我有一個看起來像這樣的txt檔案
1000 lewis hamilton 36
1001 sebastian vettel 34
1002 lando norris 21
我希望它們看起來像這樣
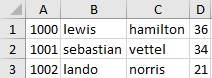
我在這里嘗試了解決方案,但在嘗試打開它時它給了我一個空白的 excel 檔案和錯誤
有超過一百萬行,每行包含大約 10 列
最后一件事,我不能 100% 確定它們是否被制表符限制,因為有些列看起來它們之間的空間比其他列更大,但是當我按下退格鍵時,它們粘在一起,所以我猜是
uj5u.com熱心網友回復:
您可以使用 pandasread_csv讀取您的 txt 檔案,然后將其保存為 excel 檔案.to_excel
df = pd.read_csv('your_file.txt' , delim_whitespace=True)
df.to_excel('your_file.xlsx' , index = False)
這里有一些檔案:
pandas.read_csv : https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
.to_excel : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_excel.html
uj5u.com熱心網友回復:
如果您不確定欄位的分隔方式,可以使用“\s”按空格分隔。
import pandas as pd
df = pd.read_csv('f1.txt', sep="\s ", header=None)
# you might need: pip install openpyxl
df.to_excel('f1.xlsx', 'Sheet1')
隨機分隔欄位示例 (f1.txt):
1000 lewis hamilton 2 36
1001 sebastian vettel 8 34
1002 lando norris 6 21
如果某些行的列數比第一行多,則導致:
ParserError:標記資料時出錯。C 錯誤:第 5 行中應有 5 個欄位,看到 6
您可以使用以下方法忽略它們:
df = pd.read_csv('f1.txt', sep="\s ", header=None, error_bad_lines=False)
這是一個資料示例:
1000 lewis hamilton 2 36
1001 sebastian vettel 8 34
1002 lando norris 6 21
1003 charles leclerc 1 3
1004 carlos sainz ferrari 2 2
最后一行將被忽略:
b'跳過第 5 行:預期 5 個欄位,看到 6\n'
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/315028.html
上一篇:字串中數字字符數的資料驗證