
HashMap基本原理和優缺點
HashMap基本原理和優缺點
一句話講, HashMap底層資料結構,JDK1.7陣列+單向鏈表、JDK1.8陣列+單向鏈表+紅黑樹,
HashMap的3個底層原理
HashMap的3個底層原理
在看過了ArrayList、LinkedList的底層原始碼后,相信你對閱讀JDK原始碼已經輕車熟路了,除了List很多時候你使用最多的還有Map和Set,接下來我將用三張圖和你一起來探索下HashMap的底層核心原理到底有哪些?
這一節我們就不一步一步帶著大家看原始碼,直接通過3張原始碼原理圖,給大家講解HashMap原理圖,有了之前的經驗,相信你應該有能力自己看懂原理和自己畫圖了,
首先你應該知道HashMap的核心方法之一就是put,我們帶著如下幾個問題來看下圖:
-
- hash值計算的演算法是什么?就是key.hashCode()嗎?
- 默認情況下,put第一個元素時候容量大小是多少?擴容閾值又是多少?
- hash尋址如何進行的?
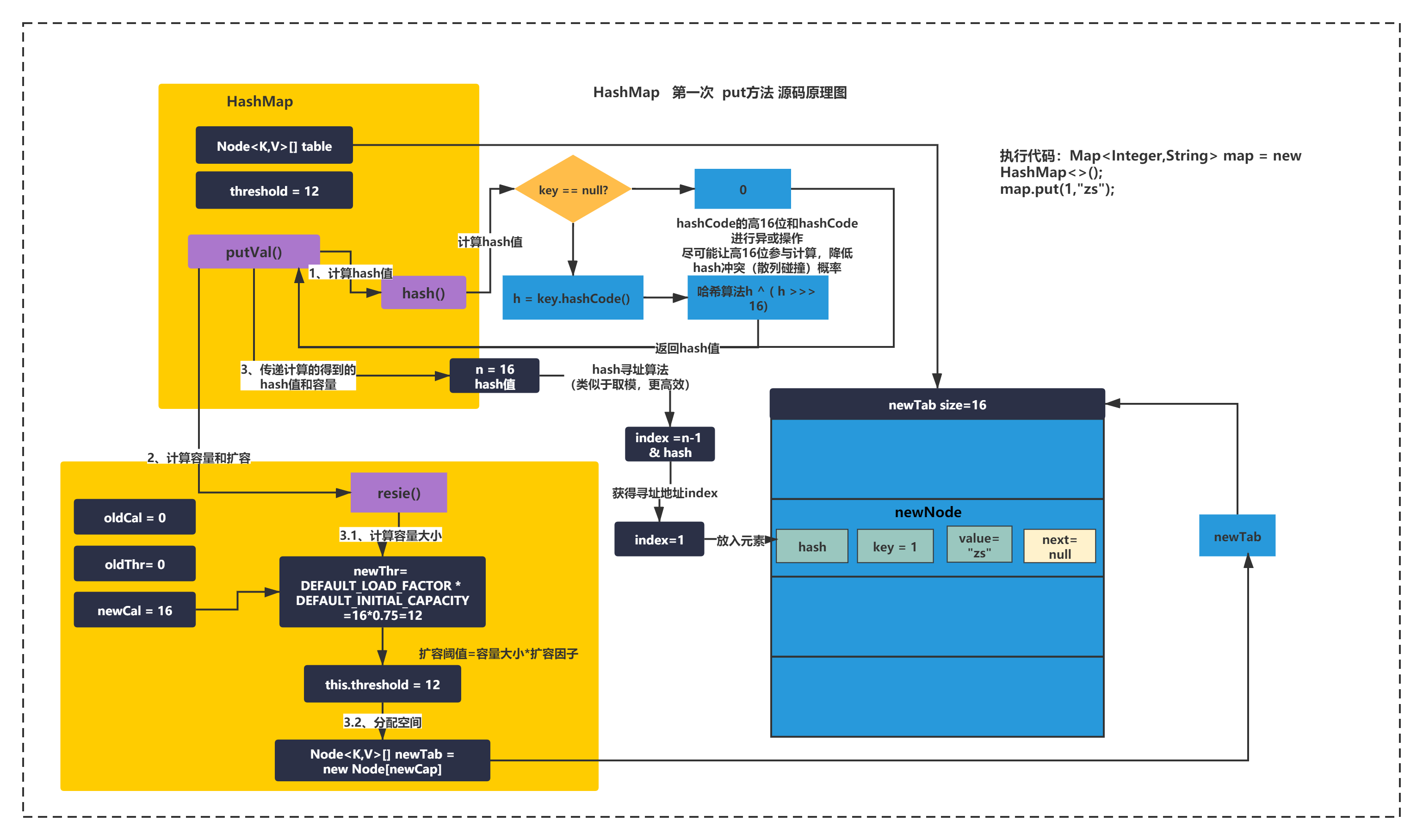
如上圖所示,put方法呼叫了putVal方法,之后主要脈絡是:
- 第一步呼叫了hash方法計算hash值,
- 第二步計算容量和擴容
- 第三步創建元素
如何計算hash值?
計算hash值的演算法就在第一步,如圖所示,對key值進行hashCode()后,對hashCode的值進行無符號右移16位和hashCode值進行了異或操作,為什么這么做呢?其實涉及了很多數學知識,簡單的說就是盡可能讓高16和低16位參與運算,可以減少hash值的沖突(資料結構演算法課中可能叫散列碰撞),
默認容量和擴容閾值是多少?
如上圖所示,很明顯第二步回呼叫resize方法,獲取到默認容量為16,這個16在原始碼里是1<<4得到的,1左移4位得到的,之后由于默認擴容因子是0.75,所以兩者相乘就是擴容大小閾值16*0.75=12,之后就分配了一個大小為16的Node[]陣列,作為Key-Value對存放的資料結構,
最后一問題是,如何進行hash尋址的?
hash尋址其實就在陣列中找一個位置的意思,用的演算法其實也很簡單,就是用陣列大小和hash值進行n-1&hash運算,這個操作和對hash取模很類似,只不過這樣效率更高而已,hash尋址后,就得到了一個位置,可以把key-value的Node元素放入到之前創建好的Node[]陣列中了,
HashMap另外3個底層原理
HashMap另外3個底層原理
當你了解了上面的三個原理后,你還需要掌握如下幾個問題:
- hash值如果計算的相同該怎么解決沖突?
- HashMap擴容后怎么進行rehash的?
- 指定大小的HashMap,擴容閾值演算法是什么?
還是老規矩,看如下圖:
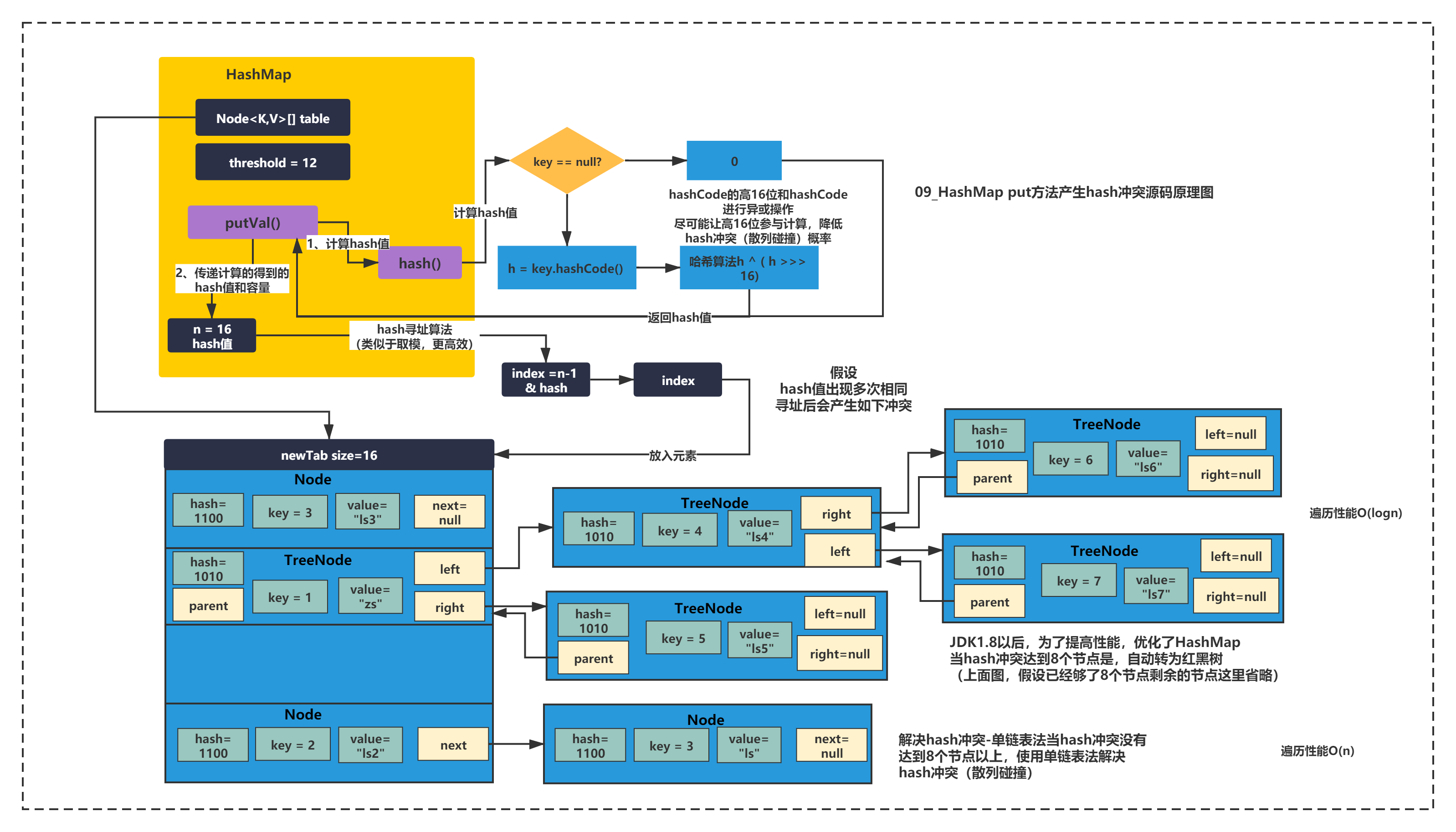
- hash值如果計算的相同該怎么解決沖突?
當hash值計算一致,比如當hash值都是1100時,Key-Value對的Node節點還有一個next指標,會以單鏈表的形式,將沖突的節點掛在陣列同樣位置,這就是資料結構中所提到解決hash 的沖突方法之一:單鏈法,當然還有探測法+rehash法有興趣的人可以回顧《資料結構和演算法》相關書籍,
但是當hash沖突嚴重的時候,單鏈法會造成原理鏈接過長,導致HashMap性能下降,因為鏈表需要逐個遍歷性能很差,所以JDK1.8對hash沖突的演算法進行了優化,當鏈表節點數達到8個的時候,會自動轉換為紅黑樹,自平衡的一種二叉樹,有很多特點,比如區分紅和黑節點等,具體大家可以看小灰演算法圖解,紅黑樹的遍歷效率是O(logn)肯定比單鏈表的O(n)要好很多,
總結一句話就是,hash沖突使用單鏈表法+紅黑樹來解決的,
- HashMap擴容后怎么進行rehash的?
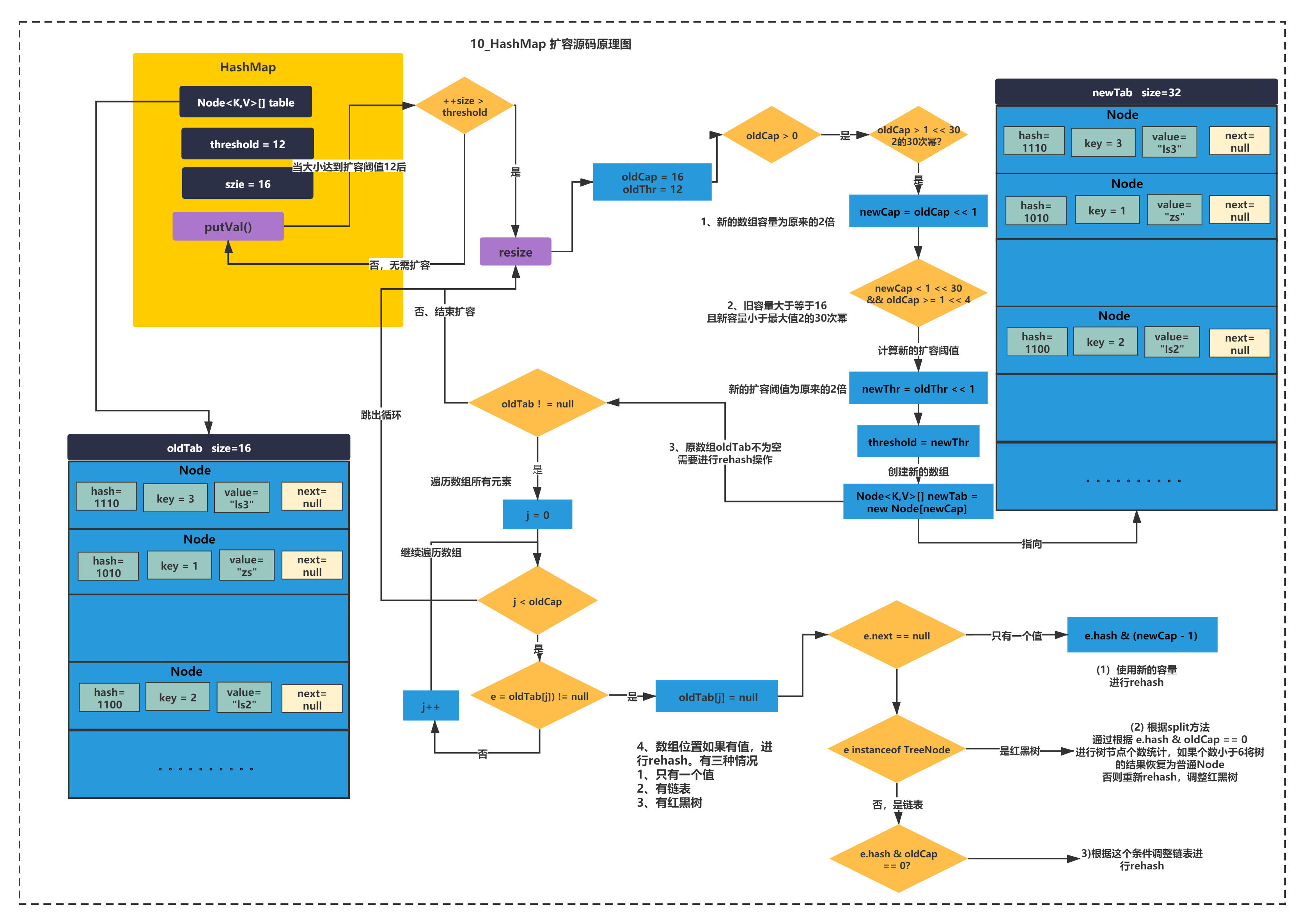
上面的圖,核心脈絡是四步,原始碼具體的就不粘出來了,當put一個之后,map的size達到擴容閾值12,就會觸發rehash,你可以看到如下具體思路:
-
新的陣列容量為原來的2倍,比如16-32
-
新的擴容閾值也是原來的2倍,比如12->24
-
為新陣列分配了空間newTab,原陣列oldTab不為空,需要進行rehash操作
-
rehash有3種情況,陣列位置如果有值,進行rehash,(這一步是rehash核心中的核心)有如下三種情況:
情況1:如果陣列位置只有一個值:使用新的容量進行rehash,即e.hash & (newCap - 1)
情況2:如果陣列位置有鏈表,根據 e.hash & oldCap == 0進行判斷,結果為0的使用原位置,否則使用index + oldCap位置,放入元素形成新鏈表,這里不會和情況1新的容量進行rehash與運算了,index + oldCap這樣更省性能,
情況3:如果陣列位置有紅黑樹,根據split方法,同樣根據 e.hash & oldCap == 0進行樹節點個數統計,如果個數小于6,將樹的結果恢復為普通Node,否則使用index + oldCap,調整紅黑樹位置,這里不會和新的容量進行rehash與運算了,index + oldCap這樣更省性能,
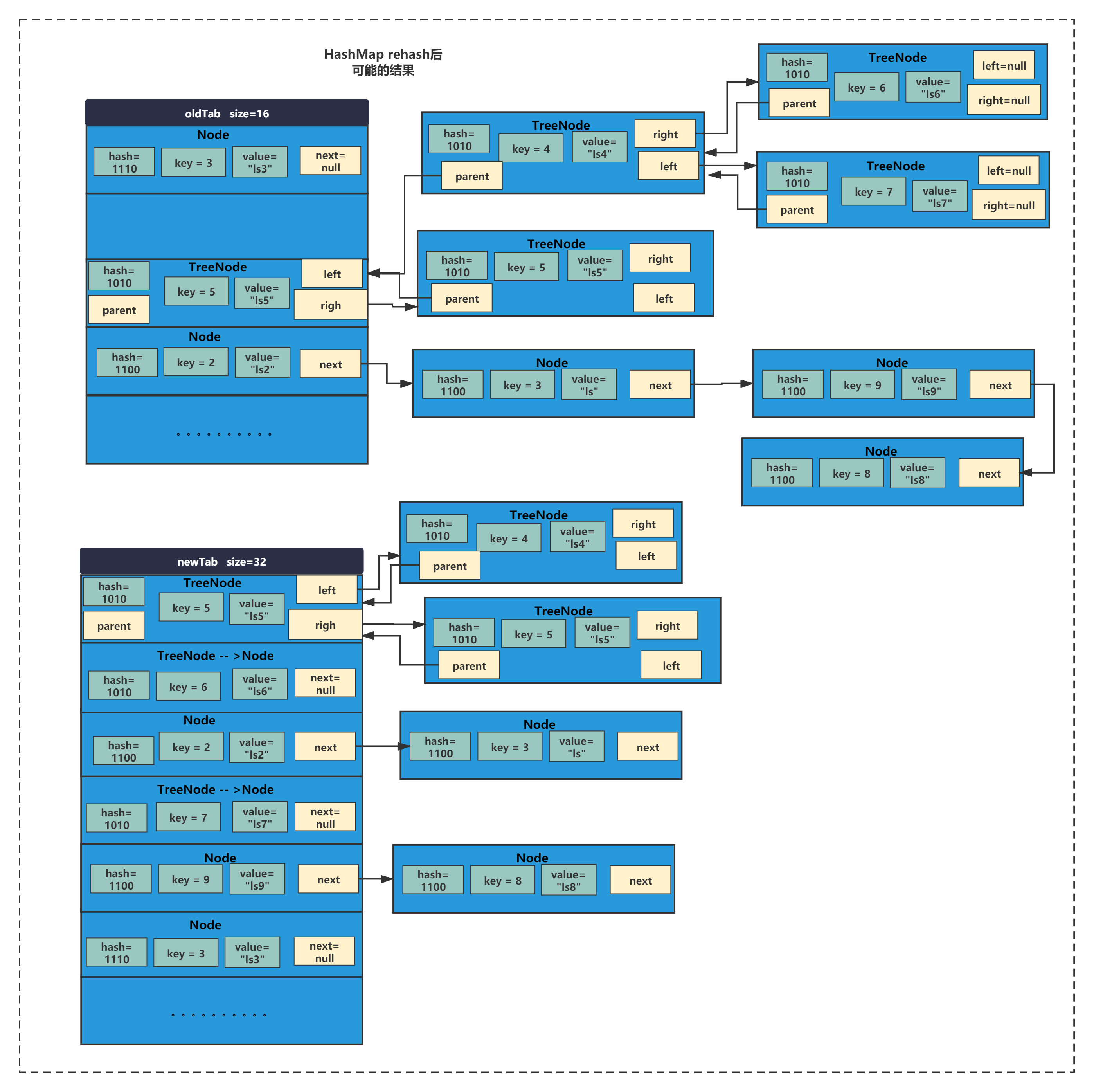
你有興趣的話,可以分別畫一下這三種情況的圖,這里給大家一個圖,假設都出發了以上三種情況結果如下所示:
上面的圖,核心脈絡是四步,原始碼具體的就不粘出來了,當put一個之后,map的size達到擴容閾值12,就會觸發rehash,你可以看到如下具體思路:
-
新的陣列容量為原來的2倍,比如16-32
-
新的擴容閾值也是原來的2倍,比如12->24
-
為新陣列分配了空間newTab,原陣列oldTab不為空,需要進行rehash操作
-
rehash有3種情況,陣列位置如果有值,進行rehash,(這一步是rehash核心中的核心)有如下三種情況:
情況1:如果陣列位置只有一個值:使用新的容量進行rehash,即e.hash & (newCap - 1)
情況2:如果陣列位置有鏈表,根據 e.hash & oldCap == 0進行判斷,結果為0的使用原位置,否則使用index + oldCap位置,放入元素形成新鏈表,這里不會和情況1新的容量進行rehash與運算了,index + oldCap這樣更省性能,
情況3:如果陣列位置有紅黑樹,根據split方法,同樣根據 e.hash & oldCap == 0進行樹節點個數統計,如果個數小于6,將樹的結果恢復為普通Node,否則使用index + oldCap,調整紅黑樹位置,這里不會和新的容量進行rehash與運算了,index + oldCap這樣更省性能,
你有興趣的話,可以分別畫一下這三種情況的圖,這里給大家一個圖,假設都出發了以上三種情況結果如下所示:
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
上面原始碼核心脈絡,3個if主要是校驗了一堆,沒做什么事情,之后賦值了擴容因子,不傳遞使用默認值0.75,擴容閾值threshold通過tableSizeFor(initialCapacity);進行計算,注意這里只是計算了擴容閾值,沒有初始化陣列,代碼如下:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
竟然不是大小*擴容因子?
n |= n >>> 1這句話,是在干什么?n |= n >>> 1等價于n = n | n >>>1; 而|表示位運算中的或,n>>>1表示無符號右移1位,遇到這種情況,之前你應該學到了,如果碰見復雜邏輯和演算法方法就是畫圖或者舉例子,這里你就可以舉個例子:假設現在指定的容量大小是100,n=cap-1=99,那么計算程序應該如下:
n是int型別,java中一般是4個位元組,32位,所以99的二進制:0000 0000 0000 0000 0000 0000 0110 0011,
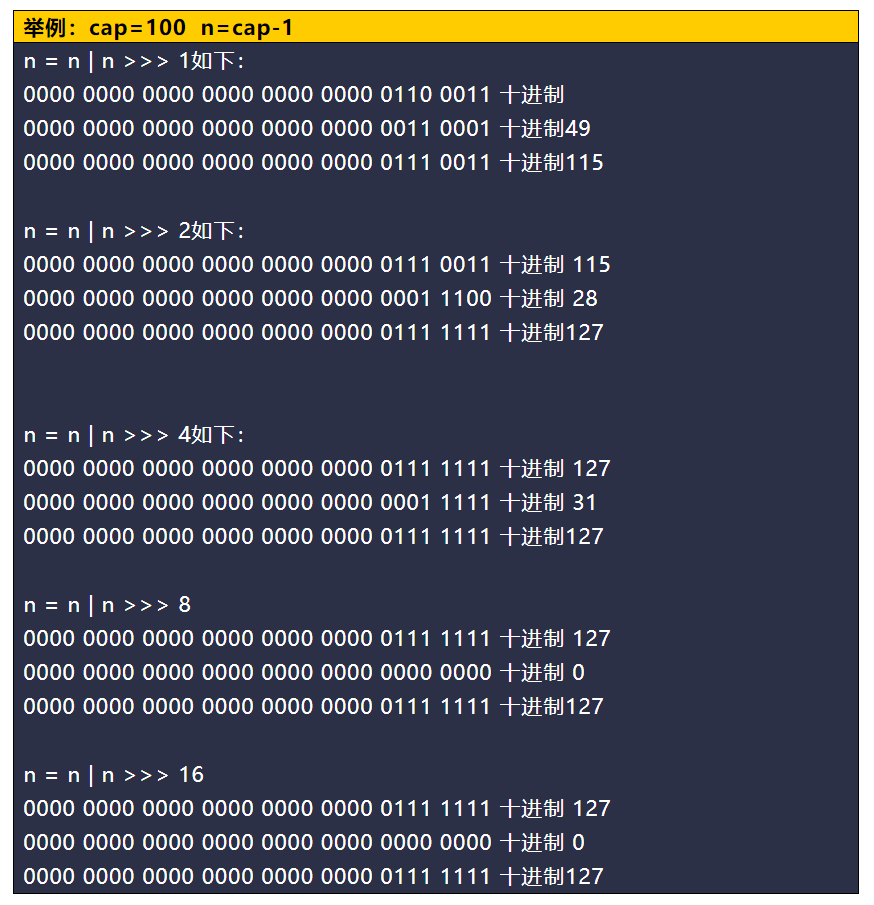
最后n+1=128,方法回傳,賦值給threshold=128,再次注意這里只是計算了擴容閾值,沒有初始化陣列,
為什么這么做呢?一句話,為了提高hash尋址和擴容計算的的效率,
因為無論擴容計算還是尋址計算,都是二進制的位運算,效率很快,另外之前你還記得取余(%)操作中如果除數是2的冪次方則等同于與其除數減一的與(&)操作,即 hash%size = hash & (size-1),這個前提條件是除數是2的冪次方,
你可以再回顧下resize代碼,看看指定了map容量,第一次put會發生什么,會將擴容閾值threshold,這樣在第一次put的時候就會呼叫newCap = oldThr;使得創建一個容量為threshold的陣列,之后從而會計算新的擴容閾值newThr為newCap*0.75=128*0.75=96,也就是說map到了96個元素就會進行擴容,
JDK1.7 HashMap死回圈問題?
JDK1.7 HashMap死回圈問題?
-
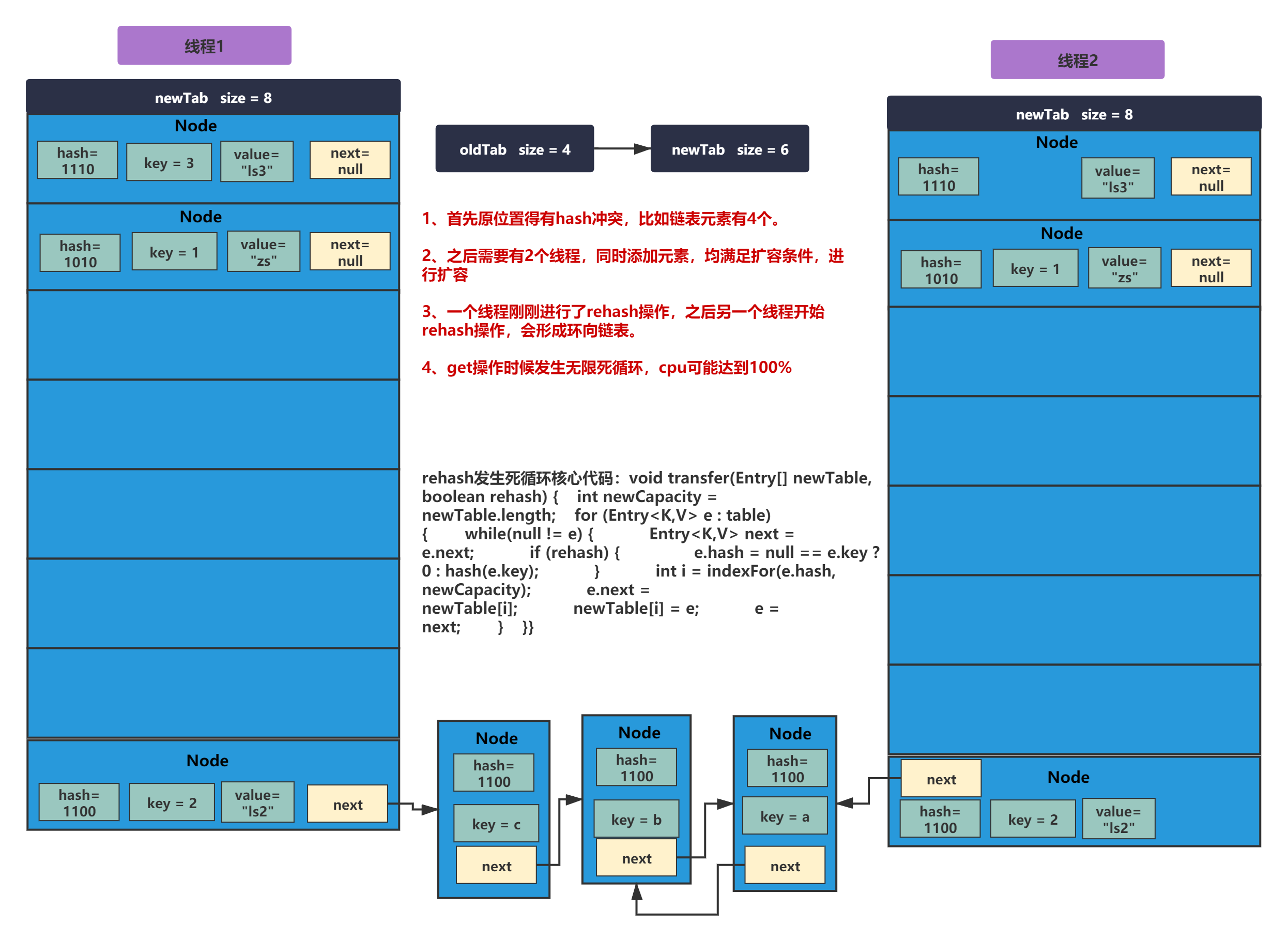
在JDK1.8引入紅黑樹之前,JDK1.7由于只有單向鏈表解決hash沖突,除了遍歷性能可能會慢,還有幾率在多執行緒同時擴容,rehash的時候發生死回圈問題,造成cpu100%,雖然把hashMap用到多執行緒很不合理,但是有時候面試總會考這么刁鉆的問題,面試圈有時候還是比較復雜的,,,
造成死回圈的這個問題,程序比較復雜,這一節可能講不完了,這里給大家拋磚引玉下,
造成死回圈的核心脈絡有如下幾步:
1、首先原位置得有hash沖突,比如鏈表元素有4個,
2、之后需要有2個執行緒,同時添加元素,均滿足擴容條件,進行擴容
3、一個執行緒剛剛進行了rehash操作,之后另一個執行緒開始rehash操作,會形成環向鏈表,
4、get操作時候發生無限死回圈,cpu可能達到100%
如下圖:
金句甜點
金句甜點
除了今天知識,技能的成長,給大家帶來一個金句甜點,結束我今天的分享:堅持的三個秘訣之一目標化,
堅持的秘訣除了上一節提到的視徑訓,第二個秘訣就是目標化,顧名思義,就是需要給自己定立一個目標,這里要提到的是你的目標不要定的太高了,就比如你想要增加肌肉,給自己定了一個目標,每天5組,每次10個俯臥撐,你看到自己胖的身形或者海報,很有刺激,結果開始前兩天非常厲害,干勁十足,特別奧利給,但是第三天,你想到要50個俯臥撐,你就不想起床,就算起來,可能也會把自己撅死過去......其實你的目標不要一下子定的太大,要從微習慣開始,比如我媳婦從來沒有做過俯臥撐,就讓她每天從1個開始,不能多,我就怕她收不住,做多了,一開始其實從習慣開始,先變成習慣,再開始慢慢加量,量太大養不成習慣,量小才能養成習慣,很容易做到才能養成,你想想是不是這個道理?
所以,堅持的第二個秘訣就是定一個目標,可以通過小量目標,養成微習慣,比如每天你可以讀五分鐘書或者5分鐘成長記,不要多,我想超過你也會睡著了的.....
最后,大家可以在閱讀完原始碼后,在茶余飯后的時候問問同事或同學,你也可以分享下,講給他聽聽,
歡迎大家在評論區留言和我交流,
(宣告:JDK原始碼成長記基于JDK 1.8版本,部分章節會提到舊版本特點)
本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/322956.html
標籤:Java