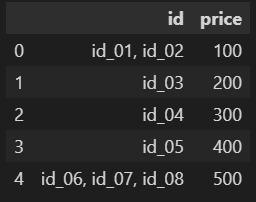
我有一個這樣的資料框架:
我有一個這樣的資料框架。
data = {'id': ['id_01,id_02',
'id_03'。
'id_04'。
'id_05'。
'id_06, id_07, id_08'] 。
'price': [100, 200, 300, 400, 500]}。
df = pd.DataFrame(data)
df
輸出:
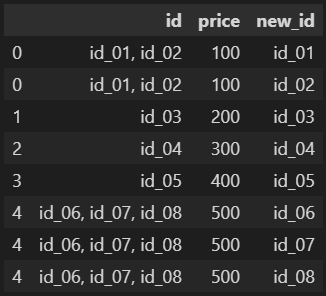
我這樣做是為了拆分每個id,并將每個id作為單行進行分析:
new_df = df.assign(new_id=df.id. str.split(",")).explode('new_id')
新_df
輸出:
到目前為止,很好=)
對于一個初學者,我怎樣才能用最簡單的方法達到這個結果呢?
uj5u.com熱心網友回復:
當你可以通過.str.len()訪問id項的長度時,在你爆炸之前計算一下:
(df.assign(new_id=df.id.str.split(" ,")
.assign(new_price=lambda df: df.price / df.new_id.str.len()
.explode('new_id'))
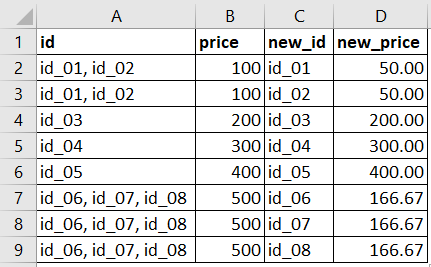
id price new_id new_price
0 id_01, id_02 100 id_01 50.000000[/span].
0 id_01, id_02 100 id_02 50.000000[/span].
1 id_03 200 id_03 200.000000
2 id_04 300 id_04 300.000000
3 id_05 400 id_05 400.000000
4 id_06, id_07, id_08 500 id_06 166.666667
4 id_06, id_07, id_08 500 id_07 166.666667
4 id_06, id_07, id_08 500 id_08 166.666667
uj5u.com熱心網友回復:
另一種方法,在一行中,str.分割成一列,找到新串列的長度,并使用它來動態地找到平均值。比lambda更快。
new_df = (df.assign(new_id=df.id. str.split(","),#new colume。
price=df['price'].div(df.id.str. split(",").str.len())#Find average。
.astype(int)).explode('new_id')#explode以expend the df。
)
輸出
id price new_id
0 id_01, id_02 50 id_01
0 id_01, id_02 50 id_02
1 id_03 200 id_03
2 id_04 300 id_04
3 id_05 400 id_05
4 id_06, id_07, id_08 166 id_06
4 id_06, id_07, id_08 166 id_07
4 id_06, id_07, id_08 166 id_08
uj5u.com熱心網友回復:
可能不是最好的解決方案,但你可以利用爆炸的行具有相同的索引這一事實:
new_df['new_price'] = new_df['price']/new_df. groupby(new_df.index).transform('count') ['id']
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/323855.html
標籤: