
上一節我們主要分析了RecordAccumulator通過BufferPool申請記憶體的原始碼原理,在之前的分析中,在KafkaProducer發送訊息時,把訊息放入記憶體緩沖區中主要分為了三步,如下:
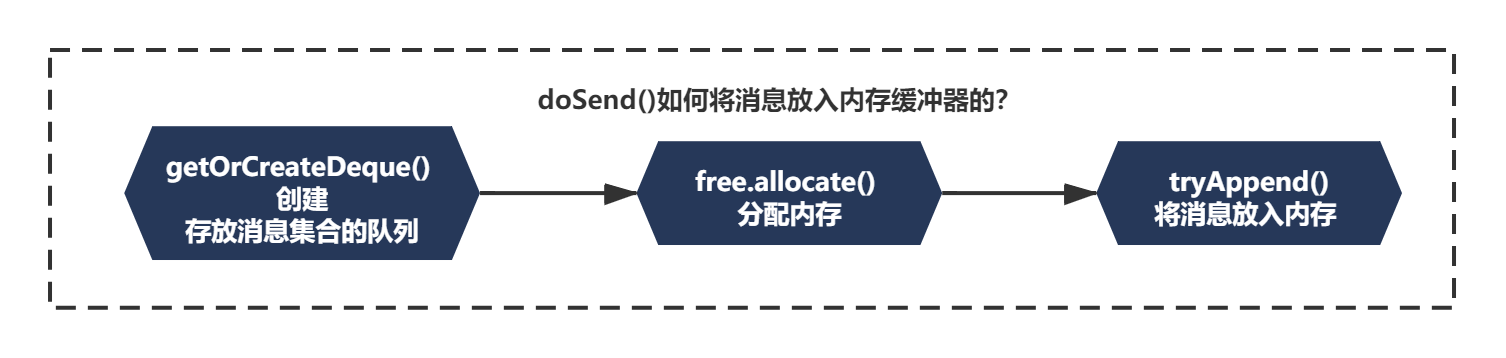
而且之前我們主要分析了前兩步的代碼,如下注釋所示:
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
// We keep track of the number of appending thread to make sure we do not miss batches in
// abortIncompleteBatches().
appendsInProgress.incrementAndGet();
try {
// check if we have an in-progress batch
// 1、創建存放訊息的記憶體結果 本質是一個map集合,內部主要是雙端佇列 (已分析)
Deque<RecordBatch> dq = getOrCreateDeque(tp);
//這段tryAppend代碼發第一條訊息的時候不會執行,暫時沒有分析
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null)
return appendResult;
}
//2、BufferPool申請記憶體塊邏輯 (已分析)
// we don't have an in-progress record batch try to allocate a new batch
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
//3、將訊息封裝到記憶體塊中,放入之前準備的記憶體結構 (待分析)
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
free.deallocate(buffer);
return appendResult;
}
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
之前分析的邏輯,可以概括如下圖所示:
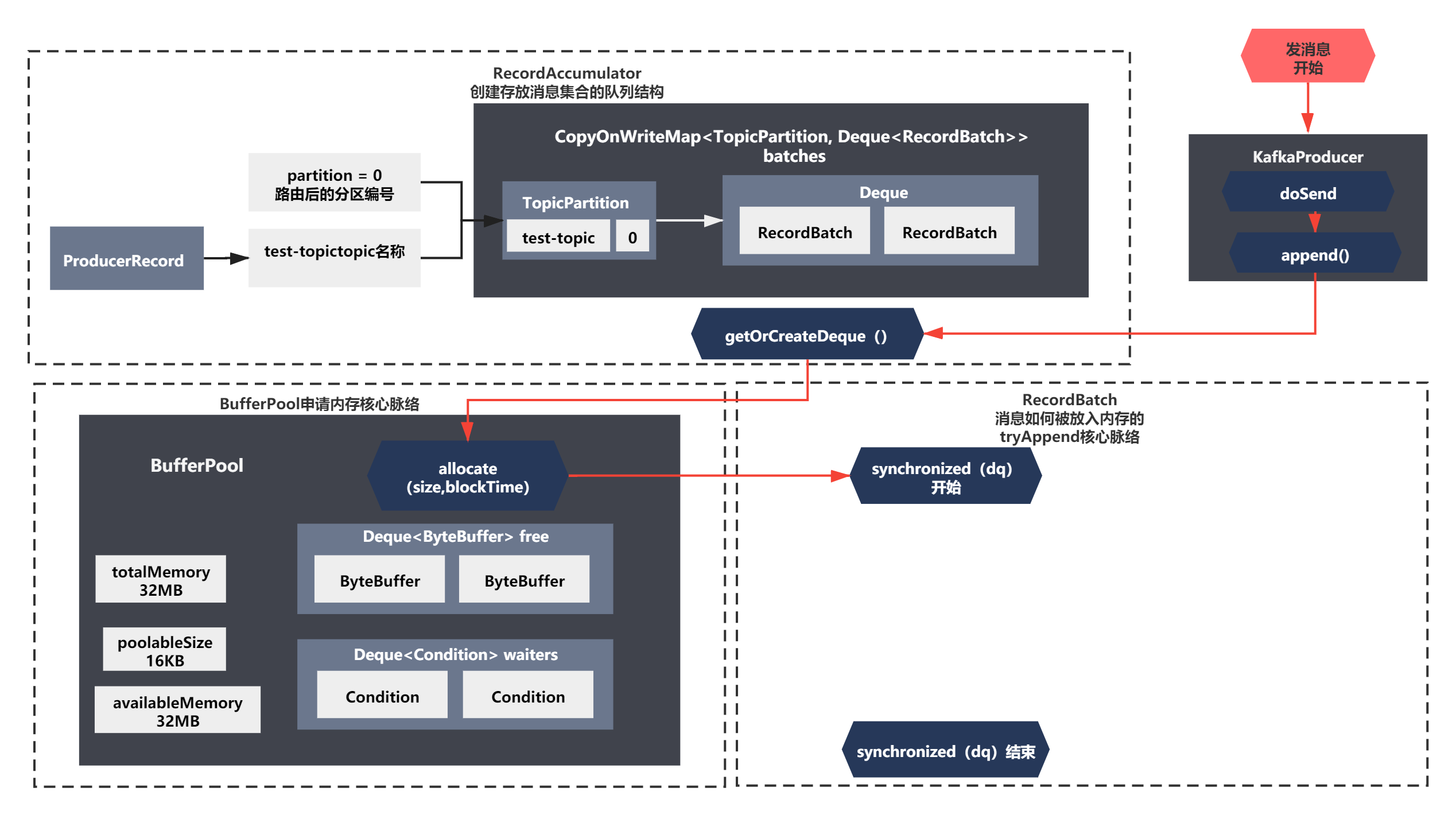
這一節我們繼續來分析將訊息放入緩沖區的最后一步—tryAppend的邏輯,讓我們一起來看下吧!
tryAppend的核心脈絡
首先我們肯定要初步摸一下第三步代碼主要在做什么,它的邏輯主要如下:
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
free.deallocate(buffer);
return appendResult;
}
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
可以看到上面的代碼主要脈絡:
1)執行了一段tryAppend() 如果回傳appendResult非空,則進行了一個釋放BufferPool記憶體塊的邏輯,否則什么都不做,這個之前第一步 getOrCreateDeque后面的邏輯很像,應該是同樣的邏輯,
2)創建了 MemoryRecords和RecordBatch這兩個關鍵的物件,應該是通過這兩個物件,把Buffer這個記憶體塊和訊息一起進行了封裝
3)之后執行了Recordbatch.tryAppend方法,又一個tryAppend,還是異步的一個Feature,應該也是某種追加邏輯,
4)最后就是將RecordBatch這個batch物件放入了2個記憶體結構了,dp就是之前的雙端佇列,incomplete是一個RecordBatch的Set集合,從名字上看是正在處理中或者未完成發送的RecordBatch的意思
整個脈絡補充到上面的圖中,如下所示:
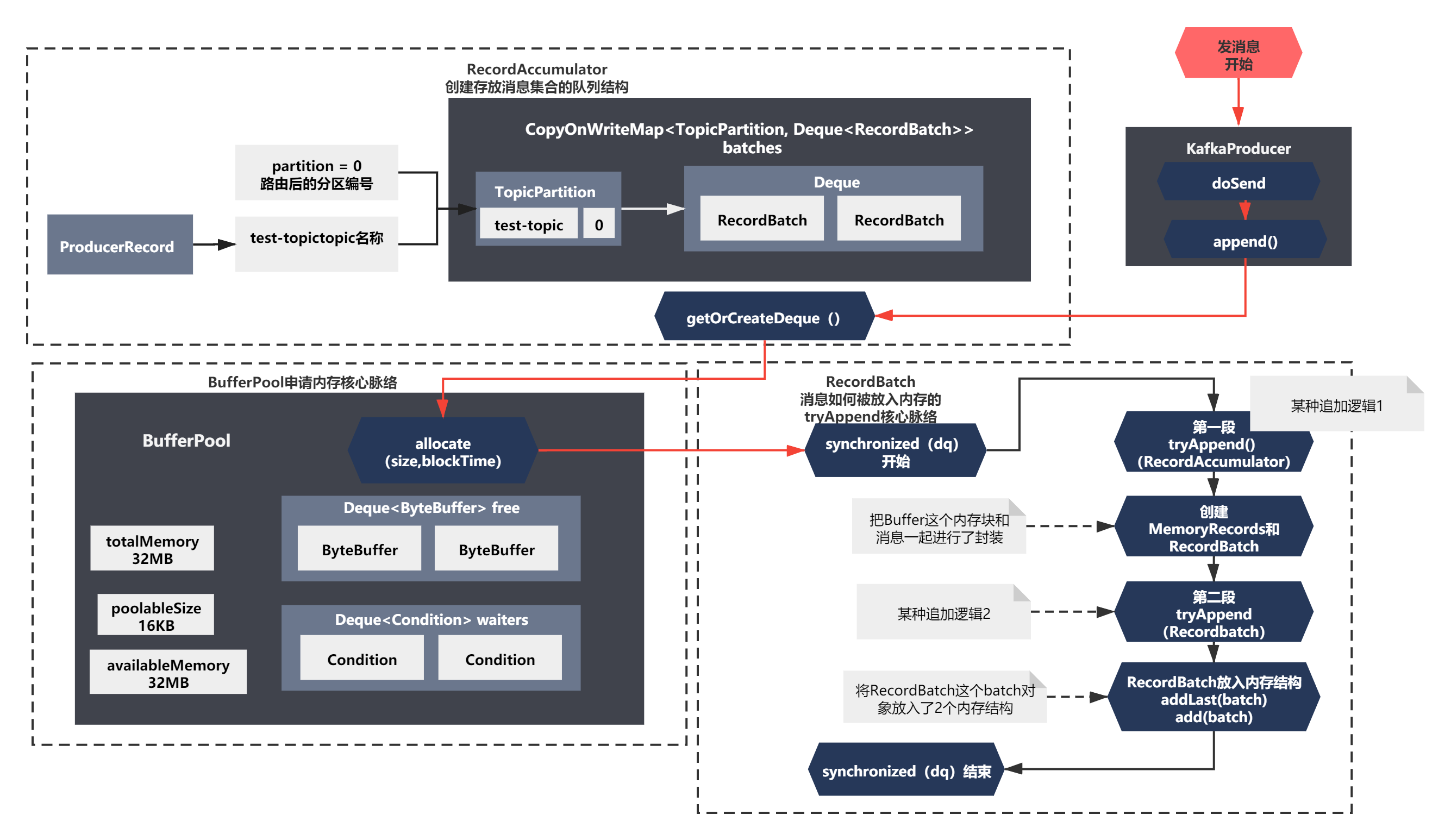
既然知道了這個核心脈絡,我們一步一步來分析下就好,
兩段tryAppend()到底在干什么?
在上面核心脈絡中,有兩段TryAppend邏輯,首先我們來看下tryAppend()在做什么,
//RecordAccumulator.java
synchronized (dq) {
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
free.deallocate(buffer);
return appendResult;
}
}
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, Deque<RecordBatch> deque) {
RecordBatch last = deque.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future == null)
last.records.close();
else
return new RecordAppendResult(future, deque.size() > 1 || last.records.isFull(), false);
}
return null;
}
// RecordBatch.tryAppend()
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, long now) {
if (!this.records.hasRoomFor(key, value)) {
return null;
} else {
long checksum = this.records.append(offsetCounter++, timestamp, key, value);
this.maxRecordSize = Math.max(this.maxRecordSize, Record.recordSize(key, value));
this.lastAppendTime = now;
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value =https://www.cnblogs.com/fanmao/p/= null ? -1 : value.length);
if (callback != null)
thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}
//MemoryRecords.java append方法
public long append(long offset, long timestamp, byte[] key, byte[] value) {
if (!writable)
throw new IllegalStateException("Memory records is not writable");
int size = Record.recordSize(key, value);
compressor.putLong(offset);
compressor.putInt(size);
long crc = compressor.putRecord(timestamp, key, value);
compressor.recordWritten(size + Records.LOG_OVERHEAD);
return crc;
}
這段邏輯其實比較不好理解,內部呼叫了兩個不同類的tryAppend(),我起初看這塊的時候,都沒理解它在干什么,
為什么這里加了synchronized (dq)?
從這個佇列中deque.peekLast()是在干嗎?
為啥又執行了last.tryAppend?
......
反正有各種問題,各種不理解,我們看原始碼經常會遇到這種情況,這個時候怎么辦呢?
其實就是一個辦法:嘗試,
嘗試各種方法,比如看看注釋、比如能不能debug、比如能不能舉例子、比如畫圖、比如能不能搜搜帖子看看有人研究過這塊邏輯么,或者你可能就是自己非要死磕硬鋼,不斷重復閱讀邏輯,聚焦這里,仔細思考、研究這這塊邏輯核心目的是什么.....
總之,就這樣不斷重復嘗試,鉆研,不放棄,你就會慢慢理解晦澀的知識點,
就像有句老話說:”只要思想不滑坡,辦法總比困難多,“ 意思就是對技術有興趣,保持心態好,不抱怨,不煩躁,慢慢來,不斷研究和嘗試各種方法,總會解決困難的,其實這個就是許多人的差異所在,也正是每個人需要成長的地方,
而這塊邏輯經過我不斷研究和思考后,發現邏輯并不復雜,下面我舉幾個例子來幫助大家理解這段邏輯,
場景是這樣的,Producer有一個執行緒1,不斷發送總大小為3KB的訊息Record,連續發送了6條,我們來看下它的流程是怎么樣的呢?
首先執行緒1第1次發送訊息的話,按照上面的核心脈絡,執行程序如下所示:
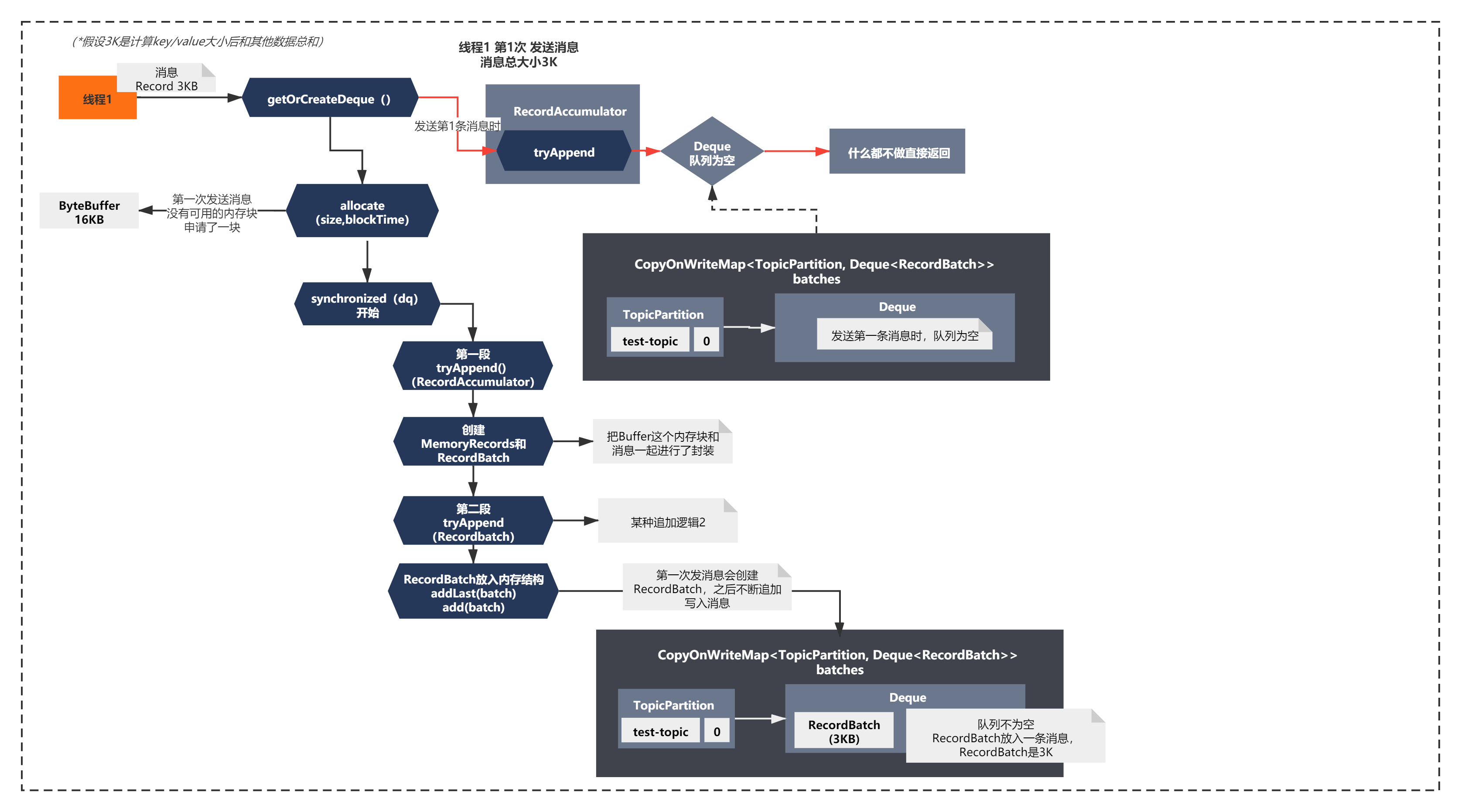
從圖中可以清晰的看到執行緒1第1次發送訊息時候,創建了一個記憶體塊ByteBuffer,之后將訊息進行了封裝處理,寫入到了RecordBatch,最后將RecordBatch放入佇列中,(可以對應上面的代碼來理解)
通過畫圖,我們可以梳理思路,串起來整個流程整個方法在你困惑的時候非常有用,
接這執行緒1繼續發送訊息,發送第2-5條訊息,流程則會發生一些改變,如下圖所示:
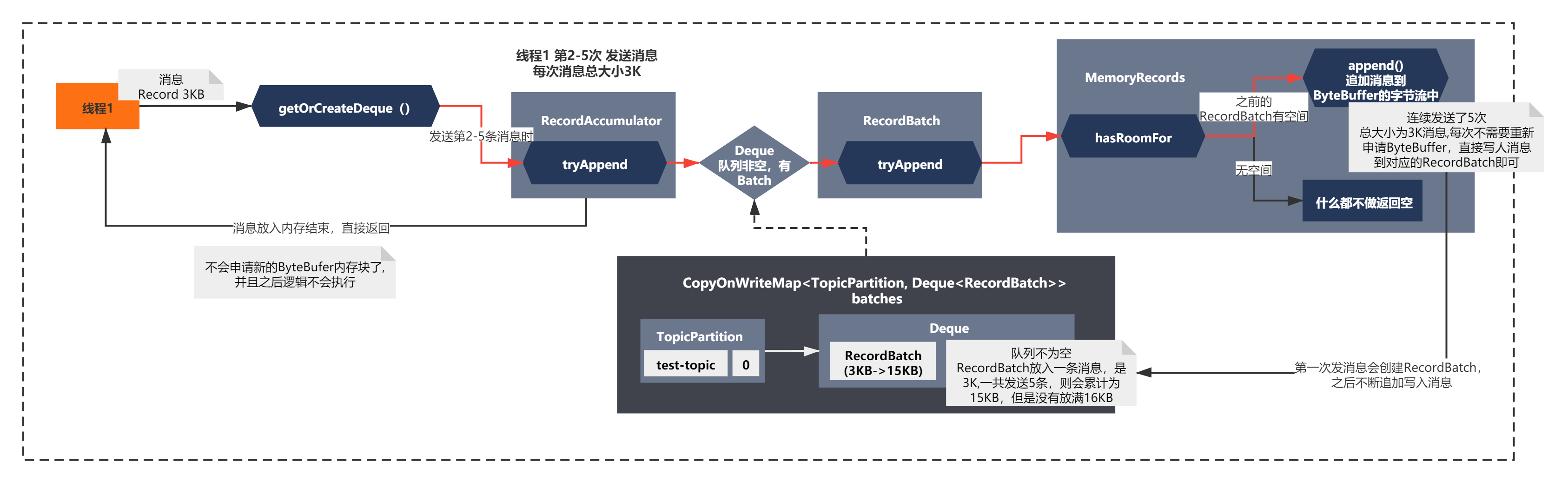
在發送第2-5條訊息時,可以發現不會申請新的ByteBuffer,直接向現有的的RecordBatch寫入訊息,通過MemoryRecords追加訊息到ByteBuffer的位元組流中,最終RecordBatch的大小為15KB,(可以對應上面的代碼來理解)
接著執行緒1發送第6條訊息時,流程又會發生新的變化,整體如下圖所示:
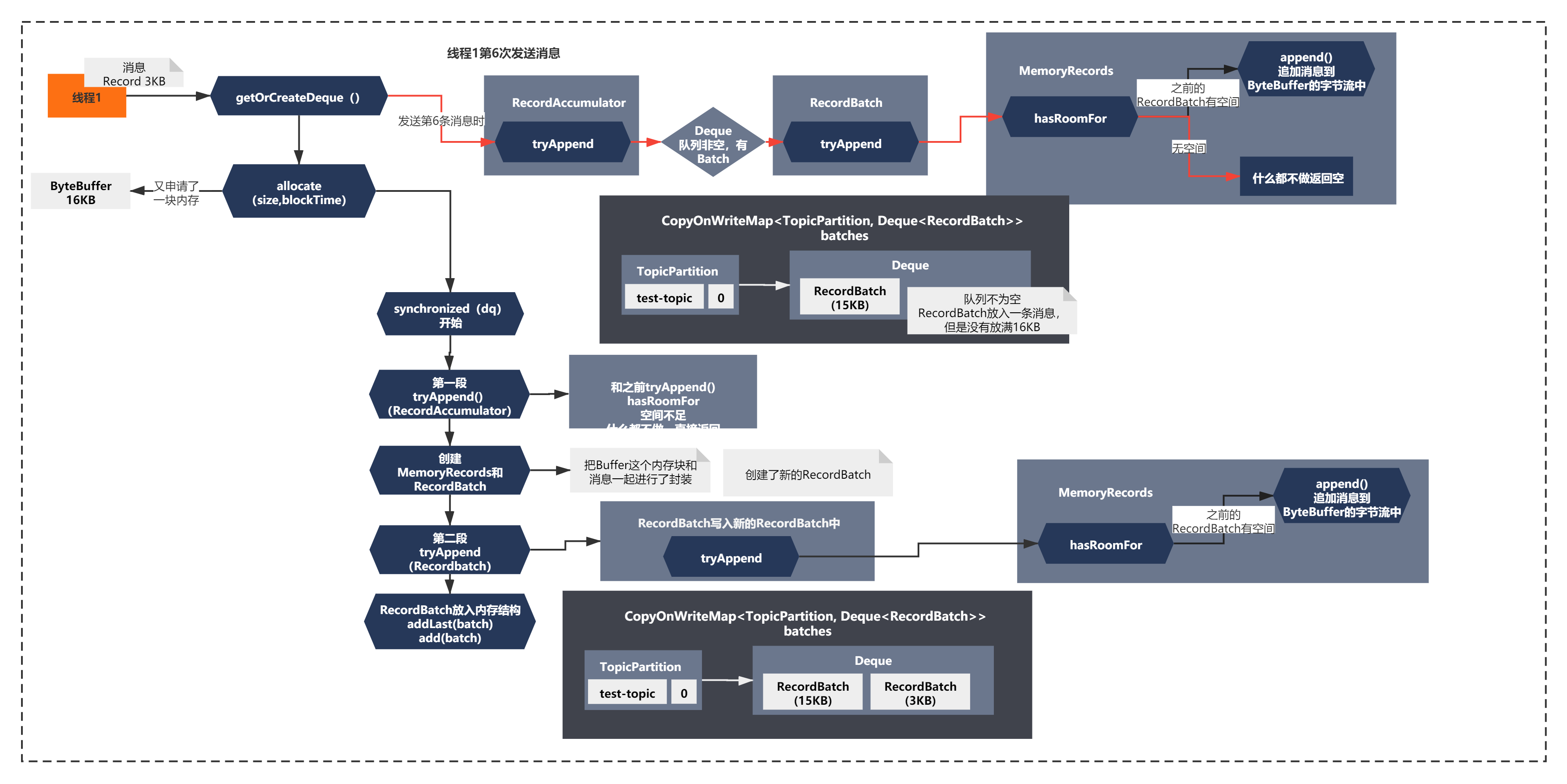
在發送第6條訊息時,又申請了一塊記憶體塊和創建了新的RecordBatch,之后由于第一個Batch寫滿了,會將訊息寫入第二個Batch,并放入佇列中,(可以對應上面的代碼來理解)
通過上面的例子,你可以發現KafkaProducer整個發送訊息的程序是一個打包發送的程序,會將訊息一條一條打成一個16KB的batch,放入佇列,之后發送出去,
這種微打包邏輯很多中間件和框架,甚至業務系統中都可以借鑒,你可以發散下思維想想是不是?
其實這里還有很多思考點:
比如單條訊息如果超過16KB會怎么樣?提示:ByteBuffer不會被復用,直接會生成一個大的RecordBatch,
每個Batch為什么會生成一個異步feature,放入List
synchronized加鎖的目的什么?提示:肯定是考慮多執行緒發送訊息的場景的,
這些留給大家去思考和練習下,大家可以在評論區留下你的回答,或者在之后的我建立微信群后討論下,
Record訊息的進一步封裝和序列化
分析完兩段tryAppend()到底在干什么之后,其實整個tryAppend的核心脈絡就剩下一段邏輯了,
如何創建了 MemoryRecords和RecordBatch這兩個關鍵的物件,并通過這兩個物件,把ByteBuffer這個記憶體塊和訊息一起進行了封裝的呢?
讓我們來看下代碼:
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
//MemoryRecords.java
private MemoryRecords(ByteBuffer buffer, CompressionType type, boolean writable, int writeLimit) {
this.writable = writable;
this.writeLimit = writeLimit;
this.initialCapacity = buffer.capacity();
if (this.writable) {
this.buffer = null;
this.compressor = new Compressor(buffer, type);
} else {
this.buffer = buffer;
this.compressor = null;
}
}
//Compressor.java
public Compressor(ByteBuffer buffer, CompressionType type) {
this.type = type;
this.initPos = buffer.position();
this.numRecords = 0;
this.writtenUncompressed = 0;
this.compressionRate = 1;
this.maxTimestamp = Record.NO_TIMESTAMP;
if (type != CompressionType.NONE) {
// for compressed records, leave space for the header and the shallow message metadata
// and move the starting position to the value payload offset
buffer.position(initPos + Records.LOG_OVERHEAD + Record.RECORD_OVERHEAD);
}
// create the stream
bufferStream = new ByteBufferOutputStream(buffer);
appendStream = wrapForOutput(bufferStream, type, COMPRESSION_DEFAULT_BUFFER_SIZE);
}
//RecordBatch.java
public RecordBatch(TopicPartition tp, MemoryRecords records, long now) {
this.createdMs = now;
this.lastAttemptMs = now;
this.records = records;
this.topicPartition = tp;
this.produceFuture = new ProduceRequestResult();
this.thunks = new ArrayList<Thunk>();
this.lastAppendTime = createdMs;
this.retry = false;
}
其實可以看到,基本就是初始化RecordBatch和MemoryRecords內部資料結構,核心通過一個組件Compressor操作ByteBuffer,將訊息訊息的key和Value之后寫入到一個outPutStream流中,
至于具體如何寫入的,其實是在之后MemoryRecords.append()中
public long append(long offset, long timestamp, byte[] key, byte[] value) {
if (!writable)
throw new IllegalStateException("Memory records is not writable");
int size = Record.recordSize(key, value);
compressor.putLong(offset);
compressor.putInt(size);
long crc = compressor.putRecord(timestamp, key, value);
compressor.recordWritten(size + Records.LOG_OVERHEAD);
return crc;
}
public static int recordSize(int keySize, int valueSize) {
return CRC_LENGTH + MAGIC_LENGTH + ATTRIBUTE_LENGTH + TIMESTAMP_LENGTH + KEY_SIZE_LENGTH + keySize + VALUE_SIZE_LENGTH + valueSize;
}
public long putRecord(long timestamp, byte[] key, byte[] value, CompressionType type,
int valueOffset, int valueSize) {
// put a record as un-compressed into the underlying stream
long crc = Record.computeChecksum(timestamp, key, value, type, valueOffset, valueSize);
byte attributes = Record.computeAttributes(type);
putRecord(crc, attributes, timestamp, key, value, valueOffset, valueSize);
return crc;
}
public static void write(Compressor compressor, long crc, byte attributes, long timestamp, byte[] key, byte[] value, int valueOffset, int valueSize) {
// write crc
compressor.putInt((int) (crc & 0xffffffffL));
// write magic value
compressor.putByte(CURRENT_MAGIC_VALUE);
// write attributes
compressor.putByte(attributes);
// write timestamp
compressor.putLong(timestamp);
// write the key
if (key == null) {
compressor.putInt(-1);
} else {
compressor.putInt(key.length);
compressor.put(key, 0, key.length);
}
// write the value
if (value =https://www.cnblogs.com/fanmao/p/= null) {
compressor.putInt(-1);
} else {
int size = valueSize >= 0 ? valueSize : (value.length - valueOffset);
compressor.putInt(size);
compressor.put(value, valueOffset, size);
}
}
public void putByte(final byte value) {
try {
appendStream.write(value);
} catch (IOException e) {
throw new KafkaException("I/O exception when writing to the append stream, closing", e);
}
}
通過上面的代碼可以看出來,訊息最侄訓按照一定格式最終序列化成位元組陣列寫入到輸出流中,
什么樣的格式呢?其實根據寫入的順序可以看出它的自定義二進制協議如下:
offset | size | crc | magic | attibutes | timestamp | key size | key | value size | value
整個程序他規范里規定了,就是先是幾個位元組的offset,然后是幾個位元組的size,然后是幾個位元組的crc,接著是幾個位元組的magic,以此類推,他就是完全按照規范來寫入ByteBuffer里去的,
并且可以看到他最最底層的寫入ByteBuffer的IO流的方式,
整個程序簡單可以概括如下圖所示:
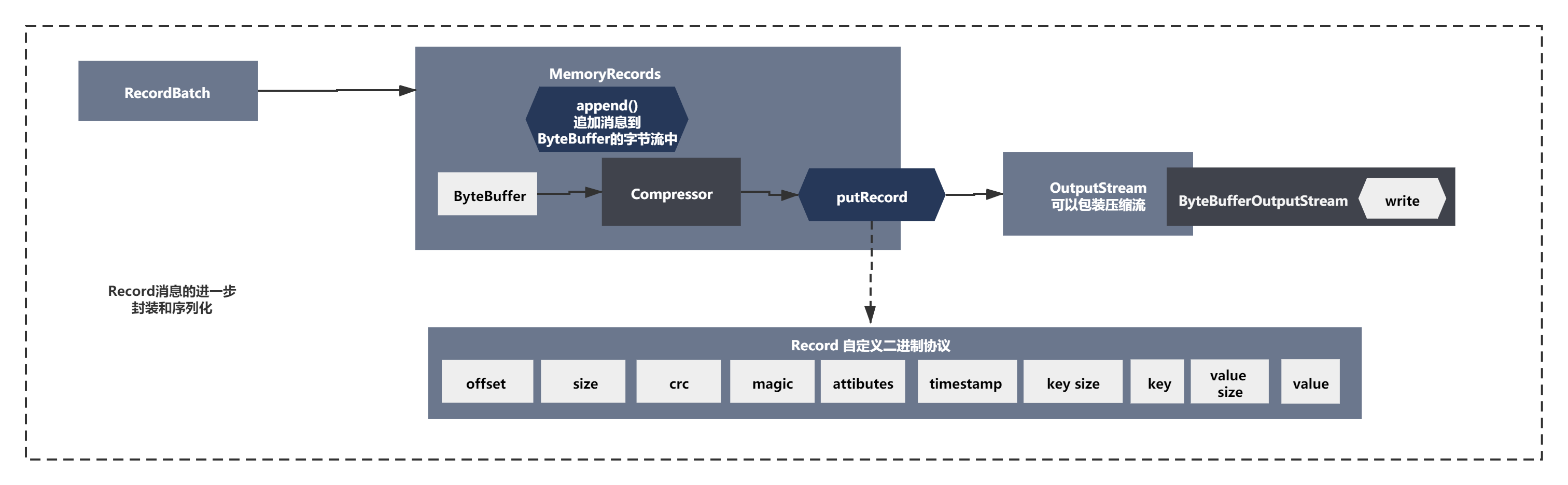
如果你仔細分析下,會發現個流可以進行壓縮,ByteBufferOutputStream給包裹在一個壓縮流里,gzip、lz4、snappy,如果是包裹在壓縮流里,寫入的時候會先進入壓縮流的流的緩沖區,之后再寫入ByteBufferOutputStream, 如果是非壓縮的模式,最最普通的情況下,就是DataOutputStream包裹了ByteBufferOutputSteram,然后寫入資料,Long、Byte、String,都會在底層轉換為位元組進入到ByteBuffer里去,
其實這才是訊息最終的序列化,根據自定義的二進制協議寫入流中發送出去,之前的序列化定義只是對key和value的定義而已,最終底層的序列化,會包裝一些元資料,
這里kafka對訊息格式其實做過優化和改進,有興趣的同學可以去查閱下資料了解下,它為什么這么設計呢?解決了哪些問題,其實都是值得思考的地方,
這里劇透下,通過這樣的訊息格式其實可以解決粘包拆包的問題,你看出來了么?
小結
好了,今天就到這里了,我們主要分析了tryAppend邏輯:
1)是如何將訊息最終放入到記憶體的佇列中的,
2)并且知道了batch打包訊息的機制
3)最終序列化訊息的自定義二進制協議
這當中其實有很多值得思考的亮點,Kafka這塊的原始碼邏輯還是很值得大家多研究幾遍,
之后的我們要分析的邏輯其實就是如何記憶體佇列中將打包好的訊息發送給Broker的,我們下一節再見!
本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/309387.html
標籤:Java