我正在嘗試通過 Tesseract 為 OCR 準備影像。然而,某些字符序列接觸(由于字體字形上的襯線),這會混淆它。
例如I/U:

我注意到每個角色都有一個明亮的輪廓。如果可以用深色代替,字母將獲得一些喘息空間。
img_grey[img_grey > 100] = 0
......但我無法讓它發揮作用。
有人知道更好的技術嗎?
uj5u.com熱心網友回復:
使用 OpenCV,您可以將其轉換為灰度,然后應用 OTSU 的閾值以獲得二值化影像,然后對其進行腐蝕:
import cv2
import numpy as np
im = cv2.imread('image.png')
im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
_, th = cv2.threshold(im, 120, 255, cv2.THRESH_BINARY cv2.THRESH_OTSU)
kernel = np.ones((5,5), np.uint8)
# Increase iterations if want more thinner
eroded = cv2.erode(th, kernel, iterations=2)
cv2.imwrite('eroded.png', eroded)
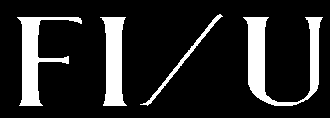
uj5u.com熱心網友回復:
您可以嘗試腐蝕影像,在opencv中有一個稱為腐蝕的操作,在這種情況下它基本上會縮小字符的厚度。這應該在字符之間留出一些空間,但要注意不要過度使用,否則 tesseract 可能無法識別該字符。可以通過反復試驗獲得適量的腐蝕。
有關更多詳細資訊,請參閱此鏈接。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/321295.html