一、前情提要
相信來看這篇深造爬蟲文章的同學,大部分已經對爬蟲有不錯的了解了,也在之前已經寫過不少爬蟲了,但我猜爬取的資料量都較小,因此沒有過多的關注爬蟲的爬取效率,這里我想問問當我們要爬取的資料量為幾十萬甚至上百萬時,我們會不會需要要等幾天才能將資料全都爬取完畢呢?
唯一的辦法就是讓爬蟲可以 7×24 小時不間斷作業,因此我們能做的就是多叫幾個爬蟲一起來爬資料,這樣便可大大提升爬蟲的效率,
但在介紹Python 如何讓多個爬蟲一起爬取資料之前,我想先為大家介紹一個概念——并發,
文章目錄
- 一、前情提要
- 二、并發的概念
- 三、并發與多執行緒
- 四、執行緒池
二、并發的概念
為了讓大家簡單易懂,我就用例子代替復雜的文章來向大家介紹吧
第一個例子
我們用 requests 成功請求一個網頁,實際上 requests 做了三件事:
1、根據鏈接、引數等組合成一個請求;
2、把這個請求發往要爬取的網站,等待網站回應;
3、網站回應后,把結果包裝成一個回應物件方便我們使用,

其中步驟 2 花費的時間是最長的,取決于被爬網站的性能,這個時間可能達到幾十到幾百毫秒,
對這個程式來說:綠色部分代表代碼是在 運行 的,黃色部分(步驟 2)代表程式是 空閑 的,因為在等待網站回應, 所以,爬蟲代碼真正運行的時間很短,大部分時間都浪費在等待網站回應上了,
第二個例子
我們連續用 requests 請求三個網頁 A、B、C,執行的程序如下圖所示:
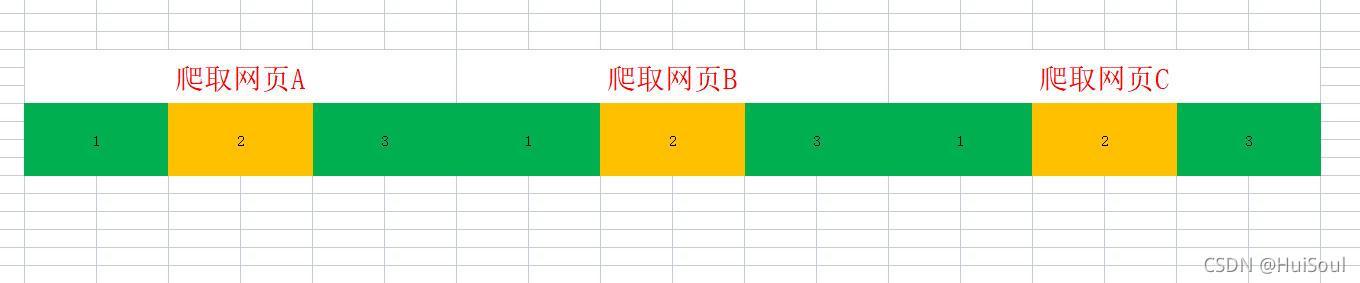
同樣的,每次步驟 1、3 和 2 所花費時間的差異很大,我們假設步驟 1 和步驟 3 都要花費 1 毫秒,步驟 2 要花費 98 毫秒,那么一個網頁要花費 100 毫秒,爬取 A、B、C 三個網頁一共花費了 300 毫秒,
這時我們其實遇到一個問題:整個程序的 300 毫秒里,代碼運行的時間只有 6 毫秒,剩下有 294 毫秒我們的程式只是空閑在那里等待著網站回應,
第三個例子
想一想,第一個例子里,順序必須是 1-2-3,因為步驟 2 依賴步驟 1 的結果,步驟 3 依賴步驟 2 的結果,但是第二個例子里,步驟為什么必須是 A1-A2-A3-B1-B2-B3-C1-C2-C3 呢?「爬取網頁 B」的步驟 1 其實和「爬取網頁 A」的步驟 3 并沒有依賴關系,
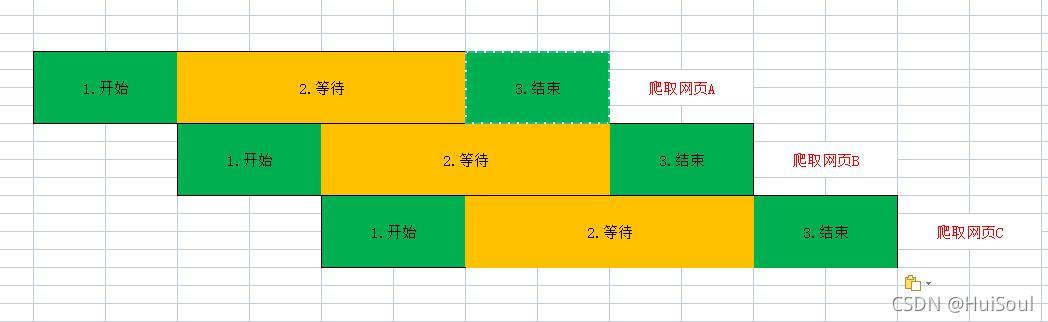
這張圖是什么意思呢?其實就是:在「爬取網頁 A」這個程序進行到步驟 2 的時候,程式空閑下來了,這時我們讓「爬取網頁 B」的步驟 1 開始執行;同樣的,「爬取網頁 B」的步驟 1 執行完,程式又空閑下來,于是我們安排「爬取網頁 C」開始執行,
依然假設步驟 1 和 3 需要花費 1 毫秒,步驟 2 花費 98 毫秒,算一算,只需要102 毫秒!
我們要爬 10 個或者 20 個網頁,現在預計分別只需要 109 毫秒和 119 毫秒,而假如我們用第二個例子里的方式運行,則分別需要 1000 毫秒和 2000 毫秒!
可以看到,我們僅僅是利用了爬蟲等待網站回應的空閑時間,爬蟲的效率就提升了數十倍,當爬取資料量更大時,爬蟲效率提升會更加的顯著,
回到問題:什么叫并發?
上面第二個例子就不是并發:我要做三件事,然后我一件一件完成它們,
上面的第三個例子就是并發:我們明明要做三件事,但是在這段時間內,我們交錯著做這三件事,就好像在 同時做這些事 !
而上面第一個例子里,我們只需要做一件事情,這時不管我們寫并發的代碼或者普通的代碼,它總是步驟 1-2-3 這樣被執行完,沒有什么區別,
上面第三種例子這種情況,在計算機中被稱為并發
讓我們用一段代碼,來讓大家直觀的看看并發是什么:
import time
import requests
class Adapter(requests.adapters.HTTPAdapter):
def send(self, *args, **kwargs):
global start
print(
"步驟 1 結束,耗時",
round((time.time() - start) * 1000),
"毫秒"
)
return super().send(*args, **kwargs)
s = requests.Session()
s.mount("https://", Adapter())
start = time.time()
r = s.get('https://www.baidu.com')
end = time.time()
print(
"步驟 2 結束,耗時",
round(r.elapsed.total_seconds() * 1000),
"毫秒"
)
print(
"步驟 3 結束,耗時",
int((end -start - r.elapsed.total_seconds()) * 1000),
"毫秒"
)
//輸出結果↓
//步驟 1 結束,耗時 2 毫秒
//步驟 2 結束,耗時 66 毫秒
//步驟 3 結束,耗時 1 毫秒
通過以上的講解,相信大家已經對并發有一個初步的認識了,接下來我們再來講講多執行緒
三、并發與多執行緒
作業系統為我們提供了兩個東西:行程和執行緒,利用這兩樣東西,我們可以輕易地實作代碼的并發,而不用考慮細枝末節,
例如,我們把下面三個任務丟到三個執行緒中,作業系統就能讓任務A等待時,啟動任務B,任務AB等待時,啟動任務C,而當任務A等待結束了,接著回去完成任務A,以此類推,在最短的時間內完成所有的任務,而不用擠占時間,
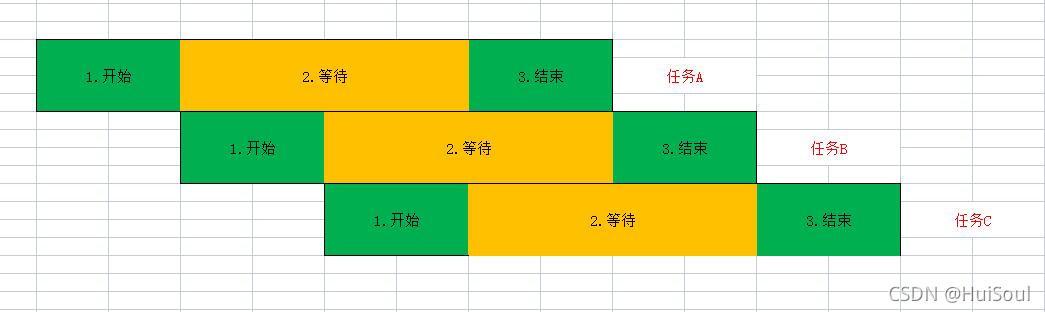
我們來比較一下,有用多執行緒和沒有用多執行緒的爬蟲程式的耗時究竟相差多少!
import time
import requests
# 匯入 concurrent.futures 這個包
from concurrent import futures
# 假設我們要爬取 30 個網頁
urls = ["https://wpblog.x0y1.com/?p=34"] * 30
session = requests.Session()
# 普通爬蟲
start1 = time.time()
results = []
for url in urls:
r = session.get(url)
results.append(r.text)
end1 = time.time()
print("普通爬蟲耗時", end1-start1, "秒")
# 多執行緒爬蟲
# 初始化一個執行緒池,最大的同時任務數是 5
executor = futures.ThreadPoolExecutor(max_workers=5)
start2 = time.time()
fs = []
for url in urls:
# 提交任務到執行緒池
f = executor.submit(session.get, url)
fs.append(f)
# 等待這些任務全部完成
futures.wait(fs)
# 獲取任務的結果
result = [f.result().text for f in fs]
end2 = time.time()
print("多執行緒爬蟲耗時", end2-start2, "秒")
#輸出結果↓ 耗時與線上環境和硬體條件有關
#普通爬蟲耗時 3.626128673553467 秒
#多執行緒爬蟲耗時 2.0856518745422363 秒
看到結果對比之后就會知道,通常情況下多執行緒爬蟲的效率會比單執行緒高很多,而且需要處理的任務量越多的時候,這個差異會越明顯,
好,我們再來仔細解讀一下這部分多執行緒爬蟲代碼,我們取出關鍵部分看看↓
# 匯入 concurrent.futures 這個包
from concurrent import futures
# 初始化一個執行緒池,最大的同時任務數是 5
executor = futures.ThreadPoolExecutor(max_workers=5)
concurrent 是 Python 自帶的庫,這個庫具有執行緒池和行程池、管理并行編程任務、處理非確定性的執行流程、行程/執行緒同步等功能,
executor 就是我們剛剛初始化的執行緒池,我們呼叫 executor 的 submit() 方法往里面提交任務,第一個引數 session.get 是提交要運行的函式,第二個引數 url 是提交的函式運行時的引數,
fs = []
for url in urls:
# 提交任務到執行緒池
f = executor.submit(session.get, url)
fs.append(f)
executor 就是我們剛剛初始化的執行緒池,我們呼叫 executor 的 submit() 方法往里面提交任務,第一個引數 session.get 是提交要運行的函式,第二個引數 url 是提交的函式運行時的引數,
executor.submit() 方法會給我們一個回傳值,它是一個 future 物件,我們把它賦值給變數 f,
# 等待這些任務全部完成
futures.wait(fs)
fs 是保存了上面所有任務的 future 物件的串列,futures.wait() 方法可以等待直到 fs 里面所有的 future 物件都有結果為止,
# 獲取任務的結果
result = [f.result().text for f in fs]
fs 是保存了上面所有任務的 future 物件的串列,我們遍歷所有任務的 future 物件,呼叫 future 物件的 result() 方法,就能得到任務的結果,
那結果是什么型別的呢?取決于提交的任務,比如我們提交的是 session.get(url),它的回傳值是一個 response 物件,那我們呼叫它的 text 屬性就能得到回應的完整內容了,
四、執行緒池
前面我們講過,執行緒是作業系統提供給我們的能力,可以把不同的任務放到不同的執行緒里,這樣它們可以同時運行,但是這個能力一定是有限的,并不能無止境的制造執行緒,如果運行的執行緒數太多,作業系統在安排這些執行緒的執行順序等事情上要花費很大的代價,
我們先來回憶一下一開始的第三個例子,在這個例子里,之所以切換到第二個任務可以提高我們的效率,是因為第一個任務已經處于空閑狀態,
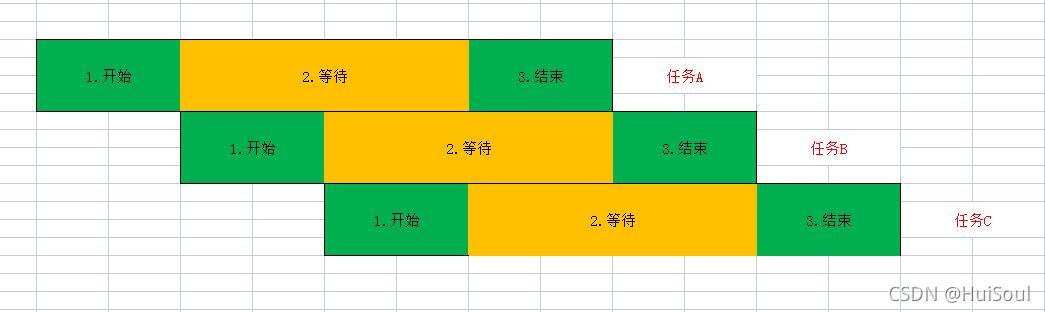
但假如我們的執行緒數非常多,步驟 1 可以一直往圖的右下堆疊,直到占滿了空閑時間,這時再加執行緒對爬蟲而言是沒有意義的,任務同樣要排隊來運行,
所以執行緒池其實就是限制了最多同時運行的執行緒數,比如我們初始化一個最大任務數為 5 的執行緒池,這樣即使我們提交了 100 任務到這個池子里,同時在運行的也只有五個,而一個任務被完成后,也會被移出執行緒池騰出空間,所以,用執行緒池可以避免上面提到的兩個問題,
其實還有第三個問題,就是考慮到被爬網站的性能和其反爬機制,我們也不應該讓機器過快地去運行爬蟲,執行緒池的數量建議可以在 10 左右,電腦性能好而且不擔心被爬取網站封禁的可以考慮加到幾十,性能差的可以考慮降到 5,
下一篇文章我會介紹一個并發爬取的專案實戰,希望有需要的同學來看看!!
文章鏈接:Python爬蟲深造篇(二)——多執行緒爬取虎撲網頁
本次分享到此結束,非常感謝大家閱讀!!
有問題歡迎評論區留言!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/321246.html
標籤:python