第一章 1000W用戶的問題分解
如何支撐1000W用戶其實是一個非常抽象的問題,對于技術開發來說,我們需要一個非常明確的對于執行關鍵業務上的性能指標資料,比如,高峰時段下對于事務的回應時間、并發用戶數、QPS、成功率、以及基本指標要求等,這些都 必須要非常明確,只有這樣才能夠指導整個架構的改造和優化,所以,如果大家接到這樣一個問題,首先需要去定位到問題的本質,也就是首先得知道一些可量化的資料指標,
?如果有過往的相似業務交易歷史資料經驗,你需要盡量參考,處理這些收集到的原始資料(日志),從而分析出高峰時段,以及該時段下的交易行為,交易規模等,得到你想要看清楚的需求細節?另外一種情況,就是沒有相關的資料指標作為參考,這個時候就需要經驗來分析,比如可以參考一些類似行業的比較成熟的業務交易模型(比如銀行業的日常交易活動或交通行業售檢票交易活動)或者干脆遵循“2/8”原則和“2/5/8”原則來直接下手實踐,
?當用戶能夠在2秒以內得到回應時,會感覺系統的回應很快;?當用戶在2-5秒之間得到回應時,會感覺系統的回應速度還可以;?當用戶在5-8秒以內得到回應時,會感覺系統的回應速度很慢,但是還可以接受;?而當用戶在超過8秒后仍然無法得到回應時,會感覺系統糟透了,或者認為系統已經失去回應,而選擇離開這個Web站點,或者發起第二次請求,
在估算回應時間、并發用戶數、TPS、成功率這些關鍵指標的同時,你仍需要關心具體的業務功能維度上的需求,每個業務功能都有各自的特點,比如有些場景可以不需要同步回傳明確執行結果,有些業務場景可以接受回傳“系統忙,請等待!”這樣暴力的訊息,以避免過大的處理流量所導致的大規模癱瘓,因此,學會平衡這些指標之間的關系是必要的,大多數情況下最好為這些指標做一個優先級排序,并且盡量只考察幾個優先級高的指標要求,(SLA服務等級)
SLA:Service-Level Agreement的縮寫,意思是服務等級協議,服務的SLA是服務提供者對服務消費者的正式承諾,是衡量服務能力等級的關鍵項,服務SLA中定義的項必須是可測量的,有明確的測量方法,
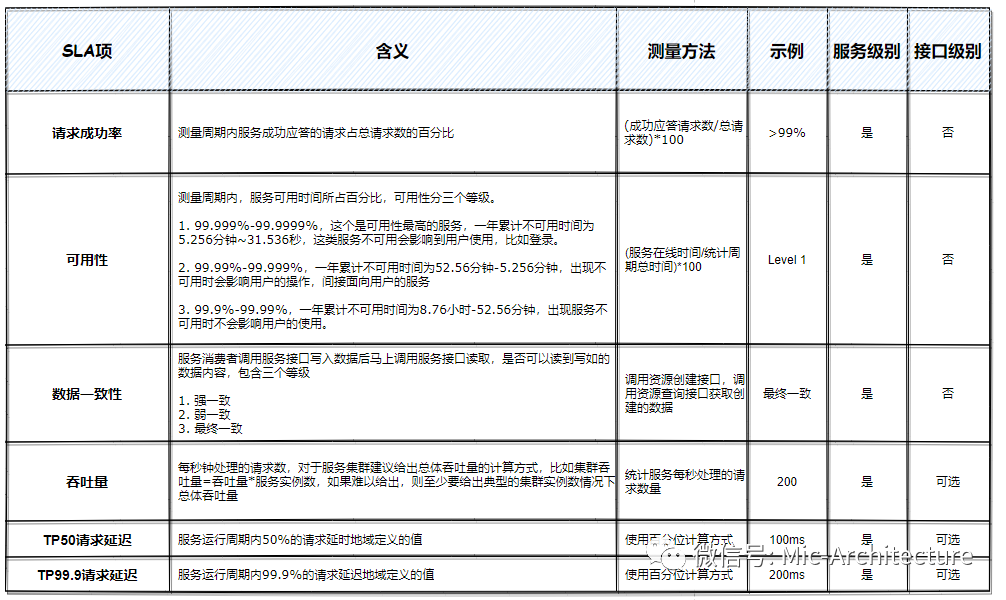
image-20210623165109183
1.1 并發中相關概念的解釋
在分析上述問題之前,先給大家普及一下,系統相關的一些關鍵衡量指標,
1.1.1 TPS
TPS(Transaction Per Second)每秒處理的事務數,
站在宏觀角度來說,一個事務是指客戶端向服務端發起一個請求,并且等到請求回傳之后的整個程序,從客戶端發起請求開始計時,等到收到服務器端回應結果后結束計時,在計算這個時間段內總共完成的事務個數,我們稱為TPS,
站在微觀角度來說,一個資料庫的事務操作,從開始事務到事務提交完成,表示一個完整事務,這個是資料庫層面的TPS,
1.1.2 QPS
QPS(Queries Per Second)每秒查詢數,表示服務器端每秒能夠回應的查詢次數,這里的查詢是指用戶發出請求到服務器做出回應成功的次數,可以簡單認為每秒鐘的Request數量,
針對單個介面而言,TPS和QPS是相等的,如果從宏觀層面來說,用戶打開一個頁面到頁面渲染結束代表一個TPS,那這個頁面中會呼叫服務器很多次,比如加載靜態資源、查詢服務器端的渲染資料等,就會產生兩個QPS,因此,一個TPS中可能會包含多個QPS,
QPS=并發數/平均回應時間
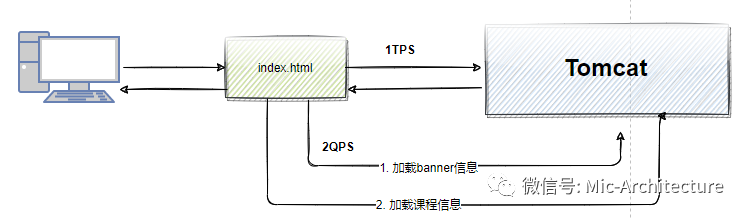
image-20210622180649041
1.1.3 RT
RT(Response Time),表示客戶端發起請求到服務端回傳的時間間隔,一般表示平均回應時間,
1.1.4 并發數
并發數是指系統同時能處理的請求數量,
需要注意,并發數和QPS不要搞混了,QPS表示每秒的請求數量,而并發數是系統同時處理的請求數量,并發數量會大于QPS,因為服務端的一個連接需要有一個處理時長,在這個請求處理結束之前,這個連接一直占用,
舉個例子,如果QPS=1000,表示每秒鐘客戶端會發起1000個請求到服務端,而如果一個請求的處理耗時是3s,那么意味著總的并發=1000*3=3000,也就是服務端會同時有3000個并發,
1.1.5 計算方法
上面說的這些指標,怎么計算呢?舉個例子,
假設在10點到11點這一個小時內,有200W個用戶訪問我們的系統,假設平均每個用戶請求的耗時是3秒,那么計算的結果如下:
?QPS=2000000/60*60 = 556 (表示每秒鐘會有556個請求發送到服務端)?RT=3s(每個請求的平均回應時間是3秒)?并發數=556*3=1668
從這個計算程序中發現,隨著RT的值越大,那么并發數就越多,而并發數代表著服務器端同時處理的連接請求數量,也就意味服務端占用的連接數越多,這些鏈接會消耗記憶體資源以及CPU資源等,所以RT值越大系統資源占用越大,同時也意味著服務端的請求處理耗時較長,
但實際情況是,RT值越小越好,比如在游戲中,至少做到100ms左右的回應才能達到最好的體驗,對于電商系統來說,3s左右的時間是能接受的,那么如何縮短RT的值呢?
1.2 按照2/8法則來推算1000w用戶的訪問量
繼續回到最開始的問題,假設沒有歷史資料供我們參考,我們可以使用2/8法則來進行預估,
?1000W用戶,每天來訪問這個網站的用戶占到20%,也就是每天有200W用戶來訪問,?假設平均每個用戶過來點擊50次,那么總共的PV=1億,?一天是24小時,根據2/8法則,每天大部分用戶活躍的時間點集中在(24*0.2) 約等于5個小時以內,而大部分用戶指的是(1億點擊 * 80%)約等于8000W(PV), 意味著在5個小時以內,大概會有8000W點擊進來,也就是每秒大約有4500(8000W/5小時)個請求,?4500只是一個平均數字,在這5個小時中,不可能請求是非常平均的,有可能會存在大量的用戶集中訪問(比如像淘寶這樣的網站,日訪問峰值的時間點集中在下午14:00、以及晚上21:00,其中21:00是一天中活躍的峰值),一般情況下訪問峰值是平均訪問請求的3倍到4倍左右(這個是經驗值),我們按照4倍來計算,那么在這5個小時內有可能會出現每秒18000個請求的情況,也就是說,問題由原本的支撐1000W用戶,變成了一個具體的問題,就是服務器端需要能夠支撐每秒18000個請求(QPS=18000)

image-20210622160313561

image-20210622160320454
1.3 服務器壓力預估
大概預估出了后端服務器需要支撐的最高并發的峰值之后,就需要從整個系統架構層面進行壓力預估,然后配置合理的服務器數量和架構,既然是這樣,那么首先需要知道一臺服務器能夠扛做多少的并發,那這個問題怎么去分析呢?我們的應用是部署在Tomcat上,所以需要從Tomcat本身的性能下手,
下面這個圖表示Tomcat的作業原理,該圖的說明如下,
?LimitLatch是連接控制器,它負責控制Tomcat能夠同時處理的最大連接數,在NIO/NIO2的模式中,默認是10000,如果是APR/native,默認是8192?Acceptor是一個獨立的執行緒,在run方法中,在while回圈中呼叫socket.accept方法中接收客戶端的連接請求,一旦有新的請求過來,accept會回傳一個Channel物件,接著把這個Channel物件交給Poller去處理,
Poller 的本質是一個 Selector ,它同樣也實作了執行緒,Poller 在內部維護一個 Channel 陣列,它在一個死回圈里不斷檢測 Channel 的資料就緒狀態,一旦有 Channel 可讀,就生成一個 SocketProcessor 任務物件扔給 Executor 去處理
?SocketProcessor 實作了 Runnable 介面,當執行緒池在執行SocketProcessor這個任務時,會通過Http11Processor去處理當前這個請求,Http11Processor 讀取 Channel 的資料來生成 ServletRequest 物件,?Executor 就是執行緒池,負責運行 SocketProcessor 任務類, SocketProcessor 的 run 方法會呼叫 Http11Processor 來讀取和決議請求資料,我們知道, Http11Processor 是應用層協議的封裝,它會呼叫容器獲得回應,再把回應通過 Channel 寫出,
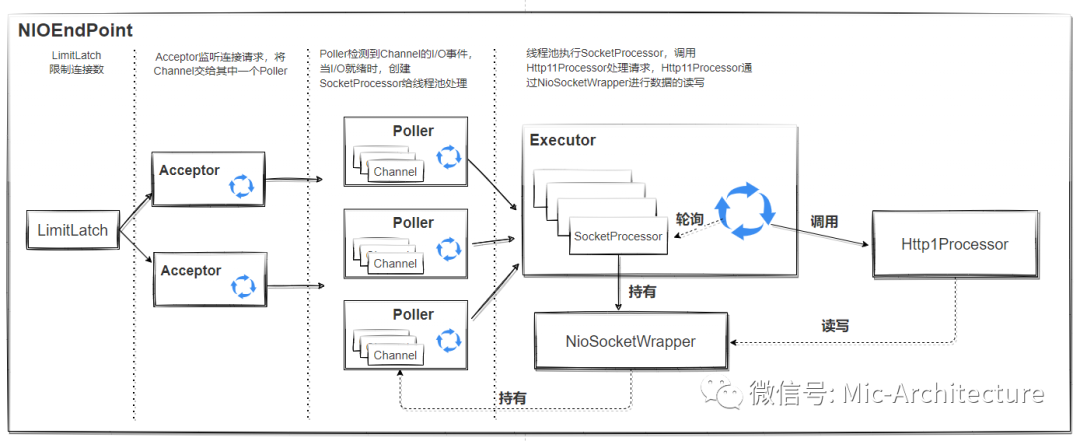
image-20210622154519229
從這個圖中可以得出,限制Tomcat請求數量的因素四個方面,
1.3.1 當前服務器系統資源
我想可能大家遇到過類似“Socket/File:Can't open so many files”的例外,這個就是表示Linux系統中的檔案句柄限制,
在Linux中,每一個TCP連接會占用一個檔案描述符(fd),一旦檔案描述符超過Linux系統當前的限制,就會提示這個錯誤,
我們可以通過下面這條命令來查看一個行程可以打開的檔案數量
ulimit -a 或者 ulimit -nopen files (-n) 1024 是linux作業系統對一個行程打開的檔案句柄數量的限制(也包含打開的套接字數量)
這里只是對用戶級別的限制,其實還有個是對系統的總限制,查看系統總限制:
cat /proc/sys/fs/file-maxfile-max是設定系統所有行程一共可以打開的檔案數量 ,同時一些程式可以通過setrlimit呼叫,設定每個行程的限制,如果得到大量使用完檔案句柄的錯誤資訊,是應該增加這個值,
當出現上述例外時,我們可以通過下面的方式來進行修改(針對單個行程的打開數量限制)
vi /etc/security/limits.confroot soft nofile 65535root hard nofile 65535* soft nofile 65535* hard nofile 65535
?*代表所有用戶、root表示root用戶,?noproc 表示最大行程數量?nofile代表最大檔案打開數量,?soft/hard,前者當達到閾值時,制作警告,后者會報錯,
另外還要注意,要確保針對行程級別的檔案打開數量范圍是小于或者等于系統的總限制,否則,我們需要修改系統的總限制,
vi /proc/sys/fs/file-maxTCP連接對于系統資源最大的開銷就是記憶體,
因為tcp連接歸根結底需要雙方接收和發送資料,那么就需要一個讀緩沖區和寫緩沖區,這兩個buffer在linux下最小為4096位元組,可通過cat /proc/sys/net/ipv4/tcp_rmem和cat /proc/sys/net/ipv4/tcp_wmem來查看,
所以,一個tcp連接最小占用記憶體為4096+4096 = 8k,那么對于一個8G記憶體的機器,在不考慮其他限制下,最多支持的并發量為:810241024/8 約等于100萬,此數字為純理論上限數值,在實際中,由于linux kernel對一些資源的限制,加上程式的業務處理,所以,8G記憶體是很難達到100萬連接的,當然,我們也可以通過增加記憶體的方式增加并發量,
1.3.2 Tomcat依賴的JVM的配置
我們知道Tomcat是Java程式,運行在JVM上,因此我們還需要對JVM做優化,才能更好的提升Tomcat的性能,簡單帶大家了解一下JVM,如下圖所示,

image-20210623204411021
在JVM中,記憶體劃分為堆、程式計數器、本地方法堆疊、方法區(元空間)、虛擬機堆疊,
1.3.2.1 堆空間說明
其中,堆記憶體是JVM記憶體中最大的一塊區域,幾乎所有的物件和陣列都會被分配到堆記憶體中,它被所有執行緒共享,堆空間被劃分為新生代和老年代,新生代進一步劃分為Eden和Surivor區,如下圖所示,
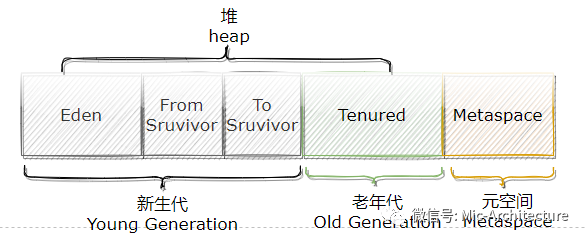
image-20210623205840226
新生代和老年代的比例是1:3,也就是新生代會占1/3的堆空間,老年代會占2/3的堆空間,另外,在新生代中,空間占比為Eden:Surivor0:Surivor1=8:1:1 ,舉個例子來說,如果eden區記憶體大小是40M,那么兩個Survivor區分別是占5M,整個新生代就是50M,然后計算出老年代的記憶體大小是100M,也就是說堆空間的總記憶體大小是150M,
可以通過 java -XX:PrintFlagsFinal -version查看默認引數
uintx InitialSurvivorRatio = 8uintx NewRatio = 2
InitialSurvivorRatio: 新生代Eden/Survivor空間的初始比例
NewRatio :Old區/Young區的記憶體比例
堆記憶體的具體作業原理是:
?絕大部分的物件被創建之后,會保存在Eden區,當Eden區滿了的時候,就會觸發YGC(Young GC),大部分物件會被回收掉,如果還有活著的物件,就拷貝到Survivor0,這時Eden區被清空,?如果后續再次觸發YGC,活著的物件Eden+Survivor0中的物件拷貝到Survivor1區, 這時Eden和Survivor0都會被清空?接著再觸發YGC,Eden+Survivor1中的物件會被拷貝到Survivor0區,一直這么回圈,直到物件的年齡達到閾值,則放入到老年代,(之所以這么設計,是因為Eden區的大部分物件會被回收)?Survivor區裝不下的物件會直接進入到老年代?老年代滿了,會觸發Full GC,
GC標記-清除演算法 在執行程序中暫停其他執行緒??
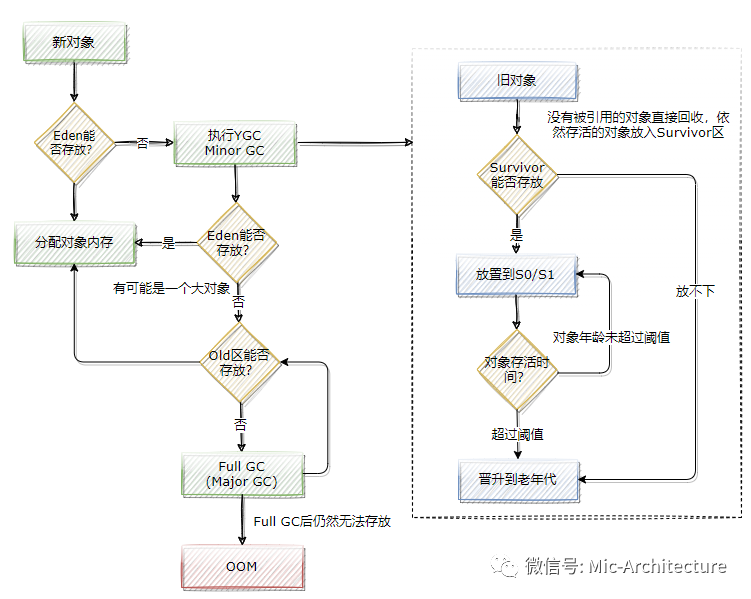
image-20210623214030533
1.3.2.2 程式計數器
程式計數器是用來記錄各個執行緒執行的位元組碼地址等,當執行緒發生背景關系切換時,需要依靠這個來記住當前執行的位置,當下次恢復執行后要沿著上一次執行的位置繼續執行,
1.3.2.3 方法區
方法區是邏輯上的概念,在HotSpot虛擬機的1.8版本中,它的具體實作就是元空間,
方法區主要用來存放已經被虛擬機加載的類相關資訊,包括類元資訊、運行時常量池、字串常量池,類資訊又包括類的版本、欄位、方法、介面和父類資訊等,
方法區和堆空間類似,它是一個共享記憶體區域,所以方法區是屬于執行緒共享的,
1.3.2.4 本地方法堆疊和虛擬機堆疊
Java虛擬機堆疊是執行緒私有的記憶體空間,當創建一個執行緒時,會在虛擬機中申請一個執行緒堆疊,用來保存方法的區域變數、運算元堆疊、動態鏈接方法等資訊,每一個方法的呼叫都伴隨著堆疊幀的入堆疊操作,當一個方法回傳之后,就是堆疊幀的出堆疊操作,
本地方法堆疊和虛擬機堆疊類似,本地方法堆疊是用來管理本地方法的呼叫,也就是native方法,
1.3.2.5 JVM記憶體應該怎么設定
了解了上述基本資訊之后,那么JVM中記憶體應該如何設定呢?有哪些引數來設定?
而在JVM中,要配置的幾個核心引數無非是,
?-Xms,Java堆記憶體大小?-Xmx,Java最大堆記憶體大小?-Xmn,Java堆記憶體中的新生代大小,扣除新生代剩下的就是老年代記憶體新生代記憶體設定過小會頻繁觸發Minor GC,頻繁觸發GC會影響系統的穩定性?-XX:MetaspaceSize,元空間大小, 128M?-XX:MaxMetaspaceSize,最大云空間大小 (如果沒有指定這兩個引數,元空間會在運行時根據需要動態調整,) 256M
一個新系統的元空間,基本上沒辦法有一個測算的方法,一般設定幾百兆就夠用,因為這里面主要存放一些類資訊,
?-Xss,執行緒堆疊記憶體大小,這個基本上不需要預估,設定512KB到1M就行,因為值越小,能夠分配的執行緒數越多,
JVM記憶體的大小,取決于機器的配置,比如一個2核4G的服務器,能夠分配給JVM行程也就2G左右,因為機器本身也需要記憶體,而且機器上還運行了其他的行程也需要占記憶體,而這2G還得分配給堆疊記憶體、堆記憶體、元空間,那堆記憶體能夠得到的也就1G左右,然后堆記憶體還要分新生代、老年代,
1.3.3 Tomcat本身的配置
http://tomcat.apache.org/tomcat-8.0-doc/config/http.html
The maximum number of request processing threads to be created by this Connector, which therefore determines the maximum number of simultaneous requests that can be handled. If not specified, this attribute is set to 200. If an executor is associated with this connector, this attribute is ignored as the connector will execute tasks using the executor rather than an internal thread pool. Note that if an executor is configured any value set for this attribute will be recorded correctly but it will be reported (e.g. via JMX) as
-1to make clear that it is not used.
server:tomcat:uri-encoding: UTF-8#最大作業執行緒數,默認200, 4核8g記憶體,執行緒數經驗值800#作業系統做執行緒之間的切換調度是有系統開銷的,所以不是越多越好,max-threads: 1000# 等待佇列長度,默認100,accept-count: 1000max-connections: 20000# 最小作業空閑執行緒數,默認10, 適當增大一些,以便應對突然增長的訪問量min-spare-threads: 100
?accept-count: 最大等待數,當呼叫HTTP請求數達到tomcat的最大執行緒數時,還有新的HTTP請求到來,這時tomcat會將該請求放在等待佇列中,這個acceptCount就是指能夠接受的最大等待數,默認100,如果等待佇列也被放滿了,這個時候再來新的請求就會被tomcat拒絕(connection refused)?maxThreads:最大執行緒數,每一次HTTP請求到達Web服務,tomcat都會創建一個執行緒來處理該請求,那么最大執行緒數決定了Web服務容器可以同時處理多少個請求,maxThreads默認200,肯定建議增加,但是,增加執行緒是有成本的,更多的執行緒,不僅僅會帶來更多的執行緒背景關系切換成本,而且意味著帶來更多的記憶體消耗,JVM中默認情況下在創建新執行緒時會分配大小為1M的執行緒堆疊,所以,更多的執行緒意味著需要更多的記憶體,執行緒數的經驗值為:1核2g記憶體為200,執行緒數經驗值200;4核8g記憶體,執行緒數經驗值800,?maxConnections,最大連接數,這個引數是指在同一時間,tomcat能夠接受的最大連接數,對于Java的阻塞式BIO,默認值是maxthreads的值;如果在BIO模式使用定制的Executor執行器,默認值將是執行器中maxthreads的值,對于Java 新的NIO模式,maxConnections 默認值是10000,對于windows上APR/native IO模式,maxConnections默認值為8192如果設定為-1,則禁用maxconnections功能,表示不限制tomcat容器的連接數, maxConnections和accept-count的關系為:當連接數達到最大值maxConnections后,系統會繼續接收連接,但不會超過acceptCount的值,
1.3.4 應用帶來的壓力
前面我們分析過,NIOEndPoint接收到客戶端請求連接后,會生成一個SocketProcessor任務給到執行緒池去處理,SocketProcessor中的run方法會呼叫HttpProcessor組件去決議應用層的協議,并生成Request物件,最后呼叫Adapter的Service方法,將請求傳遞到容器中,
容器主要負責內部的處理作業,也就是當前置的連接器通過Socket獲取到資訊之后,得到一個Servlet請求,而容器就是負責處理Servlet請求,
Tomcat使用Mapper組件將用戶請求的URL定位到一個具體的Serlvet,然后Spring中的DispatcherServlet攔截到該Servlet請求后,基于Spring本身的Mapper映射定位到我們具體的Controller中,
到了Controller之后,對于我們的業務來說,才是一個請求真正的開始,Controller呼叫Service、Service呼叫dao,完成資料庫操作之后,將請求原路回傳給到客戶端,完成一次整體的會話,也就是說,Controller中的業務邏輯處理耗時,對于整個容器的并發來說也會受到影響,
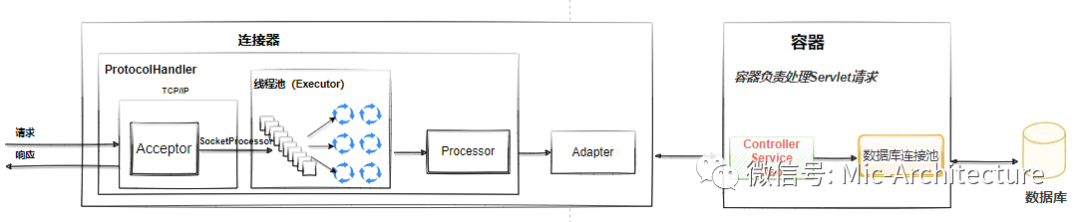
image-20210622151107514
1.4 服務器數量評估
通過上述分析,我們假設一個tomcat節點的QPS=500,如果要支撐到高峰時期的QPS=18000,那么需要40臺服務器,這四臺服務器需要通過Nginx軟體負載均衡,進行請求分發,Nginx的性能很好,官方給的說明是Nginx處理靜態檔案的并發能夠達到5W/s,另外Nginx由于不能單點,我們可以采用LVS對Nginx做負載均衡,LVS(Linux VirtualServer),它是采用IP負載均衡技術實作負載均衡,
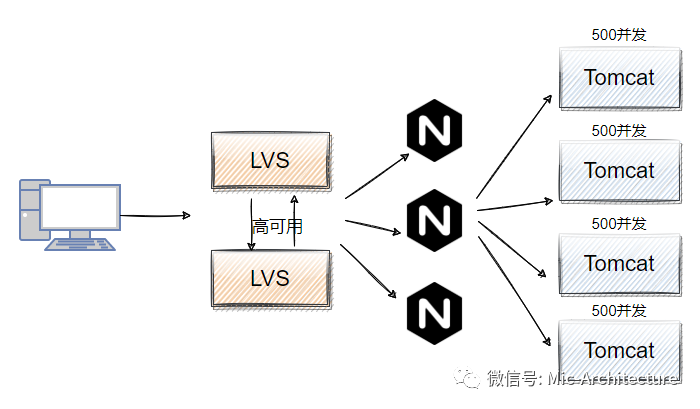
image-20210622220213652
通過這樣的一組架構,我們當前服務端是能夠同時承接QPS=18000,但是還不夠,再回到前面我們說的兩個公式,
?QPS=并發量/平均回應時間?并發量=QPS*平均回應時間
假設我們的RT是3s,那么意味著服務器端的并發數=18000*3=54000,也就是同時有54000個連接打到服務器端,所以服務端需要同時支持的連接數為54000,這個我們在前文說過如何進行配置,如果RT越大,那么意味著堆積的鏈接越多,而這些連接會占用記憶體資源/CPU資源等,容易造成系統崩潰的現象,同時,當鏈接數超過閾值時,后續的請求無法進來,用戶會得到一個請求超時的結果,這顯然不是我們所希望看到的,所以我們必須要縮短RT的值,
推薦閱讀:
我今天也想要凡爾賽一次,原來大廠的面試也沒有想象中的那么難,位元組跳動 3 面+騰訊 6 面,就這么一次性過了
2021 年常見面試真題匯總,含了 14 個技術堆疊,已助我成功拿到騰訊 offer!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/323418.html
標籤:java
上一篇:接私活賺到W了!!!!
下一篇:八大排序演算法(交換排序:冒泡排序與快速排序;選擇排序:簡單選擇排序與堆排序,這四種排序已經完成)與三大查找方法