詳解優化sql的程序
在我們平時的面試中,如果面試官問起資料庫的問題時,一般都逃不開資料庫引擎的區別和如何優化sql的問題,關于資料庫引擎的區別,我上一篇文章就很詳細的寫了有興趣的可以去學習學習(Mysql引擎之間的區別),下面我們就一起來學習學習如何在面試中關于Sql優化問題與面試官進行對線,
1.很多人面試中,當面試官問起你在實際開發中,你是怎么處理一些sql執行很慢的,很多面試者可能想都不想就說直接加索引,這雖然很籠統的說出了如何優化sql 的一種方式,但是這樣的答案,在面試官看來是不合格的,不出眾的,因為這種回答加索引的,在面試中太多人是這樣回答的,這樣不能讓面試官覺得你是正在懂優化sql 的,因此接下來我們講講怎么樣的回答能夠使得面試官認為你是真正學習過sql優化或者真正在實際開發中使用過msql優化的,
2.sql執行慢總體上有兩種優化方式:一種是軟體層面的優化、另一種是硬體層面的優化
2.1 硬體層面的優化
首先我們先來說說硬體層面優化:
- 配置運行速度更快的CUP
- 把機械硬碟更換成固態硬碟
- 加大運行記憶體
硬體層面優化最主要是上面這幾種方式,
2.2 軟體層面的優化(基于Mysql 8.0及以上)
關于軟體層面的優化,也是本文章的最主要的核心內容,接下來我們將結合我實際開發中用到的案例進行詳細的講解,
2.2.1 我們要拋棄在面試中,面試官一問到如何優化一些慢查詢的時,就不假思索地回答加索引的“陋習”,
當我們實際開發中,我們在執行sql陳述句需要很長的時間時,我們需要對該陳述句進行分析,首先是使用explain命令對sql進行分析,接下來我們以案例進行講解:
即將用到的表結構:
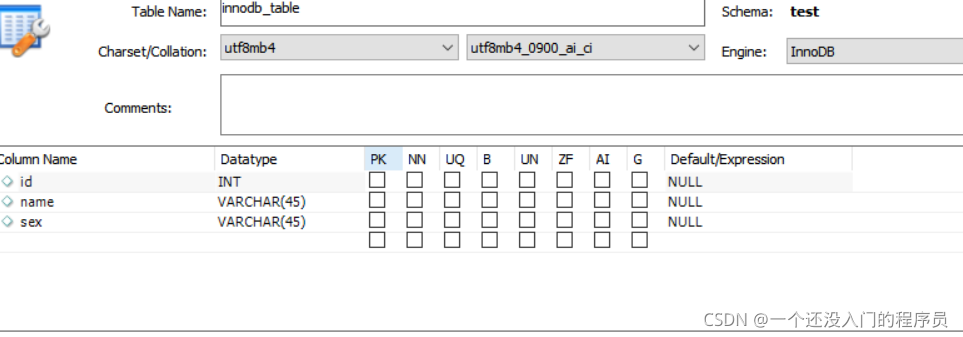
創表陳述句:
CREATE TABLEinnodb_table(idint DEFAULT NULL,namevarchar(45) DEFAULT NULL,sexvarchar(45) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
我創建了以上簡單的資料表,
如何我們執行了一個sql陳述句
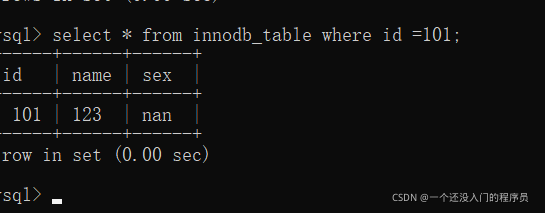
假如執行的時間花了很久,那么我們就要對該陳述句進行分析,分析程序如下:

 然后發現type為all,說明進行了全表掃描,并且在possible_keys和key中都是為null,說明沒有用到索引,其實我們一開始就沒有建立索引,因此我們對該sql的優化是對該表進行加個索引,操作如下:
然后發現type為all,說明進行了全表掃描,并且在possible_keys和key中都是為null,說明沒有用到索引,其實我們一開始就沒有建立索引,因此我們對該sql的優化是對該表進行加個索引,操作如下:
ALTER TABLE `shop`.`innodb_table`
CHANGE COLUMN `id` `id` INT NOT NULL ,
ADD PRIMARY KEY (`id`);
即假如了欄位id的索引,然后我們再次執行explain命令
 發現sql查詢陳述句用到了索引,這樣就能加快了sql的執行的速度,
發現sql查詢陳述句用到了索引,這樣就能加快了sql的執行的速度,
2.2.2 如果上面的查詢陳述句不再是 select * from innodb_table where id =101;,而是變成了select * from innodb_table where name=?時,我們應該怎么優化呢?
執行分析結果很顯然的使用了全表掃描,這是讀到這里的讀者,很清楚的知道要怎么加索引了,對,就是加一個欄位為name 的索引;
alter table `innodb_table` add index name_index(name);
在這里我們能看到兩條命令的分析結果中possible_keys都是name_index,但是第一條的key卻為null,而第二條key卻為name_key,從結果看出,第一條查詢沒有使用到了索引,第二條的索引使用到了索引,這是為什么呢?關于這個的原因,我再文章的后面會進行講解,這里我們還是先探究加索引方式,
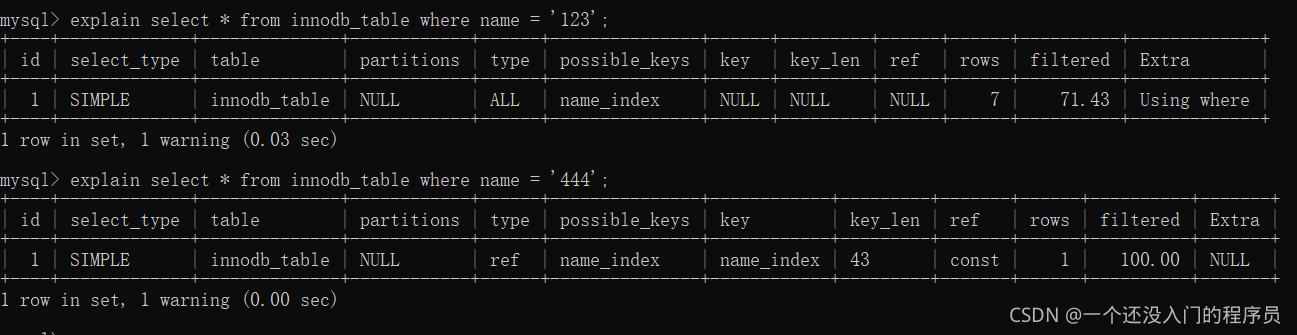 從第二跳的命令中,我們能夠分析出我們加了name欄位索引后,查詢陳述句使用到了我創建的索引了,因此這就是我們對該陳述句的優化方式,
從第二跳的命令中,我們能夠分析出我們加了name欄位索引后,查詢陳述句使用到了我創建的索引了,因此這就是我們對該陳述句的優化方式,
2.2.3 此時我們的需求又發生了變化,變成了 select name,sex from innodb_table where name =‘444’;那我們要怎么優化呢?首先我們先要分析一下該陳述句,結果如下:
 name索引,很多人就會覺得這句sql已經很完美了,不能再優化了,其實不是這樣的,在innodb引擎中,我們建立的普通索引的樹的葉子節點存的是該資料對應的主鍵的值,而不是存了我們需要查的資料,也就是說,當我們使用了普通的索引后,只是查到該資料的主鍵值,然后需要再次回表到主鍵索引的樹中,才能讀取出我們想要的資料,其實我們可以使用聯合索引的覆寫索引的特性去優化該查詢的陳述句的,這樣就可以減少回表的次數:
name索引,很多人就會覺得這句sql已經很完美了,不能再優化了,其實不是這樣的,在innodb引擎中,我們建立的普通索引的樹的葉子節點存的是該資料對應的主鍵的值,而不是存了我們需要查的資料,也就是說,當我們使用了普通的索引后,只是查到該資料的主鍵值,然后需要再次回表到主鍵索引的樹中,才能讀取出我們想要的資料,其實我們可以使用聯合索引的覆寫索引的特性去優化該查詢的陳述句的,這樣就可以減少回表的次數:
非主鍵索引樹的結構:
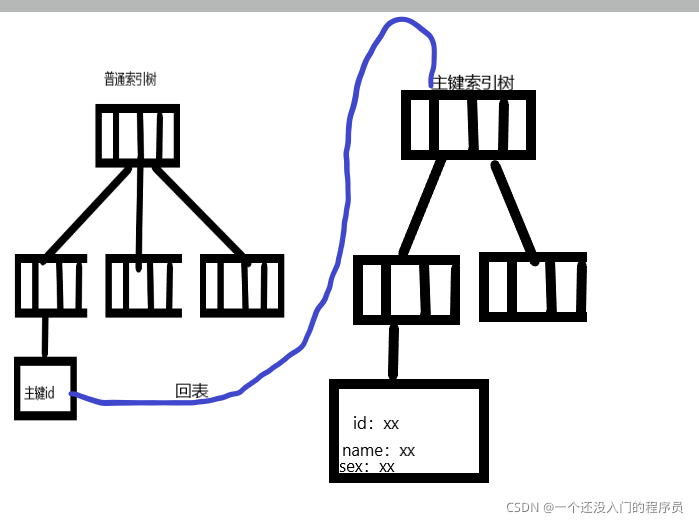
聯合索引樹的結構:
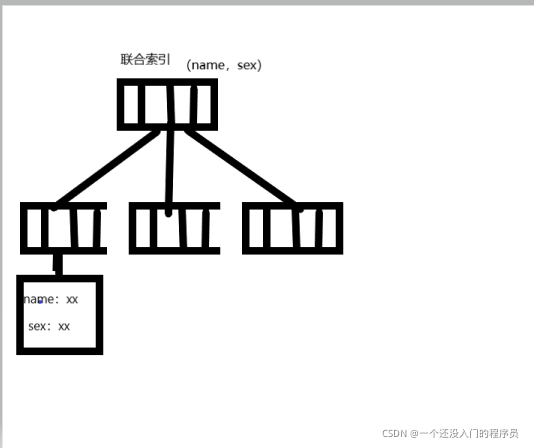
因此從上面的索引樹結構中,我們發現如果我們創建(name,sex)聯合索引,那么就可以省去回表的步驟,這也能加快sql執行速度,
alter table `innodb_table` add index name_sex_index(name,sex);
執行結果:
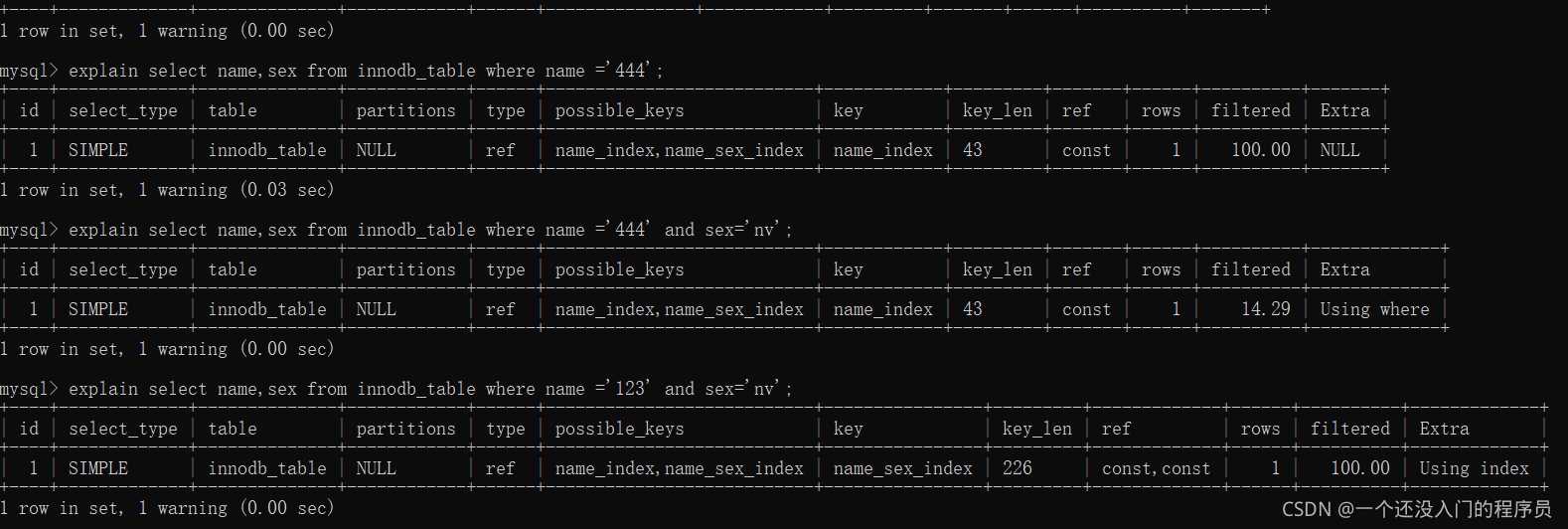
很顯然三條命令中,只有第三條使用到了我們創建的索引,這和2.2.2中出現的問題,我們先不進行探究,但是這樣的聯合索引的優化可以提高查詢的效率,
2.2.4 如果通過上面的方式,sql優化的效果還是不明顯,那我們就需要考慮是不是表中的資料真的太大了,那就需要進行分庫分表了,分庫分表可以分為垂直分和水平分,根據自身的業務進行分,
2.2.5 接下來我們就來說說為什么我們建立了索引,而sql在最后執行的時候沒有用到呢?
Mysql可以分為幾個部分:連接器、分析器、優化器、執行器、引擎,
選擇哪個索引的作業是優化器復制的,而優化器選擇索引的目的,是找到一個最優的執行方案,并用最小的代價去執行陳述句,在資料庫里面,掃描行數是影響執行代價的因素之一,掃描的行數越少,意味著訪問磁盤資料的次數越少,消耗的CPU資源越少,
在mysql執行sql之前,優化器是不能精確的知道滿足條件有多少行的,只能通過之前統計的資訊來預估有多少行,因此這一步就有可能使得索引選擇時與我們預想的結果不一樣,
這個統計資訊就是索引的“區分度”,顯然,一個索引上不同的值越多,這個索引的區分度就越好,而一個索引上不同的值的個數,我們稱之為“基數”,也就是說,這個基數越大,索引的區分度越好,
我們可以使用show index方法,看到一個索引的基數
(注意:Cardinality就是我們上面所說的基數)
 通過show index發現我們創建索引的區分度(基數)都不是很大,所以這就導致了優化器選擇索引時就會出錯,如果我們真的需要mysql按照我們預想的使用索引,我們就可以通過強制索引的方式就行優化了,
通過show index發現我們創建索引的區分度(基數)都不是很大,所以這就導致了優化器選擇索引時就會出錯,如果我們真的需要mysql按照我們預想的使用索引,我們就可以通過強制索引的方式就行優化了,
例如:
select name,sex from innodb_table force(name_sex_index) where name ='444' and sex='nv';
結果如下:
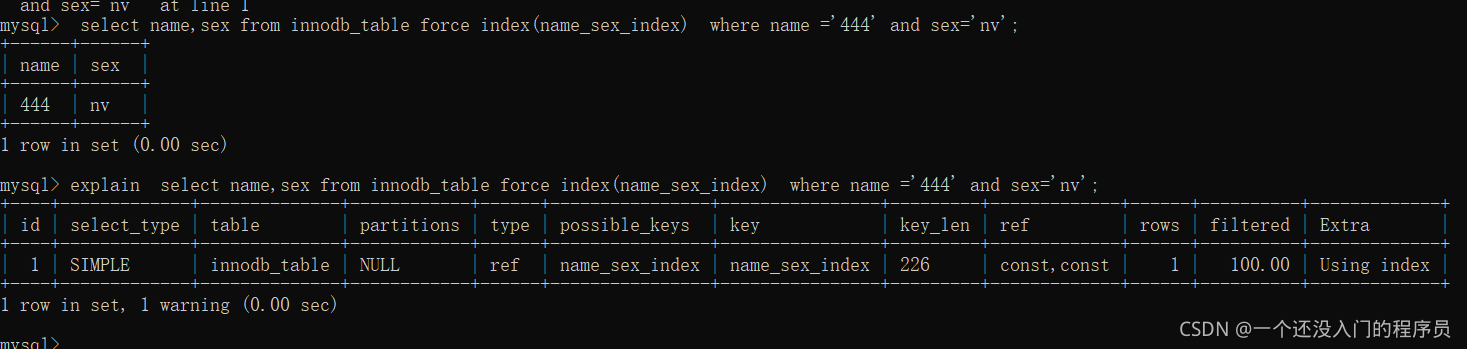 不過我們在開發中一般不會使用強制索引的方式,因為優化器選錯索引的情況是很少發生的,而且這樣寫的話,索引改名字了,sql陳述句就需要改;還有就是比如還資料庫了,不同資料庫強制索引的方式不一樣,因此不建議開發中使用,
不過我們在開發中一般不會使用強制索引的方式,因為優化器選錯索引的情況是很少發生的,而且這樣寫的話,索引改名字了,sql陳述句就需要改;還有就是比如還資料庫了,不同資料庫強制索引的方式不一樣,因此不建議開發中使用,
本期就先講到這,下期我們講講如何優化我們進行插入操作時比較慢的方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/325571.html
標籤:java
上一篇:??答應粉絲的Maven倉庫學習筆記,今天它來了!一起來學習快速入門Maven??
下一篇:2017 課程筆記