所以我有一個代碼如下:
Yb=pd.DataFrame(y, column='something')
df_merge = pd.merge(Yb, file, on='something', how='left')
我不太明白代碼是做什么的?在這里做什么column=和on=作業?
uj5u.com熱心網友回復:
columnsIndex 或類似陣列的列標簽,當資料沒有它們時用于結果幀,默認為 RangeIndex(0, 1, 2, ..., n)。如果資料包含列標簽,將改為執行列選擇。
所以yb,y是被訪問的資料,和column說法是,好了,列。這是一個簡單的例子。
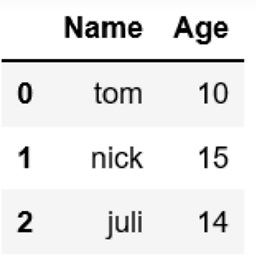
# Import pandas library
import pandas as pd
# initialize list of lists
data = [['tom', 10], ['nick', 15], ['juli', 14]]
# Create the pandas DataFrame
df = pd.DataFrame(data, columns = ['Name', 'Age'])
# print dataframe.
df
這將輸出如下內容:
至于df_merge,我們本質上是在組合資料。它需要兩個引數,左邊的 DataFrame 和右邊的 DataFrame。因此Yb,“檔案”是您正在合并的 2 個資料幀。以下是其他論點:
how:這定義了要進行的合并型別。它默認為 'inner',但其他可能的選項包括 'outer'、'left' 和 'right'。
on:使用它來告訴 merge() 您要加入哪些列或索引(也稱為鍵列或鍵索引)。這是可選的。如果未指定,并且 left_index 和 right_index(如下所述)為 False,則共享名稱的兩個 DataFrame 中的列將用作連接鍵。如果使用 on,則指定的列或索引必須存在于兩個物件中。
在這種情況下,how設定為left。
使用左外連接將使新合并的 DataFrame 保留來自左側 DataFrame 的所有行,同時丟棄右側 DataFrame 中在左側 DataFrame 的鍵列中沒有匹配項的行。
并on設定為something,因此它將專門合并something列。
希望這有幫助。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/322015.html
上一篇:在回圈中檢索索引時出現問題