作為一個素材收集狂,遇到一個好的圖片站,那是必須要盤它的,這次就碰到一個 PNG images 號稱有 100000+ 免費的 PNG 圖片,
免摳圖片站點分析
目標站點:http://pngimg.com/
目標資料:全站 PNG 圖片,一鍵下載,
該網站具備非常多的分類頁,在采集程序中,優先采集該分類頁資料,
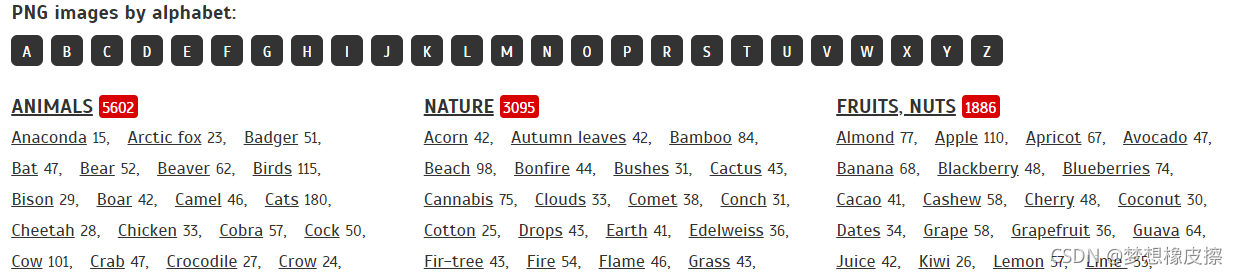
分類頁地址通過開發者工具查看,得到如下內容
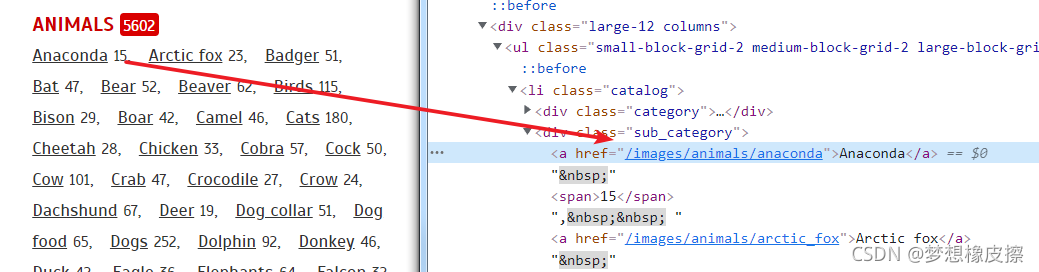
該地址需要與域名資訊進行拼接,得到詳情頁地址,例如 anaconda 地址如下:
http://pngimg.com/images/animals/anaconda
打開詳情頁,檢查圖片所在區域,目的獲取圖片地址,測驗程序中發現圖片串列頁并未分頁,即一頁即可獲取全部資料,
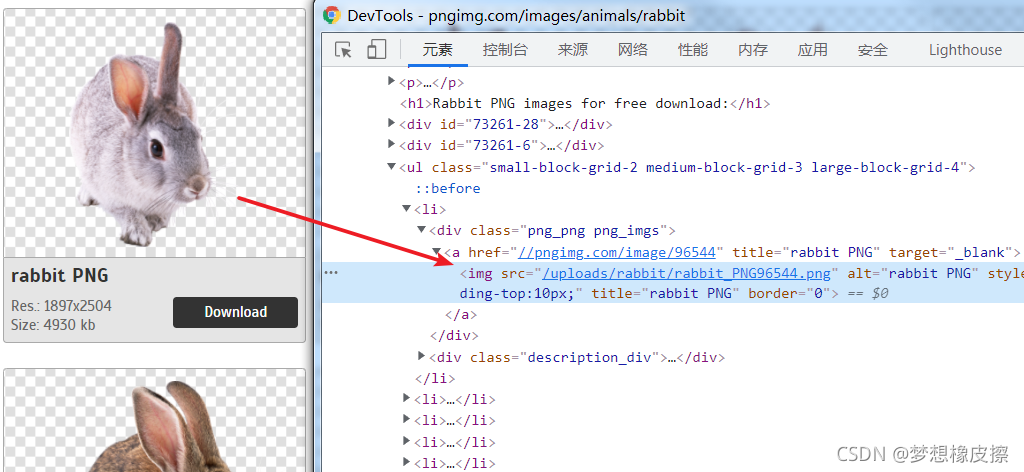
基于上述內容,整理邏輯如下:
- 獲取所有圖片分類標簽;
- 基于分類進入圖片串列頁;
- 提取圖片串列頁圖片地址;
- 下載圖片
編碼時間
由于本案例涉及檔案的讀寫操作,所以采用多執行緒實作,代碼分為 3 個部分,采集分類,采集圖片地址,下載圖片,
采集分類代碼如下
import random
import logging
import threading
from typing import Optional, Text
import requests
from bs4 import BeautifulSoup
import lxml
logging.basicConfig(level=logging.NOTSET)
thread_lock = threading.Lock()
def get_headers():
uas = [
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)",
]
ua = random.choice(uas)
headers = {
"user-agent": ua
}
return headers
# 通用的 requests get 請求方法
def get_html(url: Text, headers: dict, timeout: int) -> Optional[Text]:
try:
res = requests.get(url=url, headers=headers, timeout=timeout)
except Exception as e:
logging.error(e)
if res is not None:
return res.text
else:
return None
if __name__ == '__main__':
url = "http://pngimg.com/"
headers = get_headers()
# 獲取首頁的 HTML 資料
html_str = get_html(url, headers, 5)
# 決議首頁的HTML資料,獲取所有串列頁鏈接
soup = BeautifulSoup(html_str, 'lxml')
div_parents = soup.find_all(attrs={'class': 'sub_category'})
# 獲取到所有的詳情頁地址
all_links = []
for div in div_parents:
all_links.extend(div.find_all('a'))
print("累計獲取到", len(all_links), "個串列頁資料")
上述代碼中將 get_headers() 函式單獨提煉,后續將函式直接作為引數,傳遞到對應類的構造方法中即可,
提取到所有的分類標簽存盤到 all_links 變數中,后續由于多執行緒需要共享全域變數,顧提前匯入執行緒鎖:
thread_lock = threading.Lock()
PNG 采集與下載類
class PngImg(threading.Thread):
# 建構式
def __init__(self, thread_name, headers_func, requests_func) -> None:
threading.Thread.__init__(self)
self._headers = headers_func()
self._timeout = 5
self.requests_func = requests_func
self._thread_name = thread_name
def run(self) -> None:
bast_host = "http://pngimg.com"
while True:
thread_lock.acquire() # 全域鎖,獲取地址
global all_links
if all_links is None:
break
list_url = bast_host + all_links.pop().get('href')
thread_lock.release()
print(self._thread_name + " 正在運行,采集的地址是 " + list_url)
list_html_str = self.requests_func(url=list_url, headers=self._headers, timeout=self._timeout)
ret_imgs = self._get_imgs(list_html_str)
self._save(ret_imgs)
def _get_imgs(self, html) -> list:
"""獲取所有的圖片地址
:return: 圖片 list
"""
soup = BeautifulSoup(html, 'lxml')
# 獲取圖片所在 div 標簽
div_imgs = soup.find_all(attrs={'class': 'png_imgs'})
# 圖片地址為空,用來保存圖片 tag
imgs_src = []
for div_img in div_imgs:
# 遍歷 div 標簽,檢索后代標簽中的 img 圖片標簽
imgs_src.append(div_img.a.img.get("src"))
return imgs_src
def _save(self, imgs):
"""保存圖片 """
for img in imgs:
img = img.replace('small/', '') # 去除 small 標記,獲取大圖
img_url = "https://pngimg.com{}".format(img) # 拼接完整圖片訪問地址
name = img[img.rfind('/') + 1:]
# print(img_url)
# print(name)
try:
res = requests.get(url=img_url, headers=self._headers, timeout=self._timeout)
except Exception as e:
logging.error(e)
if res is not None:
name = name.replace("/", "_")
with open(f'./imgs/{self._thread_name}_{name}', "wb+") as f:
f.write(res.content)
代碼說明:
上述類為核心采集類,重寫了 run 方法,在其中通過回圈實作對所有串列頁的采集,_get_imgs() 方法用于獲取所有圖片地址,用到的依舊是 BeautifulSoup 物件的 find_all() 方法,標簽檢索使用子集標簽尋找方式 div_img.a.img.get("src"),_save() 方法用于存盤圖片,在這里橡皮擦第一次測驗的時候,發現圖片路徑中帶有 small 關鍵字,如希望獲取大圖,需要對其進行洗掉,后續測驗發現已經移除該標記,
類的構造方法引數說明如下:
def __init__(self, thread_name, headers_func, requests_func) -> None:
thread_name:執行緒名;headers_func:get_headers()函式;requests_func:請求函式;
執行緒的開啟代碼直接寫在 main 代碼塊中即可,本案例使用 5 個執行緒,
threads = ["Thread A", "Thread B", "Thread C", "Thread D", "Thread E"]
for t in threads:
my_thread = PngImg(t, get_headers, get_html)
my_thread.start()
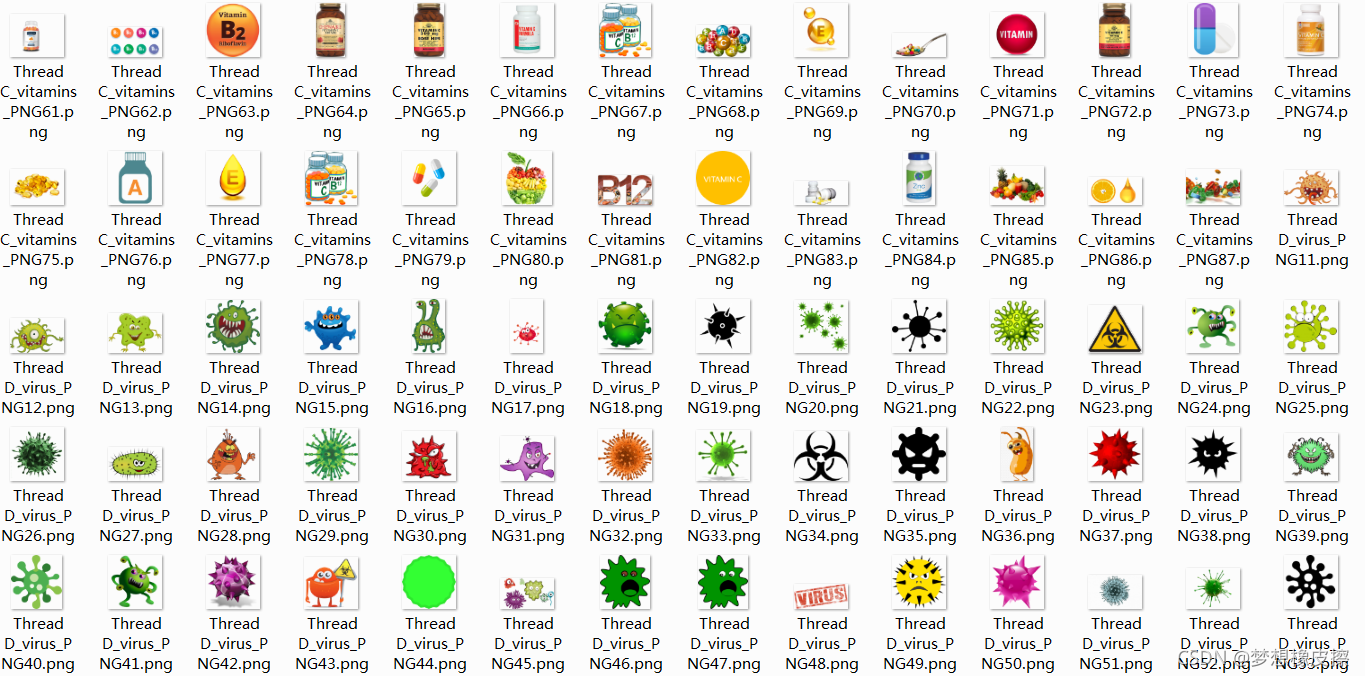
代碼運行程序效果圖如下所示:

獲取圖片也是非常快速的,
寫在后面
BeautifulSoup 模塊的學習暫時告一段落,希望這3篇文章,能讓你對 bs4 模塊有一個初步的認識,
- 在120篇系列專欄中,才能學會 python beautifulsoup4 模塊,7000字博客+爬第九工場網
- 都說python是萬能的,這次用python看溧陽攝影圈,真不錯
今天是持續寫作的第 240 / 365 天,
期待 關注,點贊、評論、收藏,
更多精彩
《爬蟲 100 例,專欄銷售中,買完就能學會系列專欄》

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/317944.html
標籤:python
上一篇:這18張 Python 資料科學速查表,讓你的代碼能力飛起來!
下一篇:異步和等待-難以理解