如圖所示,表示發起一個請求時,涉及到資料庫的相關操作,在前面的文章中我們說過,如果服務端要提升整體的吞吐量,就必須要減少每一次請求的處理時長,那么在當前這個場景中,資料庫層面哪些因素會影響到性能呢?
池化技術,減少頻繁創建資料庫連接
遇到這樣的問題,解決辦法就是順著當前整體的邏輯去思考,首先,應用要和資料庫打交道,必然會設計到資料庫鏈接的建立,然后在當前連接中完成資料庫的相關操作,最后再關閉連接,
在這種場景下,客戶端每次發起請求,都需要重新建立連接,如果頻繁的創建連接是否會影響到性能呢?答案是一定的,我們通過下面這樣一個方式來驗證一下
# -i指定網卡名稱
tcpdump -i eth0 -nn -tttt port 3306
當我們向資料庫發起一次連接時,上述抓包命令會列印連接的相關資訊如下,(通過Navicat 的鏈接測驗工具測驗)
關注前面8行資料即可,
2021-06-24 23:15:50.130812 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [S], seq 759743325, win 64240, options [mss 1448,nop,wscale 8,nop,nop,sackOK], length 0
2021-06-24 23:15:50.130901 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [S.], seq 3058334924, ack 759743326, win 29200, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0
2021-06-24 23:15:50.160730 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [.], ack 1, win 260, length 0
2021-06-24 23:15:50.161037 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [P.], seq 1:79, ack 1, win 229, length 78
2021-06-24 23:15:50.190126 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [P.], seq 1:63, ack 79, win 259, length 62
2021-06-24 23:15:50.190193 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [.], ack 63, win 229, length 0
2021-06-24 23:15:50.190306 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [P.], seq 79:90, ack 63, win 229, length 11
2021-06-24 23:15:50.219256 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [P.], seq 63:82, ack 90, win 259, length 19
2021-06-24 23:15:50.219412 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [P.], seq 90:101, ack 82, win 229, length 11
2021-06-24 23:15:50.288721 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [.], ack 101, win 259, length 0
-
第一部分是TCP三次握手建立連接的資料包
- 第一個資料包是客戶端向服務區段發送一個SYN包
- 第二個資料包是服務端回傳給客戶端的ACK包以及一個SYN包
- 第三個資料包是客戶端回傳給服務端的ACK包
-
第二個部分是Mysql服務端校驗客戶端密碼的程序
從開始建立連接的時間130812到最終完成連接288721, 總共耗時157909,接近158ms時間,這個時間看起來很小,而且在請求量較小的情況下,對系統的影響不是很大,但是請求量上來之后,這個請求耗時的影響就非常大了,
而對于這個問題的解決辦法大家都已經知道,就是利用池化技術,預先建立好資料庫連接,當應用需要使用連接時,直接從預先建立好的連接中來獲取進行呼叫,如圖2-2所示,
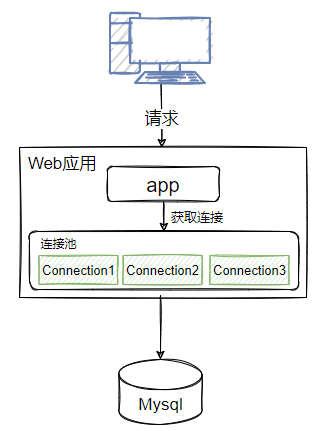
資料庫連接池的作業原理和執行緒池類似,資料庫連接池有兩個最重要的配置: 最小連接數和最大連接數, 它們控制著從連接池中獲取連接的流程:
- 如果當前連接數小于最小連接數,則創建新的連接處理資料庫請求;
- 如果連接池中有空閑連接則復用空閑連接;
- 如果空閑池中沒有連接并且當前連接數小于最大連接數,則創建新的連接處理請求;
- 如果當前連接數已經大于等于最大連接數,則按照配置中設定的時間(maxWait)等待舊的連接可用;
- 如果等待超過了這個設定時間則向用戶拋出錯誤,
總的來說,連接池核心思想是空間換時間,期望使用預先創建好的物件來減少頻繁創建物件的性能開銷,同時還可以對物件進行統一的管理,降低了物件的使用的成本,
資料庫本身的性能優化
資料庫本身的性能優化也很重要,常見的優化手段
- 創建并正確使用索引,盡量只通過索引訪問資料
- 優化SQL執行計劃,SQL執行計劃是關系型資料庫最核心的技術之一,它表示SQL執行時的資料訪問演算法,優化執行計劃也就能夠提升sql查詢的性能
- 每次資料互動時,盡可能回傳更少的資料,因為更大的資料意味著會增大網路通信延遲,常見的方式是通過分頁來查詢資料、只回傳當前場景需要的欄位
- 減少和資料庫的互動次數,比如批量提交、批量查詢
- ...
資料庫讀寫操作的性能問題
如果老板說公司準備在下個月搞一場運營活動,用戶數量會快速增加,導致對資料庫的讀壓力增加,假設在4 核 8G 的機器上運 MySQL 5.7 時,大概可以支撐 500 的 TPS 和 10000 的 QPS,而實際的QPS可能是10W,那怎么解決呢?
首先分析一下這個問題,在絕大部分面向用戶的系統中,都是讀多寫少的模型,比如電商,大部分的時候是在搜索和瀏覽,比如抖音,大部分是在加載短視頻,所以我們需要考慮的問題是,資料庫如何扛住查詢請求,一般的解決方法是讀寫分離,
所謂讀寫分離,就是把同一個資料庫分離成兩份,一份專門用來做事務操作,另一份專門用來做讀操作,如圖2-3所示,
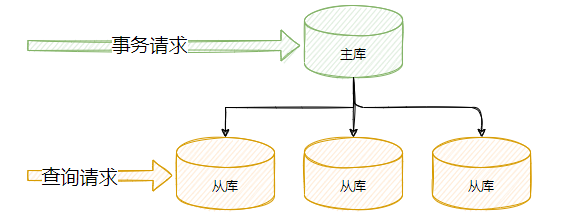
做了主從復制之后,我們就可以在寫入時只寫主庫,在讀資料時只讀從庫,這樣即使寫請求會鎖表或者鎖記錄,也不會影響到讀請求的執行,同時呢,在讀流量比較大的情況下,我們可以部署多個從庫共同承擔讀流量,這就是所說的 一主多從 部署方式,在你的垂直電商專案中就可以通過這種方式來抵御較高的并發讀流量,另外,從庫也可以當成一個備庫來使用,以避免主庫故障導致資料丟失,
那么你可能會說,是不是我無限制地增加從庫的數量就可以抵抗大量的并發呢? 實際上并不是的,因為隨著從庫數量增加,從庫連接上來的 IO 執行緒比較多,主庫也需要創建同樣多的 log dump 執行緒來處理復制的請求,對于主庫資源消耗比較高,同時受限于主庫的網路帶寬,所以在實際使用中,一般一個主庫最多掛 3~5 個從庫,
當然,主從復制也有一些缺陷, 除了帶來了部署上的復雜度,還有就是會帶來一定的主從同步的延遲,這種延遲有時候會對業務產生一定的影響
資料量增加帶來的性能問題
隨著業務的增長,資料庫中的資料量也會隨著增加,由于最早開發時主要是為了趕進度,資料都是單表存盤,因此單表資料量增加之后,導致資料庫的查詢和寫入都造成非常大的性能開銷,具體體現在,
- 單表資料量過大,千萬級別到上億級別,這時即使你使用了索引,索引占用的空間也隨著資料量的增長而增大,資料庫就無法快取全量的索引資訊,那么就需要從磁盤上讀取索引資料,就會影響到查詢的性能,
- 資料量的增加也占據了磁盤的空間,資料庫在備份和恢復的時間變長
- 不同模塊的資料,比如用戶資料和用戶關系資料,全都存盤在一個主庫中,一旦主庫發生故障,所有的模塊兒都會受到影響
- 在 4 核 8G 的云服務器上對 MySQL5.7 做 Benchmark,大概可以支撐 500TPS 和 10000QPS,你可以看到資料庫對于寫入性能要弱于資料查詢的能力,那么隨著系統寫入請求量的增長,對于寫請求的耗時也會增加(更新資料操作需要同步更新索引,資料量較大的情況下更新索引耗時較長)
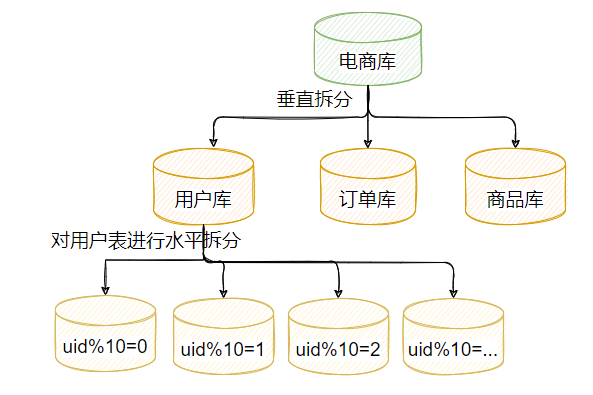
在這類場景中,解決方案就是對資料進行分片,也就是分庫分表的機制,如圖2-4所示,資料拆分的核心降低單表和單庫的資料IO壓力,從而提升對資料庫相關操作的性能,
不同存盤設備帶來的性能提升
前面我們了解了對于傳統關系型資料庫的一些優化思路,整體來說,通過優化之后能夠提升程式訪問資料庫的計算性能,但是還是有一些情況,即便是優化之后,使用傳統關系型資料庫無法解決的,比如,
- 當資料量達到TB級別時,傳統關系型資料庫基本做了分庫分表,單表資料量也是非常大的,
- 對于一些不適合用關系型資料庫存盤的資料,傳統資料庫無法做到,所以資料庫本身的特性限制了多樣性資料的管理,
所以nosql出現了,大家對nosql這個概念已經不陌生了,它是指不同于傳統關系型資料庫的其他資料庫系統的一個統稱,它不使用SQL作為查詢語言,并且相對于傳統關系型資料庫來說,
它提供了更高的性能以及橫向擴展能力,非常適合互聯網專案中高并發且資料量較大的場景中,如圖25所示,表示目前比較主流的不同型別的nosql資料庫,

這個網站上記錄了所有的Nosql框架
https://hostingdata.co.uk/nosql-database/
Key-Value資料庫
key-value資料庫,典型的代表就是Redis、Memcached,也是目前業內非常主流的Nosq資料庫,
之所以在IO性能方面比傳統關系型資料庫高,有兩個點
- 資料基于記憶體,讀寫效率高
- KV型資料,時間復雜度為O(1),查詢速度快
KV型NoSql最大的優點就是高性能,利用Redis自帶的BenchMark做基準測驗,TPS可達達到接近10W的級別,性能非常強勁,同樣的Redis也有所有KV型NoSql都有的比較明顯的缺點:
- 查詢方式單一,只有KV的方式,不支持條件查詢,多條件查詢唯一的做法就是資料冗余,但這會極大的浪費存盤空間
- 記憶體是有限的,無法支持海量資料存盤
- 同樣的,由于KV型NoSql的存盤是基于記憶體的,會有丟失資料的風險
基于Key-Value資料庫的特性,這類資料庫比較適用于快取的場景,
- 讀多寫少
- 讀取能力強
- 可以接受資料丟失
這類存盤相比于傳統的資料庫的優勢是極高的讀寫性能,一般對性能有比較高的要求的場景會使用,主要使用場景,
- 用來做分布式快取,提升程式處理效率,
- 用來做會話資料存盤
- 其他功能性特性,比如訊息通信、分布式鎖、布隆過濾器
- 微博的feed流,早期就是用了redis實作,(持續更新并呈現給用戶內容的資訊流,每個人的朋友圈,微博關注頁等等都是一個 Feed 流)
列式資料庫
我們最早學習資料庫,都是基于以二維表形式存盤,每一行代表一條完整的資料,大部分傳統的關系型資料庫中,都是以行來存盤資料,不過最近幾年,列式存盤也逐步被廣泛運用在大資料框架中,
行存盤和列存盤,是資料庫底層資料組織的形式的區別,如圖2-6所示,資料庫表中所有列一次排成一行,以行位單位存盤,再配合B+樹或者SS-Table作為索引,就能快速通過主鍵找到相應的行資料,
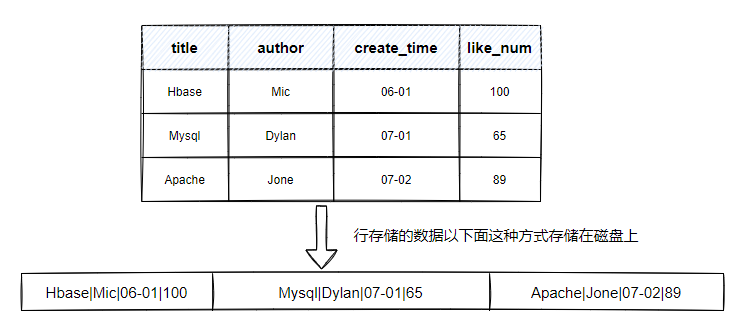
在實際應用中,大部分的操作都是以物體(Entity)為單位,也就是大部分CRUD操作都是針對一整行記錄,如果需要保存一行資料,只需要在原來的資料后追加一行資料即可,所以資料的寫入非常快,
但是對于查詢來說,一個典型的查詢操作需要遍歷整個表,分組、排序、聚合等,對于行存盤來說,這樣的操作的優勢就不存在了,更慘的是,分析型SQL可能不需要用到所有的列,僅僅只需要對某些列進行運算即可,但是那一行中和本次操作無關的列也必須要參與到資料掃描中,
比如,如圖2-7所示,現在我想統計所有文章的總的點贊數量,作為行存盤的系統,資料庫會怎么操作呢?
- 首先需要把所有行的資料加載到記憶體
- 然后對like_num列做sum操作
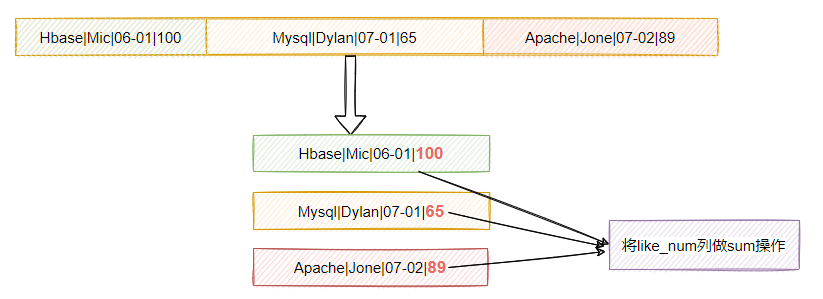
行式存盤對于OLAP場景而言,優勢就不存在了,所以就引入了列式存盤,
OLTP(on-line transaction processing)翻譯為聯機事務處理, OLAP(On-Line Analytical Processing)翻譯為聯機分析處理,從字面上來看OLTP是做事務處理,OLAP是做分析處理,從對資料庫操作來看,OLTP主要是對資料的增刪改,OLAP是對資料的查詢
如圖2-8所示,列式存盤是將每一列資料組織在一起,它方便對于列的操作,比如前面說的統計like_num之和,按列存盤之后只需要一次磁盤操作就可以完成三個資料的匯總,所以非常適合OLAP的場景,
- 當查詢陳述句只涉及部分列時,只需要掃描相關列
- 每一列資料都是相同型別,彼此間的關聯性更大,對列資料壓縮的效率較高,
但是對于OLTP來說不是很友好,因為一行資料的寫入需要修改多個列,

列式存盤在大資料分析中使用非常多,比如推薦畫像(螞蟻金服的風控)、是空資料(滴滴打車的歸集資料)、訊息/訂單(電信領域、銀行領域)不少訂單查詢底層的存盤, Feeds流(朋友圈類似的應用)等等,
檔案型資料庫
傳統的資料庫,所有資訊會被分割成離散的資料欄位,保存在關系型資料庫中,甚至對于一些復雜的場景,還會分散在不同的表結構中,
舉個例子,在一個技術論壇中,假設對于用戶、文章、文章評論表的關系圖如圖2-10所示,
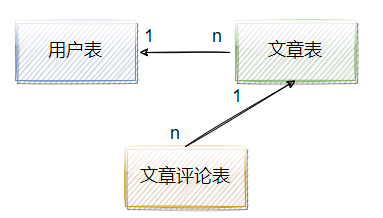
那用戶點一篇文章,里面要顯示該文章的創建者、文章詳情、文章的評論,那么服務端要做什么呢?
- 查找文章詳情
- 根據文章中的uid查找用戶資訊
- 查詢該文章的所有評論串列
- 查詢每個評論的創建者名字
這個程序要么就是多次資料庫查詢,要么就是使用一個復雜關聯查詢來檢索,不管怎么做,都不是很方便,而檔案資料庫就可以解決這樣的問題,
檔案資料庫是以檔案單位,具體的檔案形式有很多種,比如(XML、YAML、JSON、BSON)等,檔案中存盤具體的欄位和值,應用可以使用這些欄位進行查詢和資料篩選,
一般情況下,檔案中包含了物體中的全部資料,比如圖2-10的結構,我們可以直接把一篇文章的基本要素資訊構建成一個完整的檔案保存到檔案資料庫中,應用程式只需要發起一次請求就可以獲取所有資料,b
Article:{
Creator:{
uid: '',
username: ''
},
Topic: {
title: '',
content: ''
},
Reply: [
{
replyId:,
content:''
},
{
replyId:,
content:''
}
]
}
MongoDB是目前最流行的Nosql資料庫,它是一種面向集合、與模式(Schema Free)無關的檔案型資料庫,它的資料是以“集合”的方式進行分組,每個集合都有單獨的名稱并可以包含無線數量的檔案,這種集合與關系型資料庫中的表類似,唯一的區別就是它并沒有任何明確的schema,
在資料庫中,schema(發音 “skee-muh” 或者“skee-mah”,中文叫模式)是資料庫的組織和結構,schemas 和schemata都可以作為復數形式,模式中包含了schema物件,可以是表(table)、列(column)、資料型別(data type)、視圖(view)、存盤程序(stored procedures)、關系(relationships)、主鍵(primary key)、外鍵(foreign key)等,資料庫模式可以用一個可視化的圖來表示,它顯示了資料庫物件及其相互之間的關系
如圖2-11所示, 將資料存盤在類似 JSON 的靈活檔案中,這意味著欄位可能因具體檔案而異,并且資料結構可能隨著時間的推移而變化,

MongoDB沒有“資料一致性檢查”、“事務”等,不適合存盤對資料事務要求較高的場景,只適合放一些非關鍵性資料,常見應用場景如下:
- 使用Mongodb對應用日志進行記錄
- 存盤監控資料,比如應用的埋點資訊,可以直接上報存盤到mongoDB中
- MongoDB可以用來實作O2O快遞應用,比如快遞騎手、快遞商家的資訊存盤在MongoDB,然后通過MongoDB的地理位置查詢,方便用來查詢附近的商家、騎手等功能,
圖形資料庫
圖形資料庫,表示以資料結構“圖”作為存盤的資料庫,
圖形資料存盤管理兩類資訊:節點資訊和邊緣資訊, 節點表示物體,邊緣表示這些物體之間的關系, 節點和邊緣都可以包含一些屬性用于提供有關該節點或邊緣的資訊(類似于表中的列),
邊緣還可以包含一個方向用于指示關系的性質,
圖形資料存盤的用途是讓應用程式有效執行需遍歷節點和邊緣網路的查詢,以及分析物體之間的關系, 如圖2-12所示,顯示了已結構化為圖形的組織人員資料,
物體為員工和部門,邊緣指示隸屬關系以及員工所在的部門, 在此圖中,邊緣上的箭頭表示關系的方向,
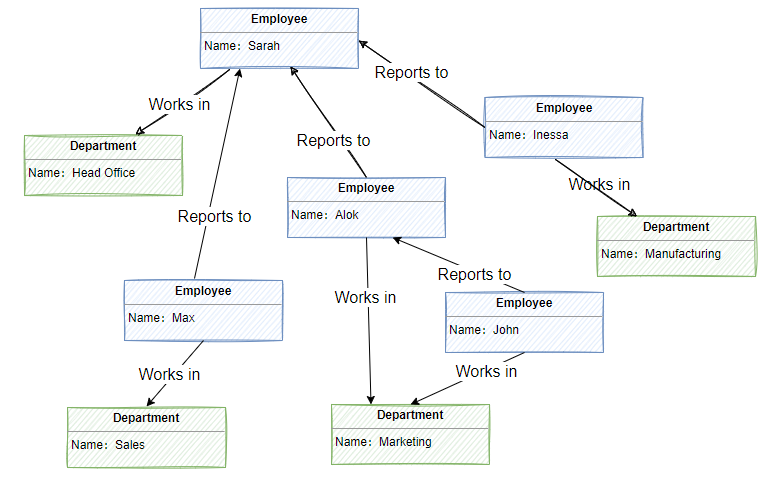
使用此結構可以簡單直接地執行類似于“查找 Sarah 的直接或間接下屬”或“誰與 John 在同一個部門作業?”的查詢, 對于包含大量物體和關系的大型圖形,可以快速執行復雜的分析, 多個圖形資料庫提供一種可用于高效遍歷關系網路的查詢語言,比如:關系、地圖、網路拓撲、交通路線等場景,
NewSql
NewSql也是最近幾年出來的概念,想必大家或多或少都有聽過,NewSql是Nosql發展之后的下一代資料存盤方案,
前面我們了解了Nosql的優勢,
- 高可用性和可擴展性,自動磁區,輕松擴展
- 不保證強一致性,性能大幅提升
- 沒有關系模型的限制,極其靈活
但是有些優勢在某些場景下不是很適合,比如不保證強一致性,對于普通應用來說沒有問題,但是對于一些金融級的企業應用來說,
強一致的需求會比較高,另外,Nosql不支持SQL陳述句,不同的Nosql資料庫都是有自己獨立的API來進行資料操作,相對來說比較麻煩和復雜,
所以NewSql出現了,簡單來說,newSQL 就是在傳統關系型資料庫上集成了 noSQL 強大的可擴展性,傳統的SQL架構設計基因中是沒有分布式的,而 newSQL 生于云時代,天生就是分布式架構,
NewSQL 的主要特性:
- SQL 支持,支持復雜查詢和大資料分析,
- 支持 ACID 事務,支持隔離級別,
- 彈性伸縮,擴容縮容對于業務層完全透明,
- 高可用,自動容災
商用NewSql
-
Spanner、F1:谷歌
-
OceanBase:阿里
-
TDSQL:騰訊
-
UDDB:UCloud
總結
在 NoSQL 資料庫剛剛被應用時,它被認為是可以替代關系型資料庫的銀彈,在我看來,也許因為以下幾個方面的原因:
- 彌補了傳統資料庫在性能方面的不足;
- 資料庫變更方便,不需要更改原先的資料結構;
- 適合互聯網專案常見的大資料量的場景;
不過,這種看法是個誤區,因為慢慢地我們發現在業務開發的場景下還是需要利用 SQL 陳述句的強大的查詢功能以及傳統資料庫事務和靈活的索引等功能,NoSQL 只能作為一些場景的補充,
使用Redis優化性能問題
Redis是目前用得非常多的一種Key-Vlaue資料庫,我們先來通過一個壓測資料了解一下redis和mysql的性能差距,
演示專案: springboot-redis-example
通過jmeter工具分別壓測這個專案中的兩個url,
- http://localhost:8080/city/{id}
- http://localhost:8080/city/redis/{id}
其中,基于mysql訪問的介面,吞吐量資料如下,qps=4735/s,

基于redis的壓測資料,如圖2-14所示,

可以很明顯的看到,在同樣的程式中,Redis的QPS要比Mysql的多了1000,
了解Redis
08年的時候有一個意大利西西里島的小伙子,筆名antirez(http://invece.org/),創建了一個訪客資訊網站LLOOGG.COM,如果有自己做過網站的同學應該知道,
有的時候我們需要知道網站的訪問情況,比如訪客的IP、作業系統、瀏覽器、使用的搜索關鍵詞、所在地區、訪問的網頁地址等等,在國內,有很多網站提供了這個功能,比如CNZZ,百度統計,國外也有谷歌的Google Analytics,
也就是說,我們不用自己寫代碼去實作這個功能,只需要在全域的footer里面嵌入一段JS代碼就行了,當頁面被訪問的時候,就會自動把訪客的資訊發送到這些網站統計的服務器,然后我們登錄后臺就可以查看資料了,
LLOOGG.COM提供的就是這種功能,它可以查看最多10000條的最新瀏覽記錄,這樣的話,它需要為每一個網站創建一個串列(List),不同網站的訪問記錄進入到不同的串列,如果串列的長度超過了用戶指定的長度,它需要把最早的記錄洗掉(先進先出),
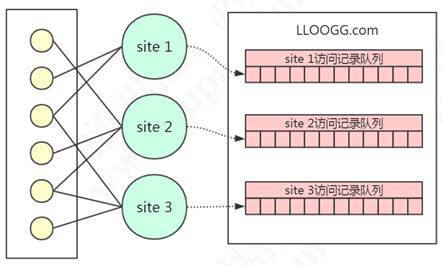
當LLOOGG.COM的用戶越來越多的時候,它需要維護的串列數量也越來越多,這種記錄最新的請求和洗掉最早的請求的操作也越來越多,LLOOGG.COM最初使用的資料庫是MySQL,可想而知,因為每一次記錄和洗掉都要讀寫磁盤,因為資料量和并發量太大,在這種情況下無論怎么去優化資料庫都不管用了,
考慮到最終限制資料庫性能的瓶頸在于磁盤,所以antirez打算放棄磁盤,自己去實作一個具有串列結構的資料庫的原型,把資料放在記憶體而不是磁盤,這樣可以大大地提升串列的push和pop的效率,antirez發現這種思路確實能解決這個問題,所以用C語言重寫了這個記憶體資料庫,并且加上了持久化的功能,09年,Redis橫空出世了,從最開始只支持串列的資料庫,到現在支持多種資料型別,并且提供了一系列的高級特性,Redis已經成為一個在全世界被廣泛使用的開源專案,
為什么叫REDIS呢?它的全稱是Remote Dictionary Service,直接翻譯過來是遠程字典服務,
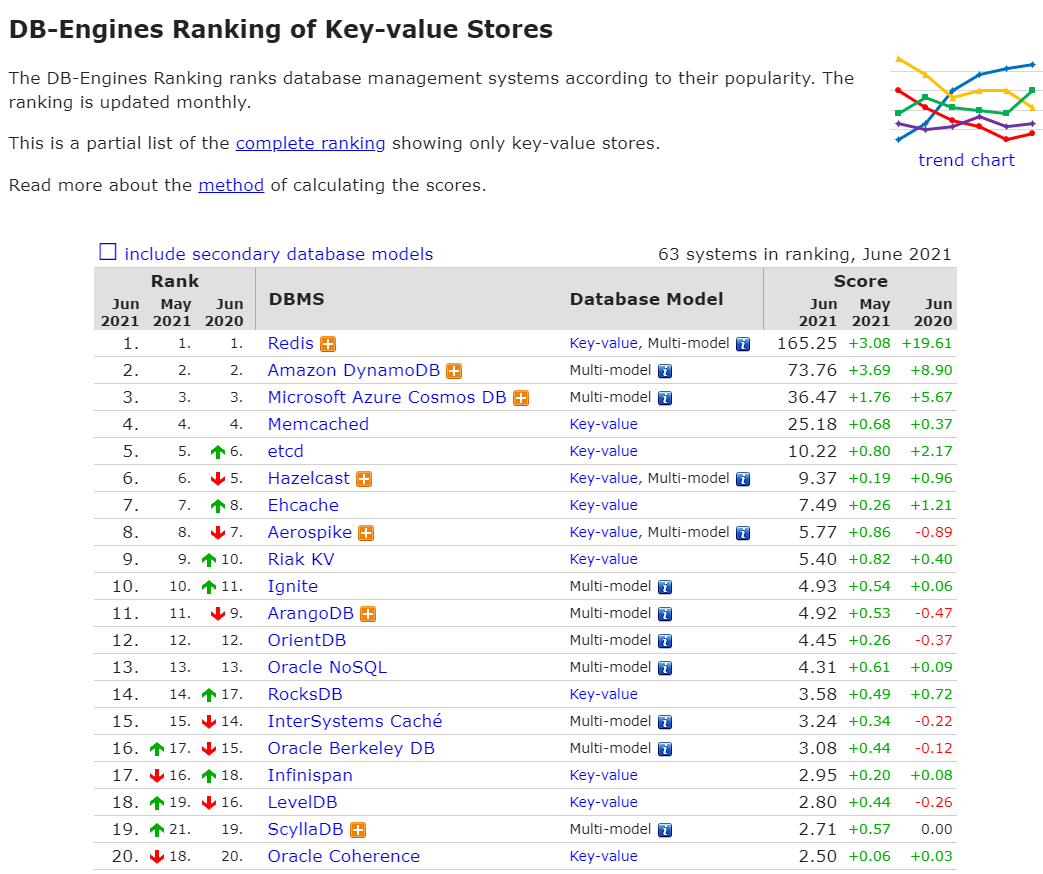
key-value資料庫使用排名
對于Redis,我們大部分時候的認識是一個快取的組件,當然從它的發展歷史我們也可以看到,它最開始并不是作為快取使用的,只是在很多的互聯網應用里面,它作為快取發揮了最大的作用,所以下面我們來聊一下,Redis的主要特性有哪些,我們為什么要使用它作為資料庫的快取,
大家對于快取應該不陌生,比如我們有硬體層面的CPU的快取,瀏覽器的快取,手機的應用也有快取,我們把資料快取起來的原因就是從原始位置取資料的代價太大了,放在一個臨時存盤起來,取回就可以快一些,
如果要了解Redis的特性,我們必須回答幾個問題:
1、為什么要把資料放在記憶體中?
-
記憶體的速度更快,10w QPS
-
減少計算的時間
2、如果是用記憶體的資料結構作為快取,為什么不用HashMap或者Memcache?
-
更豐富的資料型別
-
行程內與跨行程;單機與分布式
-
功能豐富:持久化機制、過期策略
-
支持多種編程語言
-
高可用,集群
https://db-engines.com/en/ranking/key-value+store
關注[跟著Mic學架構]公眾號,獲取更多精品原創

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/327741.html
標籤:Java
下一篇:簡單談談Java泛型