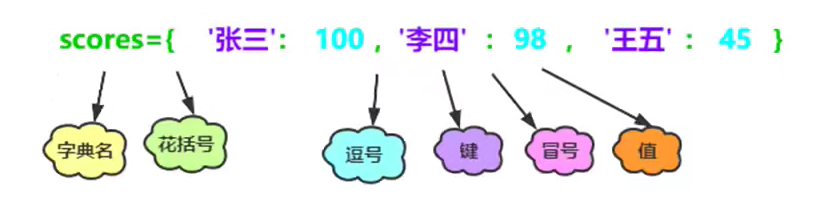
1.什么是字典
- Python內置的資料結構之一,與串列一樣是一個可變序列
- 以鍵值對的方式存盤資料,字典是一個無序的序列
- 在存盤資料時要經過hash(key)的計算,計算的結果就是存盤的位置,因此字典的鍵值對順序并不是按照存盤時的先后順序決定的,而是經過計算得到的存盤位置,
- 字典中的鍵必須時不可變序列,否則當鍵改變時,hash計算的結果就會發生變化,導致存盤位置發生變化,因此鍵必須要使用不可變序列
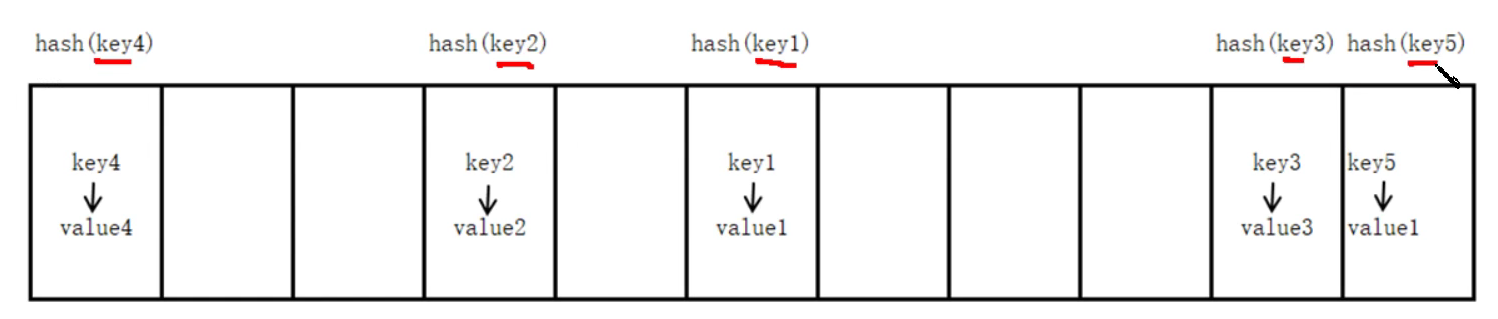
- 字典的實作原理
- 與查新華字典類似,差字典是先根據部首或者拼音查找相應的頁碼,Python中的字典是根據 key去查找value的所在位置
2.字典的創建方式
#字典創建的兩種方式 #第一種,使用花括號 dict_1 = {'num':'20210101','name':'Liming','sex':'male'} print(dict_1) #第二種,使用內置函式dict() # 2.1 通過其他字典創建 dict_2 = dict(dict_1) print(dict_2) print(dict_2 is dict_2) # True # 2.2 通過關鍵字引數創建 dict_3 = dict(num = "20210101",name = "Liming",sex = 'male') print(dict_3) print(dict_1 == dict_3) #True print(dict_1 is dict_3) #False # 2.3 通過鍵值對的序列創建 dict_4 = dict([('num',"20210101"),('name',"Liming"),('sex',"male")]) print(dict_3) #2.4 通過dict和zip結合創建 dict_5 = dict(zip(['num','name','sex'],['20210101','Liming','male'])) print(dict_5) if dict_1 == dict_2 == dict_3 == dict_4 == dict_5: #判斷字典的值是否相同 print("創建字典的5種方式相同") else: print("創建字典的5種方式不同")
- 字典種的鍵是唯一的,創建字典時若出現“鍵”相同的情況,則后定義的“鍵-值”對將覆寫先定義的“鍵-值”對,
x = {'a':1,'b':2,"b":3}
print(x)
#運行結果
{'a': 1, 'b': 3}
- fromkeys()方法創建字典:當所有的鍵對應同一個值的時候,可以使用fromkeys創建字典
- dict.fromkeys(seq[,value]):
- seq:為字典“鍵”的值串列
- value:為設定鍵序列(seq)的值,省略時默認為None
dict_1 = dict.fromkeys(['zhangsan','wangwu']) print(dict_1) dict_2 = dict.fromkeys(['zhang_san','wang_wu'],18) print(dict_2) dict_3 = dict.fromkeys(['zhang_san','wang_wu'],b) print(dict_3) #從下面四行代碼可以看出,當他們值為可變序列并且參考地址相同時,類似于淺copy dict_3['wang_wu'].pop() print(dict_3) dict_3['wang_wu'].append(10) print(dict_3) #運行結果 {'zhangsan': None, 'wangwu': None} {'zhang_san': 18, 'wang_wu': 18} {'zhang_san': [18], 'wang_wu': [18]} {'zhang_san': [], 'wang_wu': []} {'zhang_san': [10], 'wang_wu': [10]}
3.字典的訪問
a.根據鍵訪問值
- 字典中每個元素表示一種映射關系,將提供的“鍵‘作為下標可以訪問對應的值
- 如果字典中不存在這個”鍵“,則會拋出例外
#根據鍵訪問值 dict_1 = {"name":"張飛","age":18,"sex":"male"} print(dict_1["name"]) print(dict_1["sex"]) #print(dict_1["x"]) 指定的鍵不存在,拋出例外
b.使用get()方法訪問值
- 在訪問字典時,若不確定字典中是否由某個鍵,可通過get()方法進行獲取,
- 若該鍵存在,則回傳對應的值
- 若該鍵不存在,則回傳默認值
- 語法格式
- dict.get([key[,default = None])
- key:要查找的鍵
- default:默認值,默認為None,可自行設定需要輸出的默認值,如果指定的鍵不存在,則回傳默認值,當default為空時,回傳None
#使用get()方法訪問值 dict_1 = {"name":"張飛","age":18,"sex":"male"} print(dict_1.get("name")) print(dict_1.get("x")) #回傳None print(dict_1.get("x",18)) #當鍵不存在時,輸出設定的默認值,并不會把鍵x存入dect_1 print(dict_1.get("age",19)) #當鍵存在時,輸出age原本的值
4.in 和 not in 在字典中的使用
- 判斷鍵是否在字典中
#in和not in在字典中的使用:判斷鍵是否在字典中 dict_1 = {"name":"張飛","age":18,"sex":"male"} print("name" in dict_1) #True print("張飛" in dict_1) #False print("張飛" not in dict_1) #True
5.修改和添加字典中的元素
- 當以指定鍵為下標為字典元素賦值時,有兩種含義:
- 若該鍵存在字典中,則表示修改該鍵對應的值
- 若該鍵不存在字典中,則表示添加一個新的鍵值對,也就是添加一個新元素到字典中
dict_1 = {"name":"張飛","age":18}
print(dict_1)
dict_1["name"] = "李四" #name鍵存在字典dict_1中,所以此處為修改name的值
print(dict_1)
dict_1["sex"] = "male" #sex鍵不存在字典dict_1中,所以此處為添加新的鍵值對
print(dict_1)
#輸出結果
{'name': '張飛', 'age': 18}
{'name': '李四', 'age': 18}
{'name': '李四', 'age': 18, 'sex': 'male'}
6.洗掉字典中的元素 del命令 clear()方法 pop()方法 popitem()方法
- del命令:根據”鍵“洗掉字典中的元素
dict_1 = {"name":"張飛","age":18,"sex":"male"}
del dict_1["name"]
print(dict_1)
#運行結果
{'age': 18, 'sex': 'male'}
- clear()方法:用于清除字典中所有元素,其語法格式如下:
dict_1 = {"name":"張飛","age":18,"sex":"male"}
dict_1.clear()
print(dict_1)
#運行結果
{}
- pop()方法:用于獲取指定”鍵“的值,并將這個鍵值對從字典中移除,并回傳該鍵的值,
- dict.pop(key[,default])
- key:要被洗掉的鍵
- default:默認值,當字典中沒有要被洗掉的key時,該方法回傳指定的默認值
dict_1 = {"name":"張飛","age":18,"sex":"male"}
print(dict_1.pop("age")) #洗掉鍵age與其值,pop()方法的回傳值為,洗掉的該鍵的值
print(dict_1)
print(dict_1.pop('age',17))
print(dict_1)
print(dict_1.pop('name',"里斯"))
print(dict_1)
- popitem()方法:用于隨機獲取一個鍵值對,將其洗掉,并以元組的方式回傳被洗掉的鍵值對
- dict.popitem():該方法無引數
dict_1 = {"name":"張飛","age":18,"sex":"male"}
x = dict_1.popitem()
print(x,type(x))
print(dict_1)
#運行結果
('sex', 'male') <class 'tuple'>
{'name': '張飛', 'age': 18}
7.更新字典
- 使用update()方法:可以將新字典的鍵值對,一次性全部添加到當前字典中
- 如果兩個字典存在相同的鍵,則以新字典中的值為準,更新當前字典
- dict.updata(dict2)
- dict:當前字典
- dict2:新字典
dict_1 = {"name":"張飛","age":18}
dict_2 = {"name":"李四","sex":"male"}
dict_1.update(dict_2)
print(dict_1)
print(dict_2)
#運行結果
{'name': '李四', 'age': 18, 'sex': 'male'}
{'name': '李四', 'sex': 'male'}
8.獲取字典視圖的三個方法
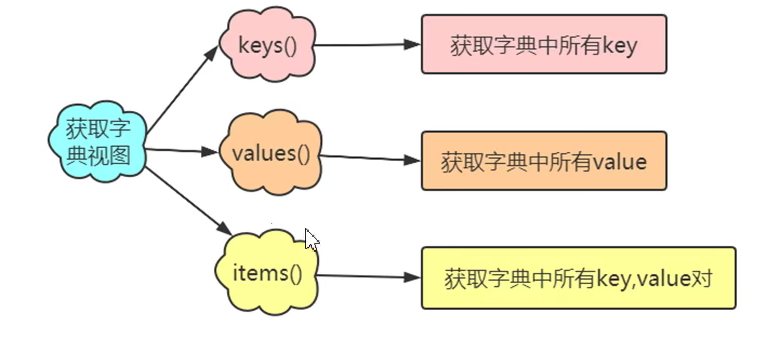
- key()方法
#keys()方法:獲取字典中所有的key dict_1 = {"name":"張飛","age":18,"sex":"male"} key_1 = dict_1.keys() print(key_1,type(key_1)) #可以看出獲取到了字典所有的鍵,并存放在了一個貌似串列的dict_keys視圖中 key_2 = list(key_1) #將物件key_1視圖變成串列,并不改變原來的key_1視圖 print(key_1) print(key_2) #運行結果 dict_keys(['name', 'age', 'sex']) <class 'dict_keys'> dict_keys(['name', 'age', 'sex']) ['name', 'age', 'sex']
- values()方法
#values()方法:獲取字典中所有的value dict_1 = {"name":"張飛","age":18,"sex":"male"} value_1 = dict_1.values() print(value_1,type(value_1)) #可以看出獲取到了字典所有的值,并存放在了一個貌似串列的dict_values視圖中 value_2 = list(value_1) print(value_1) print(value_2) #運行結果 dict_values(['張飛', 18, 'male']) <class 'dict_values'> dict_values(['張飛', 18, 'male']) ['張飛', 18, 'male']
- items()方法
#items()方法:獲取字典中所有的鍵值對 dict_1 = {"name":"張飛","age":18,"sex":"male"} items_1 = dict_1.items() #可以看出獲取到了字典所有的鍵值對,并將鍵值對存放在了元組中,再把元組存放在串列中,視圖型別為:dict_items print(items_1,type(items_1)) items_2 = list(items_1) #將視圖轉換成串列 print(items_2) items_3 = tuple(items_2) #將串列轉換成元組 print(items_2) print(items_3) #運行結果 dict_items([('name', '張飛'), ('age', 18), ('sex', 'male')]) <class 'dict_items'> [('name', '張飛'), ('age', 18), ('sex', 'male')] [('name', '張飛'), ('age', 18), ('sex', 'male')] (('name', '張飛'), ('age', 18), ('sex', 'male'))
9.遍歷字典
-
使用for回圈遍歷,串列、元組和集合的組合時
·當變數x為一個時,x會直接獲取串列(元組)的值
·當變數x,y···的個數剛好與串列(元組)的個數相同時,則直接將值依次賦給變數
注意:只有在使用串列和元組和集合的兩兩組合時才能這樣使用,
""" 使用for回圈遍歷,串列和元組的組合時, ·當變數x為一個時,x會直接獲取串列(元組)的值 ·當變數x,y···的個數剛好與串列(元組)的個數相同時,則直接將值依次賦給變數 """ a = [('Mary', 'C',"d"),('Jone', 'java',"d"),('Lily', 'Python',"d"),('Lily', 'Python',"d")] for x in a: print(x) #串列里面存盤的元組,只有一個變數x,所以將元組直接賦值給x print("============================================") for x,y,z in a: #串列里面存盤的元組,每個元組里面存盤了3個元素,剛好可以用三個變數xyz接收這三個元素 print(x,y,z) print("============================================") a = (['Mary', 'C',"d"],['Jone', 'java',"d"],['Lily', 'Python',"d"],['Lily', 'Python',"d"]) for x in a: #元組里面存盤的串列,只有一個變數x,所以將元組直接賦值給x print(x) print("============================================") for x,y,z in a: #元組里面存盤的串列,每個串列里面存盤了3個元素,剛好可以用三個變數xyz接收這三個元素 print(x,y,z) #運行結果 ('Mary', 'C', 'd') ('Jone', 'java', 'd') ('Lily', 'Python', 'd') ('Lily', 'Python', 'd') ============================================ Mary C d Jone java d Lily Python d Lily Python d ============================================ ['Mary', 'C', 'd'] ['Jone', 'java', 'd'] ['Lily', 'Python', 'd'] ['Lily', 'Python', 'd'] ============================================ Mary C d Jone java d Lily Python d Lily Python d
a = {('Mary', 'C',"A"),('Jone', 'java',"B"),('Lily', 'Python',"C"),('Lily', 'Python',"D")}
for x in a: #集合里面存盤的元組,只有一個變數x,所以將元組直接賦值給x
print(x)
for x,y,z in a: #集合里面存盤的元組,每個元組里面存盤了3個元素,剛好可以用三個變數xyz接收這三個元素
print(x,y,z)
#運行結果
('Mary', 'C', 'A')
('Lily', 'Python', 'D')
('Jone', 'java', 'B')
('Lily', 'Python', 'C')
Mary C A
Lily Python D
Jone java B
Lily Python C
-
遍歷字典中所有的鍵值對
- 使用items()方法,該方法以串列的形式回傳可遍歷的鍵值對元組
stu_class = { 'Mary': 'C', 'Jone': 'java', 'Lily': 'Python', 'Lilo': 'Python' } for name,cla in stu_class.items(): print(name,"選修的課程為:",cla) #運行結果 Mary 選修的課程為: C Jone 選修的課程為: java Lily 選修的課程為: Python Lilo 選修的課程為: Python
-
遍歷字典中所有的鍵
- 當不需要字典中的值時,可使用keys()方法,只遍歷字典中的鍵,該方法以串列回傳一個字典中所有的鍵
stu_class = { 'Mary': 'C', 'Jone': 'java', 'Lily': 'Python', 'Lilo': 'Python' } for name in stu_class.keys(): print(name) #運行結果 Mary Jone Lily Lilo
-
遍歷字典中所有的值
- 當只關心字典所包含的值時,可以使用values()方法,該方法以串列形式回傳字典中所有的值
stu_class = { 'Mary': 'C', 'Jone': 'java', 'Lily': 'Python', 'Lilo': 'Python' } for cla in stu_class.values(): print(cla) #運行結果 C java Python Python
10.字典的特點
- 字典中所有的元素都是一個鍵值對(key - value),key不允許重復,但是value可以重復
- 字典中的元素是無序的
- 字典中的key是不可變物件(不可變序列)
- 字典頁可以根據需要動態伸縮
- 字典會浪費較大的記憶體,是一種使用空間換時間的資料
11.復制字典
- 直接賦值:物件的參考
- 淺復制(copy()方法):拷貝父物件,參考物件內部的子物件
- 深復制(deepcopy()方法):copy模塊的deepcopy()方法,完全復制父物件及其子物件
dict1 = {'user':'runoob','num':[123]}
dict2 = dict1 #參考物件
dict3 = dict1.copy() #淺復制,深復制父物件,子物件不復制,還是參考
import copy
dict4 = copy.deepcopy(dict1) #深復制,完全復制父物件和子物件
print(1,dict1,id(dict1)) #1 {'user': 'runoob', 'num': [123]} 1630766832896
dict1['user'] = 'root'
print(1,dict1,id(dict1)) #1 {'user': 'root', 'num': [123, 23]} 1630766832896
print(2,dict2,id(dict2)) #2 {'user': 'root', 'num': [123, 23]} 1630766832896
print(3,dict3,id(dict3)) #3 {'user': 'runoob', 'num': [123, 23]} 1630766833088
print(4,dict4,id(dict4)) #4 {'user': 'runoob', 'num': [123]} 1630767214080
Python集合(set)
1.什么是集合
- python語言提供的內置資料結構
- 與串列和字典一樣,都屬于可變序列
- 集合是沒有value的字典
- 集合型別與其他型別最大的區別在于,它不包含重復元素
2.集合創建
#集合創建方式一:使用{} set_1 = {"Python","Hello",90} print(set_1) set_2 = {1,1,2,3,4,4,"Python","Python"} #集合中的元素不允許重復 print(set_2) set_3 = {1,2.2,(1,2,3,4),"Python"} print(set_3) #set_4 = {1,2.2,[1,2,3,4]} # 代碼報錯:集合中的元素不允許為 可變資料型別(可變序列) #集合創建方式二:使用內置函式 set():將字符出、串列、元組、range()等物件轉化成集合 set_4 = set("python") print(set_4) set_5 = set([1,2,3,4,5]) print(set_5) set_6 = set((1,2,"Hello")) print(set_6) set_7 = set(range(5)) print(set_7) set_8 = set() #創建空集合 print(set_8) set_9 = {} print(type(set_9)) # <class 'dict'> :所以創建空集合的時候,不能直接使用{}
3.集合的判斷操作
- in 或者 not in : 判斷元素是否在集合中
set_1 = {10,20,30,40,50}
print(10 in set_1) #True
print(100 in set_1) #False
print(20 not in set_1) #False
print(100 not in set_1) #True
4.集合添加元素 add()方法 update()方法
set_1.add(x)方法:如果資料項x不在結合set_1中,將x添加到set_1中 (一次添加一個元素,元素不重復的前提下)
set_1.update(T)方法:合并結合T中的元素到當前集合set_1中,并自動去除重復元素 (至少添加一個元素,元素不重復的前提下)
#集合添加元素 set_1 = {1,2.2,"Python"} set_2 = {(1,2,True,"Hello"),2.2,"Python","China"} set_1.add((1,2,True,"Hello")) print(set_1) set_1.update(set_2) print(set_1) set_1.update([10,20,30]) #可以添加集合中的元素 print(set_1) set_1.update((40,50,60)) #可以添加元組中過的元素 print(set_1) #運行結果 {1, 2.2, (1, 2, True, 'Hello'), 'Python'} {1, 2.2, 'China', (1, 2, True, 'Hello'), 'Python'} {1, 2.2, 'China', 10, (1, 2, True, 'Hello'), 20, 'Python', 30} {1, 2.2, 'China', 40, 10, (1, 2, True, 'Hello'), 50, 20, 'Python', 60, 30}
5.集合洗掉元素 remove()方法 discard()方法 pop()方法 clear()方法
S.remove(x)方法:如果x在集合S中,移除該元素;如果x不存在則拋出例外
S.discard(x)方法:如果x在集合S中,移除該元素;如果x不存在不會報錯
set_1 = {1,(1,2,True,"Hello"),2.2,"Python"}
set_1.remove(1)
print(set_1)
# set_1.remove(1) #集合中無元素1,執行此代碼會拋出例外
set_1.discard(2.2)
print(set_1)
set_1.discard(2.2) #集合中無元素2.2,不過執行此代碼不會拋出例外
print(set_1)
#運行結果
{(1, 2, True, 'Hello'), 2.2, 'Python'}
{(1, 2, True, 'Hello'), 'Python'}
{(1, 2, True, 'Hello'), 'Python'}
S.pop()方法:隨機洗掉并回傳集合中過的一個元素,如果集合為空則拋出例外
S.clear()方法:清空集合
set_1 = {1,(1,2,True,"Hello"),2.2,"Python"}
print(set_1.pop())
print(set_1)
set_1.clear()
print(set_1)
#set_1.pop() #集合為空,執行此行代碼,會拋出例外
#運行結果
1
{2.2, 'Python', (1, 2, True, 'Hello')}
set()
6.集合間的關系
- 兩個集合是否相等 == 、 != 、 is 、not is
set_1 = {10,20,30,40}
set_2 = {40,30,10,20}
print(set_1 == set_2) #True 比較集合的值是否相等
print(set_1 is set_2) #False 比較集合的參考地址是否相等
- 一個集合是否是另一個集合的子集
- 可以呼叫方法 issubset() 判斷
- B是A的子集
A = {1,2,3,4,5,6}
B = {1,2,3,4}
print(B.issubset(A)) #True B是A的子集
- 一個集合是否是另一個集合的超集
- 可以呼叫方法 issuperset() 判斷
- A是B的子集
A = {1,2,3,4,5,6}
B = {1,2,3,4}
print(A.issuperset(B)) #True A是B的超集
- 兩個集合是否沒有交集
- 可以呼叫方法 isdisjoint() 判斷
A = {1,2,3,4,5,6}
B = {1,2,3,4}
print(A.isdisjoint(B)) #False 判斷A和B是否沒有交集
B = {7,8,9,10}
print(A.isdisjoint(B)) #True 判斷A和B是否沒有交集
7.集合的資料關系
pass
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/320866.html
標籤:其他