的參考fmt_number()說可以使用運算式選擇行:
行
要格式化的可選行。在格式化列中的所有行中提供
everything()(默認值)或TRUE結果。可以是 中提供的行標題c()向量、行索引向量或專注于選擇的輔助函式。選擇輔助功能有:starts_with(),ends_with(),contains(),matches(),one_of(),num_range(),和everything()。我們還可以使用運算式過濾到我們需要的行(例如,[colname_1] > 100 & [colname_2] < 50)。
但是,我還沒有找到如何使這項作業。我嘗試了以下操作(這只是一個說明;這些數字轉換在此資料集中沒有意義):
library(gt)
library(tidyverse)
df = starwars
gt_tb = gt(df) %>%
fmt_number(
rows = [birth_year] > 20,
pattern = '({x})'
)
gt_tb = gt(df) %>%
fmt_number(
columns = mass,
rows = [birth_year] > 20,
pattern = '({x})'
)
gt_tb = gt(df) %>%
fmt_number(
columns = mass,
rows = expression([birth_year] > 20),
pattern = '({x})'
)
gt_tb = gt(df) %>%
fmt_number(
columns = mass,
rows = df[birth_year] > 20,
pattern = '({x})'
)
gt_tb = gt(df) %>%
fmt_number(
columns = mass,
rows = everything([birth_year] > 20),
pattern = '({x})'
)
還嘗試了他們參考的等價物。
這個包很新,對不起,如果我錯過了一些明顯的東西!
uj5u.com熱心網友回復:
您還必須指定columns:
df %>%
gt() %>%
fmt_number(
columns = where(is.numeric),
rows = birth_year > 20,
pattern = '({x})'
)
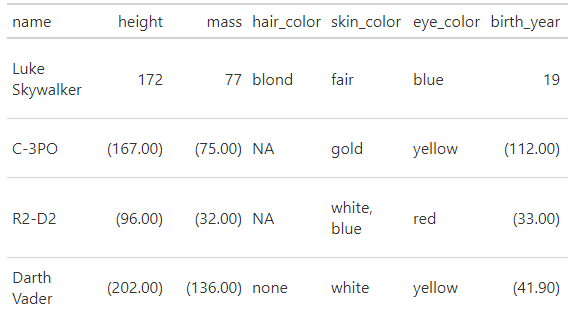
這給了我們(作為螢屏截圖/示例):
uj5u.com熱心網友回復:
我們還可以使用運算式過濾到我們需要的行(例如,[colname_1] > 100 & [colname_2] < 50)。
該示例使用方括號 ( []) 來告訴您這些是占位符,這不是有效的語法。
在你的情況下,它會是
fmt_number(
columns = mass,
rows = birth_year > 20,
pattern = '({x})'
)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/325688.html
上一篇:將列添加到R中的tibble-獲取“is.data.frame(.data)中的錯誤:缺少引數“.data”,沒有默認值”