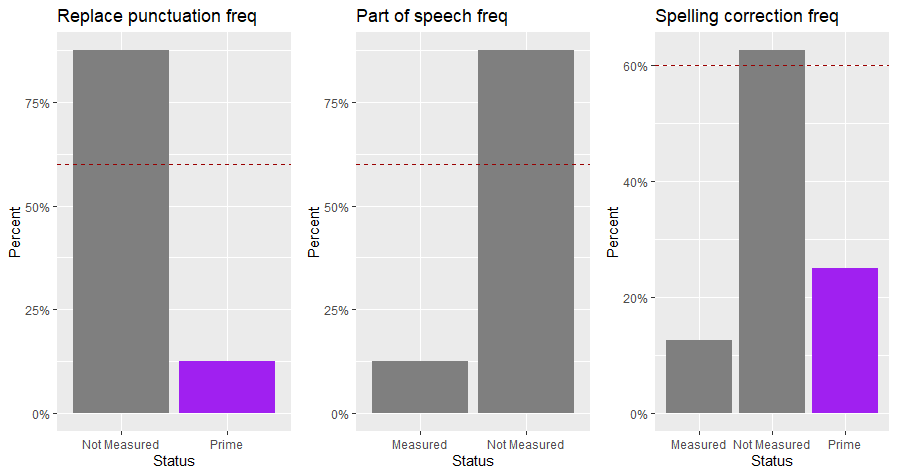
我想在柱狀圖中只突出 "主要 "元素。然而,當某一列中沒有 "Prime "元素時,該條形圖會突出顯示所有條形(它不應該被突出顯示)。
這是我的R代碼,供進一步了解:
這是我的R代碼。
test.df <- data. frame(replace_punct = c("Prime"/span>。 "not Measured"。 "not Measured", "not Measured"。 "not Measured", "not Measured"。 "未測量", "未測量")。 pos = c("Measured"。 "未測量"。 "not Measured", "not Measured"。 "not Measured", "not Measured"。 "Not Measured", "Not Measured")。 spelling_corr = c("Measured"。 "未測量"。 "not Measured", "not Measured"。 "not Measured", "not Measured"。 "Prime", "Prime")。 stringsAsFactors = FALSE)
replace_punct_bar <- ggplot(data=test. df, aes(x = replace_punct。 y = after_stat(count/sum(count))。 填充= ifelse(replace_punct == "Prime"。 "highlighted", "Normal")))) scale_y_continuous(labels =scales: : operator"> labs(title = "Replace punctuation freq"。 y = "百分比", operator"> geom_hline(aes(yintercept=0。 6), color="#990000"/span>。 linetype="dashed") theme(legend. position="none")。
pos_bar <- ggplot(data=test. df, aes(x = pos, y = after_stat(count/sum(count))。 填充= ifelse(pos == "Prime"/span>。 "highlighted", "Normal")))) scale_y_continuous(labels =scales。 : operator"> labs(title = "Part of speech freq", y = "百分比", operator"> geom_hline(aes(yintercept=0。 6), color="#990000"/span>。 linetype="dashed") theme(legend. position="none")。
spelling_corr_bar <- ggplot(data=test. df, aes(x =spelling_corr, y = after_stat(count/sum(count))。 填充= ifelse(spelling_corr == "Prime"。 "highlighted", "Normal")))) scale_y_continuous(labels =scales: : operator"> labs(title = "Spelling correction freq"。 y = "百分比"。 operator"> geom_hline(aes(yintercept=0。 6), color="#990000"/span>。 linetype="dashed") theme(legend. position="none")。
grid. arrange(replace_punct_bar, pos_bar, spelling_corr_bar, ncol=3)
提前感謝您的時間和幫助!
uj5u.com熱心網友回復:
你可以添加一個刻度,比如:
scale_fill_manual(values = c("Highlighted" = "purple"。 "不正常" = "灰色"))
在每個情節中,結果將是:
uj5u.com熱心網友回復:
我從@vinícius-félix的回答中得到了這個想法。下面是我想讓條形圖可視化的最新代碼。
test.df <- data. frame(replace_punct = c("Prime"/span>。 "not Measured"。 "not Measured", "not Measured"。 "not Measured", "not Measured"。 "未測量", "未測量")。 pos = c("Measured"。 "未測量"。 "not Measured", "not Measured"。 "not Measured", "not Measured"。 "Not Measured", "Not Measured")。 spelling_corr = c("Measured"。 "未測量"。 "not Measured", "not Measured"。 "not Measured", "not Measured"。 "Prime", "Prime")。 stringsAsFactors = FALSE)
replace_punct_bar <- ggplot(data=test. df, aes(x = replace_punct。 y = after_stat(count/sum(count))。 填充= ifelse(replace_punct == "Prime"。 "highlighted", "Normal")))) scale_y_continuous(labels =scales: : operator"> labs(title = "Replace punctuation freq"。 y = "百分比", operator"> geom_hline(aes(yintercept=0。 6), color="#990000"/span>。 linetype="dashed") theme(legend. position="none") scale_fill_manual(values =) 運算子">= c("Highlighted" = "#f8766d"。 "Normal" = "#00bfc4"))
pos_bar <- ggplot(data=test. df, aes(x = pos, y = after_stat(count/sum(count))。 填充= ifelse(pos == "Prime"。 "highlighted", "Normal")))) scale_y_continuous(labels =scales。 : operator"> labs(title = "Part of speech freq", y = "百分比", operator"> geom_hline(aes(yintercept=0。 6), color="#990000"/span>。 linetype="dashed") theme(legend. position="none") scale_fill_manual(values =) 運算子">= c("Highlighted" = "#f8766d"。 "Normal" = "#00bfc4"))
spelling_corr_bar <- ggplot(data=test. df, aes(x = spelling_corr。 y = after_stat(count/sum(count))。 填充= ifelse(spelling_corr == "Prime"。 "highlighted", "Normal")))) scale_y_continuous(labels =scales: : operator"> labs(title = "Spelling correction freq"。 y = "百分比"。 operator"> geom_hline(aes(yintercept=0。 6), color="#990000"/span>。 linetype="dashed") theme(legend. position="none") scale_fill_manual(values =) 運算子">= c("Highlighted" = "#f8766d"。 "Normal" = "#00bfc4"))
網格。 arrange(replace_punct_bar, pos_bar, spelling_corr_bar, ncol=3)
我希望這段代碼能幫助那些面臨像我這樣問題的人。謝謝!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/318896.html
標籤: