文章目錄
- 方法1
- 方法2
作為王者榮耀的老玩家,今天教大家如何用python爬蟲獲取王者榮耀皮膚
本文將介紹兩種王者榮耀皮膚的爬取方法,一種比較簡單的,一種復雜的方法供大家學習,
首先先進去王者榮耀官方網站: 王者榮耀
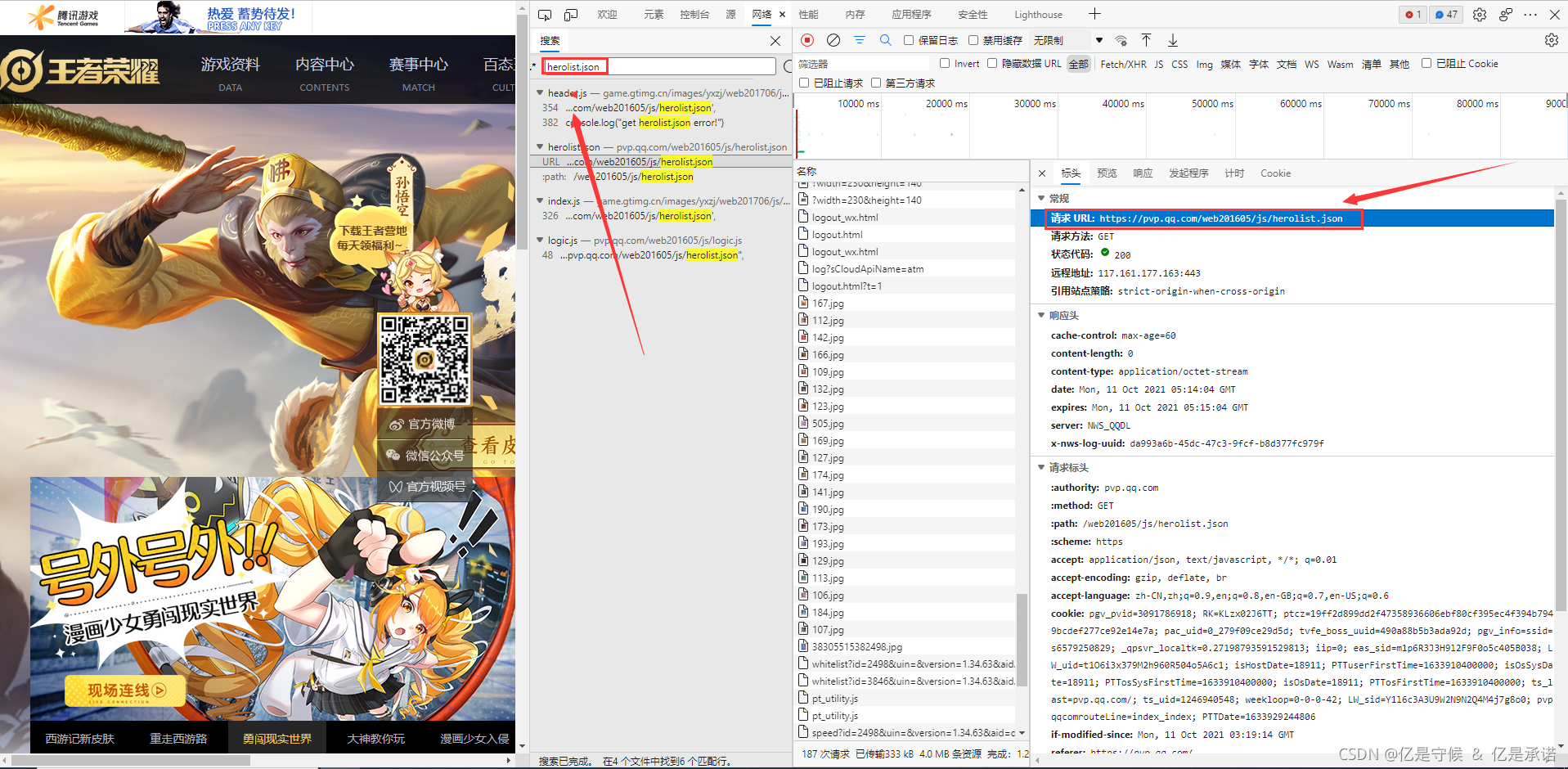
進入開發者工具找到英雄皮膚所在位置,圖中
herolist.json就是我們需要找的英雄串列,包括英雄編號、英雄名稱、影響型別、皮膚等資訊,復制
url:http://pvp.qq.com/web201605/js/herolist.json路徑
方法1
見注釋
# 匯入所需要的模塊
import urllib.request
import json
import os
# 獲取回應頭檔案
response = urllib.request.urlopen("http://pvp.qq.com/web201605/js/herolist.json")
# 讀取英雄串列,并存入hero_json中
hero_json = json.loads(response.read())
hero_num = len(hero_json)
# 保存路徑
save_dir = 'Dheroskin\\'
# 檢查路勁是否存在,不存在則創建路徑
if not os.path.exists(save_dir):
os.mkdir(save_dir)
for i in range(hero_num):
# 獲取英雄皮膚串列
skin_names = hero_json[i]['skin_name'].split('|')
for cnt in range(len(skin_names)):
save_file_name = save_dir + str(hero_json[i]['ename']) + '-' +hero_json[i]['cname']+ '-' +skin_names[cnt] + '.jpg'
skin_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(hero_json[i]['ename'])+ '/' +str(hero_json[i]['ename'])+'-bigskin-' + str(cnt+1) +'.jpg'
print(skin_url)
# 檢查圖片檔案是否存在,如果存在則跳過下載
if not os.path.exists(save_file_name):
urllib.request.urlretrieve(skin_url, save_file_name)
效果展示如下

方法2
見注釋
import requests
import re
import json
import os
import time
# 獲取當前時間戳,用于計算爬蟲爬取完畢消耗了多少時間
now = lambda: time.time()
# 請求頭
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"Cookie": "pgv_pvid=120529985; pgv_pvi=8147644416; RK=iSx1Z7fSHW; ptcz=d094d0d03f513f6762a4c18a13ddae168782ec153f43b16b604723b27069d0a7; luin=o0894028891; lskey=000100008bc32936da345e2a5268733bf022b5be1613bd2600c10ad315c7559ff138e170f30e0dcd6a325a38; tvfe_boss_uuid=8f47030b9d8237f7; o_cookie=894028891; LW_sid=s116T01788a5f6T2U8I0j4F1K8; LW_uid=Z1q620M7a8E5G6b2m8p0R4U280; eas_sid=m1j6R057x88566P2Z8k074T2N7; eas_entry=https%3A%2F%2Fcn.bing.com%2F; pgv_si=s8425377792; PTTuserFirstTime=1607817600000; isHostDate=18609; isOsSysDate=18609; PTTosSysFirstTime=1607817600000; isOsDate=18609; PTTosFirstTime=1607817600000; pgv_info=ssid=s5339727114; ts_refer=cn.bing.com/; ts_uid=120529985; weekloop=0-0-0-51; ieg_ingame_userid=Qh3nEjEJwxHvg8utb4rT2AJKkM0fsWng; pvpqqcomrouteLine=index_herolist_herolist_herodetail_herodetail_herodetail_herodetail; ts_last=pvp.qq.com/web201605/herolist.shtml; PTTDate=1607856398243",
"referer": "https://pvp.qq.com/"
}
# 決議函式,回傳文本或者二進制或者None
def parse_url(url, get_b=False):
try:
response = requests.get(url, headers=headers)
response.encoding = "gbk"
assert response.status_code == 200
if get_b == True:
return response.content
else:
return response.text
except:
print("status_code != 200(from parse_url)")
return None
# 處理單個英雄
def parse_hero_detail(id, name):
# 保存所有皮膚圖片的本地路徑
path = f"./英雄皮膚/{name}"
if not os.path.exists(path):
os.makedirs(path, exist_ok=True)
# 因為不確定每個英雄有多少個皮膚,所以假設單個英雄一共請求10張皮膚,這樣就不會出現皮膚缺少的情況
for num in range(1, 11):
# 單個英雄皮膚圖片的url鏈接
api_url = f"https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id}/{id}-bigskin-{num}.jpg"
# 如果回傳None,則說明狀態碼不是200,即沒有這個請求的皮膚
b_data = parse_url(api_url, get_b=True)
if b_data == None:
print(f"{name} 一共有{num - 1}個皮膚")
print("--------------------------------------------------")
# 沒有新的皮膚了,立即退出回圈
break
img_path = f"{path}/demo{num}.jpg"
if not os.path.exists(img_path):
try:
download_img(img_path, b_data)
except:
return
print(f"{name} 第{num}張皮膚圖片 下載完畢")
# 下載圖片
def download_img(path, b_data):
with open(path, "wb") as f:
f.write(b_data)
def main():
# 含有每個英雄對應的id、英雄名稱的url
api_url = "https://game.gtimg.cn/images/yxzj/web201706/js/heroid.js"
text = parse_url(api_url)
search_result = re.search('var module_exports = ({.*?})', text, re.S)
hero_info_str = search_result.group(1)
hero_info_str = re.sub("'", '"', hero_info_str)
# 包含 所有英雄以及各自對應的id 的字典
hero_info_dict = json.loads(hero_info_str)
for hero in hero_info_dict:
name, id = hero_info_dict[hero], hero
print(name, id)
parse_hero_detail(id, name)
if __name__ == '__main__':
start = now() # 記錄起始時間
main() # 主函式
print(f"耗時: {now() - start}") # 計算爬蟲執行完畢消耗的時間
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/310579.html
標籤:python