Redis使用程序中要注意的事項
Redis使用起來很簡單,但是在實際應用程序中,一定會碰到一些比較麻煩的問題,常見的問題有
- redis和資料庫資料的一致性
- 快取雪崩
- 快取穿透
- 熱點資料發現
下面逐一來分析這些問題的原理及解決方案,
資料一致性
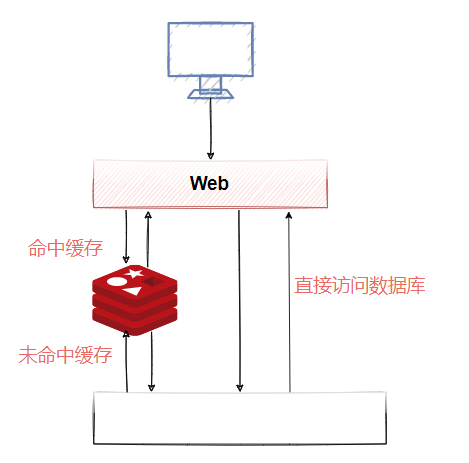
針對讀多寫少的高并發場景,我們可以使用快取來提升查詢速度,當我們使用Redis作為快取的時候,一般流程如圖3-4所示,
- 如果資料在Redis存在,應用就可以直接從Redis拿到資料,不用訪問資料庫,
- 如果Redis里面沒有,先到資料庫查詢,然后寫入到Redis,再回傳給應用,
因為這些資料是很少修改的,所以在絕大部分的情況下可以命中快取,但是,一旦被快取的資料發生變化的時候,我們既要操作資料庫的資料,也要操作Redis的資料,所以問題來了,現在我們有兩種選擇:
-
先操作Redis的資料再操作資料庫的資料
-
先操作資料庫的資料再操作Redis的資料
到底選哪一種?
首先需要明確的是,不管選擇哪一種方案, 我們肯定是希望兩個操作要么都成功,要么都一個都不成功,不然就會發生Redis跟資料庫的資料不一致的問題,但是,Redis的資料和資料庫的資料是不可能通過事務達到統一的,我們只能根據相應的場景和所需要付出的代價來采取一些措施降低資料不一致的問題出現的概率,在資料一致性和性能之間取得一個權衡,
對于資料庫的實時性一致性要求不是特別高的場合,比如T+1的報表,可以采用定時任務查詢資料庫資料同步到Redis的方案,由于我們是以資料庫的資料為準的,所以給快取設定一個過期時間,是保證最終一致性的解決方案,
Redis:洗掉還是更新?
這里我們先要補充一點,當存盤的資料發生變化,Redis的資料也要更新的時候,我們有兩種方案,一種就是直接更新,呼叫set;還有一種是直接洗掉快取,讓應用在下次查詢的時候重新寫入,
這兩種方案怎么選擇呢?這里我們主要考慮更新快取的代價,
更新快取之前,判斷是不是要經過其他表的查詢、介面呼叫、計算才能得到最新的資料,而不是直接從資料庫拿到的值,如果是的話,建議直接洗掉快取,這種方案更加簡單,一般情況下也推薦洗掉快取方案,
這一點明確之后,現在我們就剩一個問題:
-
到底是先更新資料庫,再洗掉快取
-
還是先洗掉快取,再更新資料庫
先更新資料庫,再洗掉快取
正常情況:更新資料庫,成功,洗掉快取,成功,
例外情況:
1、更新資料庫失敗,程式捕獲例外,不會走到下一步,所以資料不會出現不一致,
2、更新資料庫成功,洗掉快取失敗,資料庫是新資料,快取是舊資料,發生了不一致的情況,
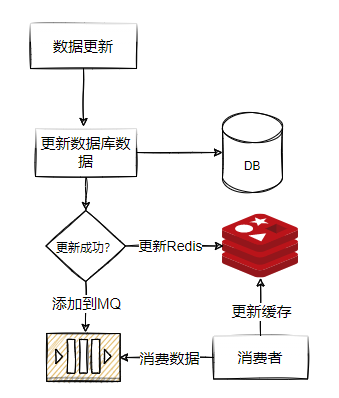
這種問題怎么解決呢?我們可以提供一個重試的機制,
比如:如果洗掉快取失敗,我們捕獲這個例外,把需要洗掉的key發送到訊息佇列,然后自己創建一個消費者消費,嘗試再次洗掉這個key,如圖3-5所示,
另外一種方案,異步更新快取:
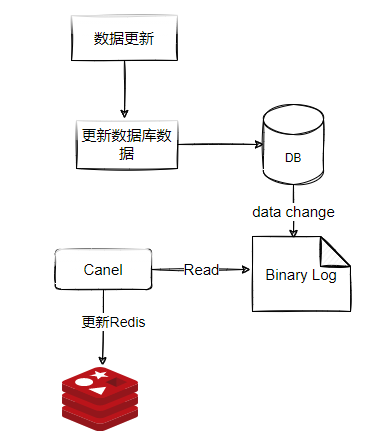
因為更新資料庫時會往binlog寫入日志,所以我們可以通過一個服務來監聽binlog的變化(比如阿里的canal),然后在客戶端完成洗掉key的操作,如果洗掉失敗的話,再發送到訊息佇列,
總之,對于后洗掉快取失敗的情況,我們的做法是不斷地重試洗掉,直到成功,無論是重試還是異步洗掉,都是最終一致性的思想,如圖3-6所示,
基于資料庫增量日志決議,提供增量資料訂閱&消費,目前主要支持了mysql,
先洗掉快取,再更新資料庫
正常情況:洗掉快取,成功,更新資料庫,成功,
例外情況:
-
洗掉快取,程式捕獲例外,不會走到下一步,所以資料不會出現不一致,
-
洗掉快取成功,更新資料庫失敗, 因為以資料庫的資料為準,所以不存在資料不一致的情況,
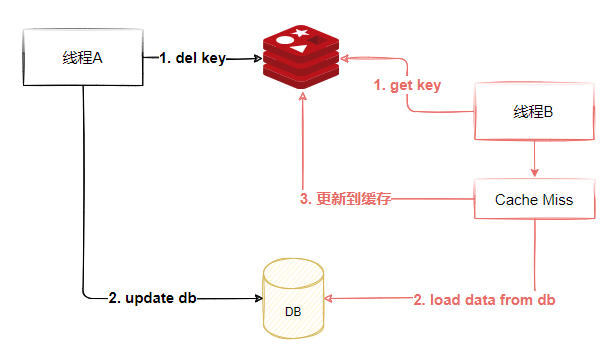
看起來好像沒問題,但是如果有程式并發操作的情況下:
-
執行緒A需要更新資料,首先洗掉了Redis快取
-
執行緒B查詢資料,發現快取不存在,到資料庫查詢舊值,寫入Redis,回傳
-
執行緒A更新了資料庫
這個時候,Redis是舊的值,資料庫是新的值,發生了資料不一致的情況,如圖3-7所示,這種情況就比較難處理了,只有針對同一條資料進行串行化訪問,才能解決這個問題,但是這種實作起來對性能影響較大,因此一般情況下不會采用這種做法,
快取雪崩
快取雪崩就是Redis的大量熱點資料同時過期(失效),因為設定了相同的過期時間,剛好這個時候Redis請求的并發量又很大,就會導致所有的請求落到資料庫,
關于快取過期
在實際開發中,我們經常會,比如限時優惠、快取、驗證碼有效期等,一旦過了指定的有效時間就需要自動洗掉這些資料,否則這些無效資料會一直占用記憶體但是缺沒有任何價值,因此在Redis中提供了Expire命令設定一個鍵的過期時間,到期以后Redis會自動洗掉它,這個在我們實際使用程序中用得非常多,
expire key seconds # 設定鍵在給定秒后過期
pexpire key milliseconds # 設定鍵在給定毫秒后過期
expireat key timestamp # 到達指定秒數時間戳之后鍵過期
pexpireat key timestamp # 到達指定毫秒數時間戳之后鍵過期
EXPIRE 回傳值為1表示設定成功,0表示設定失敗或者鍵不存在,如果向知道一個鍵還有多久時間被洗掉,可以使用TTL命令
ttl key # 回傳鍵多少秒后過期
pttl key # 回傳鍵多少毫秒后過期
當鍵不存在時,TTL命令會回傳-2,而對于沒有給指定鍵設定過期時間的,通過TTL命令會回傳-1,
除此之外,針對String型別的key的過期時間,我們還可以通過下面這個方法來設定,其中可選引數ex表示設定過期時間,
set key value [ex seconds]
如果向取消鍵的過期時間設定(使該鍵恢復成為永久的),可以使用PERSIST命令,如果該命令執行成功或者成功清除了過期時間,則回傳1 , 否則回傳0(鍵不存在或者本身就是永久的)
SET expire.demo 1 ex 20
TTL expire.demo
PERSIST expire.demo
TTL expire
除了PERSIST命令,使用set命令為鍵賦值的操作也會導致過期時間失效,
關于key過期的實作原理
Redis使用一個過期字典(Redis字典使用哈希表實作,可以將字典看作哈希表)存盤鍵的過期時間,字典的鍵是指向資料庫鍵的指標(使用指標可以避免浪費記憶體空間),字典的值是一個毫秒時間戳,所以在當前時間戳大于字典值的時候這個鍵就過期了,就可以對這個鍵進行洗掉(洗掉一個鍵不僅要洗掉資料庫中的鍵,也要洗掉過期字典中的鍵),
設定過期時間的命令都是使用pexpireat命令實作的,其他命令也會轉換成pexpireat,給一個鍵設定過期時間,就是將這個鍵的指標以及給定的到期時間戳添加到過期字典中,比如,執行命令pexpireat key 1608290696843,那么過期字典結構將如圖3-8所示,
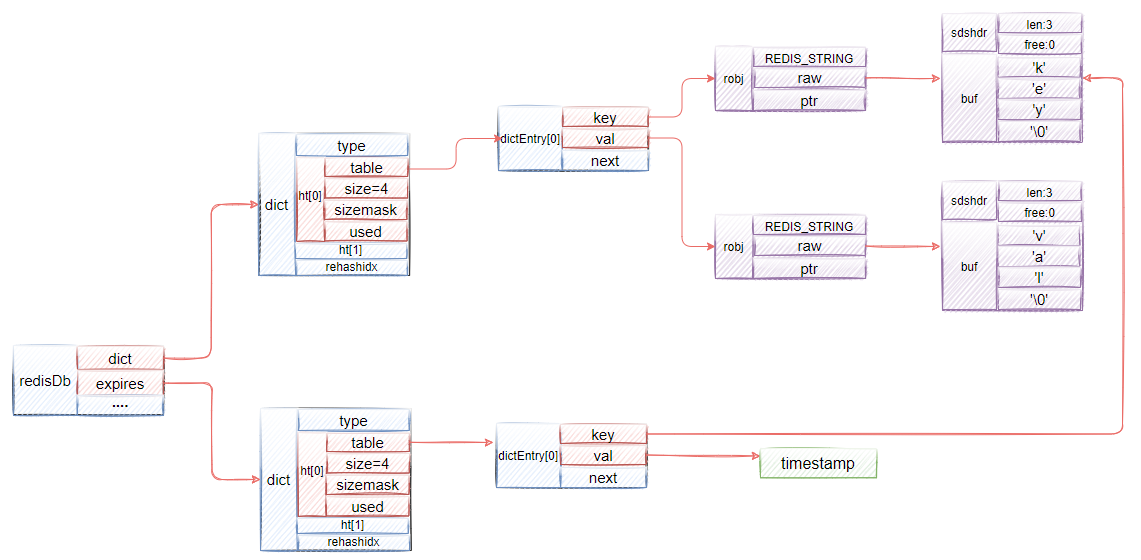
過期鍵的洗掉
過期鍵的洗掉有兩種方法,
-
被動方式洗掉
被動方式的核心原理是,當客戶端嘗試訪問某個key時,發現當前key已經過期了,就直接洗掉這個key,
當然,有可能會存在一些key,一直沒有客戶端訪問,就會導致這部分key一直占用記憶體,因此加了一個主動洗掉方式,
-
主動方式洗掉
主動洗掉就是Redis定期掃描國期間中的key進行洗掉,它的洗掉策略是:
- 從過期鍵中隨機獲取20個key,洗掉這20個key中已經過期的key,
- 如果在這20個key中有超過25%的key過期,則重新執行當前步驟,實際上這是利用了一種概率演算法,
Redis結合這兩種設計很好的解決了過期key的處理問題,
如何解決快取雪崩
了解了過期key的洗掉后,再來分析快取雪崩問題,快取雪崩有幾個方面的原因導致,
- Redis的大量熱點資料同時過期(失效)
- Redis服務器出現故障, 這種情況,我們需要考慮到redis的高可用集群,這塊后面再說,
我們來分析第一種情況,這種情況無非就是程式再去查一次資料庫,再把資料庫中的資料保存到快取中就行,問題也不大,可是一旦涉及大資料量的需求,比如一些商品搶購的情景,或者是主頁訪問量瞬間較大的時候,單一使用資料庫來保存資料的系統會因為面向磁盤,磁盤讀/寫速度比較慢的問題而存在嚴重的性能弊端,一瞬間成千上萬的請求到來,需要系統在極短的時間內完成成千上萬次的讀/寫操作,這個時候往往不是資料庫能夠承受的,極其容易造成資料庫系統癱瘓,最終導致服務宕機的嚴重生產問題,
解決這類問題的方法有幾個,
- 對過期時間增加一個隨機值,避免同一時刻大量key失效,
- 對于熱點資料,不設定過期時間,
- 當從redis中獲取資料為空時,去資料庫查詢資料的地方互斥鎖,這種方式會造成性能下降,
- 增加二級快取,以及快取和二級快取的過期時間不同,當一級快取失效后,可以再通過二級快取獲取,
快取穿透
快取穿透,一般是指當前訪問的資料在redis和mysql中都不存在的情況,有可能是一次錯誤的查詢,也可能是惡意攻擊,
在這種情況下,因為資料庫值不存在,所以肯定不會寫入Redis,那么下一次查詢相同的key的時候,肯定還是會再到資料庫查一次,試想一下,如果有人惡意設定大量請求去訪問一些不存在的key,這些請求同樣最侄訓訪問到資料庫中,有可能導致資料庫的壓力過大而宕機,
這種情況一般有兩種處理方法,
快取空值
我們可以在資料庫快取一個空字串,或者快取一個特殊的字串,那么在應用里面拿到這個特殊字串的時候,就知道資料庫沒有值了,也沒有必要再到資料庫查詢了,
但是這里需要設定一個過期時間,不然的會資料庫已經新增了這一條記錄,應用也還是拿不到值,
這個是應用重復查詢同一個不存在的值的情況,如果應用每一次查詢的不存在的值是不一樣的呢?即使你每次都快取特殊字串也沒用,因為它的值不一樣,比如我們的用戶系統登錄的場景,如果是惡意的請求,它每次都生成了一個符合ID規則的賬號,但是這個賬號在我們的資料庫是不存在的,那Redis就完全失去了作用,因此我們有另外一種方法,布隆過濾器,
布隆過濾器解決快取穿透
先來了解一下布隆過濾器的原理,
- 首先,專案在啟動的時候,把所有的資料加載到布隆過濾器中,
- 然后,當客戶端有請求過來時,先到布隆過濾器中查詢一下當前訪問的key是否存在,如果布隆過濾器中沒有該key,則不需要去資料庫查詢直接反饋即可
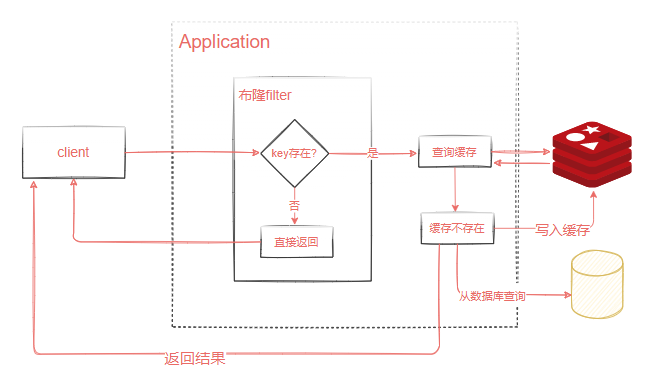
下面我們通過一個案例來演示一下布隆過濾器的作業機制,
注意,該案例是在[springboot-redis-example]這個工程中進行演示,
-
添加guava依賴,guava中提供了布隆過濾器的api
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>21.0</version> </dependency> -
增加一個ApplicationRunner實作,當spring boot啟動完成后執行初始化
@Slf4j @Component public class BloomFilterDataLoadApplicationRunner implements ApplicationRunner { @Autowired ICityService cityService; @Override public void run(ApplicationArguments args) throws Exception { List<City> cityList=cityService.list(); // expectedInsertions: 預計添加的元素個數 // fpp: 誤判率(后續再講) BloomFilter<String> bloomFilter=BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),10000000,0.03); cityList.parallelStream().forEach(city -> { bloomFilter.put(RedisKeyConstants.CITY_KEY+":"+city.getId()); }); BooleanFilterCache.bloomFilter=bloomFilter; } } -
添加一個controller用來訪問測驗
@RestController public class BloomFilterController { @Autowired RedisTemplate redisTemplate; @GetMapping("/bloom/{id}") public String filter(@PathVariable("id")Integer id){ String key=RedisKeyConstants.CITY_KEY+":"+id; if(BooleanFilterCache.bloomFilter.mightContain(key)){ //判斷當前資料在布隆過濾器中是否存在,如果存在則從快取中加載 return redisTemplate.opsForValue().get(key).toString(); } return "資料不存在"; } }
布隆過濾器存盤空間大小計算: https://hur.st/bloomfilter/?n=1000000&p=0.03&m=&k=
布隆過濾器原理分析
完成上述實驗程序后,很多同學會產生疑問,
- 老師,如果我的資料量有上千萬,那不會很占記憶體啊?
- 老師,布隆過濾器的實作原理是什么呀?
什么是布隆過濾器
布隆過濾器是Burton Howard Bloom在1970年提出來的,一種空間效率極高的概率型演算法和資料結構,主要用來判斷一個元素是否在集合中存在,因為他是一個概率型的演算法,所以會存在一定的誤差,如果傳入一個值去布隆過濾器中檢索,可能會出現檢測存在的結果但是實際上可能是不存在的,但是肯定不會出現實際上不存在然后反饋存在的結果,因此,Bloom Filter不適合那些“零錯誤”的應用場合,而在能容忍低錯誤率的應用場合下,Bloom Filter通過極少的錯誤換取了存盤空間的極大節省
BitMap(位圖)
所謂的Bit-map就是用一個bit位來標記某個元素對應的Value,通過Bit為單位來存盤資料,可以大大節省存盤空間.
ps:位元是一個二進制數的最小單元,就像我們現在金額的最小單位是分,只不過位元是二進制數而已,一個位元只能擁有一個值,不是0就是1,所以如果我給你一個值0,你可以說它就是一個位元,如果我給你兩個(00),你就可以說它們是兩個位元了,如果你將八個0或者1組合在一起,我們可以說說是8位元或者1個位元組,在32位的機器上,一個int型別的資料會占用4個位元組,也就是32個位元位,
在java中,一個int型別占32個位元,我們用一個int陣列來表示時未new int[32],總計占用記憶體32*32bit,現假如我們用int位元組碼的每一位表示一個數字的話,那么32個數字只需要一個int型別所占記憶體空間大小就夠了,這樣在大資料量的情況下會節省很多記憶體,
如果要存盤n個數字,那么具體思路如下,
-
1個int占4位元組即4*8=32位,那么我們只需要申請一個int陣列長度為 int tmp[1+N/32]即可存盤完這些資料,其中N代表要進行查找的總數,tmp中的每個元素在記憶體在占32位可以對應表示十進制數0~31,所以可得到BitMap表:
- tmp[0]:可表示0~31
- tmp[1]:可表示32~63
- tmp[2]可表示64~95
- .......
-
接著,我們只需要把對應的數字存盤到指定陣列元素的bit中即可,如何判斷int數字在tmp陣列的哪個下標,這個其實可以通過直接除以32取整數部分,例如:整數8除以32取整等于0,那么8就在tmp[0]上,另外,我們如何知道了8在tmp[0]中的32個位中的哪個位,這種情況直接mod上32就ok,又如整數8,在tmp[0]中的
8 mod 32等于8,那么整數8就在tmp[0]中的第八個bit位(從右邊數起)
比如我們要存盤5(101)、9(1001)、3(11)、1(1)四個數字,那么我們申請int型的記憶體空間,會有32個位元位,這四個數字的二進制分別對應如下,
從右往左開始數,比如第一個數字是5,對應的二進制資料是101, 那么從有往左數到第5位,把對應的二進制資料存盤到32個位元位上,
第一個5就是 00000000000000000000000000101000
而輸入9的時候 00000000000000000000001001000000
輸入3時候 00000000000000000000000000001100
輸入1的時候 00000000000000000000000000000010
思想比較簡單,關鍵是十進制和二進制bit位需要一個map映射表,把10進制映射到bit位上,這樣的好處是記憶體占用少、效率很高(不需要比較和位移),
布隆過濾器原理
有了對位圖的理解以后,我們對布隆過濾器的原理理解就會更容易了,基于前面的例子,我們把資料庫中的一張表的資料全部先保存到布隆過濾器中,用來判斷當前訪問的key是否存在于資料庫,
假設我們需要把id=1這個key保存到布隆過濾器中,并且該布隆過濾器中的hash函式個數為3{x、y、z},它的具體實作原理如下:
- 首先將位陣列進行初始化,將里面每個位都設定位0,
- 對于集合里面的每一個元素,將元素依次通過3個哈希函式{x、y、z}進行映射,每次映射都會產生一個哈希值,這個值對應位陣列上面的一個點,然后將位陣列對應的位置標記為1,
- 查詢
id=1元素是否存在集合中的時候,同樣的方法將W通過哈希映射到位陣列上的3個點,- 如果3個點的其中有一個點不為1,則可以判斷該元素一定不存在集合中,
- 反之,如果3個點都為1,則該元素可能存在集合中,
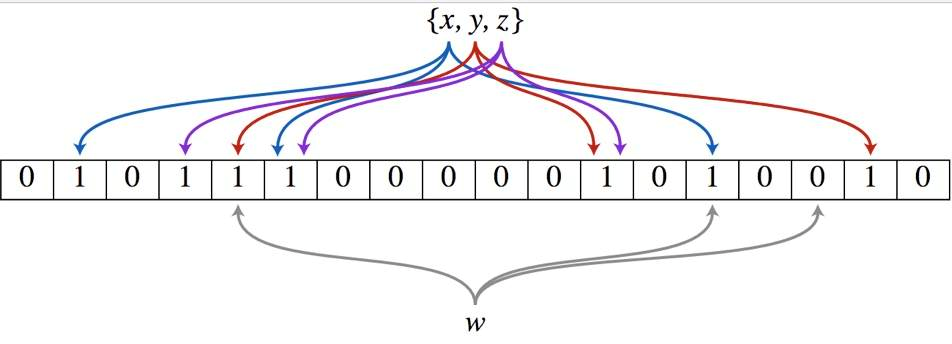
接下來按照該方法處理所有的輸入物件,每個物件都可能把bitMap中一些白位置涂黑,也可能會遇到已經涂黑的位置,遇到已經為黑的讓他繼續為黑即可,處理完所有的輸入物件之后,在bitMap中可能已經有相當多的位置已經被涂黑,至此,一個布隆過濾器生成完成,這個布隆過濾器代表之前所有輸入物件組成的集合,
如何去判斷一個元素是否存在bit array中呢? 原理是一樣,根據k個哈希函式去得到的結果,如果所有的結果都是1,表示這個元素可能(假設某個元素通過映射對應下標為4,5,6這3個點,雖然這3個點都為1,但是很明顯這3個點是不同元素經過哈希得到的位置,因此這種情況說明元素雖然不在集合中,也可能對應的都是1)存在, 如果一旦發現其中一個位元位的元素是0,表示這個元素一定不存在
至于k個哈希函式的取值為多少,能夠最大化的降低錯誤率(因為哈希函式越多,映射沖突會越少),這個地方就會涉及到最優的哈希函式個數的一個演算法邏輯,
-
fpp表示允許的錯誤概率
-
expectedInsertions: 預期插入的數量
public static void main(String[] args) {
BloomFilter<String> bloomFilter=BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),10000000,0.03);
bloomFilter.put("Mic");
System.out.println(bloomFilter.mightContain("Mic"));
}
關注[跟著Mic學架構]公眾號,獲取更多精品原創

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/330012.html
標籤:其他
上一篇:Python 快速排序法(轉)