我從 SQL 開始并做了一些練習,但我完全被最后一個困住了。它是關于尋找具有相同國家名稱的街道。使用了兩個表,位置和國家/地區來自 HR 模式。問題是我不知道如何避免重復結果。例如,如果我在加拿大有街道“x”,在加拿大也有街道“y”,它會向我顯示兩次:
- 街道 x / 加拿大 / 街道 y
- 街道 y / 加拿大 / 街道 x,我找不到糾正此問題的方法。
我的選擇是:
SELECT DISTINCT A.STREET_ADDRESS AS "CALLE A", C.COUNTRY_NAME, B.STREET_ADDRESS AS "CALLE B"
FROM HR.LOCATIONS A JOIN HR.LOCATIONS B ON (A.STREET_ADDRESS <> B.STREET_ADDRESS), HR.COUNTRIES C
WHERE A.COUNTRY_ID = B.COUNTRY_ID AND B.COUNTRY_ID = C.COUNTRY_ID
ORDER BY C.COUNTRY_NAME
我得到這個結果_
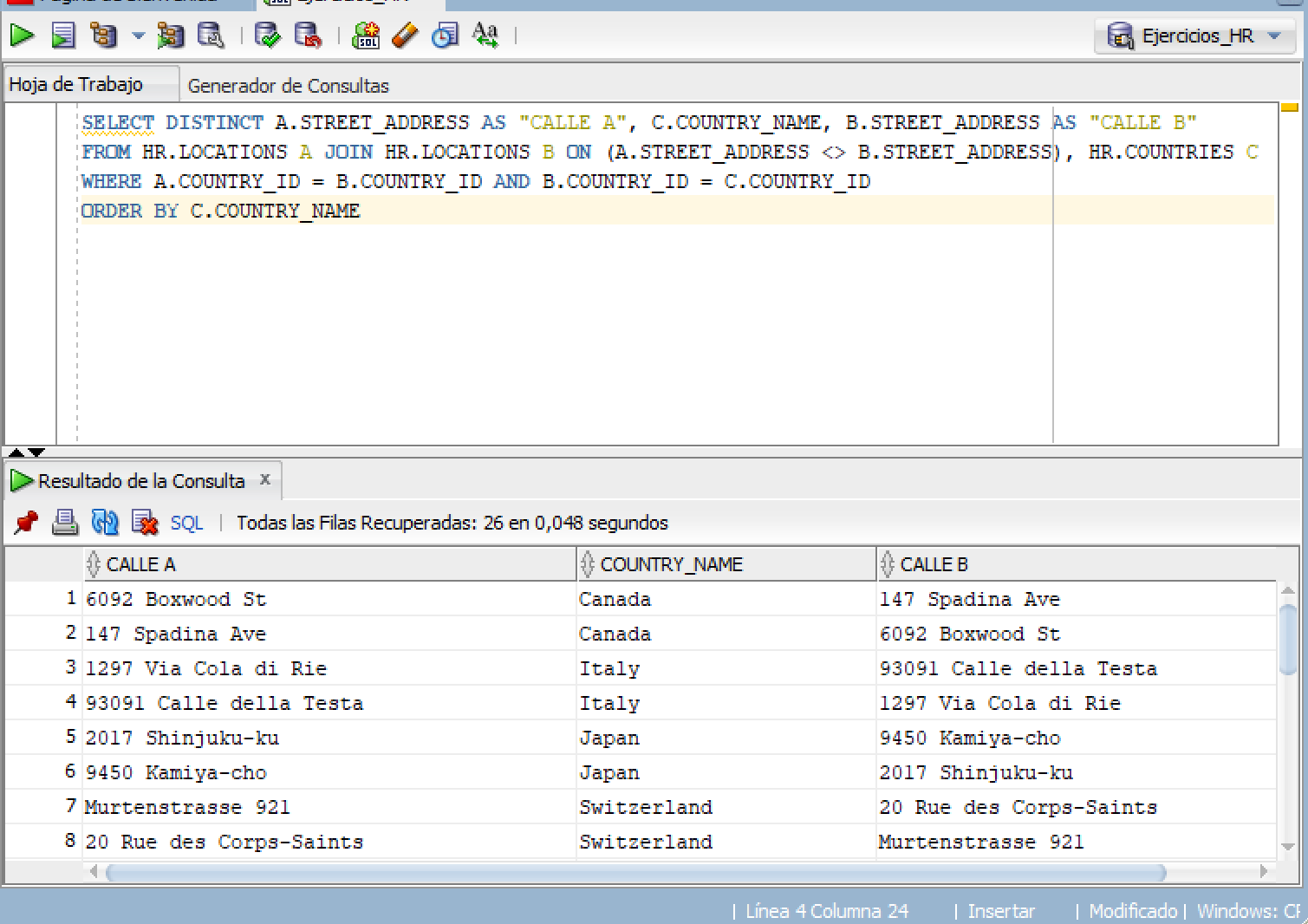
有任何想法嗎?謝謝你。
uj5u.com熱心網友回復:
使用 < 代替 <>
SELECT DISTINCT A.STREET_ADDRESS AS "CALLE A", C.COUNTRY_NAME, B.STREET_ADDRESS AS "CALLE B"
FROM HR.LOCATIONS A JOIN HR.LOCATIONS B ON (A.STREET_ADDRESS > B.STREET_ADDRESS), HR.COUNTRIES C
WHERE A.COUNTRY_ID = B.COUNTRY_ID AND B.COUNTRY_ID = C.COUNTRY_ID
ORDER BY C.COUNTRY_NAME
uj5u.com熱心網友回復:
所有正確的答案在邏輯上應該是等價的。但是,您可能希望使用更接近于此的表單。
忽略對齊,除非你覺得它有助于可讀性(我碰巧)。
正如@jarlh 提到的,我更多地指的是 JOIN / ON 形式(避免在FROM子句中使用逗號分隔的表運算式,稱為<table reference list>...一個<table reference>通常就足夠了),并保持連接標準(在ON子句中)更接近FROM子句中的相應表,除非您有特殊原因將任何邏輯與WHERE子句分開(盡量避免這種情況,除非必要)。
從邏輯上講,我們可以用很多不同的方式來撰寫這些。有些可能更容易寫/讀。
SELECT A.STREET_ADDRESS AS "CALLE A"
, C.COUNTRY_NAME
, B.STREET_ADDRESS AS "CALLE B"
FROM HR.LOCATIONS A
JOIN HR.LOCATIONS B
ON A.COUNTRY_ID = B.COUNTRY_ID
AND A.STREET_ADDRESS < B.STREET_ADDRESS
JOIN HR.COUNTRIES C
ON B.COUNTRY_ID = C.COUNTRY_ID
ORDER BY C.COUNTRY_NAME
;
正如@nbk 指出的那樣,不平等避免了街道反射。
SELECT DISTINCT如果您的連接邏輯和選定的詳細資訊足以識別唯一位置,則實際上并不需要這樣做。如果沒有,結果可能沒有實際用處。
如果這是樣本資料的一小部分和/或這些街道地址在每個國家/地區都是唯一的,那么您也可以,DISTINCT不需要。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/321319.html