讀者朋友們大家好啊,我是小張~
國慶小長假昨天就已將結束了,我們呢,也各自回到自己的作業崗位,繼續開啟我們的努力搬磚( 摸魚)生活
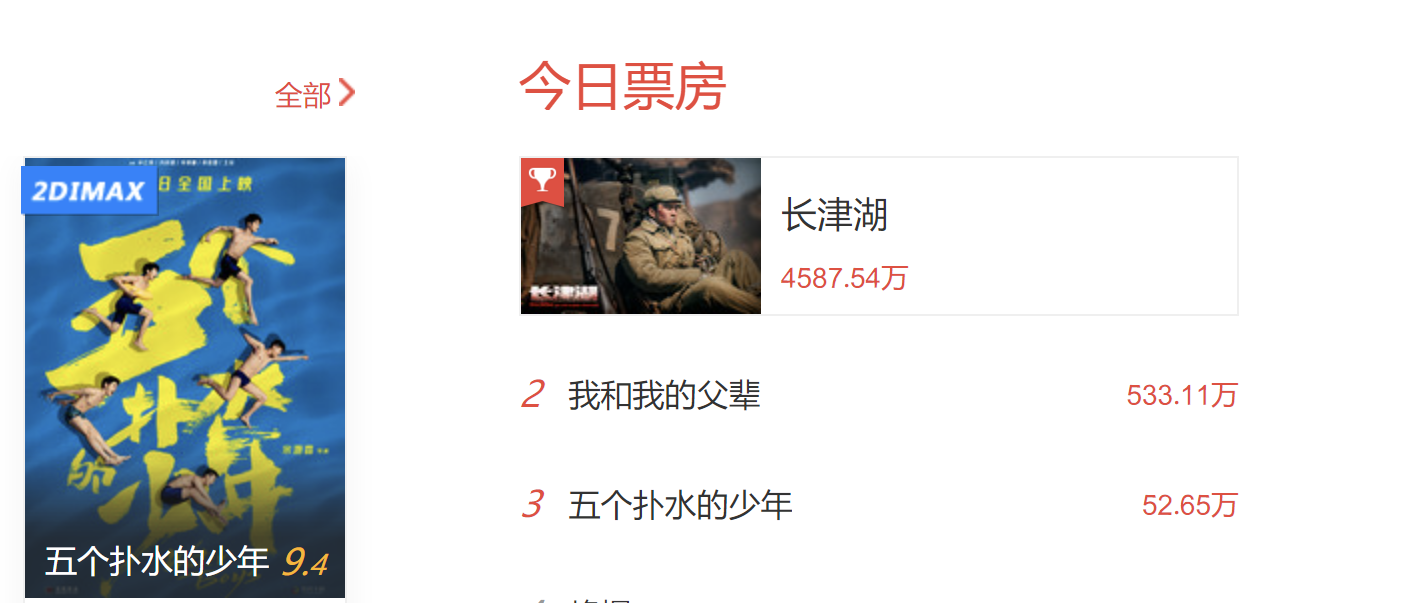
從19年開始,每逢十一就會上映一部以 我和我的* 主題的電影來喜迎國慶,并且按照前兩年票房趨勢,這部電影的歡迎程度遠大于同時期上映的其它電影,票房穩居第一
今年也不例外上映了一部《我和我的父輩》,以4個 片段來講述父母與孩子之間的故事,內容也受到大眾的肯定;
但令人意外的是它的票房,要遠低于另一部國慶檔《長津湖》,熱度和好評數原高于前者,關于其中的具體細節,本文以此來做個影評分析
本文挑選了在今年國慶上映三部電影,分別是《我和我的父輩》、《長津湖》以及《五個撲水的孩子》
《五個撲水的孩子》這部電影許多讀者可能是第一次聽到,熱度遠不及前兩部,但它的確是在今年國慶期間上映的,而且根據貓眼排名,熱度還不低,位居第三
技術堆疊
開始之前,先說下本文所用到的技術堆疊,主要分為以下兩方面:
語言:Python,javascript;
庫: echarts,styleCloud;
影評對比分析
首先是從影評角度來分析一下,這里借助 Python 獲取到三部電影的在豆瓣上的部分影評,關于豆瓣影評的爬取,這里我就不過多介紹了,不太熟悉的參考舊文:,核心代碼貼在下方:
headers = {
"Cookie":"bid=tulFhUK9Lzo; douban-fav-remind=1; ll=\"118160\"; _vwo_uuid_v2=D55143433EAF6AF4EB29A904F8BE781A1|4d5d27125abfe3f6d29caa68ba504fed; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1632849782%2C%22https%3A%2F%2Fwww.google.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.52492667.1628212627.1629608096.1632849782.3; __utmc=30149280; __utmz=30149280.1632849782.3.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __utma=223695111.788106722.1629608096.1629608096.1632849782.2; __utmb=223695111.0.10.1632849782; __utmc=223695111; __utmz=223695111.1632849782.2.2.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __utmb=30149280.3.10.1632849782; _pk_id.100001.4cf6=254979423a09aae4.1629608097.2.1632851386.1629608485.",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
}
#
#Part1 資料爬取改一下 id 即可
movieId = "35030151"
for offset in range(0,220,20):
url = "https://movie.douban.com/subject/{}/comments?start={}&limit=20&status=P&sort=new_score".format(movieId,offset)
res = requests.get(url,headers= headers)
# print(res.text)
soup = BeautifulSoup(res.text,'lxml')
time.sleep(2)
for comment_item in soup.select("#comments > .comment-item"):
try:
data_item = []
avatar = comment_item.select(".avatar a img")[0].get("src")
name = comment_item.select(".comment h3 .comment-info a")[0]
rate = comment_item.select(".comment h3 .comment-info span:nth-child(3)")[0]
date = comment_item.select(".comment h3 .comment-info span:nth-child(4)")[0]
comment = comment_item.select(".comment .comment-content span")[0]
# comment_item.get("div img").ge
data_item.append(avatar)
data_item.append(str(name.string).strip("\t"))
data_item.append(str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"))
data_item.append(str(date.string).replace('\n','').strip('\t'))
data_item.append(str(comment.string).strip("\t").strip("\n"))
data_json ={
'avatar':avatar,
'name': str(name.string).strip("\t"),
'rate': str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"),
'date' : str(date.string).replace('\n','').replace('\t','').strip(' '),
'comment': str(comment.string).strip("\t").strip("\n")
}
if not (collection.find_one({'avatar':avatar})):
print("data _json is {}".format(data_json))
collection.insert_one(data_json)
except Exception as e:
print(e)
首先呢,我們先看下關于這三部電影的評論在每個時間段有沒有數量方面的差異,于是就有了下面圖1
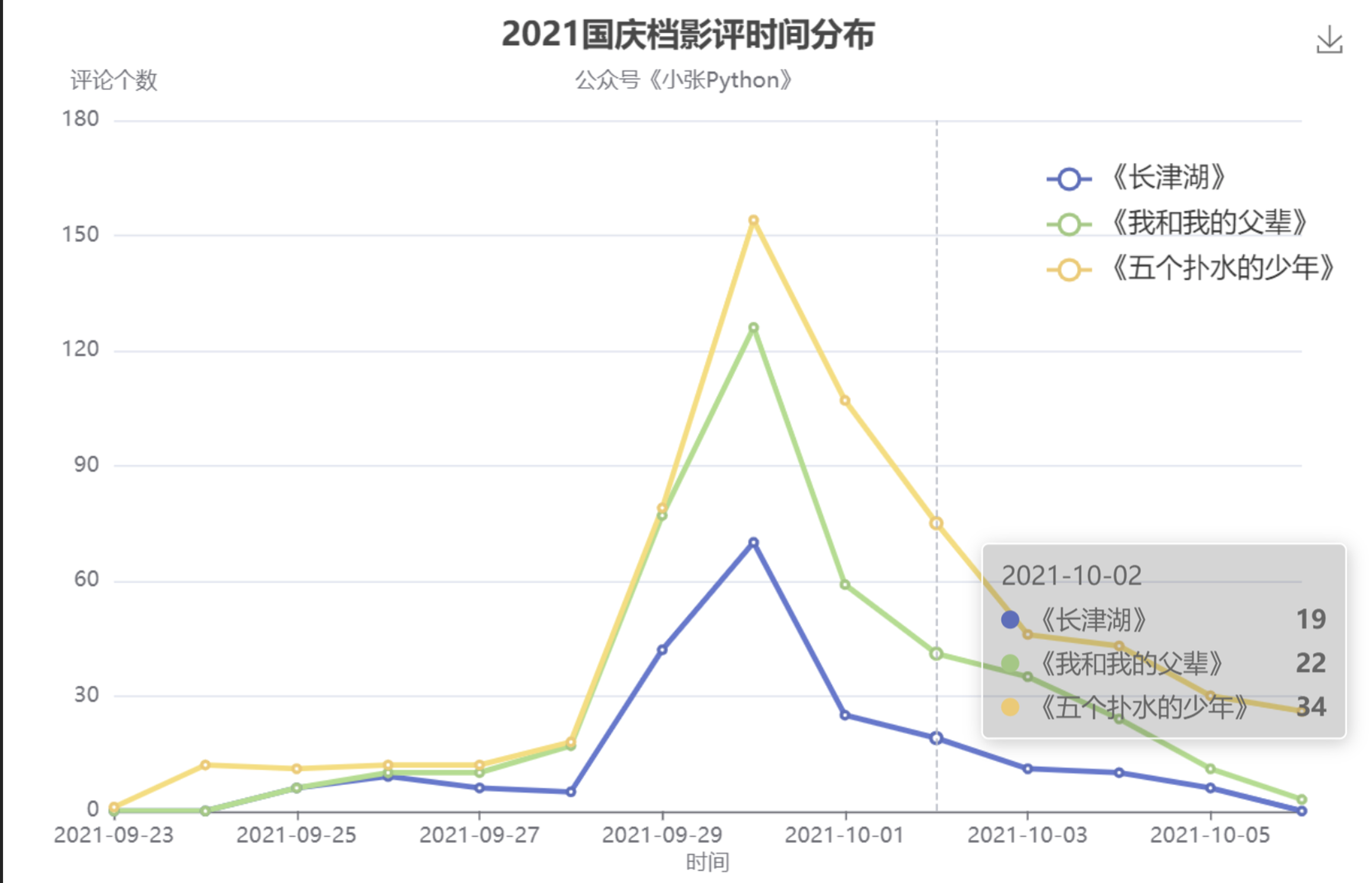
根據圖1可視化結果來看,三部電影的評論趨勢是一致的,從 24日開始評論數慢慢增加,到 30 日達到高峰,之后慢慢回落;
這個趨勢也比較合乎常理,30日及30日之前的評論都可以被認為是用戶看完點映之后反饋,也是出品商為了利益最大化,為電影增加熱度的一種方式
但是這里面比較大的一個問題是 評論數量對比,根據這個折線圖顯示,《五個撲水的少年》的評論數遠大于《長津湖》和《我和我的父輩》,無論影評好壞,根據傳播學的角度前者的熱度要遠高于后者,而后面票房對比結果卻恰恰相反,至于為什么出現這種趨勢,還請大家細品,,只能說《長津湖》出品方是真的自信,評論熱度低,但票房卻很出眾
與影評相關的星級分布,在這里我也做了個簡單對比,《少年》、《長津湖》、《父輩》(這里偷個懶,都用簡稱來替換 ) 可視化效果見圖2,圖3、圖4
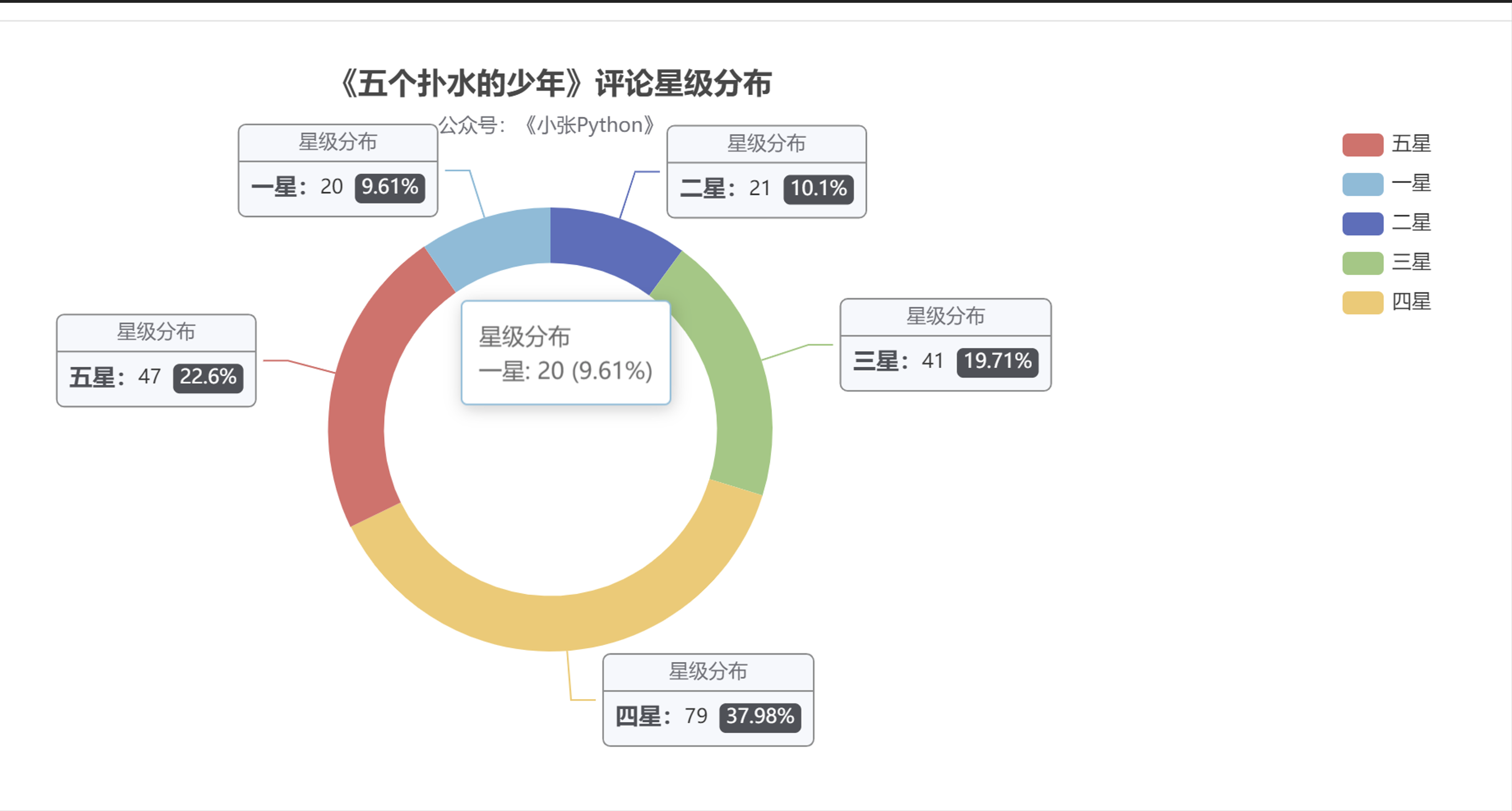
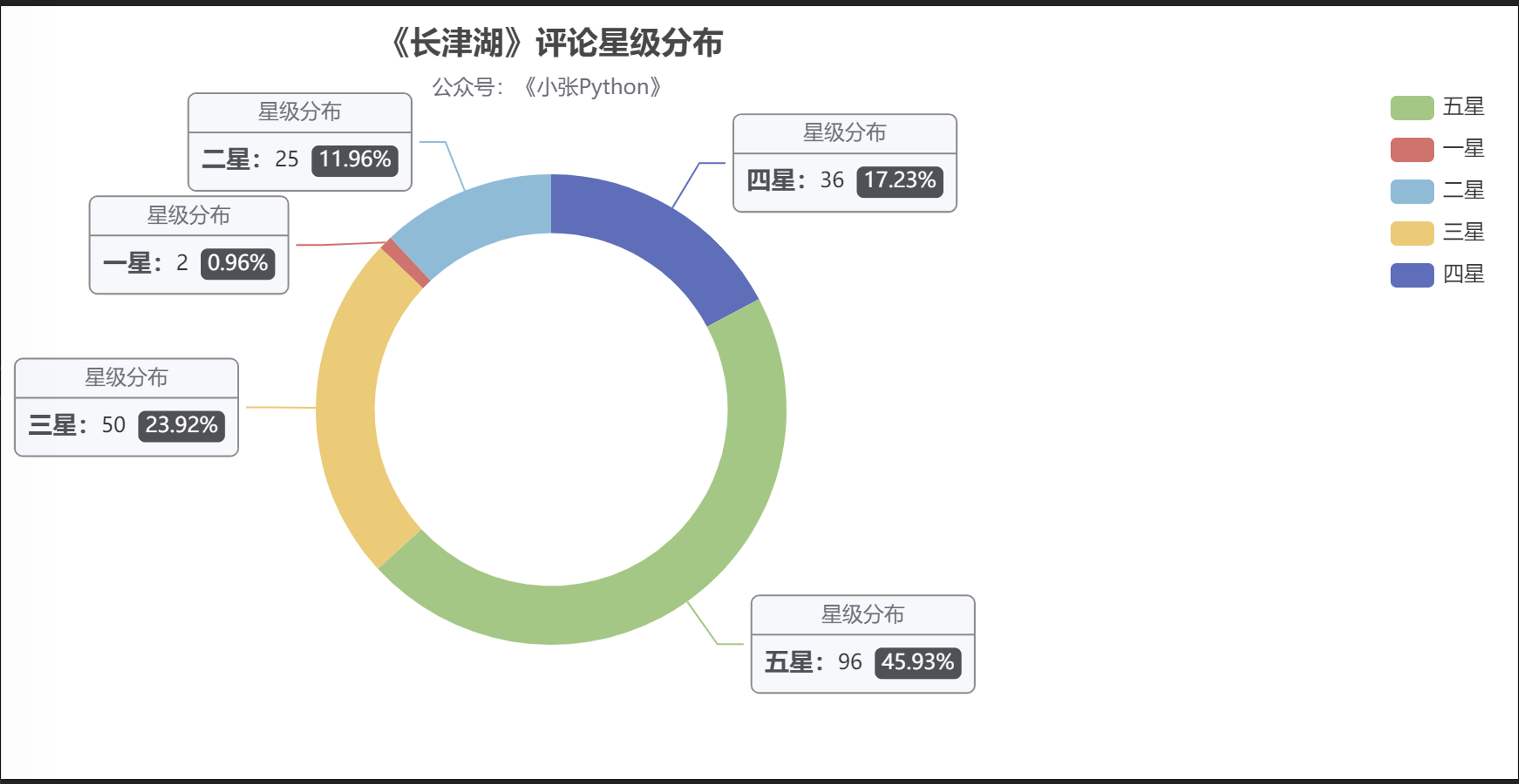
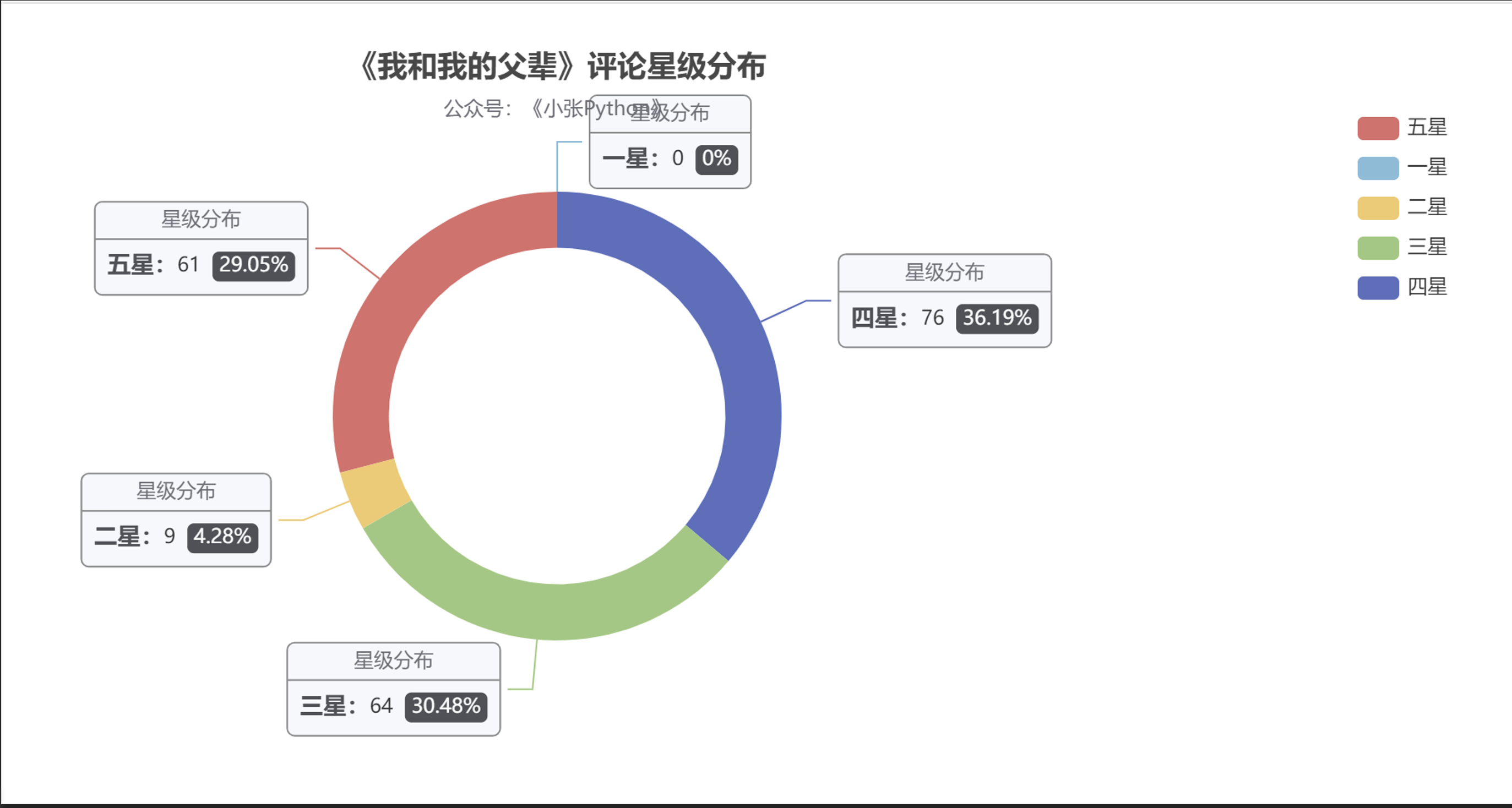
從結果來看,《長津湖》的受歡迎程度最高,從采集到的樣本中,五星級好評占比高達 45.93,近一半的比例,其次是《父輩》占據29.05,最后是《少年》 22.6;
但目前在豆瓣上評分是這樣的,《長津湖》 7.6,《父輩》:7.0,《少年》7.3,雖然豆瓣影評相對會權威一些,但對這個評分我還是持有懷疑態度,至于原因的話就是后面的票房緣故;
關于一部電影的好壞,只看評分是沒有意義的,畢竟評分根據資本的力量是可以改變的, 一部電影最終受不受歡迎,核心的還是票房,看用戶愿不愿意為這部影片支付一張電影票的價格
下面的票房資料來源于貓眼,根據三部電影的票房資料我繪制了兩個圖表,一個是當天的票房數,一個是自上映日開始的累計票房
當天票房數統計結果見圖5
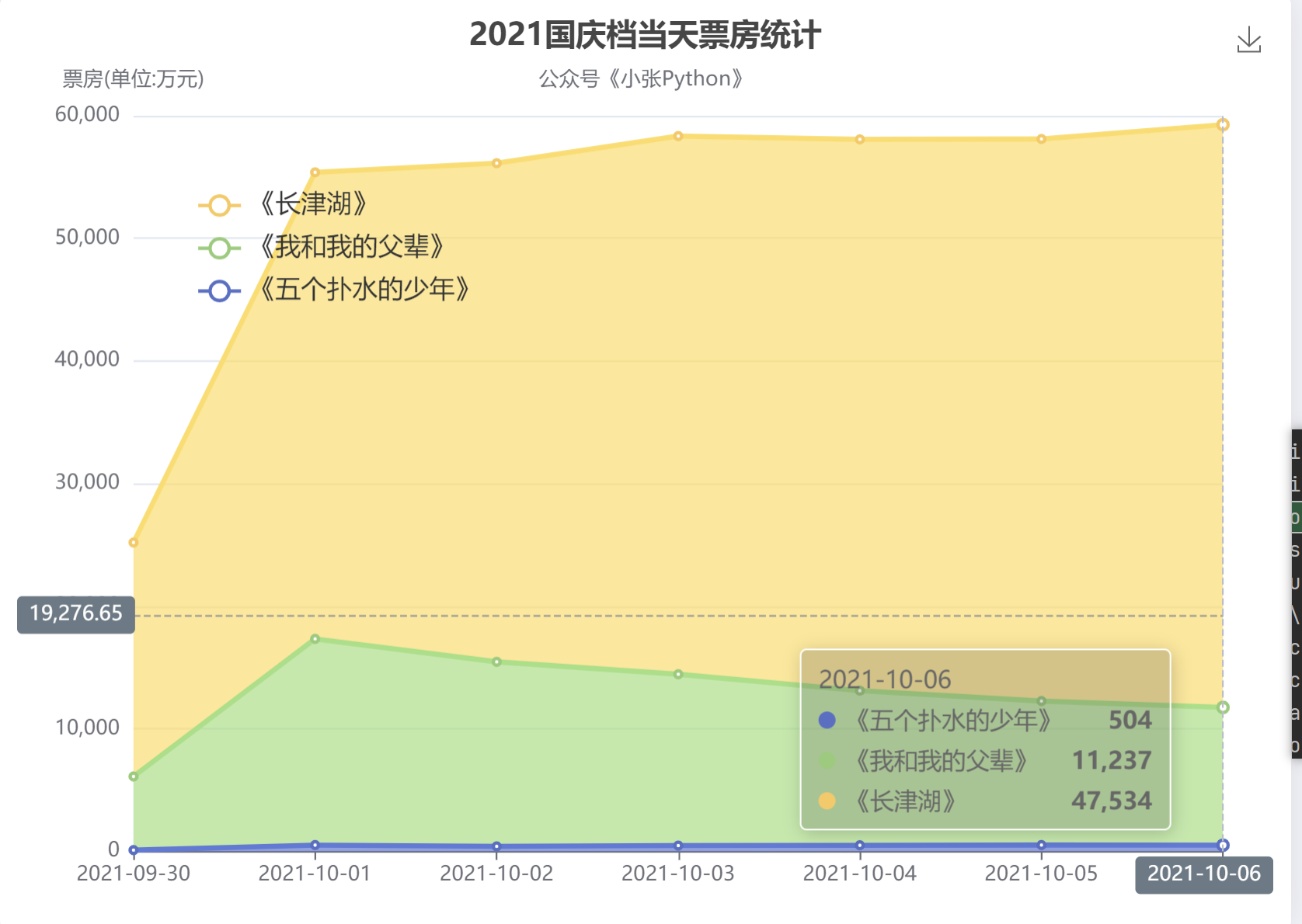
看到這個表之后我驚了個呆,如果不加入《票房》統計這一維度的對比,原以為《少年》與前兩部就有差距,但不會差別特別大,看完這個表的資料之后,發現自己還是太年輕了,《少年》的票房與另外兩部電影基本沒有可比性
請不要忽略
圖5中最下面那條藍線,那條線就是《少年》每天的票房資料統計
在10月6日這一天,《五個撲水的少年》的票房約500多萬,而《長津湖》這一天單日票房僅 4.75億,這之間相差近 90倍
除了單日票房外,這里對三部影片的累計票房走勢也繪制了一個折線圖,結果見圖6
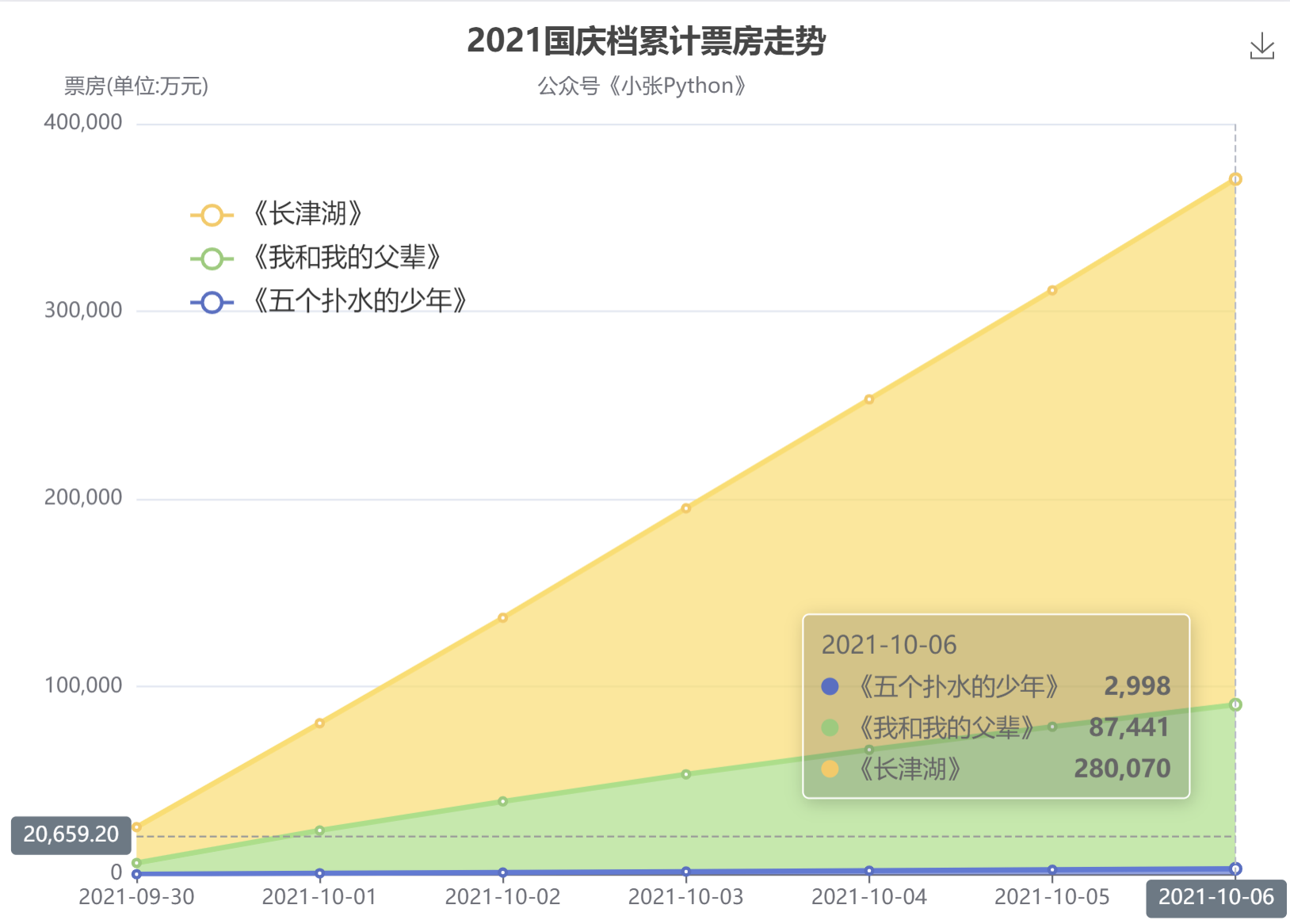
截止到10約6日,《長津湖》票房數累計 28億,《父輩》累計 8.7億,而《少年》僅有 0.3 億左右;
如果說《長津湖》是呈45度直線向上,那么《我和我的父輩》票房走勢角度只有 30度,甚至不足于30度;而《五個撲水的少年》的票房走勢呈水平狀態,是真的慘;
影評分析到這里不由地會想起一句話:旱的旱死,澇的澇死;可能一些出電影廠商特地會把電影放在國慶、春節 這種大流量的節日中,投資將很可能帶來幾倍甚至幾十倍的收益;
但從上面票房對比來看,這個策略不見得很明智,除非影片很受大眾的肯定和喜歡,否則可能不但沒有收益而且連前期投入的成本都收不回來
《我和我的父輩》作為國慶檔預期較高的一部影片,本以為票房會略低于《長津湖》,但從上面走勢來看,《父輩》離后者還是有不小的差距;
側面也可以看出,如今大眾群體對于好的電影絕不會吝嗇,對于看電影這一娛樂方式我們絕不會虧待自己,但是看一部低質量影片,我們是不能容忍的
詞云繪制
最后,將每一部電影的影評繪制為一張詞云圖,看看對于每部電影,觀眾們都說了什么
在《長津湖》的影評中,提到最多的是歷史、志愿軍、戰爭片、美軍、震撼 等關鍵詞;而這幾個關鍵詞確實與電影題材相符合,彰顯現在美好生活的來之不易

在《我和我的父輩》中,沈騰、吳京 兩個導演的名字占據整張詞云圖的一大部分,受到觀眾們的喜歡;而對于這部劇的劇情方面的評價,出現最多的就是浪漫、喜劇、感動,雖然情感方面相差較大,但襯托出四位導演之間的不同風格;

原版、翻拍、改編、國產是《少年》這部劇的題材基調,而除此之外并沒有看到與這部劇劇情相關的情感評價,也并沒有什么好討論的了,

小結
關于本篇文章中的代碼和資料的獲取方式:關注微信公眾號:小張Python,后臺回復關鍵詞:211009 即可獲取
今年國慶檔的影評分析到這里也就結束了,總的來說可以用一句話來概括:以前影片出品方能憑借炒作、前期流量IP宣傳為票房創造不少收益,而這種情況在現在很少會發生,現在的觀眾已經不再那么好糊弄的了
如果本文對你有所幫助的話,不妨點個贊鼓勵一下我,最后感謝大家的閱讀,我們下期見~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/309514.html
標籤:python