我是Python小白,我會用比較通俗易懂的方法告訴你如何去爬取資料,
一開始,我們需要pycharm(也就是我們編代碼的工具),其次我們需要打開我們需要爬取資料的網頁,我以鞋子為例,
那么,接下來就開始吧
首先,我們打開某東,搜索鞋子,
隨便點進去一個,找到他的評價
右擊空白處,點檢查,
出現以下界面時,我們點Network,
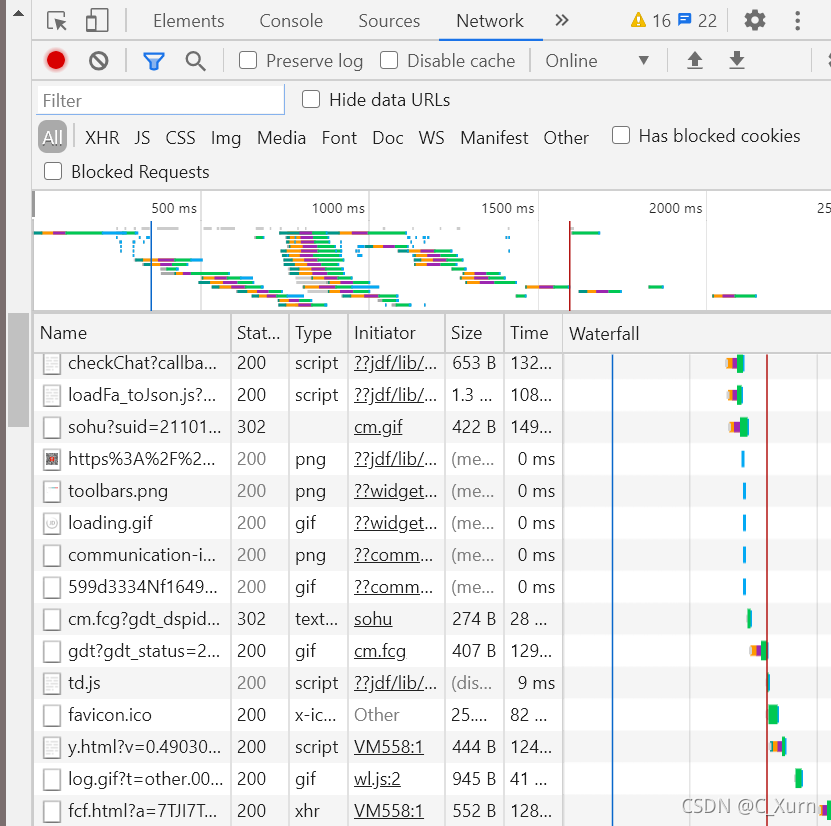
然后重繪我們找到的京東鞋子界面,就可以看到他出來很多東西,如下圖所示
這時候,我們打開評論,隨便找到一個評論,復制一下,然后找到有一個放大鏡一樣的東西那,點開,然后粘貼我們剛才復制的評論,
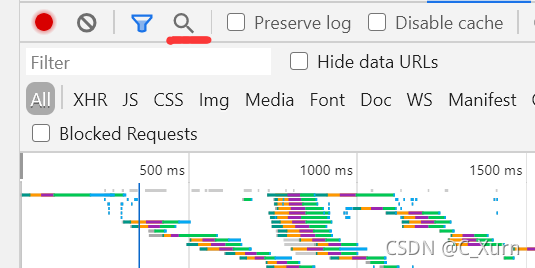
就可以看到這些東西
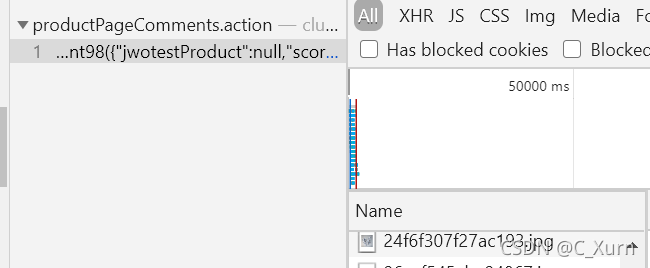
我們點開,發現右邊Name里面有這些東西,我們直接復制這個URL,
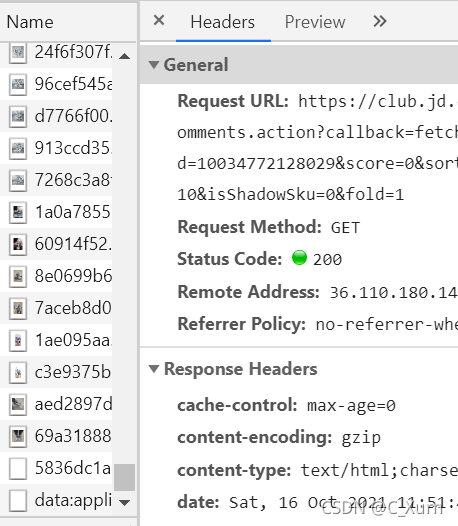
好了,我們找到了關鍵的東西,那么接下來我們來撰寫代碼
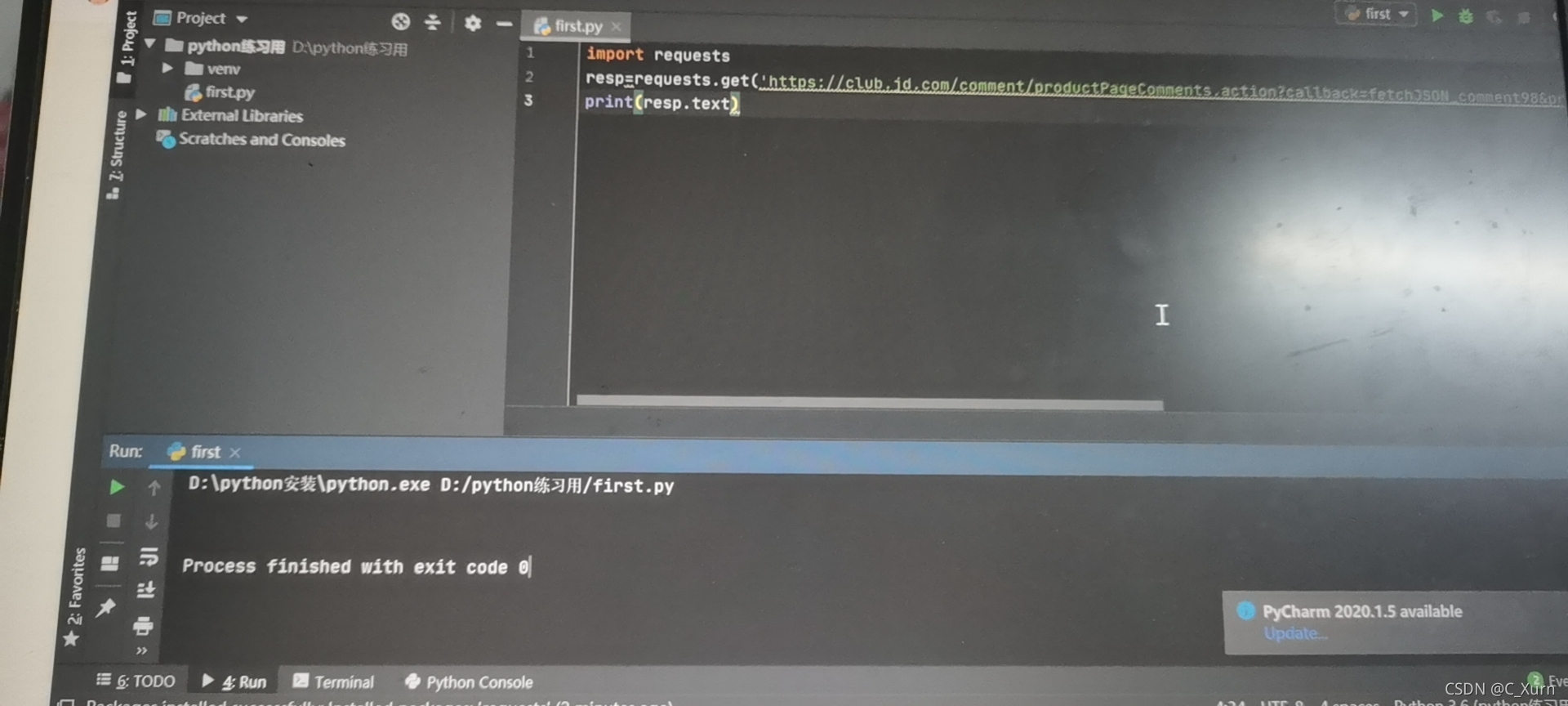
首先,第一行 是import requests
第二行就是resp=requests.get(‘URL’)[此處URL就是你自己找的]
第三行就是print(resp.text),
其實擁有這三行代碼就可以了,但是呢,我們是在pycharm中爬取的資料,京東只有在瀏覽器訪問時才會允許我們,我們用pycharm訪問時,不會給我們,
如下如所示
為了解決這個問題呢,我們可以讓我們的python程式偽裝成瀏覽器,我們需要添加一個東西,請求頭,
首先,我們隨便打開一個瀏覽器,右擊空白部位,點擊檢查,
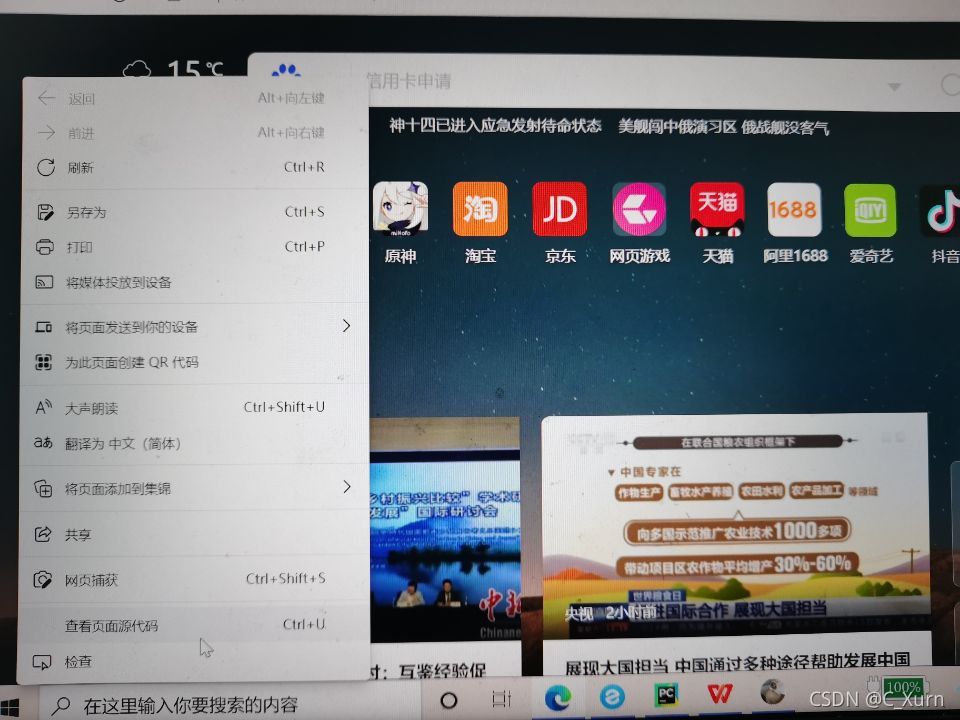
點進去后我們點擊網路,然后重繪一下這個網頁,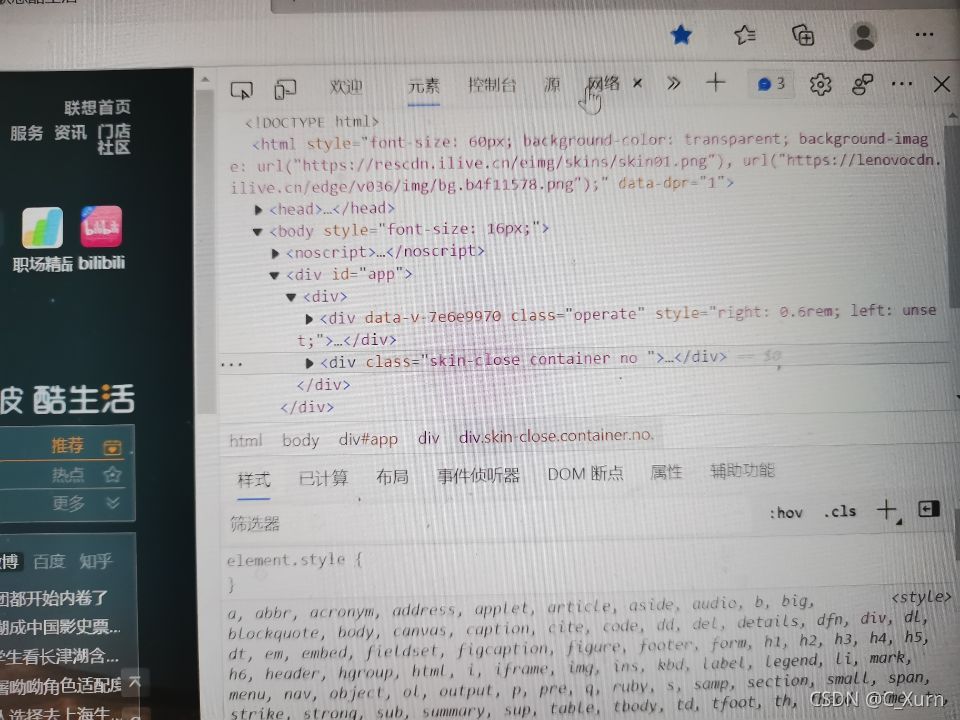
我們隨便點開一項,看標頭里面有一個User-Agent,我們直接復制,
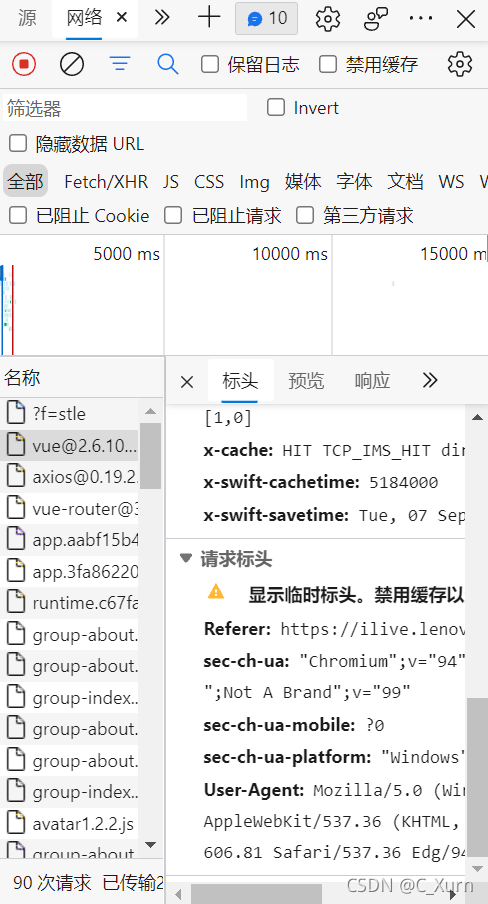
然后我們再來補充一行代碼
headers={‘User-Agent’:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50’}//此處這個是我找的,你們找的是什么就粘貼什么,
get函式里面最后加一個headers=headers,
-------------------------------------------------------------------------------------------
下面是代碼模板
import requests
headers={'user-agent': '你自己找的user-agent'}
resp=requests.get('你自己想要爬取資料的網頁URL',headers=headers)
print(resp.text)
----------------------------------------------------------------------------------------
下面是我找的一個(可以直接復制粘貼)
import requests
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/30'}
resp=requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=10335871588&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1',headers=headers)
print(resp.text)
結果就是這個,我隨便截了一小部分,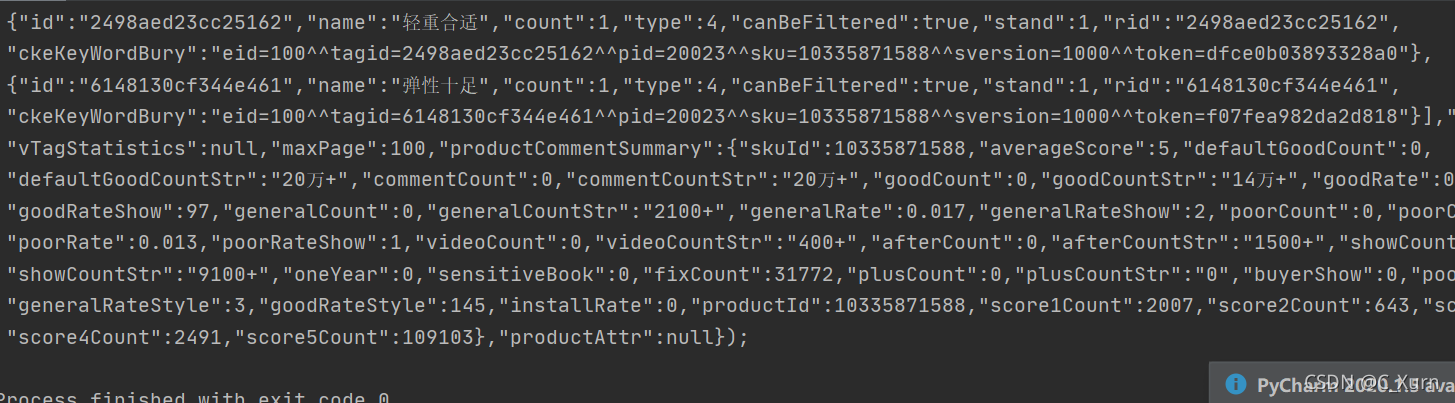
總結起來,只有三點,第一點,寫好代碼模型,第二點,找到URL,第三點,找到User-agent,
最后,給初學者一個用python創建.txt檔案的代碼
fp=open('D:/yyds.txt','a+')
print('helloworld',file=fp)
fp.close()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/319729.html
標籤:python