一個學生的資訊可以這樣寫:
/class/student[1]
輸出結果
<name>曲鳥</name>
<gender>男</gender>
2)想獲取第一個學生的名稱可以這樣寫:
/class/student[1]/name
輸出結果
曲鳥
上面的代碼是一層一層(class->student->name),那是否可以不指定層級,直接查找名稱呢?
3)通過//獲取學生名稱:
/class/name
甚至還可以這樣寫
//name
輸出結果
張三
雖然獲取到姓名了,但變成張三了,如果你通過//name[1]的方式來獲取的話,會發現執行失效!
所以,//是不能夠指定下標的,如果想獲取曲鳥的話可以通過校驗文本的方式來匹配:
//name[text()="曲鳥"]
Xpath在線練習地址:https://www.bejson.com/testtools/xpath/
2. *的含義
*代表匹配任何元素節點,通過分析下圖百度搜索框的原始碼發現它的標簽為input,那么我們將代碼改為這樣//input[@id="kw"]也是可行的,

3. []的含義
[]中用于放置具體的匹配規則,之前代碼中的[@id="kw"]代表匹配id等于kw的元素;分析上圖紅框標簽的屬性會發現,如果替換為[@name="wd"]也是能夠匹配成功的;還可以改寫為[@class="s_ipt"];
4. Xpath的模糊匹配和條件匹配
Xpath中=用于全匹配,那它支持模糊匹配嗎?
答案是支持的,Xpath中=必須一模一樣才算匹配成功,Xpath也可以通過contains進行模糊匹配,之前代碼中的[@id="kw"]可以改寫為[contains(@id, "k")]這樣也能夠匹配成功,它的含義為匹配id名稱包含k的元素,
如果有兩個id都包含k那不是就匹配失敗了嗎?
是的,這個時候就可以使用Xpath的條件判斷,例如有兩個元素,他們的id分別為:kw1、kw2,我們想通過模糊匹配來匹配kw1的話,可以這樣寫[contains(@id,"k") and contains(@id,"1")],代碼含義為匹配id名稱既包含k又包含1的元素
Xpath可以通過顯示的文本進行匹配嗎?
可以的,下面是百度頁右上角【新聞】標簽的原始碼

通過文本匹配的話,代碼可以這樣寫 (類似于八大定位方式中的By.LINK_TEXT):
//*[text()="新聞"]
通過聞字模糊匹配的話可以這樣寫 (類似于八大定位方式中的By.PARTIAL_LINK_TEXT):
//*[contains(text(),"聞")]
四、總結
Xpath的功能還有很多,但對于自動化來講掌握上述這幾種常用方法已經足夠了!萬一還不夠用,我們還可以通過airtest【影像識別】的定位方法來解決,
可以閱讀 重復元素如何定位區分?Selenium的缺點讓影像識別來彌補 這篇文章進行了解,后續也會在該專欄的實戰篇中進行詳細影像識別定位的教學,歡迎訂閱本專欄!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/308766.html
標籤:python