
之前三節我們主要分析了KafkaProducer是如何將訊息放入到記憶體緩沖區的,
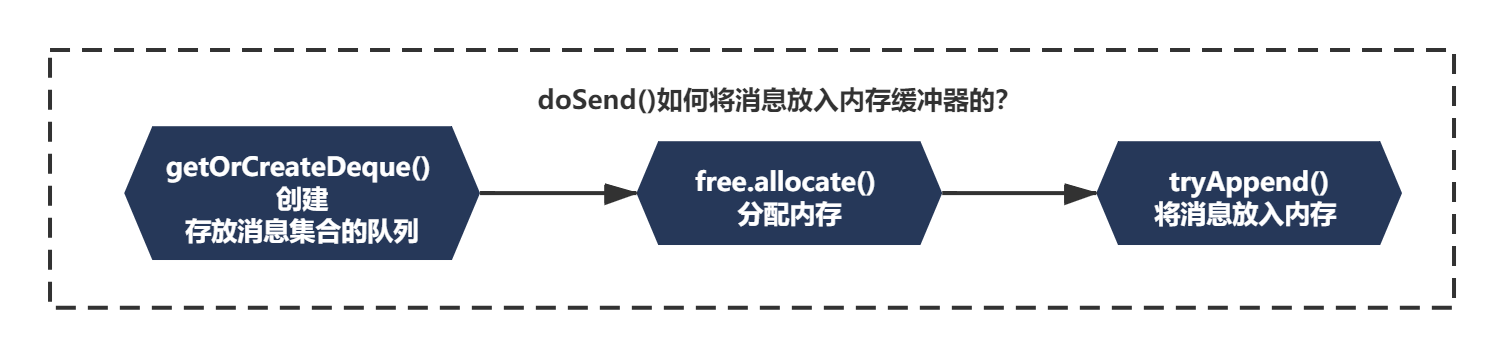
上面的邏輯只是Accumulator.append()的一段核心邏輯而已,還記得之前我們分析過的KafkaProducerHelloWorld的整體邏輯么?
之前分析的代碼邏輯如下圖所示:
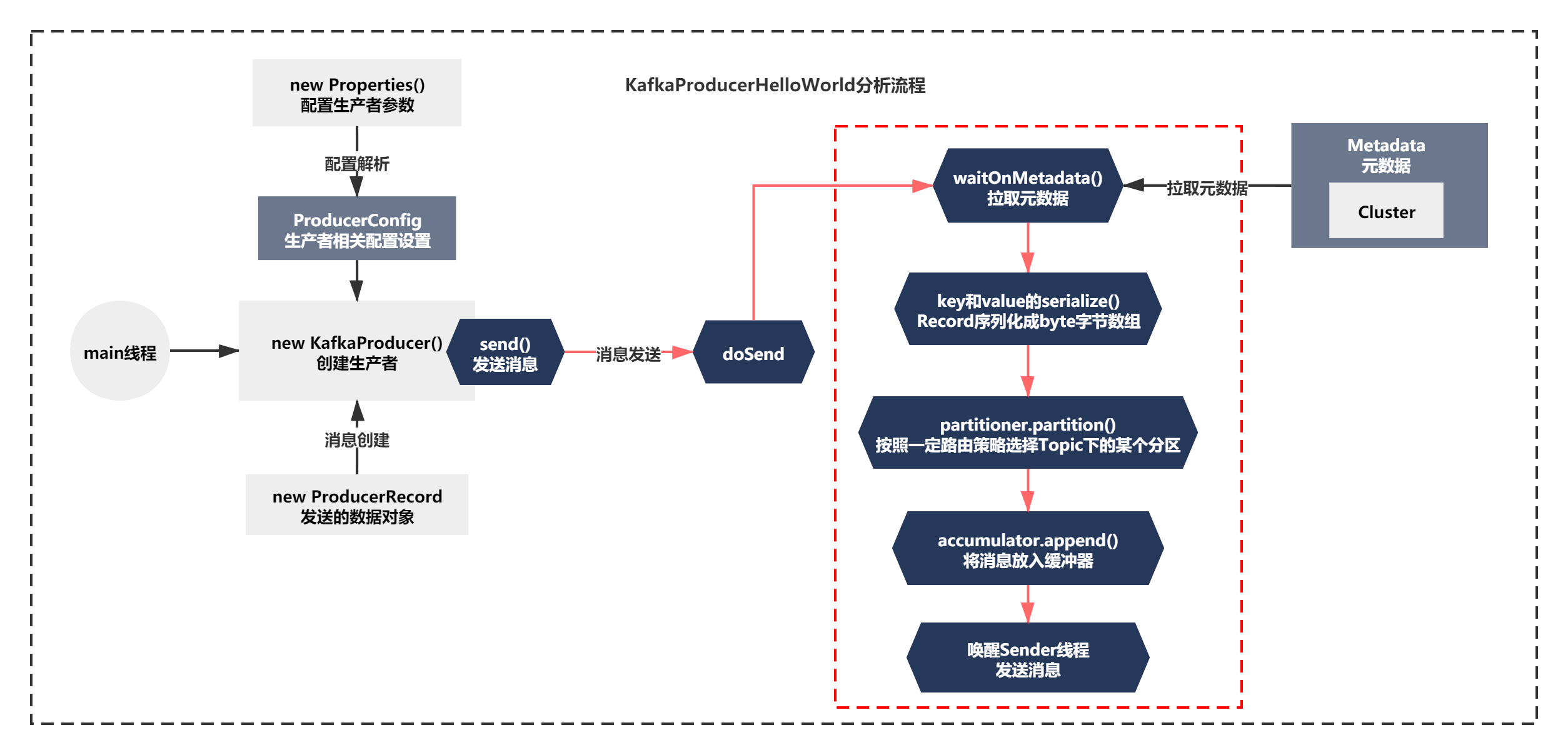
從最開始配置決議,訊息物件Record的創建,到元資料拉取、key和value的最初序列化、Product磁區路由的原理、訊息如何放入記憶體緩沖區的原理,
之前我們已經分析到了圖中紅線的部分的結尾了—喚醒Sender執行緒發送訊息,
這一節我們就繼續分析,訊息放入了記憶體緩沖中之后,觸發喚醒Sender執行緒,之后Sender執行緒如何將打包好Batch發送出去的,
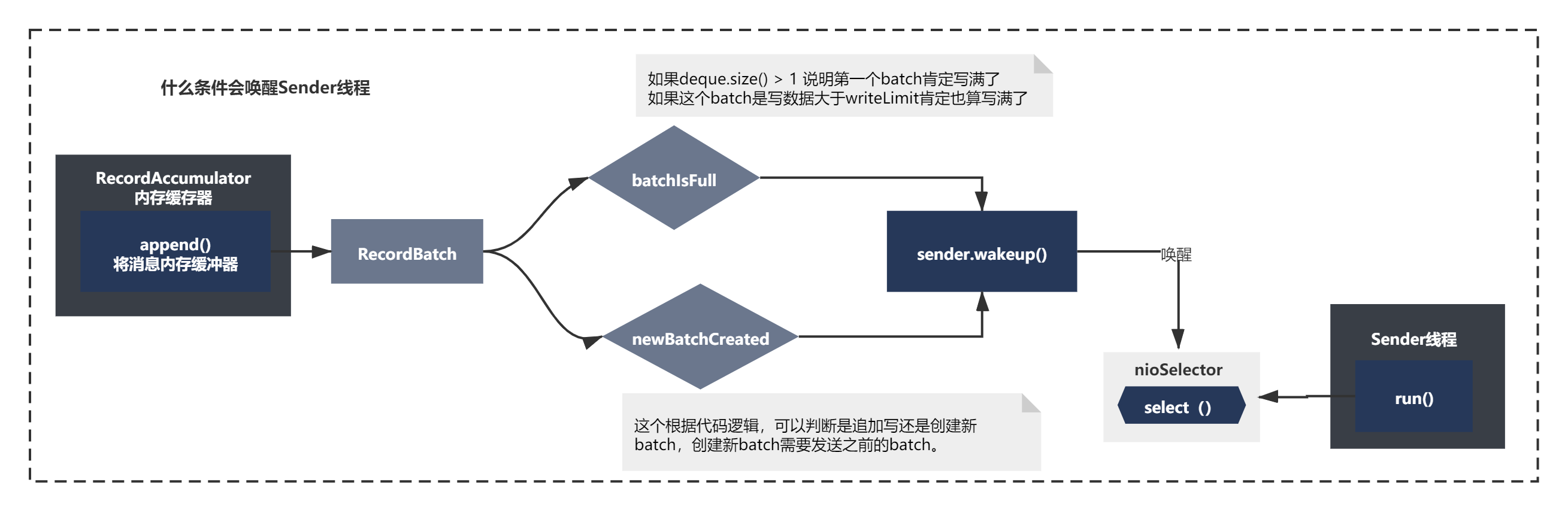
什么條件會喚醒Sender執行緒
從上面的流程圖可以看到,在producer.send()執行doSend()的時候,accumulator.append()將訊息記憶體緩沖器之后,會喚醒Sender執行緒,
那我們來看下RecordBatch放入緩沖器后,什么條件會喚醒Sender執行緒呢?
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// 1.waitOnMetadata 等待元資料拉取
// 2.keySerializer.serialize和valueSerializer.serialize,很明顯就是將Record序列化成byte位元組陣列
// 3.通過partition進行路由磁區,按照一定路由策略選擇Topic下的某個磁區
//省略代碼...
// 4.accumulator.append將訊息放入緩沖器中
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
//5.喚醒Sender執行緒的selector.select()的阻塞,開始處理記憶體緩沖器中的資料,
this.sender.wakeup();
}
return result.future;
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (Exception e) {
throw e;
}
//省略其他各種例外捕獲
}
從上面代碼,可以很清楚的看到,喚醒sender執行緒的邏輯很簡單,就是當前Batch已經寫滿,或者是新的batch創建了,
result.batchIsFull || result.newBatchCreated
那么這兩變數什么時候設定的呢?
在上一節中RecordBatch.tryAppned是創建新的batch,而RecordAccumulator.tryAppend()主要是追加寫batch,他們會設定batchIsFull和newBatchCreated的標記,表示是新創建還是寫滿的batch,
主要代碼如下:
new RecordAppendResult(future, deque.size() > 1 || last.records.isFull(), false);
new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true)
public final static class RecordAppendResult {
public final FutureRecordMetadata future;
public final boolean batchIsFull;
public final boolean newBatchCreated;
public RecordAppendResult(FutureRecordMetadata future, boolean batchIsFull, boolean newBatchCreated) {
this.future = future;
this.batchIsFull = batchIsFull;
this.newBatchCreated = newBatchCreated;
}
}
public boolean isFull() {
return !this.writable || this.writeLimit <= this.compressor.estimatedBytesWritten();
}
當滿足條件后,最侄訓觸發到sender.wakeup() 喚醒之前while回圈阻塞的Selector(),準備發送訊息,整個程序如下所示:
喚醒的Sender執行緒如何發送batch訊息的?
既然最終觸發了sender.wakeUp(),你應該知道底層觸發的就是NioSelector的wakeup,喚醒的是哪一個流程呢?我們先來回顧下,之前《Kafka成長記4 元資料拉取 下》Sender執行緒的run的主要脈絡在如下圖所示:
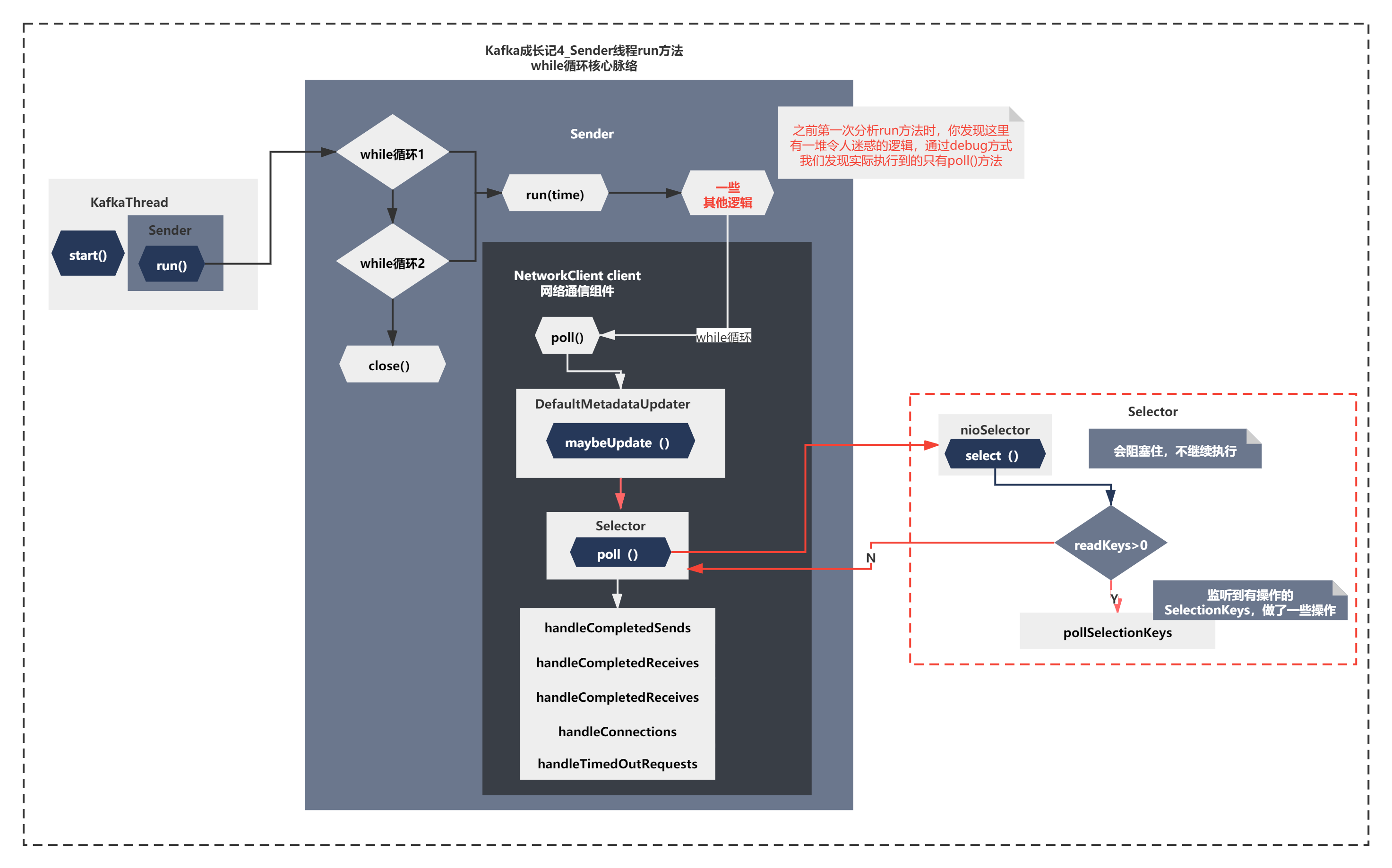
也就是之前分析拉取元資料的時候,核心就是NetworkClient.poll()的內部主要3步 maybeUpdate()-->Selector()-->hanlde(),
最終拉取元資料成功后,會再次阻塞在Selector.select()等待,而此時sender.waykeUp()就會喚醒阻塞繼續執行run方法了,
但是NetworkClient.poll()外層還有一堆令人迷惑的代碼,不知道大家記不記得?
void run(long now) {
Cluster cluster = metadata.fetch();
// get the list of partitions with data ready to send
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// if there are any partitions whose leaders are not known yet, force metadata update
if (result.unknownLeadersExist)
this.metadata.requestUpdate();
// remove any nodes we aren't ready to send to
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
// create produce requests
Map<Integer, List<RecordBatch>> batches = this.accumulator.drain(cluster,
result.readyNodes,
this.maxRequestSize,
now);
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<RecordBatch> batchList : batches.values()) {
for (RecordBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
List<RecordBatch> expiredBatches = this.accumulator.abortExpiredBatches(this.requestTimeout, now);
// update sensors
for (RecordBatch expiredBatch : expiredBatches)
this.sensors.recordErrors(expiredBatch.topicPartition.topic(), expiredBatch.recordCount);
sensors.updateProduceRequestMetrics(batches);
List<ClientRequest> requests = createProduceRequests(batches, now);
// If we have any nodes that are ready to send + have sendable data, poll with 0 timeout so this can immediately
// loop and try sending more data. Otherwise, the timeout is determined by nodes that have partitions with data
// that isn't yet sendable (e.g. lingering, backing off). Note that this specifically does not include nodes
// with sendable data that aren't ready to send since they would cause busy looping.
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (result.readyNodes.size() > 0) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
log.trace("Created {} produce requests: {}", requests.size(), requests);
pollTimeout = 0;
}
for (ClientRequest request : requests)
client.send(request, now);
// if some partitions are already ready to be sent, the select time would be 0;
// otherwise if some partition already has some data accumulated but not ready yet,
// the select time will be the time difference between now and its linger expiry time;
// otherwise the select time will be the time difference between now and the metadata expiry time;
this.client.poll(pollTimeout, now);
}
之前第一次分析run方法時,你發現這里有一堆令人迷惑的邏輯,通過debug方式我們發現實際執行到的最后一行只有client.poll()方法,
而還有一堆之前的一對令人迷惑的邏輯:
accumulator.ready()、client.ready(node, now)
accumulator.drain()
accumulator.abortExpiredBatches()
client.send(request, now)
如下所示:
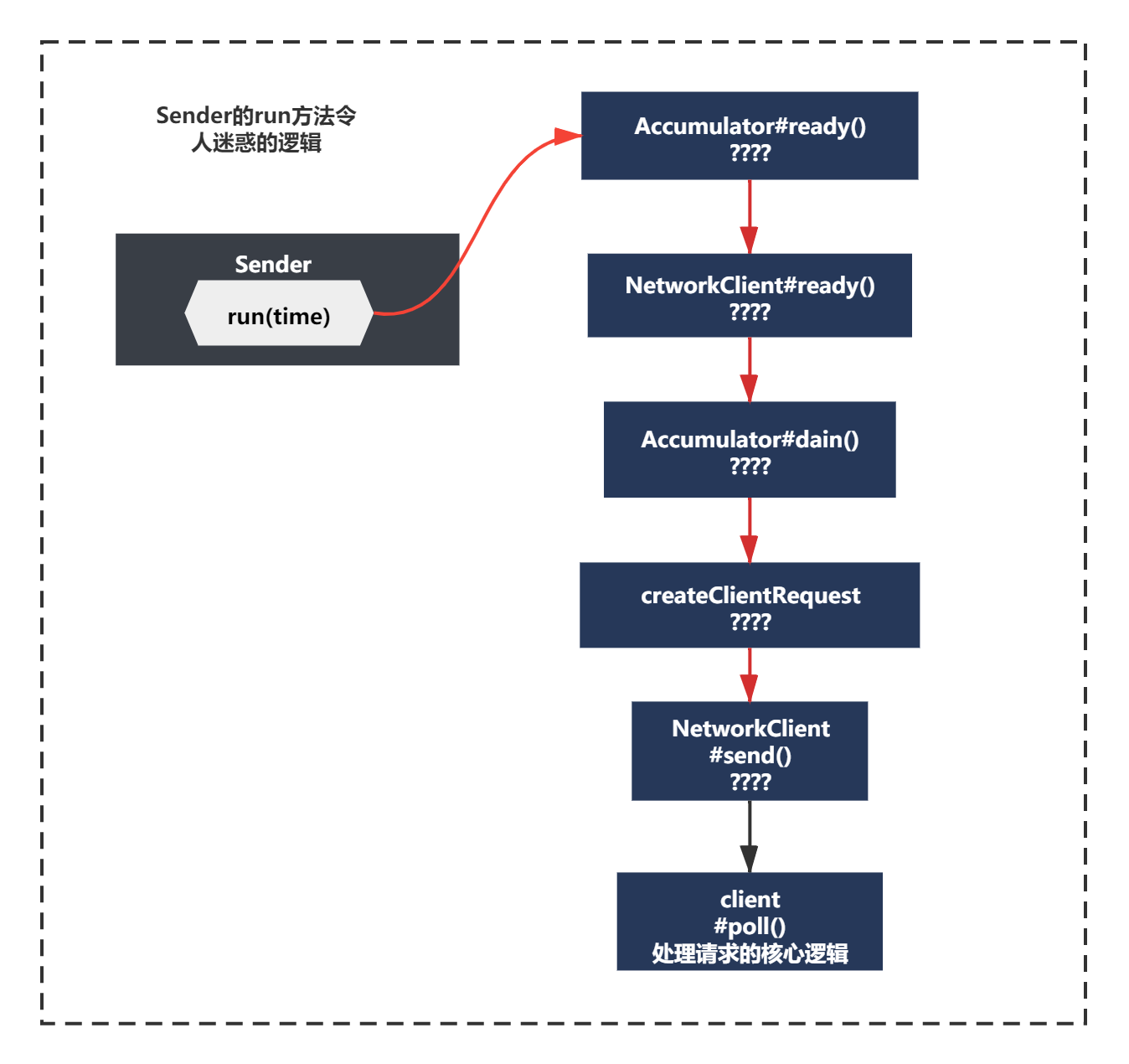
喚醒Sender之后,現在我們已經有一個batch了,這些邏輯有哪一些觸發到了呢?我們一起來看下吧,
RecordAccumulator.ready()在準備什么?
但是發送訊息前要做一些檢查,比如對應根據磁區號找到對應的Broker、Broker連接的檢查、batch超時檢查等等,
//Sender.java
run(){
// 第一次Ready
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now)
//省略...
client.poll();
}
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
Set<Node> readyNodes = new HashSet<>();
long nextReadyCheckDelayMs = Long.MAX_VALUE;
boolean unknownLeadersExist = false;
boolean exhausted = this.free.queued() > 0;
for (Map.Entry<TopicPartition, Deque<RecordBatch>> entry : this.batches.entrySet()) {
TopicPartition part = entry.getKey();
Deque<RecordBatch> deque = entry.getValue();
Node leader = cluster.leaderFor(part);
if (leader == null) {
unknownLeadersExist = true;
} else if (!readyNodes.contains(leader) && !muted.contains(part)) {
synchronized (deque) {
RecordBatch batch = deque.peekFirst();
if (batch != null) {
boolean backingOff = batch.attempts > 0 && batch.lastAttemptMs + retryBackoffMs > nowMs;
long waitedTimeMs = nowMs - batch.lastAttemptMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
boolean full = deque.size() > 1 || batch.records.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
// Note that this results in a conservative estimate since an un-sendable partition may have
// a leader that will later be found to have sendable data. However, this is good enough
// since we'll just wake up and then sleep again for the remaining time.
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeadersExist);
}
可以看到發送訊息前的Accumulator.ready()主要的脈絡就是:
通過遍歷記憶體緩沖器中batches的這個記憶體集合,經過以一些判斷,決定batch是否可以被發送,
1)第一個判斷就是要發送磁區的batchs對應的Broker必須存在,
2)如果leader存在,則計算一些條件,比如 :
backingOff,發送這個batch的時間 + 重試間隔的時間,是否大于了當前時間,默認是間隔是100ms,一般attempts是0,不重試,但是如果attempts>0,則重試時,過了間隔時間才可以發送batch,
waitedTimeMs 表示當前時間減去這個Batch被創建出來的那個時間,這個Batch從創建開始到現在已經等待了多久了
timeToWaitMs 這個Batch從創建開始算起,最多等待多久就必須去發送,如果重試階段,這個時間就是重試間隔,但是在非重試的初始階段,就是linger.ms的時間(100ms),就是到了100ms這個batch必須發送出去,
full 表示Batch是否已滿,如果說Dequeue里超過一個Batch了,說明這個peekFirst回傳的Batch就一定是已經滿的,另外就是如果假設Dequeue里只有一個Batch,但是判斷發現這個Batch達到了16kb的大小,也是已滿的
expired 當前Batch已經等待的時間(120ms) >= Batch最多只能等待的時間(100ms),已經超出了linger.ms的時間范圍了,否則呢,60ms < 100ms,此時就沒有過期,如果linger.ms默認是0,就意味著說,只要Batch創建出來了,在這個地方一定是expired = true
最終上面的條件組合成一個條件:
boolean sendable = full || expired || exhausted || closed || flushInProgress()
條件成立,則將準備好的ReadyCheckResult資料回傳,表明是否發送batch,并且發送到指明發送到哪一個Broker,
3)最后一點其實就是每次回圈每個TopicPartition只是取出第一個batch,進行判斷,如果一個都不滿足條件,會取所有Partition中timeLeftMs最小的時間等待發送Batch,這算是盡可能快速的發送batch的優化的吧,這個細節其實大家可以不用在刻意記住,知道大體發送邏輯就夠了,知道Kafka有一些優化和考量就夠了,
上面程序 整體如下圖所示:
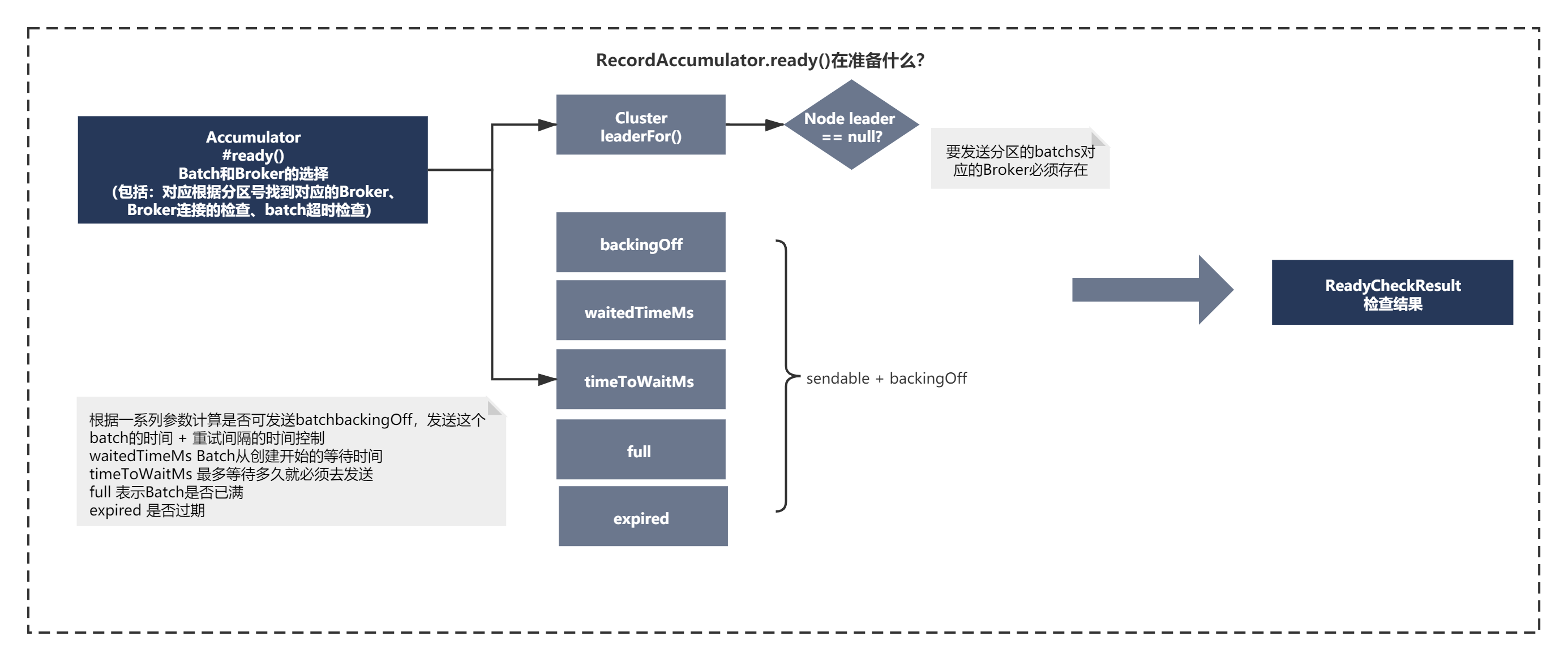
核心主要檢查了對應根據磁區號找到對應的Broker、Broker連接的檢查、batch超時檢查等資訊,
NetWorkClient.ready()在準備什么?
在run方法中,主要有兩個ready,其中一個我們已經分析過了,另一個ready是在做什么呢?
其實從名字上看,當然是在準備網路連接了,代碼如下:
//Sender.java
run(){
// 第一次Ready
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now)
//第二次ready
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
//省略...
client.poll();
}
@Override
public boolean ready(Node node, long now) {
if (node.isEmpty())
throw new IllegalArgumentException("Cannot connect to empty node " + node);
if (isReady(node, now))
return true;
if (connectionStates.canConnect(node.idString(), now))
// if we are interested in sending to a node and we don't have a connection to it, initiate one
initiateConnect(node, now);
return false;
}
public boolean isReady(Node node, long now) {
// if we need to update our metadata now declare all requests unready to make metadata requests first
// priority
return !metadataUpdater.isUpdateDue(now) && canSendRequest(node.idString());
}
private boolean canSendRequest(String node) {
return connectionStates.isConnected(node) && selector.isChannelReady(node) && inFlightRequests.canSendMore(node);
}
其實這里代碼脈絡很清晰,就是主要判斷了:
元資料是否需要拉取+網路連接Channel是否準備好+連接狀態是否已經Connected+inFlightRequests正在發送的數量有沒有超過5個(這個inFlightRequests之前拉取元資料的原理中遇見過,每次通過NIO發送的請求,如果沒有收到回應,inFlightRequests這里會記錄正在發送的請求)
如果上述都準備好了,就可以發送batch了,如果沒有準備好,該需要拉取元資料就拉取,該需要建立broker連接就建立,這個就沒什么好說的了,
經過兩次ready執行,Sender的run()方法執行如下圖:
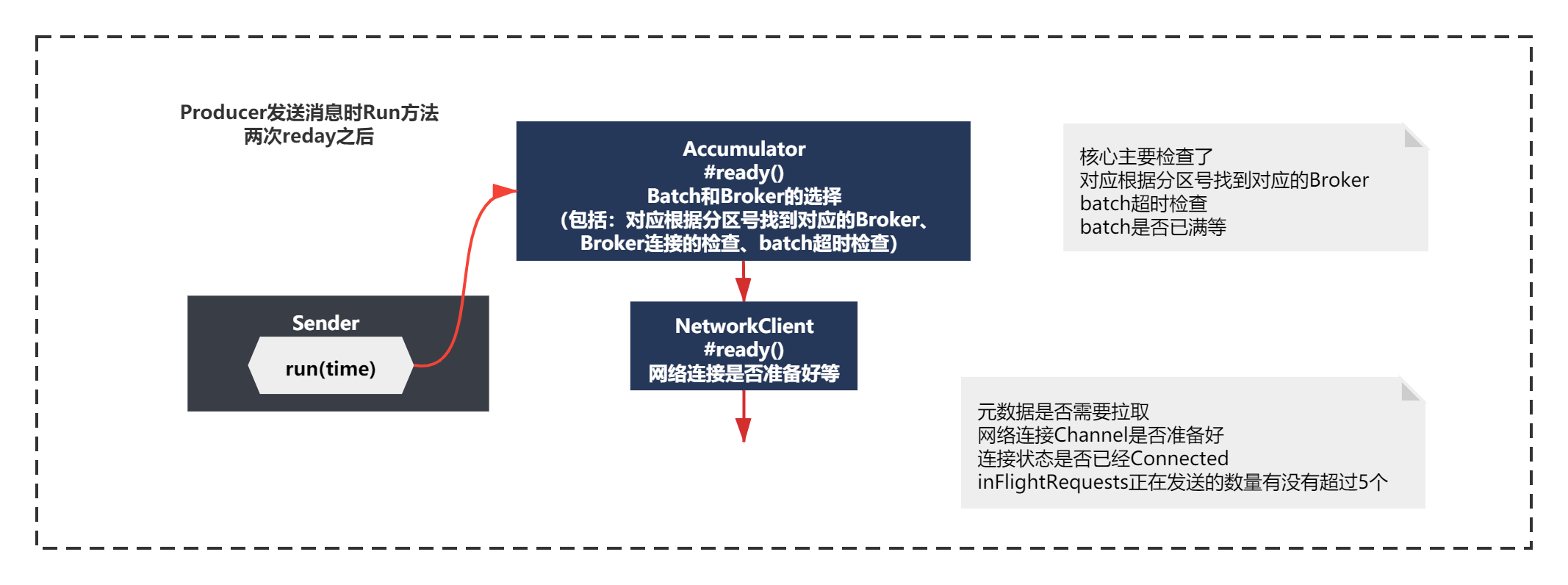
請求的準備Accumulator.drain()和ClientRequest創建
執行完兩次ready,在之后就是Accumulator.drain()方法了,drain方法其實邏輯從注釋上就能明顯看出來,
//Sender.java
run(){
// 第一次Ready accumulator.ready(cluster, now)
//第二次Ready networkclient.ready
// 請求的匯集 Accumulator.drain
Map<Integer, List<RecordBatch>> batches =
this.accumulator.drain(cluster,result.readyNodes,this.maxRequestSize,now);
//省略...
client.poll();
}
/**
* Drain all the data for the given nodes and collate them into a list of batches that will fit within the specified
* size on a per-node basis. This method attempts to avoid choosing the same topic-node over and over.
*
* @param cluster The current cluster metadata
* @param nodes The list of node to drain
* @param maxSize The maximum number of bytes to drain
* @param now The current unix time in milliseconds
* @return A list of {@link RecordBatch} for each node specified with total size less than the requested maxSize.
*/
public Map<Integer, List<RecordBatch>> drain(Cluster cluster,
Set<Node> nodes,
int maxSize,
long now) {
if (nodes.isEmpty())
return Collections.emptyMap();
Map<Integer, List<RecordBatch>> batches = new HashMap<>();
for (Node node : nodes) {
int size = 0;
List<PartitionInfo> parts = cluster.partitionsForNode(node.id());
List<RecordBatch> ready = new ArrayList<>();
/* to make starvation less likely this loop doesn't start at 0 */
int start = drainIndex = drainIndex % parts.size();
do {
PartitionInfo part = parts.get(drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
// Only proceed if the partition has no in-flight batches.
if (!muted.contains(tp)) {
Deque<RecordBatch> deque = getDeque(new TopicPartition(part.topic(), part.partition()));
if (deque != null) {
synchronized (deque) {
RecordBatch first = deque.peekFirst();
if (first != null) {
boolean backoff = first.attempts > 0 && first.lastAttemptMs + retryBackoffMs > now;
// Only drain the batch if it is not during backoff period.
if (!backoff) {
if (size + first.records.sizeInBytes() > maxSize && !ready.isEmpty()) {
// there is a rare case that a single batch size is larger than the request size due
// to compression; in this case we will still eventually send this batch in a single
// request
break;
} else {
RecordBatch batch = deque.pollFirst();
batch.records.close();
size += batch.records.sizeInBytes();
ready.add(batch);
batch.drainedMs = now;
}
}
}
}
}
}
this.drainIndex = (this.drainIndex + 1) % parts.size();
} while (start != drainIndex);
batches.put(node.id(), ready);
}
return batches;
}
結合注釋和整體脈絡,就是一個基于之前ready好的Node(broker)的串列的for回圈,我們可以得出如下結論:
由于默認我們是按照topic-partition的結構記錄batch訊息的,為了確認每一個Broker需要發送那些partition中的batchs訊息,需要基于Node組裝好Batchs,而不是基于topic組裝好baths,
Accumulator.drain()就是這件事的,獲取broker上所有的partition,遍歷broker上的所有的partitions,對每個partition獲取到dequeue里的first batch,放入待發送到broker的串列里,每個broker都有一個batches串列,形成一個map記錄下來,key是brokerId,value是batches串列,
整體如下圖所示:
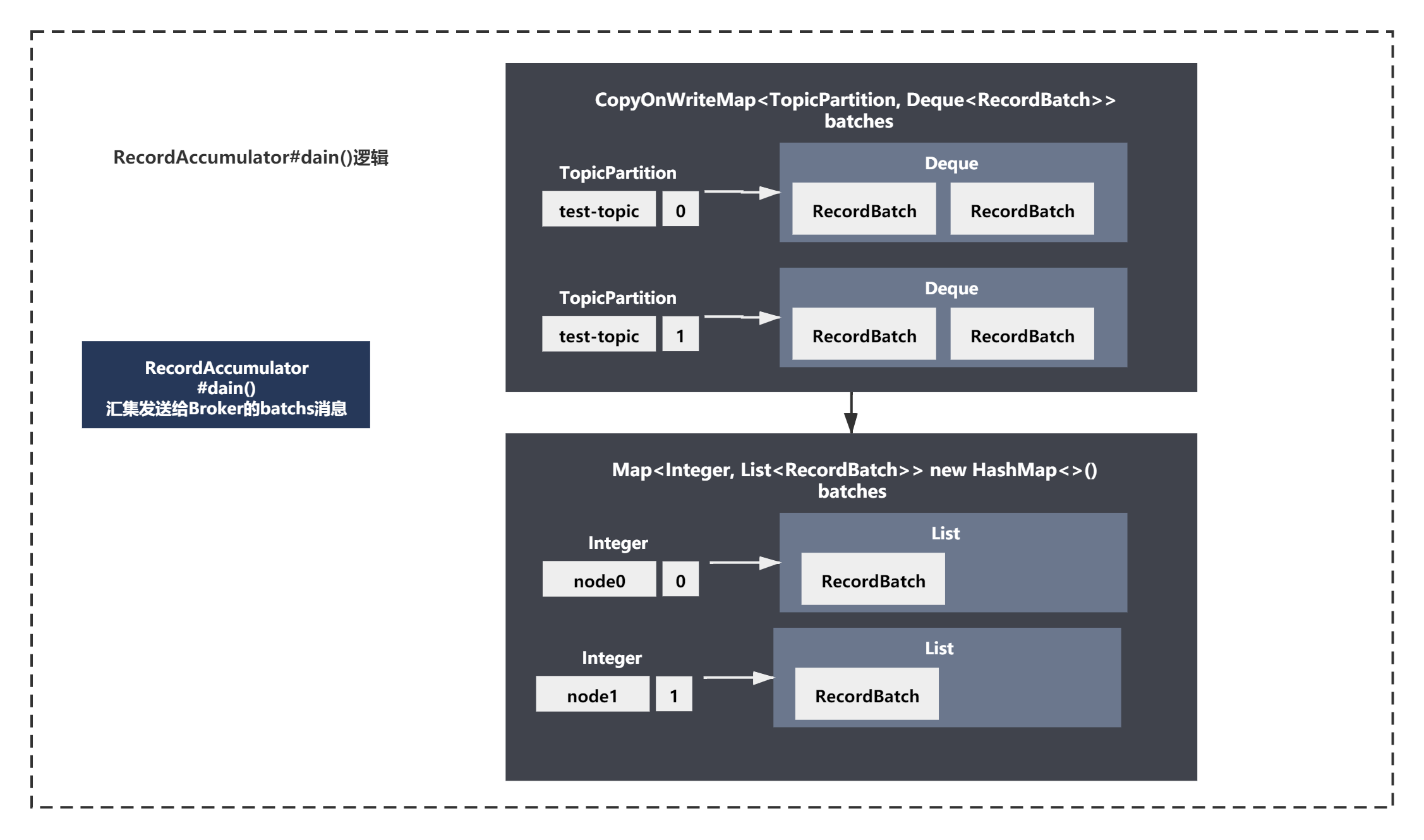
2次ready之后,drain匯集資料之后,主要進行是batchs請求的最終構建,createClientRequest,
//Sender.java
run(){
// 2次Ready、drain之后
// createProduceRequests操作
List<ClientRequest> requests = createProduceRequests(batches, now);
//省略...
client.poll()
}
/**
* Transfer the record batches into a list of produce requests on a per-node basis
*/
private List<ClientRequest> createProduceRequests(Map<Integer, List<RecordBatch>> collated, long now) {
List<ClientRequest> requests = new ArrayList<ClientRequest>(collated.size());
for (Map.Entry<Integer, List<RecordBatch>> entry : collated.entrySet())
requests.add(produceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue()));
return requests;
}
/**
* Create a produce request from the given record batches
*/
private ClientRequest produceRequest(long now, int destination, short acks, int timeout, List<RecordBatch> batches) {
Map<TopicPartition, ByteBuffer> produceRecordsByPartition = new HashMap<TopicPartition, ByteBuffer>(batches.size());
final Map<TopicPartition, RecordBatch> recordsByPartition = new HashMap<TopicPartition, RecordBatch>(batches.size());
for (RecordBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
produceRecordsByPartition.put(tp, batch.records.buffer());
recordsByPartition.put(tp, batch);
}
ProduceRequest request = new ProduceRequest(acks, timeout, produceRecordsByPartition);
RequestSend send = new RequestSend(Integer.toString(destination),
this.client.nextRequestHeader(ApiKeys.PRODUCE),
request.toStruct());
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
return new ClientRequest(now, acks != 0, send, callback);
}
我們想要發送訊息肯定不是直接吧batchs這個List發送出去,最侄訓是要進行一個簡單封裝的,你還記拉取元資料的請求是怎么封裝的么?
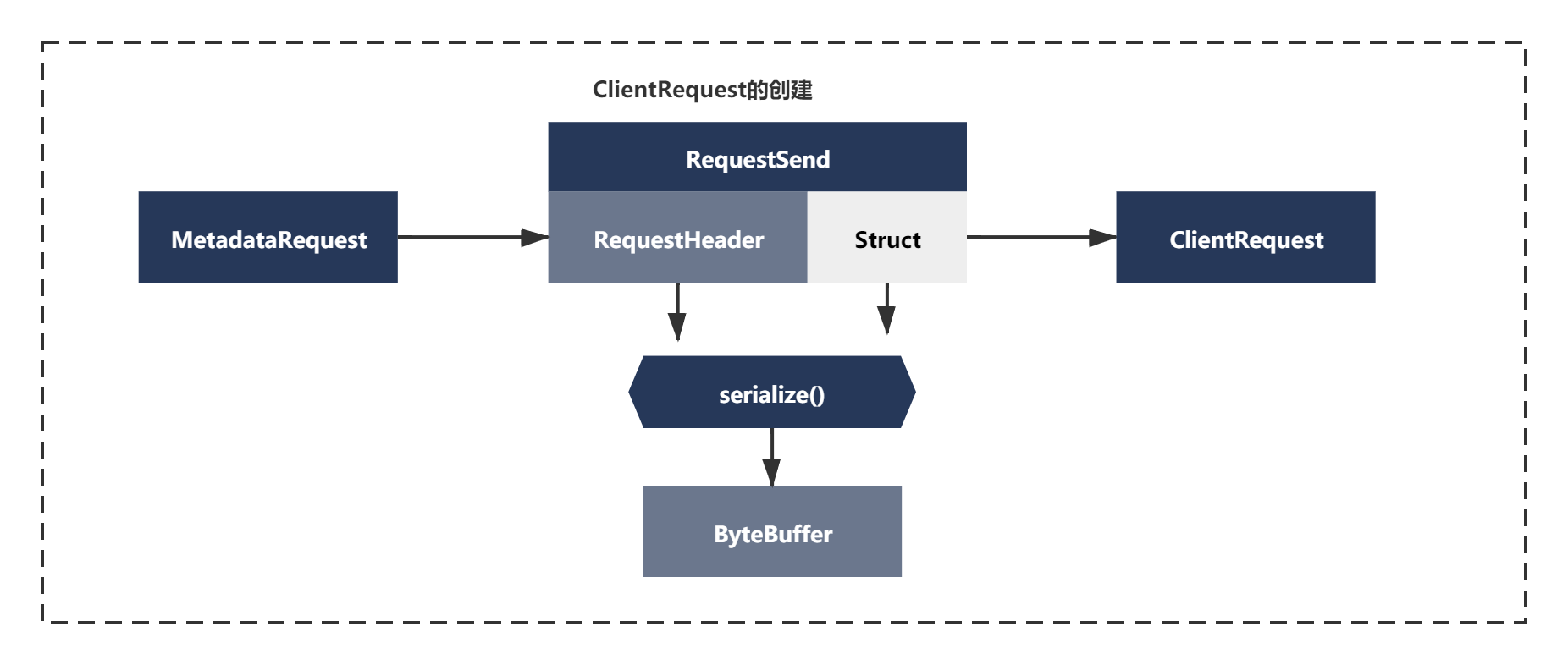
可以看到是有一套封裝請求邏輯的,同理這里發送訊息時也是類似的, 之前我們序列化好的RecordBatch訊息,本質還是ByteBuffer,這里通過一系列物件再次補充了一些新主要是額外增加了api key,api version,acks,request timeout等資料資訊,如下圖所示:
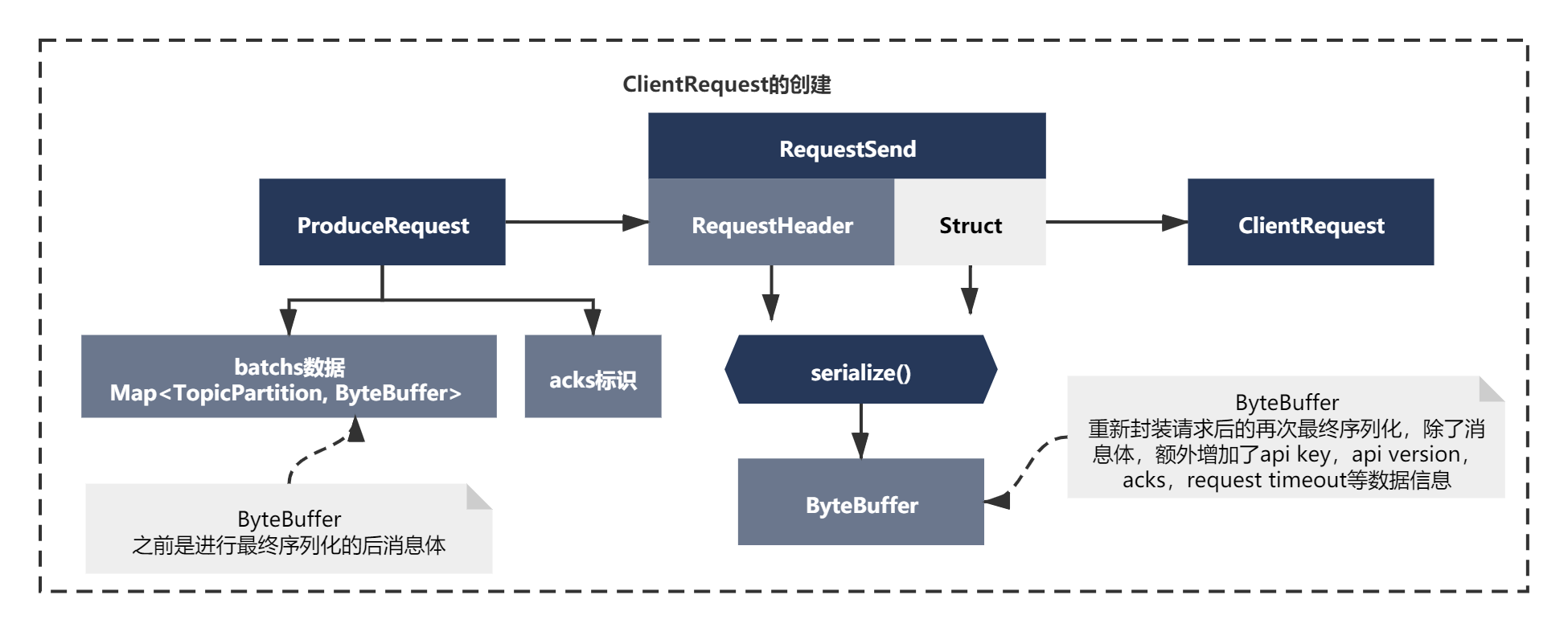
最后的準備setSend()
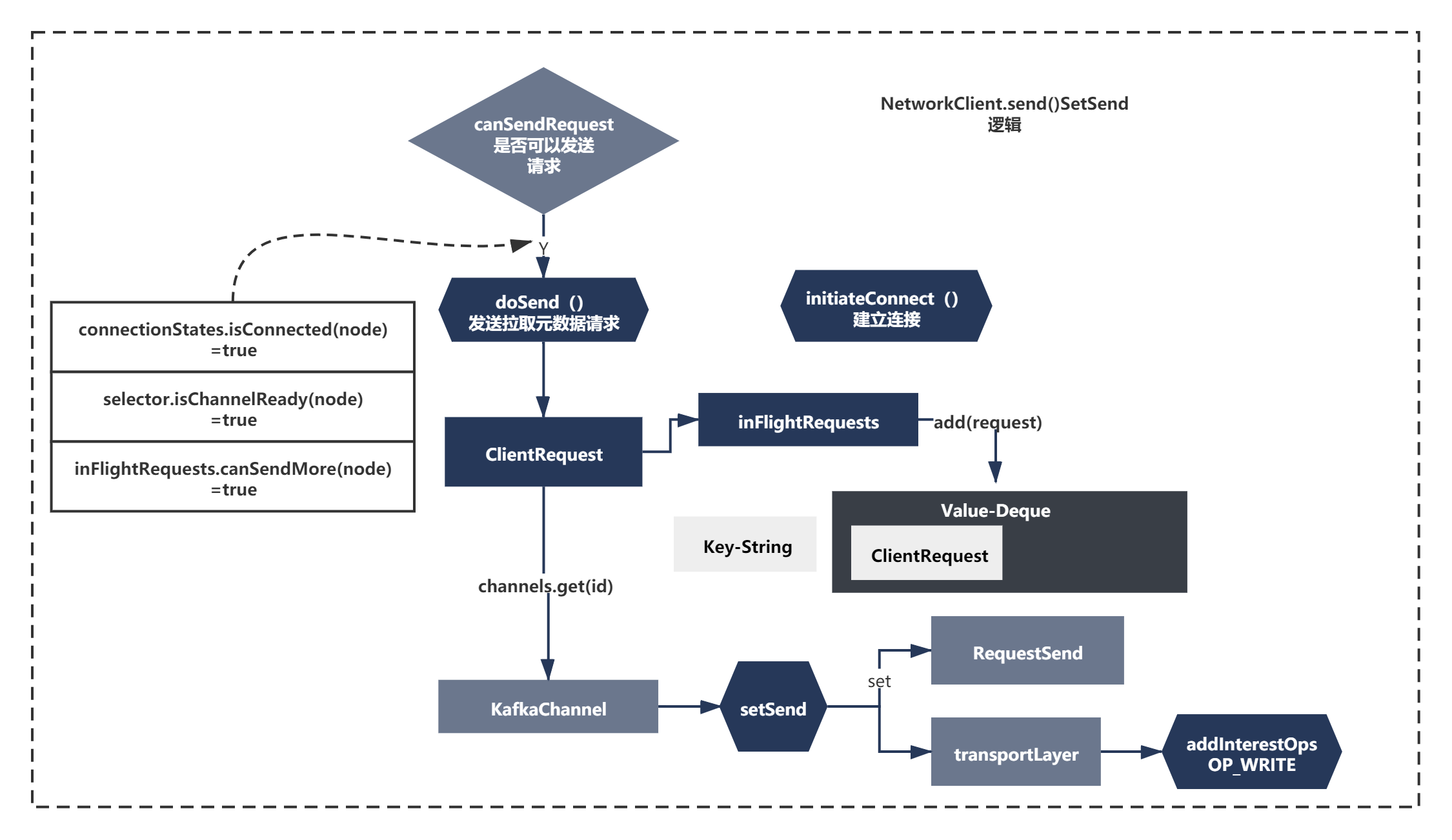
最后準備是一次setSend的操作,上面一系列準備后,連接準備好了,請求也準備好了,都ok之后,由于現在喚醒了Selector,按照NIO的通信機制,接著我們需要將SelectKey的Ops操作更新為Wirte,表示需要寫資料給Broker,接著進行write操作即可,所以這里會執行一次setSend操作,代碼主要如下:
//Sender.java
run(){
// 2次Ready、drain、createClientRequest之后
// setSend操作
for (ClientRequest request : requests)
client.send(request, now);
//省略...
client.poll();
}
public void send(ClientRequest request, long now) {
String nodeId = request.request().destination();
if (!canSendRequest(nodeId))
throw new IllegalStateException("Attempt to send a request to node " + nodeId + " which is not ready.");
doSend(request, now);
}
private void doSend(ClientRequest request, long now) {
request.setSendTimeMs(now);
this.inFlightRequests.add(request);
selector.send(request.request());
}
//org.apache.kafka.common.network.Selecotor.java
public void send(Send send) {
KafkaChannel channel = channelOrFail(send.destination());
try {
channel.setSend(send);
} catch (CancelledKeyException e) {
this.failedSends.add(send.destination());
close(channel);
}
}
// org.apache.kafka.common.network.KafkaChannel
public void setSend(Send send) {
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress.");
this.send = send;
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
這個程序和之前發送元資料拉取請求是類似的,你應該很有些熟悉,可以見《Kafka成長記4發送元資料拉取請求》,
整體如下圖所示:
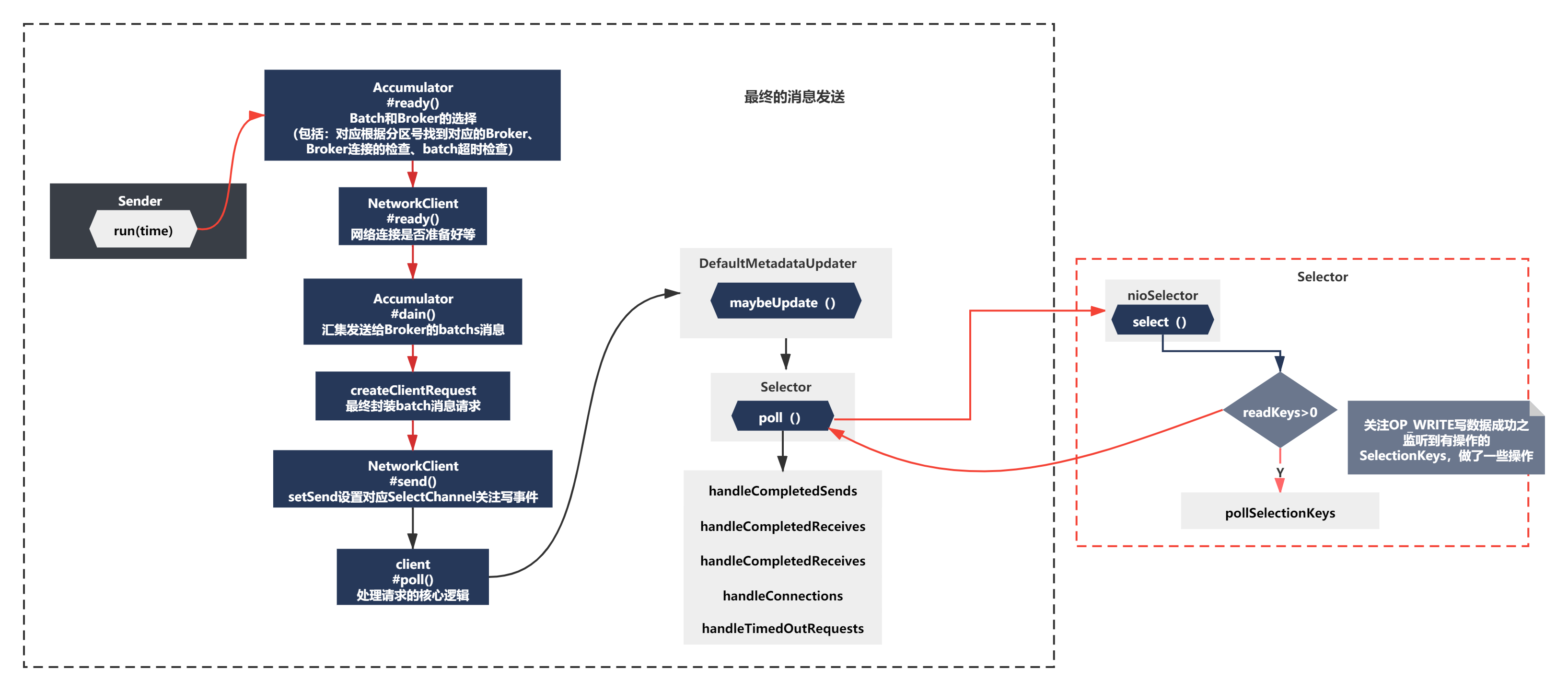
最終的訊息發送
經過前面一系列準備,2次的reday、drain、clientRequest的創建,setSend設定對應SelectChannel關注寫事件這些一系列準備都ok后,終于要執行到訊息發送了,
其實有了之前發送元資料的經驗,最終我們肯定是通過poolSelectKey->之后Handle類的方法處理的,
1)首先發送訊息的寫請求,其實就是依托inFlightRequests去暫存了正在發送的Request,通過channel.write寫資料出去,之后執行handleCompletedSend方法
2)當訊息發送成功后,取消對OP_WRITE事件的關注,會接受到回傳資訊進行handreceives方法,否則如果一個Request的資料都沒發送完畢,此時還需要保持對OP_WRITE事件的關注,關注NIO里的OP_READ事件呢key.interestOps(key.interestOps() & ~SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
(具體代碼邏輯就是在對應的handle方法,比較簡單,我就不展開帶大家看了,之后下一節講解粘包拆包的時候會再次研究這塊邏輯的)
整個程序大體如下圖所示:
小結
最后,到這里Kafka記憶體緩沖區中的訊息最終如何發送出去的就帶大家一起研究明白了,
其實之前9節內容都比較干貨,講解的比較細致,不能說算是精讀原始碼,但是肯定是Kafka的核心原始碼都摸透了,
《Kafka Producer篇》預計還有幾節就結束了
我是繁茂,我們下一節見~
本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/309385.html
標籤:Java