我每天都在嘗試在 Jupyter Notebook(來自 deepnote.com)中運行一個自動化程序,但是在運行 a 的第一次迭代 while loop 并開始下一次迭代(在for loop內部while loop)之后,虛擬機崩潰了留言如下:
KernelInterrupted:被 Jupyter 內核中斷的執行
這是代碼:
.
.
.
while y < 5:
print(f'\u001b[45m Try No. {y} out of 5 \033[0m')
#make the driver wait up to 10 seconds before doing anything.
driver.implicitly_wait(10)
#values for the example.
#Declaring several variables for looping.
#Let's start at the newest page.
link = 'https...'
driver.get(link)
#Here we use an Xpath element to get the initial page
initial_page = int(driver.find_element_by_xpath('Xpath').text)
print(f'The initial page is the No. {initial_page}')
final_page = initial_page 120
pages = np.arange(initial_page, final_page 1, 1)
minimun_value = 0.95
maximum_value = 1.2
#the variable to_place is set as a string value that must exist in the rows in order to be scraped.
#if it doesn't exist it is ignored.
to_place = 'A particular place'
#the same comment stated above is applied to the variable POINTS.
POINTS = 'POINTS'
#let's set a final dataframe which will contain all the scraped data from the arange that
#matches with the parameters set (minimun_value, maximum value, to_place, POINTS).
df_final = pd.DataFrame()
dataframe_final = pd.DataFrame()
#set another final dataframe for the 2ND PART OF THE PROCESS.
initial_df = pd.DataFrame()
#set a for loop for each page from the arange.
for page in pages:
#INITIAL SEARCH.
#look for general data of the link.
#amount of results and pages for the execution of the for loop, "page" variable is used within the {}.
url = 'https...page={}&p=1'.format(page)
print(f'\u001b[42m Current page: {page} \033[0m ' '\u001b[42m Final page: ' str(final_page) '\033[0m ' '\u001b[42m Page left: ' str(final_page-page) '\033[0m ' '\u001b[45m Try No. ' str(y) ' out of ' str(5) '\033[0m' '\n')
driver.get(url)
#Here we order the scrapper to try finding the total number of subpages a particular page has if such page IS NOT empty.
#if so, the scrapper will proceed to execute the rest of the procedure.
try:
subpages = driver.find_element_by_xpath('Xpath').text
print(f'Reading the information about the number of subpages of this page ... {subpages}')
subpages = int(re.search(r'\d{0,3}$', subpages).group())
print(f'This page has {subpages} subpages in total')
df = pd.DataFrame()
df2 = pd.DataFrame()
print(df)
print(df2)
#FOR LOOP.
#search at each subpage all the rows that contain the previous parameters set.
#minimun_value, maximum value, to_place, POINTS.
#set a sub-loop for each row from the table of each subpage of each page
for subpage in range(1,subpages 1):
url = 'https...page={}&p={}'.format(page,subpage)
driver.get(url)
identities_found = int(driver.find_element_by_xpath('Xpath').text.replace('A total of ','').replace(' identities found','').replace(',',''))
identities_found_last = identities_found%50
print(f'Página: {page} de {pages}') #AT THIS LINE CRASHED THE LAST TIME
.
.
.
#If the particular page is empty
except:
print(f'This page No. {page} IT'S EMPTY ˉ\_???????????_/ˉ, ?NEXT! ')
.
.
.
y = 1
最初我認為這 KernelInterrupted Error 是由于我的虛擬機在運行第二次迭代時缺少虛擬記憶體而引發的......
但是經過幾次測驗后,我發現我的程式根本不消耗 RAM,因為虛擬 RAM 在整個程序中并沒有發生太大變化,直到內核崩潰。我可以保證。
所以現在我想可能是我的虛擬機的虛擬 CPU是導致內核崩潰的原因,但如果是這種情況,我只是不明白為什么,這是我第一次必須處理這種情況,這個程式在我的電腦上完美運行。
這里有資料科學家或機器學習工程師可以幫助我嗎?提前致謝。
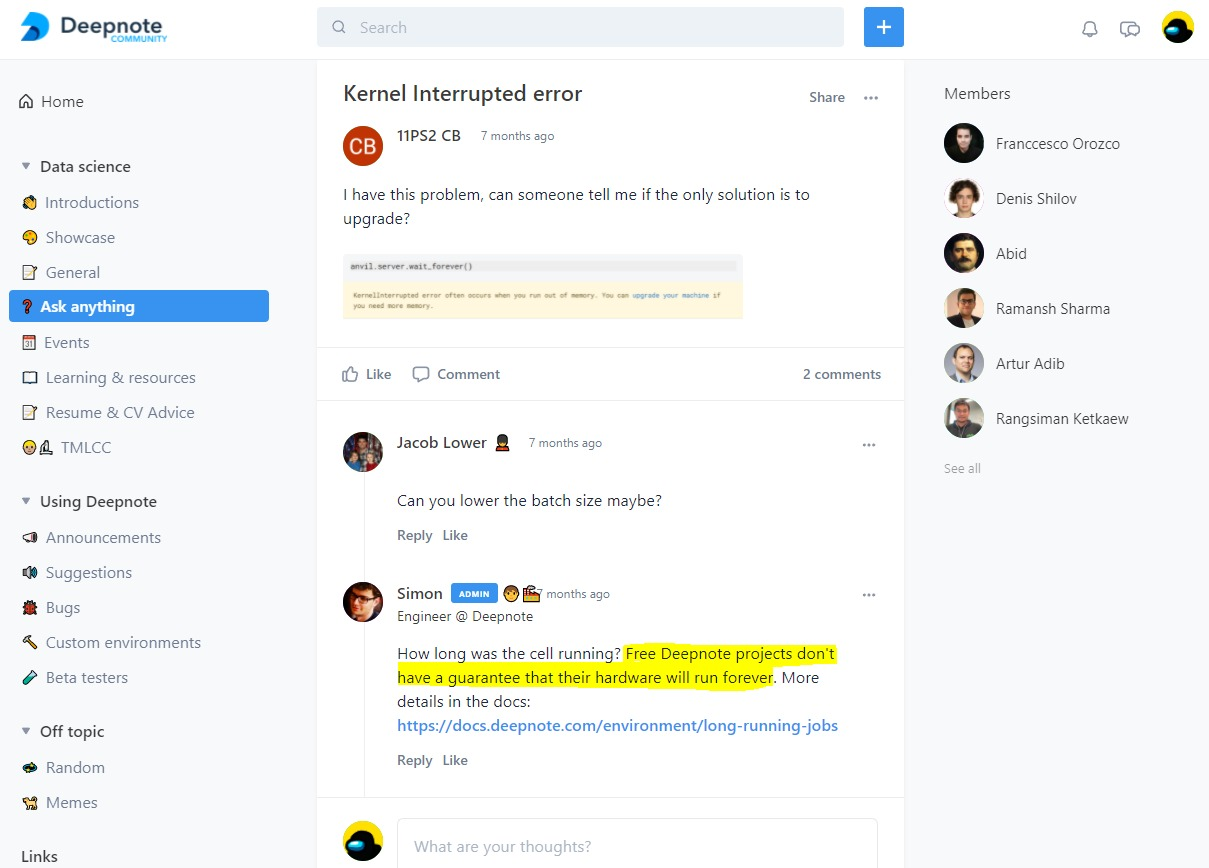
uj5u.com熱心網友回復:
我在 Deepnote 社區論壇本身找到了答案,簡單地說,無論在其 VM 中執行什么程式,該平臺的“免費層”機器都不能保證永久運行(24 小時 / 7 小時)。
就是這樣。問題解決了。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/317041.html
上一篇:使用BeautifulSoup抓取以從自行車比賽中提取資料
下一篇:并非所有容器都使用美湯裝載