
Pandas是一個基于python中Numpy模塊的一個模塊
Python在資料處理和準備???直做得很好,但在資料分析和建模??就差?些,pandas幫助填補了這?空?,使您能夠在Python中執?整個資料分析?作流程,?不必切換到更特定于領域的語?,如R,與出?的 jupyter?具包和其他庫相結合,Python中?于進?資料分析的環境在性能、?產率和協作能???都是卓越的, pandas是 Python 的核?資料分析?持庫,提供了快速、靈活、明確的資料結構,旨在簡單、直觀地處理關系型、標記型資料,pandas是Python進?資料分析的必備?級?具, pandas的主要資料結構是 Series(?維資料)與 DataFrame (?維資料),這兩種資料結構?以處理?融、統計、社會科學、?程等領域?的?多數案例處理資料?般分為?個階段:資料整理與清洗、資料分析與建模、資料可視化與制表,Pandas 是處理資料的理想?具, 環境介紹 代碼工具:jupyternotebook python版本:python3.8.6 系統版本:win10 一、Pands安裝 打開終端指令輸入pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com pandas 第?部分 資料結構
第?節 Series
?串列?成 Series時,Pandas 默認?動?成整數索引,也可以指定索引
第?部分 資料結構
第?節 Series
?串列?成 Series時,Pandas 默認?動?成整數索引,也可以指定索引
l = [0,1,7,9,np.NAN,None,1024,512] # ?論是numpy中的NAN還是Python中的None在pandas中都以缺失資料NaN對待 s1 = pd.Series(data = https://www.cnblogs.com/t-dashuai/p/l) # pandas?動添加索引 s2 = pd.Series(data = https://www.cnblogs.com/t-dashuai/p/l,index = list('abcdefhi'),dtype='float32') # 指定?索引 # 傳?字典創建,key?索引 s3 = pd.Series(data = https://www.cnblogs.com/t-dashuai/p/{'a':99,'b':137,'c':149},name = 'Python_score') display(s1,s2,s3)第二節 Dataframe DataFrame是由多種型別的列構成的?維標簽資料結構,類似于 Excel 、SQL 表,或 Series 物件構成的字典,
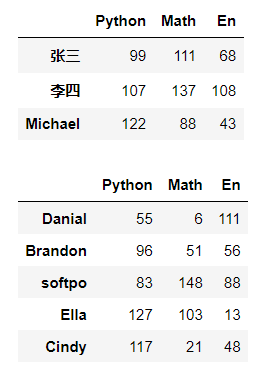
import numpy as np import pandas as pd # index 作為?索引,字典中的key作為列索引,創建了3*3的DataFrame表格?維陣列 df1 = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/{'Python':[99,107,122],'Math':[111,137,88],'En': [68,108,43]},# key作為列索引 index = ['張三','李四','Michael']) # ?索引 df2 = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,151,size = (5,3)), index = ['Danial','Brandon','softpo','Ella','Cindy'],# ?索引 columns=['Python','Math','En'])# 列索引 display(df1,df2)
import numpy as np import pandas as pd df = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,151,size=(150,3)), index = None, # 行索引默認 columns=['A','B','C'])#列索引 df.head(10)#顯示前十行 !!默認是五行!! df.tail(10)#顯示后十行 df.shape#查看行數和列數 df.dtypes#查看資料型別 df.index#查看行索引 df.value# 物件值,二維陣列 df.describe()#查看資料值列的匯總統計,計數,平均值,標準差,最小值,四分位數,最大值 df.info()#查看列索引,資料型別,非空計數和記憶體資訊
第四部分 資料的輸入輸出
第一節csv
df = DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,50,size = [50,5]), # 薪資情況 columns=['IT','化?','?物','教師','?兵']) #保存到相對路勁下檔案命名為 df.to_csv('./salary.csv', sep = ';',#分割符 header = True,#是否保存列索引 index = True)#是否保存行索引、 #加載 pd.read_csv('./salary.csv', sep = ';',# 默認是逗號 header = [0],#指定列索引 index_col=0) # 指定?索引 #加載 pd.read_table('./salary.csv', # 和read_csv類似,讀取限定分隔符的?本?件 sep = ';', header = [0],#指定列索引 index_col=1) # 指定?索引,IT作為?索引
第?節 Excel
pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple pip install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simpleimport numpy as np import pandas as pd df1 = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,50,size = [50,5]), # 薪資情況 columns=['IT','化?','?物','教師','?兵']) df2 = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,50,size = [150,3]),# 計算機科?的考試成績 columns=['Python','Tensorflow','Keras']) # 保存到當前路徑下,?件命名是:salary.xls df1.to_excel('./salary.xls', sheet_name = 'salary',# Excel中?作表的名字 header = True,# 是否保存列索引 index = False) # 是否保存?索引,保存?索引 pd.read_excel('./salary.xls', sheet_name=0,# 讀取哪?個Excel中?作表,默認第?個 header = 0,# 使?第??資料作為列索引 names = list('ABCDE'),# 替換?索引 index_col=1)# 指定?索引,B作為?索引 # ?個Excel?件中保存多個?作表 with pd.ExcelWriter('./data.xlsx') as writer: df1.to_excel(writer,sheet_name='salary',index = False) df2.to_excel(writer,sheet_name='score',index = False) pd.read_excel('./data.xlsx', sheet_name='salary') # 讀取Excel中指定名字的?作表第三節 SQL pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
import pandas as pd # SQLAlchemy是Python編程語?下的?款開源軟體,提供了SQL?具包及物件關系映射(ORM)?具 from sqlalchemy import create_engine df = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,50,size = [150,3]),# 計算機科?的考試 成績 columns=['Python','Tensorflow','Keras']) # 資料庫連接 conn = create_engine('mysql+pymysql://root:12345678@localhost/pandas? charset=UTF8MB4') # 保存到資料庫 df.to_sql('score',#資料庫中表名 conn,# 資料庫連接 if_exists='append')#如果表名存在,追加資料 # 從資料庫中加載 pd.read_sql('select * from score limit 10', # sql查詢陳述句 conn, # 資料庫連接 index_col='Python') # 指定?索引名
---------------------------------------------!!!!!!!!!第一次更新!!!!!!!!!!!----------------------------------------------------------
第五部分 資料的選取
第一節 資料獲取
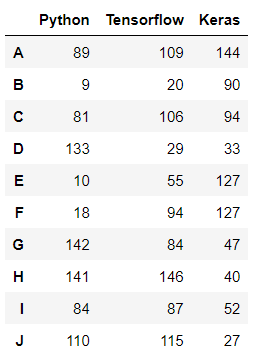
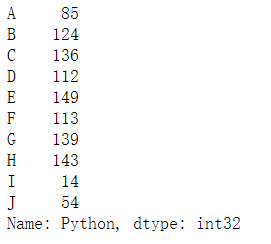
!!!---先匯入個資料---!!! df = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,150,size = [10,3]),# 計算機科?的考試成績 index = list('ABCDEFGHIJ'),# ?標簽 columns=['Python','Tensorflow','Keras'])
df.Python# 查看所在列資料 df['Python']# 查看所在列資料 df[['Python','Keras']]#獲取多列資料 df[1:3]#行切片操作 !!!--此處切片操作與資料的切片操作如出一轍--!!!
使用 loc[] 進行資料獲取 loc通過行列標簽進行索引取數操作
df.loc[['A','B']]#選取行標簽 df.loc[['A','B'],['Python','Keras']]#根據行列標簽選取對飲資料 df.loc[:,['Python','Keras']]#保留所有行 df.loc[::2,['Python','Keras']]#每隔2行取出一行資料 df.loc['A',['Python','Keras']]#根據行標簽選取出對應資料 #此處就不截圖展示了
使用 iloc[] 進行資料獲取 iloc通過行列整數標簽進行索引取數操作
df.iloc[2:4]#利用整數行切片操作與Numpy相似 !!!--此處切片操作與資料的切片操作如出一轍--!!! df.iloc[1:3,1:2]#利用整數對行和列進行切片 df.iloc[1:3:]#行切片 df.iloc[:,0:1]#列切片
Boolean索引
cond1 = df.Python > 100 # 判斷Python分數是否?于100,回傳值是boolean型別的Series df[cond1] # 回傳Python分數?于100分的?戶所有考試科?資料 cond2 = (df.Python > 50) & (df['Keras'] > 50) # &與運算 df[cond2] # 回傳Python和Keras同時?于50分的?戶的所有考試科?資料 df[df > 50]# 選擇DataFrame中滿?條件的值,如果滿?回傳值,不然回傳空資料NaN df[df.index.isin(['A','C','F'])] # isin判斷是否在陣列中,回傳也是boolean型別值
第六部分 資料集成
第?節 concat資料串聯
#再建立兩個資料矩陣 df1 = pd.DataFrame(np.random.randint(1,151,size=10), index = list('ABCDEFGHIJ'), columns=['Science']) df2 = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,150,size = [10,3]), index = list('KLMNOPQRST'), columns=['Python','Tensorflow','Keras'])
pd.concat([df,df2],axis=0)#df2串聯拼接到df1下方 pd.concat([df,df1],axis=1)#df1串聯拼接到df的左側 df.append(df1) # 在df1后?追加df2
第二節 插入
insert()插入一列
注意:如果使用insert()插入一列時,那么插入的這一列的長度必須和被插入的行數長度相等
#插入一列c++ df.insert(loc=1, column='C++', value=np.random.randint(0,151,size=(10))) df.insert(loc = 1,column='Python3.8,value=https://www.cnblogs.com/t-dashuai/p/2048)
第三節 資料的鏈接(join SQL風格)
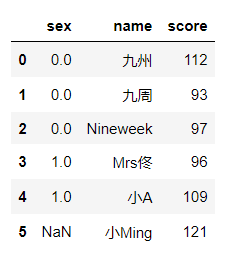
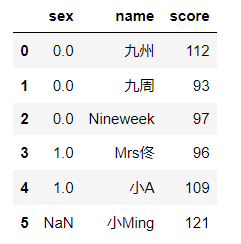
資料集的合并(merge)或連接(join)運算是通過?個或者多個鍵將資料鏈接起來的,這些運算是關系型資料庫的核?操作,pandas的merge函式是資料集進?join運算的主要切?點,#先建立兩組資料 df1 = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/{'sex':np.random.randint(0,2,size=6),'name':['九州','九周','Nineweek','Mrs佟','小A','小C']}) df2 = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/{'score':np.random.randint(90,151,size=6),'name':['九州','九周','Nineweek','Mrs佟','小A','小Ming']})
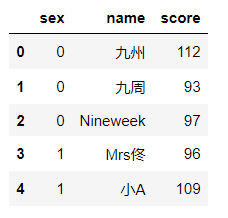
pd.merge(df1,df2) #(內連接) 在使用merge()合并中merge自動去除了空資料 pd.merge(df1,df2,how='left')#左鏈接 pd.merge(df1,df2,how='right')#右鏈接
---------------------------------------------!!!!!!!!!第二次更新!!!!!!!!!!!----------------------------------------------------------
第七部分 資料清洗
第?節 duplicated篩選重復資料
duplicated是以自上向下的順序進行篩選如果行值相同就回傳TRUE,
#創建一個分值資料 df2 = pd.DataFrame(data=https://www.cnblogs.com/t-dashuai/p/{'Name':['九州','Mrs佟','Nineweek',None,np.NAN,'Mrs佟'],'Sex':[0,1,0,1,0,1],'Score':[89,100,67,90,98,100]})
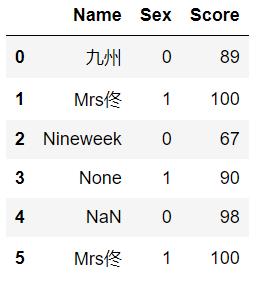
df2.duplicated()#檢查重復值 以Boolean形式進行輸出展示 df2.duplicated().sum()#列印有多少重復值 df2[df2.duplicated()]#列印重復值 df2[df2.duplicated()==False]#列印非重復值 df2.drop_duplicates()#洗掉重復值(此操作并不是在資料源本身進行洗掉操作) df2.drop_duplicates(inplace=True)#洗掉重復值(此操作是在資料源本身進行洗掉操作)
第二節 過濾空資料
df2.isnull()#檢查是否存在空值(可以查到NAN值和None值) df2.dropna(how = 'any') # 洗掉空資料(此操作并不是在資料源本身進行洗掉操作) df2.dropna(how = 'any',inplace=True)# 洗掉空資料(此操作是在資料源本身進行洗掉操作) df2.fillna(value=https://www.cnblogs.com/t-dashuai/p/'小A')#填充空資料(此操作并不是在資料源本身進行洗掉操作) df2.fillna(value=https://www.cnblogs.com/t-dashuai/p/'小A',inplace=True)#填充空資料(此操作是在資料源本身進行洗掉操作)
第三節 過濾指定行或列
del df2['Sex'] # 直接洗掉某列 df2.drop(labels = ['price'],axis = 1)# 洗掉指定列 df2.drop(labels = [0,1,5],axis = 0) # 洗掉指定?
filter函式:選取保留的資料過濾其他資料
df2.filter(items=['Name', 'Score'])#保留‘Name’,‘Score’兩列 df2.filter(like='S',axis = 1)# 保留列標簽包含‘S’的列(axis=1表示列,axis=0表示行) df.filter(regex='S$', axis=1)#正則方式進行篩選
第八部分 資料轉換
第一節 rename和replace的轉換標簽個元素
#改變行列索引 df2.rename(index = {0:10,1:11},columns={'Name':'StName'})#將行索引0換為10,1換為11;列索引Name換為StName #替換元素值 df2.replace(100,102)#將所有的100替換為102 df2.replace([89,67],78)#將所有的89和67替換為78 df2.replace({'九州':'JZ',None:'九州'})#根據字典的鍵值對進行替換 df2.replace({'Sex':1},1024)#將Sex列的1全部替換為1024
第二節 apply和Transform
相同點:都能針對Dataframe的特征的計算,常與groupby()分組聚合方式下節更新方法連用
不同點:aplly引數可以是自定義函式,包括簡單的求和函式以及復制的特征間的差值函式等,apply不能直接使用python的內置函式,比如sum、max、min,
Transform引數不能是自定義的特征互動函式,因為transform是針對每一元素(即每一列特征操作)進行計算,
#先建立陣列 df = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,150,size = [10,3]),index = list('ABCDEFGHIJ'),columns=['Python','En','Math'])
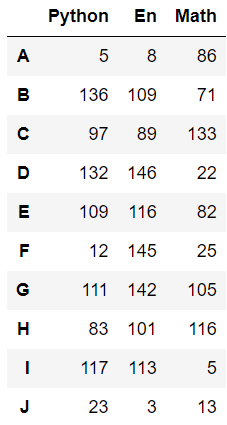
df['Python'].apply(lambda x:True if x >50 else False)#選取python學科中的大于50的資料
df.apply(lambda x : x.median(),axis = 0) # 列的中位數

#自定義函式演算法 def avg(x): return (x.mean(),x.max(),x.min(),x.var().round(1)) df.apply(avg,axis=0)#輸出列的平均值,最大值,最小值,方差保留一位小數
# ?列執?多項計算 df['Python'].transform([np.sqrt,np.log10]) # 對單列資料處理做開平方和對數運算
#自定義函式演算法 def convert(x): if x > 140: x -= 12 else: x += 12 return x df.transform({'Python':np.sqrt,'En':np.log10,'Math':convert}).round(1)# 對多列資料處理做開不同運算
---------------------------------------------!!!!!!!!!第三次更新!!!!!!!!!!!----------------------------------------------------------
第九部分 資料重塑
df = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,150,size = [20,3]), index = pd.MultiIndex.from_product([list('ABCDEFHIJK'),['一期','二期']]),# 多層索引 columns=['Python','En','Math'])
df.unstack(level=1)#行作列 df.stack()#列作行 df.mean(level=1)#各學科每期平均分 df.mean(level=0)#各學員平均分 df.mean()#各科平均分
第十部分 統計方法函式
pandas擁有多種常?的數學統計?法,可以滿足大多半的資料處理,對Series和DataFrame行計算并回傳Series形式的陣列#創建資料 df = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,150,size = [10,3]), index = list('ABCDEFGHIJ'), columns=['Python','En','Math']) df.count() # ?NA值的數量 df.max(axis = 0) #軸0最?值,即每?列最?值 df.min() #默認計算軸0最?值 df.median() # 中位數 df.sum() # 求和 df.mean(axis = 1) #計算每??的平均值 df.quantile(q = [0.2,0.5,0.9]) # 分位數 df.describe() # 查看數值型列的匯總統計,計數、平均值、標準差、最?值、四分位數、最?值 df['Python'].value_counts() # 統計元素出現次數 df['Math'].unique() # 去重 df.cumsum() # 累加 df.cumprod() # 累乘 df.std() # 標準差 df.var() # ?差 df.cummin() # 累計最?值 df.cummax() # 累計最?值 df.diff() # 計算差分 df.pct_change() # 計算百分?變化 df.cov() # 屬性的協?差 df['Python'].cov(df['Math']) # Python和Math的協?差 df.corr() # 所有屬性相關性系數 df.corrwith(df['En']) # 單?屬性相關性系數
#標簽索引計算方式 df['Python'].argmin() # 計算Python列的最?值位置 df['Math'].argmax() # 計算Math列的最?值位置 df.idxmax() # 最?值索引標簽 df.idxmin() # 最?值索引標簽
第十一部分 排序
#創建資料 df = pd.DataFrame(data = https://www.cnblogs.com/t-dashuai/p/np.random.randint(0,150,size = [10,3]), index = list('ABCDEFGHIJ'), columns=['Python','En','Math']) ran = np.random.permutation(10) df = df.take(ran)#隨機排列行索引
df.sort_index(axis=0,ascending=True)#按照行索引降序排序 df.sort_index(axis=1,ascending=True)#按照列索引降序排序
df.sort_values(by='Python')#根據Python列的值降序排序 df.sort_values(by=['Python','Math'])#先按找Python排序在按照Math排序
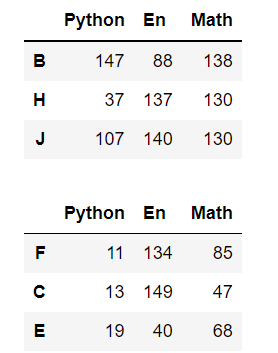
lage = df.nlargest(3,columns='Math') # 根據屬性Math排序,回傳最?3個資料 samll = df.nsmallest(3,columns='Python') # 根據屬性Python排序,回傳最?3個資料 display(lage,samll)
第十二部分 cut與qcut的分箱處理
cut函式對資料進行分箱處理的操作, 也就是 把一段連續的值切分成若干段,每一段的值看成一個分類,這個把連續值轉換成離散值的程序,我們叫做分箱處理cut會按照資料值由大到小的順序將資料分割為若干分,并且使每組范圍大致相等
qcut是按變數的數量來對變數進行分割,并且盡量保證每個分組里變數的個數相同,
df['py_cut'] = pd.cut(df.Python,bins=4)#按照資料范圍分箱 df['en_cut'] = pd.cut(df.En,bins=4)#按照資料個數分箱 df['q_評級'] = pd.qcut(df.Python,q = 4,# 4等分 labels=['差','中','良','優']) # 分箱后分類 df['c_評級'] = pd.cut(df.En,#分箱資料 bins = [0,60,90,120,150],#分箱斷點 right = False,# 左閉右開原則 labels=['差','中','良','優'])# 分箱后分類
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/311928.html
標籤:Python