十月份的黃金周,乃至整個十月份,妥妥的是《長津湖》的天下,才小半個月票房就已經突破44億,都快追上戰狼2了,貓眼評分9.5,口碑超高,2021年票房口碑雙豐收大黑馬!

今天我們通過爬取貓眼的電影評論,進行可視化分析,康康長津湖為什么這么受歡迎,最后教大家進行票房預測,千萬不要錯過!
資料獲取
貓眼評論爬取,還是那么老一套,直接構造 API 介面資訊即可
url = "https://m.maoyan.com/mmdb/comments/movie/257706.json?v=yes&offset=30" payload={} headers = { 'Cookie': '_lxsdk_cuid=17c188b300d13-0ecb2e1c54bec6-a7d173c-100200-17c188b300ec8; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1633622378; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; __mta=87266087.1633622378325.1633622378325.1633622378325.1; uuid_n_v=v1; iuuid=ECBA18D0278711EC8B0DFD12EB2962D2C4A641A554EF466B9362A58679FDD6CF; webp=true; ci=55%2C%E5%8D%97%E4%BA%AC; ci=55%2C%E5%8D%97%E4%BA%AC; ci=55%2C%E5%8D%97%E4%BA%AC; featrues=[object Object]; _lxsdk=92E6A4E0278711ECAE4571A477FD49B513FE367C52044EB5A6974451969DD28A; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1633622806', 'Host': 'm.maoyan.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36' } response = requests.request("GET", url, headers=headers, data=https://www.cnblogs.com/hahaa/p/payload) print(response.json())
這么幾行代碼,我們就可以得到如下結果
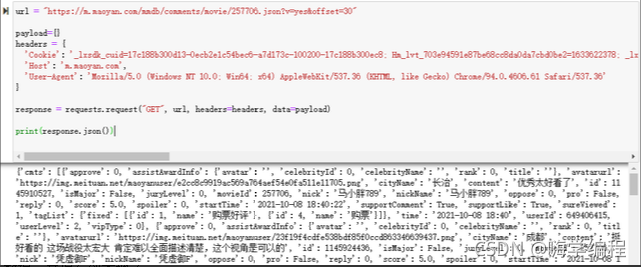
獲取到資料后,我們就可以決議回傳的 json 資料,并保存到本地了,
#兄弟們學習python,有時候不知道怎么學,從哪里開始學,掌握了基本的一些語法或者做了兩個案例后,不知道下一步怎么走,不知道如何去學習更加高深的知識, #那么對于這些大兄弟們,我準備了大量的免費領取視頻教程,PDF電子書籍,以及視頻源的源代碼! #還會有大佬解答! #都在下面這個群里了,872937351 #歡迎加入,一起討論 一起學習!
先寫一個保存資料的函式
def save_data_pd(data_name, list_info): if not os.path.exists(data_name + r'_data.csv'): # 表頭 name = ["comment_id","approve","reply","comment_time","sureViewed","nickName", "gender","cityName","userLevel","user_id","score","content"] # 建立DataFrame物件 file_test = pd.DataFrame(columns=name, data=https://www.cnblogs.com/hahaa/p/list_info) # 資料寫入 file_test.to_csv(data_name + r'_data.csv', encoding='utf-8', index=False) else: with open(data_name + r'_data.csv', 'a+', newline='', encoding='utf-8') as file_test: # 追加到檔案后面 writer = csv.writer(file_test) # 寫入檔案 writer.writerows(list_info)
直接通過 Pandas 來保存資料,可以省去很多資料處理的事情
接下來撰寫決議 json 資料的函式
def get_data(json_comment): list_info = [] for data in json_comment: approve = data["approve"] comment_id = data["id"] cityName = data["cityName"] content = data["content"] reply = data["reply"] # 性別:1男,2女,0未知 if "gender" in data: gender = data["gender"] else: gender = 0 nickName = data["nickName"] userLevel = data["userLevel"] score = data["score"] comment_time = data["startTime"] sureViewed = data["sureViewed"] user_id = data["userId"] list_one = [comment_id, approve, reply, comment_time, sureViewed, nickName, gender, cityName, userLevel, user_id, score, content] list_info.append(list_one) save_data_pd("maoyan", list_info)
我們把主要資訊提取出來,比如用戶的 nickname,評論時間,所在城市等等,然后把代碼整合,構造爬取得 url 就好了!
def fire(): tmp = "https://m.maoyan.com/mmdb/comments/movie/257706.json?v=yes&offset=" payload={} headers = { 'Cookie': '_lxsdk_cuid=17c188b300d13-0ecb2e1c54bec6-a7d173c-100200-17c188b300ec8; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1633622378; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; __mta=87266087.1633622378325.1633622378325.1633622378325.1; uuid_n_v=v1; iuuid=ECBA18D0278711EC8B0DFD12EB2962D2C4A641A554EF466B9362A58679FDD6CF; webp=true; ci=55%2C%E5%8D%97%E4%BA%AC; ci=55%2C%E5%8D%97%E4%BA%AC; ci=55%2C%E5%8D%97%E4%BA%AC; featrues=[object Object]; _lxsdk=92E6A4E0278711ECAE4571A477FD49B513FE367C52044EB5A6974451969DD28A; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1633622806', 'Host': 'm.maoyan.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36' } for i in range(0, 3000, 15): url = tmp + str(i) print(url) response = requests.request("GET", url, headers=headers, data=https://www.cnblogs.com/hahaa/p/payload) comment = response.json() if not comment.get("hcmts"): break hcmts = comment['hcmts'] get_data(hcmts) cmts = comment['cmts'] get_data(cmts) time.sleep(10)
保存到本地的資料
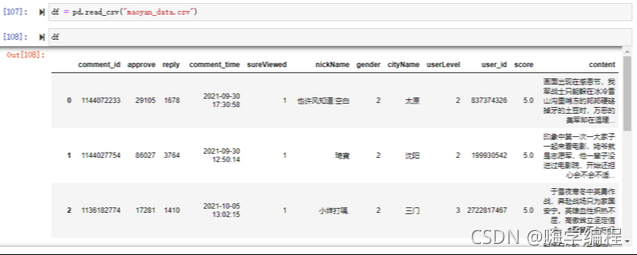
我們就來進行相關的可視化分析了
可視化分析
1、資料清洗
首先我們根據 comment_id 來去除重復資料
df_new = df.drop_duplicates(['comment_id'])
對于評論內容,我們進行去除非中文的操作,
def filter_str(desstr,restr=''): #過濾除中文以外的其他字符 res = re.compile("[^\u4e00-\u9fa5^,^,^.^,^【^】^(^)^(^)^“^”^-^!^!^?^?^]") # print(desstr) res.sub(restr, desstr)
2、評論點贊及回復榜
來看看哪些評論是被點贊最多的
approve_sort = df_new.sort_values(by=['approve'], ascending=False) approve_sort = df_new.sort_values(by=['approve'], ascending=False) x_data = approve_sort['nickName'].values.tolist()[:10] y_data = approve_sort['approve'].values.tolist()[:10] b = (Bar() .add_xaxis(x_data) .add_yaxis('',y_data) .set_global_opts(title_opts = opts.TitleOpts(title='評論點贊前十名')) .set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right')) .reversal_axis() ) grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE)) grid.add(b, grid_opts=opts.GridOpts(pos_left="20%")) grid.render_notebook()
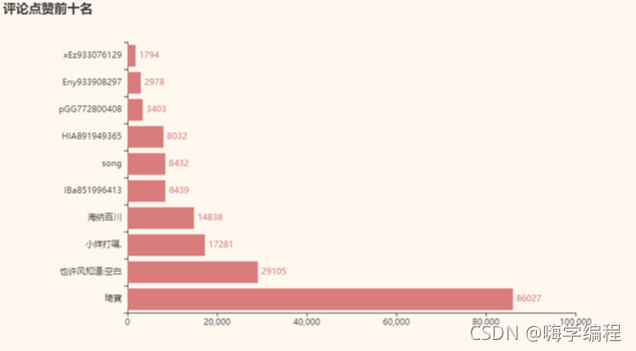
我們可以看到榜首是一個叫“琦寶”的觀眾寫的評論,點贊量86027,
再看看評論回復
reply_sort = df_new.sort_values(by=['reply'], ascending=False) x_data = reply_sort['nickName'].values.tolist()[:10] y_data = reply_sort['reply'].values.tolist()[:10] b = (Bar() .add_xaxis(x_data) .add_yaxis('',y_data) .set_global_opts(title_opts = opts.TitleOpts(title='評論回復前十名')) .set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right')) .reversal_axis() ) grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE)) grid.add(b, grid_opts=opts.GridOpts(pos_left="20%")) grid.render_notebook()
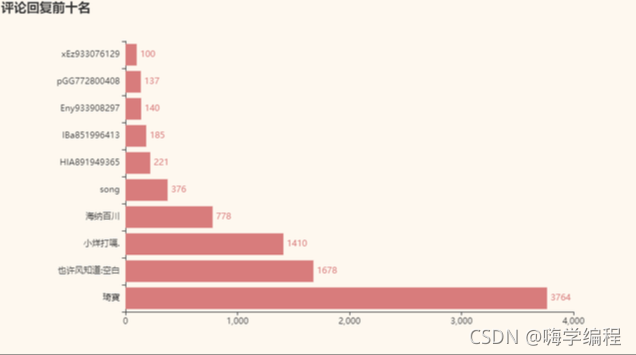
回復量最高的同樣是“琦寶”的評論,那么他到底寫了什么呢?
df_new[df_new['nickName'].str.contains('琦寶')]['content'].values.tolist()[0]
Output:
'印象中第一次一大家子一起來看電影,姥爺就是志愿軍,他一輩子沒進過電影院,開始還擔心會不會不適應,感謝影院作業人員的照顧,
姥爺全程非常投入,我坐在旁邊看到他偷偷抹了好幾次眼淚,剛才我問電影咋樣,一直念叨“好,好哇,我們那時候就是那樣的,就是那樣的……”\n忽然覺得歷史長河與我竟如此之近,剛剛的三個小時我看到的是遙遠的70年前、是教科書里的戰爭,更是姥爺的19歲,是真真切切的、他的青春年代!'
還真的是非常走心的評論,而且自己的家人就有經歷過長津湖戰役的經歷,那么在影院觀影的時候,肯定會有不一樣的感受!
當然我們還可以爬取每條評論的reply資訊,通過如下介面:
https://i.maoyan.com/apollo/apolloapi/mmdb/replies/comment/1144027754.json?v=yes&offset=0
只需要替換 json 檔案名稱為對應的 comment_id 即可,這里就不再詳細介紹了,感興趣的朋友自行探索呀
下面我們來看一下整體評論資料的情況
3、各城市排行
來看看哪些城市的評論最多呢
result = df_new['cityName'].value_counts()[:10].sort_values() x_data = result.index.tolist() y_data = result.values.tolist() b = (Bar() .add_xaxis(x_data) .add_yaxis('',y_data) .set_global_opts(title_opts = opts.TitleOpts(title='評論城市前十')) .set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right')) .reversal_axis() ) grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE)) grid.add(b, grid_opts=opts.GridOpts(pos_left="20%")) grid.render_notebook()
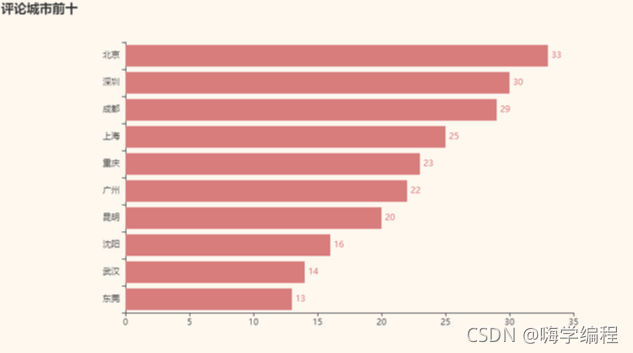
一線大城市紛紛上榜,看來這些城市的愛國主義教育做得還是要好很多呀!
再來看看城市的全國地圖分布:
result = df_new['cityName'].value_counts().sort_values() x_data = result.index.tolist() y_data = result.values.tolist() city_list = [list(z) for z in zip(x_data, y_data)]
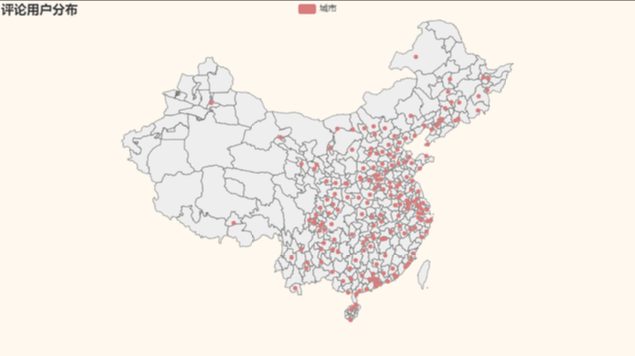
可以看到,這個評論城市的分布,也是與我國總體經濟的發展情況相吻合的
4、性別分布
再來看看此類電影,對什么性別的觀眾更具有吸引力
attr = ["其他","男","女"] b = (Pie() .add("", [list(z) for z in zip(attr, df_new.groupby("gender").gender.count().values.tolist())]) .set_global_opts(title_opts = opts.TitleOpts(title='性別分布')) .set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right')) ) grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE)) grid.add(b, grid_opts=opts.GridOpts(pos_left="20%")) grid.render_notebook()
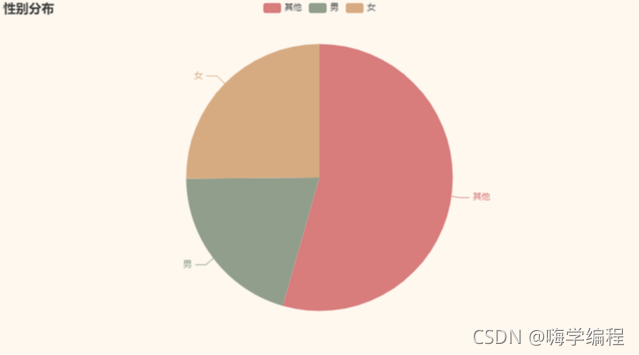
在填寫了性別的資料當中,女性竟然多一些,這還是比較出乎意料的
5、是否觀看
貓眼是可以在沒有觀看電影的情況下進行評論的,我們來看看這個資料的情況
result = df_new["sureViewed"].value_counts()[:10].sort_values().tolist() b = (Pie() .add("", [list(z) for z in zip(["未看過", "看過"], result)]) .set_global_opts(title_opts = opts.TitleOpts(title='是否觀看過')) .set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right')) ) grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE)) grid.add(b, grid_opts=opts.GridOpts(pos_left="20%")) grid.render_notebook()
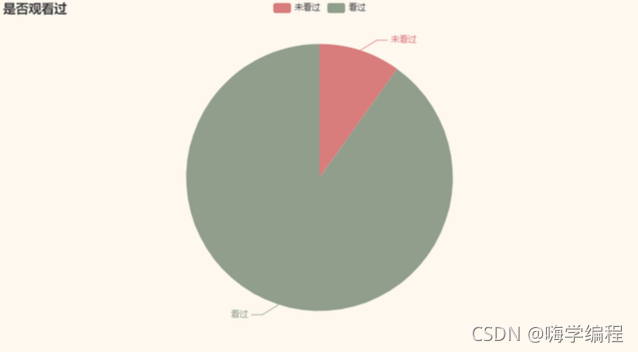
大部分人都是在觀看了之后才評論的,這要在一定程度上保證了評論和打分的可靠性
6、評分分布
貓眼頁面上是10分制,但是在介面當中是5分制
result = df_new["score"].value_counts().sort_values() x_data = result.index.tolist() y_data = result.values.tolist() b = (Bar() .add_xaxis(x_data) .add_yaxis('',y_data) .set_global_opts(title_opts = opts.TitleOpts(title='評分分布')) .set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right')) .reversal_axis() ) grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE)) grid.add(b, grid_opts=opts.GridOpts(pos_left="20%")) grid.render_notebook()
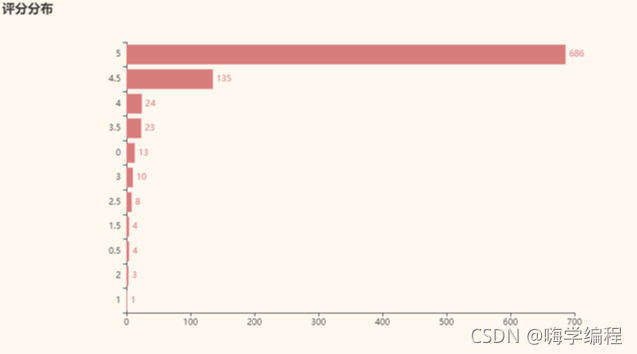
可以看到5-4.5評論占據了大部分,口碑是真的好啊
7、評論時間分布
對于評論時間,我這里直接使用了原生的 echarts 來作圖
from collections import Counter result = df_new["comment_time"].values.tolist() result = [i.split()[1].split(":")[0] + "點" for i in result] result_dict = dict(Counter(result)) result_list = [] for k,v in result_dict.items(): tmp = {} tmp['name'] = k tmp['value'] = v result_list.append(tmp) children_dict = {"children": result_list}

能夠看出,在晚上的19點和20點,都是大家寫評論的高峰期,一天的繁忙結束后,寫個影評放松下,
8、每天評論分布
接下來是每天的評論分布情況
result = df_new["comment_time"].values.tolist() result = [i.split()[0] for i in result] result_dict = dict(Counter(result)) b = (Pie() .add("", [list(z) for z in zip(result_dict.keys(), result_dict.values())]) .set_global_opts(title_opts = opts.TitleOpts(title='每天評論數量')) .set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right')) ) grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE)) grid.add(b, grid_opts=opts.GridOpts(pos_left="20%")) grid.render_notebook()
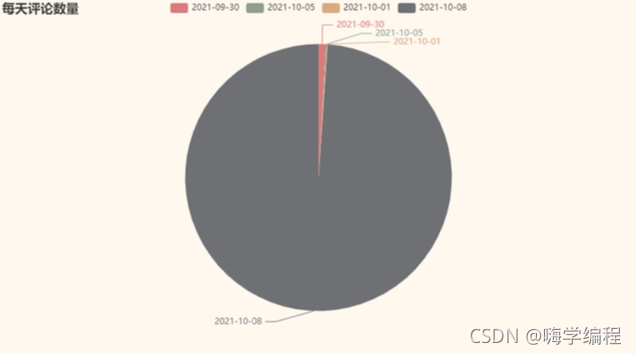
就目前來看,幾乎所有的評論都集中在10月8號,難道是上班第一天,不想上班,只想摸魚?
9、用戶等級分布
來看下貓眼評論用戶的等級情況,雖然不知道這個等級有啥用
result = df_new['userLevel'].value_counts()[:10].sort_values() x_data = result.index.tolist() y_data = result.values.tolist() b = (Bar() .add_xaxis(x_data) .add_yaxis('',y_data) .set_global_opts(title_opts = opts.TitleOpts(title='用戶等級')) .set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right')) .reversal_axis() ) grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE)) grid.add(b, grid_opts=opts.GridOpts(pos_left="20%")) grid.render_notebook()
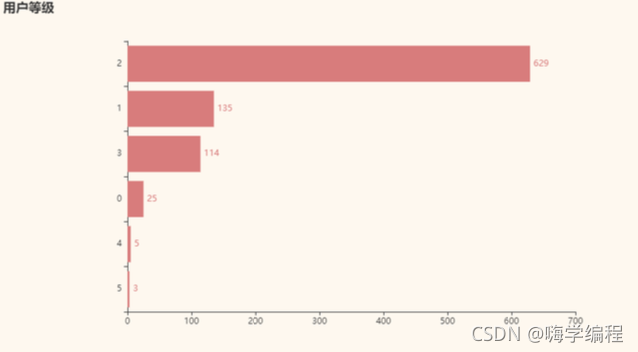
大家基本都是 level2,哈哈哈哈,普羅大眾嘛
10、主創提及次數
我們再來看看在評論中,各位主創被提及的次數情況
name = ["吳京", "易烊千璽", "段奕宏", "朱亞文", "李晨", "胡軍", "王寧", "劉勁", "盧奇", "曹陽", "李軍", "孫毅", "易", "易烊", "千璽" ] def actor(data, name): counts = {} comment = jieba.cut(str(data), cut_all=False) # 去停用詞 for word in comment: if word in name: if word == "易" or word == "千璽" : word = "易烊千璽" counts[word] = counts.get(word,0)+1 return counts counts = actor(','.join(df_comment.values.tolist()), name)
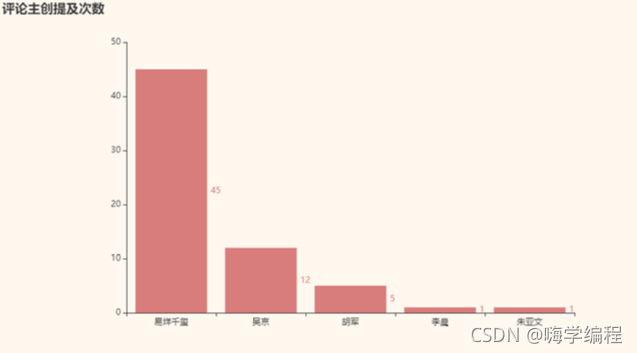
毫無疑問,易烊千璽高居榜首,可能媽媽粉比較多吧,不過人家演技確實也在線
11、評論詞云
最后來看看評論的詞云情況吧
font = r'C:\Windows\Fonts\FZSTK.TTF' STOPWORDS = {"回復", "@", "我", "她", "你", "他", "了", "的", "吧", "嗎", "在", "啊", "不", "也", "還", "是", "說", "都", "就", "沒", "做", "人", "趙薇", "被", "不是", "現在", "什么", "這", "呢", "知道", "鄧", "我們", "他們", "和", "有", "", "", "要", "就是", "但是", "而", "為", "自己", "中", "問題", "一個", "沒有", "到", "這個", "并", "對"} def wordcloud(data, name, pic=None): comment = jieba.cut(str(data), cut_all=False) words = ' '.join(comment) img = Image.open(pic) img_array = np.array(img) wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font, mask=img_array, stopwords=STOPWORDS, contour_width=3, contour_color='steelblue') wc.generate(words) wc.to_file(name + '.png')

明日票房預測
這里我們使用線性回歸來進行簡單的票房預測,畢竟票房是一個超級復雜的事物,沒有辦法完全準確地進行估計
我們先通過 AKShare 庫克來獲取這幾天《長津湖》的票房情況
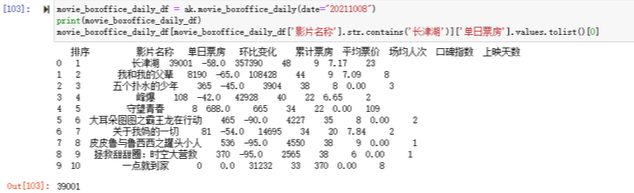
movie_boxoffice_daily_df = ak.movie_boxoffice_daily(date="20211008") print(movie_boxoffice_daily_df) movie_boxoffice_daily_df[movie_boxoffice_daily_df['影片名稱'].str.contains('長津湖')]['單日票房'].values.tolist()[0]
接下來畫散點圖,看下趨勢情況,
def scatter_base(choose, values, date) -> Scatter: c = ( Scatter() .add_xaxis(choose) .add_yaxis("%s/每天票房" % date, values) .set_global_opts(title_opts=opts.TitleOpts(title=""), # datazoom_opts=opts.DataZoomOpts(), yaxis_opts=opts.AxisOpts( axislabel_opts=opts.LabelOpts(formatter="{value} /萬") ) ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) return c date_list = create_assist_date("20211001", "20211008") value_list = get_data("長津湖", date_list) scatter_base(date_list, value_list, '長津湖').render_notebook()
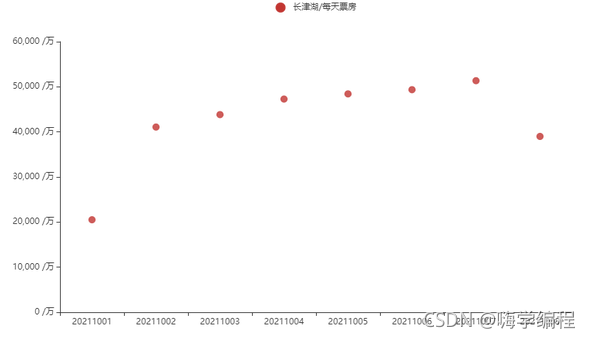
可以看到,從一號開始,單日票房逐步增長,7號達到最高峰,8號開始回落
下面我們來進行資料擬合,使用 sklearn 提供的 linear_model 來進行
date_list = create_assist_date("20211001", "20211008") value_list = get_data("長津湖", date_list) X = np.array([1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008]) X = X.reshape(-1, 1) y = value_list model = pl.make_pipeline( sp.PolynomialFeatures(5), # 多項式特征拓展器 lm.LinearRegression() # 線性回歸器 ) # 訓練模型 model.fit(X, y) # 求預測值y pred_y = model.predict(X) print(pred_y) # 繪制多項式回歸線 px = np.linspace(X.min(), X.max(), 1000) px = px.reshape(-1, 1) pred_py = model.predict(px) # 繪制影像 mp.figure("每天票房資料", facecolor='lightgray') mp.title('每天票房資料 Regression', fontsize=16) mp.tick_params(labelsize=10) mp.grid(linestyle=':') mp.xlabel('x') mp.ylabel('y') mp.scatter(X, y, s=60, marker='o', c='dodgerblue', label='Points') mp.plot(px, pred_py, c='orangered', label='PolyFit Line') mp.tight_layout() mp.legend() mp.show()
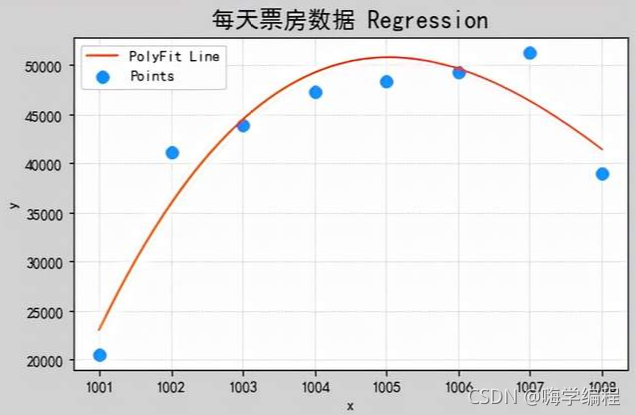
再根據擬合的結果,我們來預測下明天的票房情況,
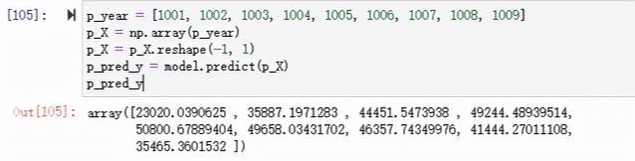
好啦,坐等明天開獎!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/317466.html
標籤:Python
上一篇:Stream流常用用法