文章目錄
- 環境
- 使用的函式介面
- 流程
- 人臉檢測部分
- 圖片讀取/尺寸修改
- 圖片矩形標注
- 人臉檢測
- 讀取視頻標注人臉
- 人臉識別
- 人臉資訊錄入
- 資料訓練
- 人臉識別
通過最近的學習感觸頗多,大資料,人工智能,分布式,云計算,基于云的云安全,萬物互聯真的是未來大方向!所謂的web開發,服務器后端其實只是一個開始,玩了python 后端也在體驗spring全家桶(學習ing)只要做一個像樣的“萬人會話”基本上都不會只是靠那一套“增刪改查”能夠實作的,都會涉及到并發,并行,但是想要做好又涉及到分布式,微服架構等等,此外還有更多的服務細節,例如如何實時分析用戶喜好從而推送對應內容等等,這些與大資料聯系密切,與分布式計算聯系緊密,當然也從這里我意識到python 并不適合,且不論性能,單從這里就可以看到在這一方面python的方案并不如Java,盡管它也有所選擇,不過好在的是python憑借著豐富的類別庫,在機器學習,人工智能這塊使用起來的簡便性讓它魅力依舊,當然這里且不論底層,
當然這里并不是說我那些玩意不玩了,這是不可能的,畢竟還有個web專案沒寫完( White Hole),而且還得用Springboot 重構,
環境
1.python 3.7
2.opencv
pip3 install opencv-python
pip3 install opencv-contrib-python
這個的話目前其實還是簡單的介面呼叫,
使用的函式介面
鐵打的API,流水的程式員呀!
import cv2.cv2 as cv
cv.imread() #讀取圖片
cv.cvtColot() #圖片顏色處理(灰度處理)
cv.imwrite() #保存圖片
cv.imshow() #展示圖片
cv.waitKey() #視窗展示(其實是等待鍵盤輸入,IO阻塞)停留傳入時間毫秒,回傳鍵盤按下的鍵位的ascll值
cv.resize() #修改圖片大小
cv.rectangle() #繪制矩形
cv.circle() #繪制圓形
cv.CascadeClassifier()#使用訓練模型
cv.VideoCapture() #讀取視頻0表示讀取攝像頭
face.LBPHFaceRecognizer_create() #資料訓練
cv.destoryAllWindows() #釋放記憶體
流程
這里的話主要分為兩個大步走
1.讀取圖片/視頻內的人臉資訊,識別人臉位置(框出人臉位置)
2.將識別出的人臉進行比對(特征提取)
人臉檢測部分
圖片讀取/尺寸修改
import cv2.cv2 as cv
Image = cv.imread("Image/face1.jpg")
cv.imshow("Image",Image)
Image_resize = cv.resize(Image,dsize=(200,200))
cv.imshow("ResizeImage",Image_resize)
cv.waitKey(0)
cv.destroyAllWindows()
圖片矩形標注
import cv2.cv2 as cv
img = cv.imread('Image/face1.jpg')
x,y,w,h = 100,100,100,100 #起始坐標
#繪制矩形
cv.rectangle(img,(x,y,x+w,y+h),color=(0,0,255),thickness=1) # 方框顏色,粗細
#繪制圓形
cv.circle(img,center=(x+w,y+h),radius=100,color=(255,0,0),thickness=5)
#顯示
cv.imshow('re_img',img)
cv.waitKey(0)
cv.destroyAllWindows()
人臉檢測
#匯入cv模塊
import cv2.cv2 as cv
import cv2.data as data
#讀取影像
img = cv.imread('Image/face1.jpg')
gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detect = cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_alt2.xml")
face = face_detect.detectMultiScale(gary)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.imshow('result',img)
cv.waitKey(0)
#釋放記憶體
cv.destroyAllWindows()
函式說明
gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY) 二值化處理圖片
face_detect = cv.CascadeClassifier(data.haarcascades+“haarcascade_frontalface_alt2.xml”)
這個是加載使用人家訓練好的提取頭像的模型幫助我們提取出圖片的人臉,此外還有還有提取人眼的,等等,
face = face_detect.detectMultiScale(gary)按照模型提取出人臉的大小位置,回傳一個元組
重點
face = face_detect.detectMultiScale(gary,1.01,5,0,(100,100),(300,300))
還可以這樣用,1.01表示圖片縮放倍數
5對比次數,意思是對比了五次還是一樣的話就認為是人臉
0默認引數不用管,加上
(100,100) (300,300) 表示人臉的范圍,這個可以設定
這些引數都可以不設定,直接使用默認的
face_detect = cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_alt2.xml")
這里加載的模型其實是在虛擬環境下的site-pakges里面找到的
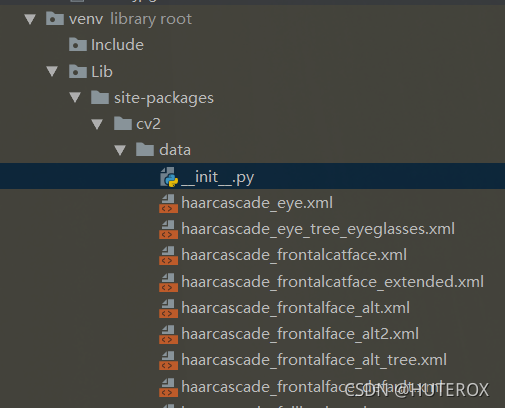
此外如果你安裝了opencv的話那么你也可以在opencv的安裝目錄找到,到時候你要用哪個就搞哪個.
例如我安裝在D盤
face_detect = cv.CascadeClassifier('D:/opencv/opencv/sources/data/haarcascades/haarcascade_frontalface_alt2.xml')
我直接填寫路徑
這邊推薦直接使用默認的,
face_detect =
cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_default.x")
讀取視頻標注人臉
cap = cv.VideoCapture(0) 讀取攝像頭
#匯入cv模塊
import cv2.cv2 as cv
import cv2.data as data
import time
#檢測函式
def face_detect_demo(img):
gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detect = cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_default.xml")
face = face_detect.detectMultiScale(gary)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.imshow('result',img)
cap = cv.VideoCapture(0)
while True:
flag, img = cap.read()
if not flag:
break
face_detect_demo(img)
if ord('q') == cv.waitKey(1):
break
cap.release() #釋放視像頭記憶體
#釋放記憶體
cv.destroyAllWindows()
當前是讀取攝像頭的視頻資訊,如果直接填入路徑的話那么就會讀取到視頻的內容進行人臉標注
人臉識別
到目前為止已經可以把人臉從視頻或者圖片當中摳下來了(其實當當前步驟已經可以實作前些日子比較火熱的AI外掛了,不過目前使用的識別模型不咋滴,如果要用得專門訓練一下,然后結合外設驅動,我們這邊回傳獲取的人頭的坐標,更具游戲特色我們還得計算一下槍械的后座偏移量然后驅動游標瞄準射擊,外掛的原理其實也類似,只是人家的坐標是直接在記憶體里面抓到的,不是我們這樣還要通過人臉識別)
人臉資訊錄入
搞人臉識別那必然還是要錄入人臉資訊的,這里由兩個方案,一個是直接準備好圖片(就是需要錄入的人臉的照片)或者通過攝像頭錄入,由于我們識別的時候要調取攝像頭所以建議從攝像頭里面開始錄入,第一個方案準備照片就好了,第二個方案看下面代碼即可:
import cv2.cv2 as cv2
import os
import threading
name = None
save_flag = False
lock = threading.Lock()
def input_name():
global name,save_flag
while 1:
if name =="Q" or name=="q":
return
else:
name=input("\n:")
save_flag = True
def Get_Face():
global name,save_flag
cap = cv2.VideoCapture(0)
num = 1
Path_save = r"Image/InPutImg/"
if not os.path.exists(Path_save):
os.makedirs(Path_save)
while(1):
ret_flag,VImg = cap.read()
cv2.imshow("Capture_Test",VImg)
cv2.waitKey(1)
lock.acquire()
if name:
if name == "Q" or name == "q":
lock.release()
return
if save_flag:
cv2.imwrite(Path_save+str(num)+"."+name+".jpg",VImg)
print("\n圖片已保存:"+str(num)+"."+name+".jpg")
num += 1
save_flag = False
lock.release()
cap.release()
cv2.destroyAllWindows()
if __name__=="__main__":
t1 = threading.Thread(target=Get_Face)
t2 = threading.Thread(target=input_name)
t1.start()
t2.start()
這里為了控制輸入額外開了個執行緒,不過顯示沒法做到同步,做了就堵死了~
之后在專案的檔案夾下會多出一個檔案
里面保存了在攝像頭拍攝的人臉,
資料訓練
這個重復先前的步驟
把獲取的圖片提取出人臉,然后把對應的人臉和人物的id進行訓練
import os
import cv2.cv2 as cv
import numpy as np
import cv2.data as data
def getImageIds(path):
#函式作用是提取人臉然后回傳人物的人臉和id
faceseare=[] # 保存檢測出的人臉
ids=[] #
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
#人臉檢測
face_detector = cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_default.xml")
if imagePaths:
print('訓練圖片為:',imagePaths)
else:
print("請先錄入人臉")
return
for imagePath in imagePaths:
#二值化處理
img = cv.imread(imagePath)
img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
img_numpy=np.array(img,'uint8')#獲取圖片矩陣
faces = face_detector.detectMultiScale(img_numpy)
id = int(os.path.split(imagePath)[1].split('.')[0])
for x,y,w,h in faces:
ids.append(id)
faceseare.append(img_numpy[y:y+h,x:x+w])
print('已獲取id:', id)
return faceseare,ids
if __name__ == '__main__':
#圖片路徑
path='Image/InPutImg'
#獲取影像陣列和id標簽陣列和姓名
faces,ids=getImageIds(path)
#獲取訓練物件
recognizer=cv.face.LBPHFaceRecognizer_create()
recognizer.train(faces,np.array(ids)) #把對應的人臉和id聯系起來訓練
#保存訓練檔案
model_save = "trainer/"
if not os.path.exists(model_save):
os.makedirs(model_save)
recognizer.write('trainer/trainer.yml')
人臉識別
這個就是最后一步了,主要其實就是通過評分進行識別
import cv2.cv2 as cv
import os
import cv2.data as data
recogizer=cv.face.LBPHFaceRecognizer_create()#加載訓練資料集檔案
recogizer.read('trainer/trainer.yml')
names=[]
warningtime = 0
#準備識別的圖片
def face_detect_demo(img):
global warningtime
gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detector=cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_default.xm")
face=face_detector.detectMultiScale(gray)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
# 人臉識別
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
if confidence > 80: #評分越大可信度越低
warningtime += 1
if warningtime > 100:
warningtime = 0
print("未識別出此人") #這塊的話其實可以再搞一套對應的懲罰機制
cv.putText(img, 'unkonw', (x + 10, y - 10), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
#這里也對應一套識別后的機制
cv.putText(img,str(names[ids-1]), (x + 10, y - 10), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
cv.imshow('result',img)
def get_name(names):
path = 'Image/InPutImg/'
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)
cap=cv.VideoCapture(0)
get_name(names)
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
if ord(' ') == cv.waitKey(10): #按下空格關了
break
cap.release()
cv.destroyAllWindows()
下面是演示,
1.已錄入圖片

1.lena.jpg
效果:

到這里一個最基本的識別就做好了,那么關于這里面的懲罰機制或者通過識別后的機制其實,如果可以結合樹莓派的話是可以自己做一個寢室專用的門禁系統的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/309524.html
標籤:python