目錄
庖丁解牛術法總綱
第一重境界:所見莫非全牛者
1、概述:
2、Set集合特點:
3、分類(實作子類):
4、所有已知實作類:
5、注意事項
6、所有方法
第二重境界:未嘗見全牛也
HashSet
1、HashSet特點:
2、HashSet集合添加一個元素的程序:
3、代碼演示
4、注意事項(特殊之處,遍歷無序的原因不是排序的無序,而是底層哈希值的存放地址的原因)
5、LinkedHashSet集合概述和特點
TreeSet
1、TreeSet集合特點
2、注意事項
3、代碼展示(比較器排序)
第三重境界:官知止而神欲行
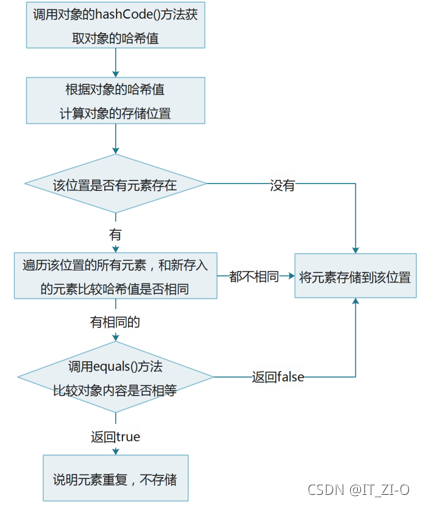
1、哈希值(hashCode)
概念:
特點:
代碼展示:
2、哈希表
概念:
哈希表的實作:
哈希表的優缺點:
哈希表的學習:
庖丁解牛術法總綱
吾生也有涯,而知也無涯 ,以有涯隨無涯,殆已!已而為知者,殆而已矣!為善無近名,為惡無近刑,緣督以為經,可以保身,可以全生,可以養親,可以盡年,
“庖丁為文惠君解牛,手之所觸,肩之所倚,足之所履,膝之所踦,砉然向然,奏刀騞然,莫不中音,合于《桑林》之舞,乃中《經首》之會,
文惠君曰:“嘻,善哉!技蓋至此乎?”
庖丁釋刀對曰:“臣之所好者,道也,進乎技矣,始臣之解牛之時,所見無非牛者,三年之后,未嘗見全牛也,方今之時,臣以神遇而不以目視,官知止而神欲行,依乎天理,批大郤,導大窾,因其固然,技經肯綮之未嘗,而況大軱乎!良庖歲更刀,割也;族庖月更刀,折也,今臣之刀十九年矣,所解數千牛矣,而刀刃若新發于硎,彼節者有間,而刀刃者無厚;以無厚入有間,恢恢乎其于游刃必有余地矣,是以十九年而刀刃若新發于硎,雖然,每至于族,吾見其難為,怵然為戒,視為止,行為遲,動刀甚微,謋然已解,如土委地,提刀而立,為之四顧,為之躊躇滿志,善刀而藏之,”
——《莊子·養生主》
呔,妖怪,看法寶!
第一重境界:所見莫非全牛者
1、概述:
Set集合類似于一個罐子,程式可以依次把多個物件“丟進”Set集合,而Set集合通常不能記住元素的添加順序,實際上Set就是Collection,只是行為略有不同(Set不允許包含重復元素),
Set集合不允許包含相同的元素,如果試圖把兩個相同元素加入同一個Set集合中,則添加操作失敗,add()方法回傳false,且新元素不會被加入,
2、Set集合特點:
(1)、不包含重復元素的集合
(2)、沒有帶索引的方法,所以不能使用普通for回圈遍歷
3、分類(實作子類):
(1)、HashSet
(2)、TreeSet
4、所有已知實作類:
AbstractSet,ConcurrentHashMap.KeySetView,ConcurrentSkipListSet,CopyOnWriteArraySet,EnumSet,HashSet,JobStateReasons,LinkedHashSet,ReadOnlySetProperty,ReadOnlySetPropertyBase,ReadOnlySetWrapper,SetBinding,SetExpression,SetProperty,SetPropertyBase,SimpleSetProperty,TreeSet
5、注意事項
不包含重復元素的集合, 更正式地,集合不包含一對元素
e1和e2,使得e1.equals(e2),并且最多只有一個空元素, 正如其名稱所暗示的那樣,這個介面模擬了數學集抽象,該
Set介面放置額外的約定,超過從繼承Collection介面,所有建構式的合同,而位于該合同add,equals和hashCode方法, 其他繼承方法的宣告也包括在這里以方便, (這些宣告中附帶的規格已針對Set介面進行了定制,但不包含任何其他規定,)建構式的額外規定并不奇怪,所有建構式都必須創建一個不包含重復元素的集合(如上所定義),
注意:如果可變物件用作設定元素,則必須非常小心, 如果物件的值以影響
equals比較的方式更改,而物件是集合中的元素,則不指定集合的行為, 這種禁止的一個特殊情況是,一個集合不允許將其本身作為一個元素,一些集合實作對它們可能包含的元素有限制, 例如,一些實作禁止空元素,有些實作對元素的型別有限制, 嘗試添加不合格元素會引發未經檢查的例外,通常為
NullPointerException或ClassCastException, 嘗試查詢不合格元素的存在可能會引發例外,或者可能只是回傳false; 一些實作將展現出前者的行為,一些實作將展現出后者, 更一般來說,嘗試對不符合條件的元素的操作,其完成不會導致不合格元素插入到集合中,可能會導致例外,或者可能會成功執行該選項, 此例外在此介面的規范中標記為“可選”,
6、所有方法
Modifier and Type 方法 描述 booleanadd?(E e)如果指定的元素不存在,則將其指定的元素添加(可選操作),
booleanaddAll?(Collection<? extends E> c)將指定集合中的所有元素添加到此集合(如果尚未存在)(可選操作),
voidclear?()從此集合中洗掉所有元素(可選操作),
booleancontains?(Object o)如果此集合包含指定的元素,則回傳
true,booleancontainsAll?(Collection<?> c)如果此集合包含指定集合的所有元素,則回傳
true,booleanequals?(Object o)將指定的物件與此集合進行比較以實作相等,
inthashCode?()回傳此集合的哈希碼值,
booleanisEmpty?()如果此集合不包含元素,則回傳
true,Iterator<E>iterator?()回傳此集合中元素的迭代器,
static <E> Set<E>of?()回傳一個包含零個元素的不可變集合,
static <E> Set<E>of?(E e1)回傳一個包含一個元素的不可變集合,
static <E> Set<E>of?(E... elements)回傳一個包含任意數量元素的不可變集合,
static <E> Set<E>of?(E e1, E e2)回傳一個包含兩個元素的不可變集合,
static <E> Set<E>of?(E e1, E e2, E e3)回傳一個包含三個元素的不可變集合,
static <E> Set<E>of?(E e1, E e2, E e3, E e4)回傳一個包含四個元素的不可變集合,
static <E> Set<E>of?(E e1, E e2, E e3, E e4, E e5)回傳一個包含五個元素的不可變集合,
static <E> Set<E>of?(E e1, E e2, E e3, E e4, E e5, E e6)回傳一個包含六個元素的不可變集合,
static <E> Set<E>of?(E e1, E e2, E e3, E e4, E e5, E e6, E e7)回傳一個包含七個元素的不可變集合,
static <E> Set<E>of?(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8)回傳一個包含八個元素的不可變集合,
static <E> Set<E>of?(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9)回傳一個包含九個元素的不可變集合,
static <E> Set<E>of?(E e1, E e2, E e3, E e4, E e5, E e6, E e7, E e8, E e9, E e10)回傳一個包含十個元素的不可變集合,
booleanremove?(Object o)如果存在,則從該集合中洗掉指定的元素(可選操作),
booleanremoveAll?(Collection<?> c)從此集合中洗掉指定集合中包含的所有元素(可選操作),
booleanretainAll?(Collection<?> c)僅保留該集合中包含在指定集合中的元素(可選操作),
intsize?()回傳此集合中的元素數(其基數),
default Spliterator<E>spliterator?()在此集合中的元素上創建一個
Spliterator,Object[]toArray?()回傳一個包含此集合中所有元素的陣列,
<T> T[]toArray?(T[] a)回傳一個包含此集合中所有元素的陣列; 回傳的陣列的運行時型別是指定陣列的運行時型別,
第二重境界:未嘗見全牛也
HashSet
1、HashSet特點:
(1)底層資料結構是哈希表(查詢速度快),使用HashCode哈希值
(2)對集合的迭代順序不作任何保證,也就是說不保證存盤和取出的元素順序一致
(3)沒有帶索引的方法,所以不能使用普通for回圈遍歷
(4)由于是Set集合,所以是不包含重復元素的集合
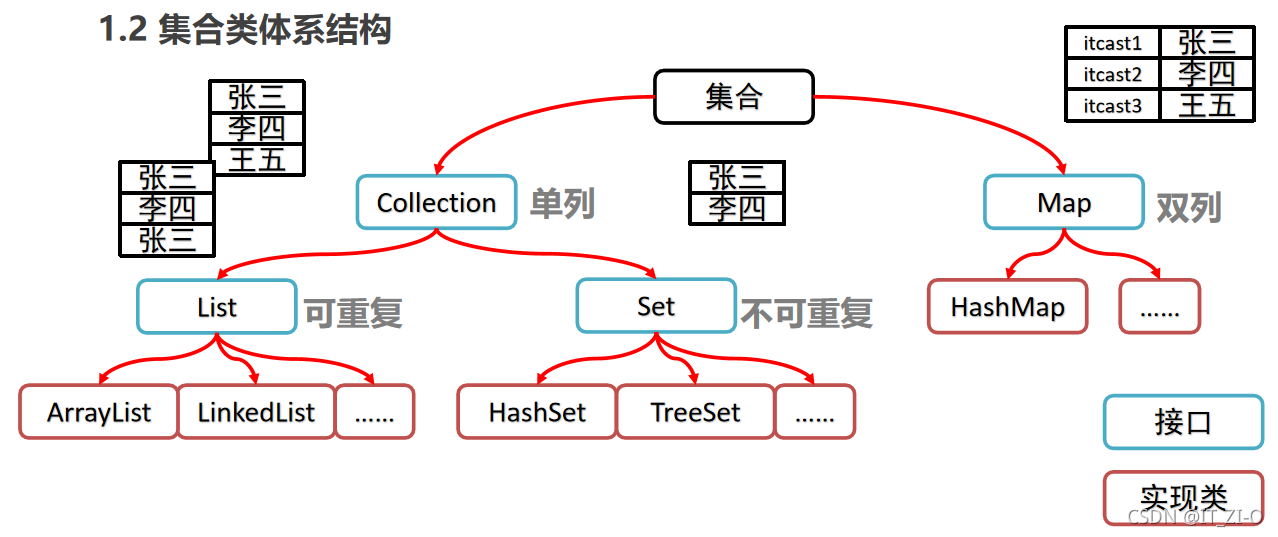
2、HashSet集合添加一個元素的程序:
3、代碼演示
package SetDemo;
import java.util.HashSet;
public class Set01 {
public static void main(String[] args) {
//導包創建物件HashSet
HashSet<String> set=new HashSet<String>();
//添加資料
set.add("aaa");
set.add("bbb");
set.add("ccc");
set.add("ddd");
//增強for回圈遍歷
for (String i:set){
System.out.println(i);
}
}
}
//代碼輸出結果
E:\develop\JDK\bin\java.exe "-javaagent:E:\IDEA\IntelliJ IDEA Community Edition
aaa
ccc
bbb
ddd
Process finished with exit code 04、注意事項(特殊之處,遍歷無序的原因不是排序的無序,而是底層哈希值的存放地址的原因)
public static void main(String[] args) {
HashSet<String> set=new HashSet<String>();
set.add("hello");
set.add("world");
set.add("java");
//集合自帶排序方式
System.out.println(set);
System.out.println("--------");
//迭代器方式
Iterator<String> it = set.iterator();
while (it.hasNext()){
String s = it.next();
System.out.println(s);
}
System.out.println("--------");
//增強for回圈
for (String s:set){
System.out.println(s);
}
}
//輸出結果
[world, java, hello]
--------
world
java
hello
--------
world
java
hello
Process finished with exit code 0上述代碼是正常輸出的結果,但是以下的代碼的輸出,請看:
public static void main(String[] args) {
HashSet<String> set=new HashSet<String>();
set.add("6");
set.add("7");
set.add("8");
set.add("9");
set.add("10");
//集合自帶排序方式
System.out.println(set);
System.out.println("--------");
//迭代器方式
Iterator<String> it = set.iterator();
while (it.hasNext()){
String s = it.next();
System.out.println(s);
}
System.out.println("--------");
//增強for回圈
for (String s:set){
System.out.println(s);
}
}
//代碼輸出結果
[6, 7, 8, 9, 10]
--------
6
7
8
9
10
--------
6
7
8
9
10
Process finished with exit code 0public static void main(String[] args) {
HashSet<String> set=new HashSet<String>();
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("e");
//集合自帶排序方式
System.out.println(set);
System.out.println("--------");
//迭代器方式
Iterator<String> it = set.iterator();
while (it.hasNext()){
String s = it.next();
System.out.println(s);
}
System.out.println("--------");
//增強for回圈
for (String s:set){
System.out.println(s);
}
}
//代碼輸出結果
[a, b, c, d, e]
--------
a
b
c
d
e
--------
a
b
c
d
e
Process finished with exit code 0上述兩則代碼結果,可以看到輸出結果都是有序的,而HashSet特點有一,就是不保證迭代順序,這不就是矛盾的一處地方嗎?
原因:但并不是HashSet的自相矛盾,其原因就是底層實作的特點,哈希表實作,計算哈希值,通過哈希值代替索引的作用,查詢存盤的值,
而哈希值的計算,有一套自己的計算規則,當一串字串計算哈希值時,哈希值的區別也許會很大,但如果是有規律的數字、字符進行計算哈希值時,其哈希值有會時有序的,
表現出來的結果就是在控制臺輸出有順序有規律的單節字符時,輸出也是有規律的,
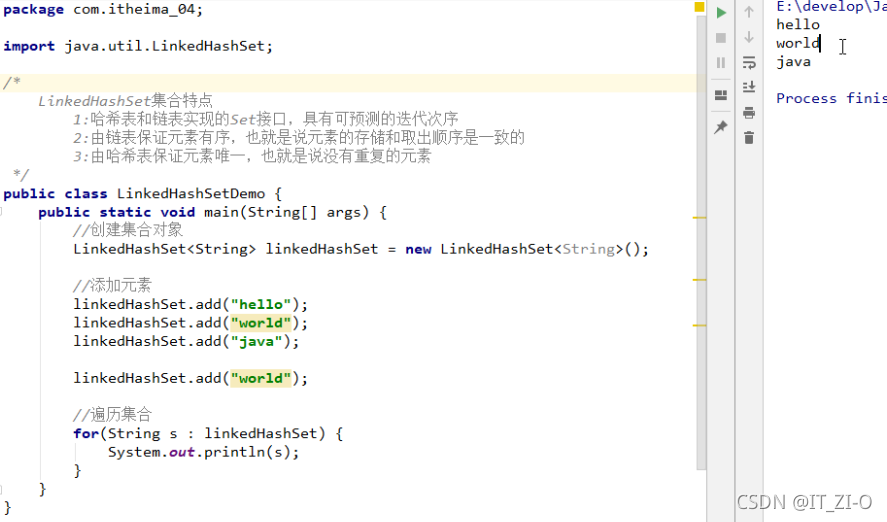
5、LinkedHashSet集合概述和特點
(1)集合特點:
哈希表和鏈表實作的Set介面,具有可預測的迭代順序,
由鏈表保證元素有序,也就是說元素的存盤和取出順序是一致的,
由哈希表保證元素唯一,也就是說沒有重復的元素,
(2)代碼案例
TreeSet
1、TreeSet集合特點
(1)元素有序,這里的順序不是指存盤和取出的順序,而是按照一定的規則進行排序,具體排序方式取決于構造方法
TreeSet?():根據其元素的自然排序進行排序
TreeSet?(Comparator<? super E> comparator) :根據指定的比較器進行排序(2)沒有帶索引的方法,所以不能使用普通for回圈遍歷
(3)由于是Set集合,所以不包含重復元素的集合
2、注意事項
用TreeSet集合存盤自定義物件,無參構造方法使用的是自然排序對元素進行排序的
自然排序,就是讓元素所屬的類實作Comparable介面,重寫compareTo?(T o)方法
重點:如何重寫方法
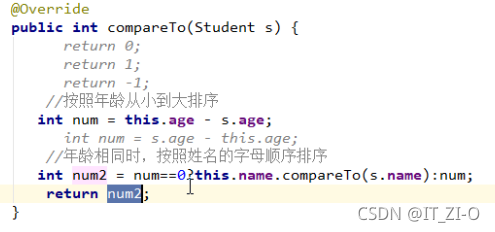
重寫方法時,一定要注意排序規則必須按照要求的主要條件和次要條件來寫
重點:主要條件與次要條件
用TreeSet集合存盤自定義物件,帶參構造方法使用的是比較器排序對元素進行排序的
比較器排序,就是讓集合構造方法接收Comparator的實作類物件,重寫compare?(T o1,T o2)方法
重寫方法時,一定要注意排序規則必須按照要求的主要條件和次要條件來寫
3、代碼展示(比較器排序)
package SetDemo;
import java.util.Comparator;
import java.util.HashSet;
import java.util.Set;
import java.util.TreeSet;
public class Set003 {
public static void main(String[] args) {
Set<News> set=new TreeSet<News>(new Comparator<News>() {
@Override
public int compare(News n1, News n2) {
int num=n1.getTitle().compareTo(n2.getTitle());
return num;
}
});
News news1=new News("中國多地遭霧霾籠罩空氣質量再成熱議話題");
News news2=new News("民進黨臺北舉行“火大游行”");
News news3=new News("春節臨近北京“賣房熱”");
News news4=new News("春節臨近北京“賣房熱”");
System.out.println("新聞一與新聞二的比較:"+news1.equals(news2));
System.out.println("新聞三與新聞四的比較:"+news3.equals(news4));
System.out.println("--------");
set.add(news1);
set.add(news2);
set.add(news3);
set.add(news4);
for (int i = 0; i < set.size(); i++) {
}
Set<News> set1=new HashSet<News>();
set1.addAll(set);
for (News n:set1){
System.out.println(n);
}
System.out.println("--------");
System.out.println("集合中新聞的長度為:"+set1.size());
}
}第三重境界:官知止而神欲行
1、哈希值(hashCode)
概念:
是Jdk根據物件的地址/String/數字算出來一串數字(int),hashCode()是Object類的方法,所以說Java的物件都可以呼叫這個hashCode方法回傳哈希值,
特點:
(1)如果自定義類沒有重寫hashCode方法,那么自定義類的物件生成的哈希值是根據物件的記憶體地址值生成的,所以說即便兩個物件的屬性一樣,哈希值也不一樣,
(2)訴求:如果兩個物件屬性一樣,那么兩個物件哈希值也要一樣,所以在自定義的類中重寫了 hashCode方法(不呼叫Object類hashCode),是根據物件的屬性生成哈希值,
(3)兩個物件哈希值一樣,不代表兩個物件的屬性一樣.兩個物件的屬性一樣,則兩個物件的哈希值肯定一樣,
(4)數字的哈希值是它本身,
代碼展示:
public static void main(String[] args) {
//創建學生類物件,實體化
Student s1 = new Student02("盤古大神", 100, 100, 100,300);
Student s2 = new Student02("女媧娘娘", 100, 95, 90,285);
Student s3 = new Student02("天皇伏羲", 98, 100, 90,288);
Student s4 = new Student02("地皇神農", 99, 95, 90,284);
Student s5 = new Student02("人皇軒轅", 95, 98, 80,273);
//輸出哈希值
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
System.out.println(s3.hashCode());
System.out.println(s4.hashCode());
System.out.println(s5.hashCode());
}
//輸出結果
356573597
1735600054
21685669
2133927002
1836019240
Process finished with exit code 02、哈希表
概念:
散串列(Hash table,也叫哈希表),是根據鍵(Key)而直接訪問在記憶體存盤位置的資料結構,也就是說,它通過計算一個關于鍵值的函式,將所需查詢的資料映射到表中一個位置來訪問記錄,這加快了查找速度,這個映射函式稱做散列函式,存放記錄的陣列稱做散串列,
哈希表的實作:
實作哈希表我們可以采用兩種方法:
1、陣列+鏈表
2、陣列+二叉樹
哈希表的優缺點:
優點:
- 無論資料有多少,處理起來都特別的快
- 能夠快速地進行
插入修改元素、洗掉元素、查找元素等操作- 代碼簡單(其實只需要把哈希函式寫好,之后的代碼就很簡單了)
缺點:
- 哈希表中的資料是沒有順序的
- 資料不允許重復
哈希表的學習:
如果大家想再深入學習哈希表的知識,下附鏈接:
資料結構 Hash表(哈希表)_積跬步 至千里-CSDN博客_哈希表
ending!!!!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/327979.html
標籤:java
上一篇:關于Map集合那些不為人知的秘密
下一篇:cgb2108-day15