知識點
1.爬蟲基本步驟
2.requests模塊
3.parsel模塊
4.xpath資料決議方法
5.分頁功能
爬蟲基本步驟:
1.獲取網頁地址 (糗事百科的段子的地址)
2.發送請求
3.資料決議
4.保存 本地
對于本篇文章有疑問的同學可以加【資料白嫖、解答交流群:1039649593】
爬蟲代碼
匯入所需模塊
import re import requests import parsel
1.獲取網頁地址
url = 'https://www.qiushibaike.com/text/' # 請求頭 偽裝客戶端向服務器發送請求 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36' }
2.發送請求
requ = requests.get(url=url, headers=headers).text
3.資料決議
sel = parsel.Selector(requ) # 決議物件 <Selector xpath=None data='https://www.cnblogs.com/qshhl/p/'//body/div/div/div[2]/div/a[1]/@href').getall() for html in href: txt_href = 'https://www.qiushibaike.com' + html requ2 = requests.get(url=txt_href, headers=headers).text sel2 = parsel.Selector(requ2) title = sel2.xpath('//body/div[2]/div/div[2]/h1/text()').get().strip() title = re.sub(r'[|/\:?<>*]','_',title) # content = sel2.xpath('//div[@]/text()').getall() content = sel2.xpath('//body/div[2]/div/div[2]/div[2]/div[1]/div/text()').getall() contents = '\n'.join(content)
4.保存資料
with open('糗事百科text\\'+title + '.txt', mode='w', encoding='utf-8') as fp: fp.write(contents) print(title, '下載成功')
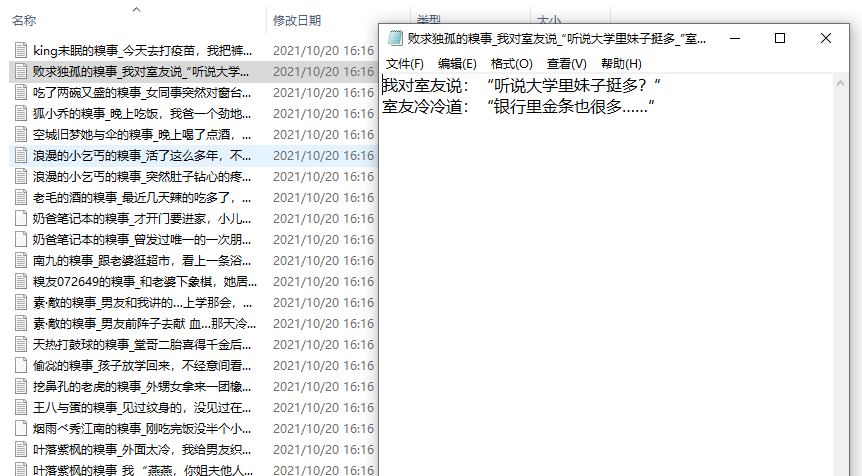
運行代碼,得到資料

【付費VIP完整版】只要看了就能學會的教程,80集Python基礎入門視頻教學
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/327763.html
標籤:Python