我試圖用ggplot來繪制Quanteda的詞頻排名。通過 "頻率 "變數來繪制,但我想要一個更漂亮的圖表,
。ggplot需要兩個aes的變數。我已經按照一個類似的主題的建議嘗試了seq_along,但是圖表什么也沒畫出來。
ggplot(word_list, aes(x = seq_along(freqs)。 y = freqs。 group = 1))
geom_line()
實驗室(title = "Rank Frequency Plot"/span>。 x = "Rank"。 y = "Frequency")
歡迎任何意見!
symptoms_corpus < -語料庫(X$TEXT。 docnames = X$id )
summary(symptoms_corpus)
#按索引列印語料庫中任何元素的文本。
cat(as. character(symptoms_corpus[/span>6500]))
# 創建檔案特征矩陣。
Symptoms_DFM <- dfm(symptoms_corpus)
癥狀_DFM
# sum columns for word counts[/span]。
freqs <- colSums(Symptoms_DFM)
# get vocabulary vector 詞匯向量
詞匯 <- colnames(Symptoms_DFM)
# 在一個資料框架中結合單詞和它們的頻率。
word_list <- data.frame(words, freqs)
#按頻率遞減重新排列詞表。
word_indexes < -順序(word_list[。 "freqs"]。 遞減= TRUE)
word_list <- word_list[word_indexes, ]
# 顯示最常出現的詞
head(word_list, 25)
#plot
ggplot(word_list, aes(x = seq_along(freqs)。 y = freqs。 group = 1))
geom_line()
實驗室(title = "Rank Frequency Plot"/span>。 x = "Rank"。 y = "Frequency")
我所說的更好的圖形是指使用下面的基本'plot'函式可以作業并說明排名分布,但這只需要一個變數。 ggplot需要兩個,這就是我的問題所在。ggplot代碼將繪制圖表,但沒有資料顯示。
plot(word_list$freqs。 型別= "l",lwd=2。 main = "Rank frequency Plot"/span>。 xlab="Rank"。 ylab ="Frequency")
下面是示例資料集:
first_column < - c("the","病人"。 "手臂", "皮疹"。 "刺痛", "被"。 "in", "not")
second_column < - c("4116407">。 "3599537"/span>。 "2582586", "1323883", "1220894",/span> "1012042", "925339", "822150")
word_list2 <- data.frame(first_column, second_column)
colnames(word_list2) < - c=("word"。 "freqs")
uj5u.com熱心網友回復:
這里有一個更整潔的、可重復的、使用內置語料庫的情節演示。
library("quanteda"/span>)
## Package version: 3.1.0
## Unicode 版本: 13.0
## ICU版本: 69.1 ## ICU版本: 69.1##并行計算。使用12個執行緒中的12個。
## 教程和例子見https://quanteda.io。
symptoms_corpus <- data_corpus_inaugural
Symptoms_DFM <- tokens(symptoms_corpus) %>%
dfm()
最好是在這里使用quanteda.textstats::textstat_frequency():
# create frequency table
library("quanteda.textstats")
word_list <- textstat_frequency(Symptoms_DFM)
head(word_list, 25)
##特征頻率等級docfreq組
## 1 the 10183 1 59 all
## 2 of 7180 2 59 all[/span].
# 3 , 7173 3 59 all
## 4 和 5406 4 59 all
## 5 . 5155 5 59 所有
## 6至4591 6 59 all
## 7 in 2827 7 59 all[/span]。
# 8 a 2292 8 58 all
#9 our 2224 9 58 all
## 10 we 1827 10 58 all[/span]。
## 11 that 1813 11 59 all[/span].
## 12 be 1502 12 59 all[/span].
## 13 是 1491 13 58 all
## 14 it 1398 14 59 all
## 15 for 1230 15 59 all ## 15 for 1230 15 59 all
## 16 by 1091 16 59 all ## 16 by 1091 16 59 all?
## 17有1031 17 59 all ## 17有1031 17 59 all
## 18 which 1007 18 57 all
## 19 not 980 19 58 all[/span]。
## 20 with 970 20 58 all[/span]。
## 21為966 21 58 all
## 22將944 22 57 all ## 22將944 22 57 all?
## 23 this 874 23 59 all[/span].
## 24 i 871 24 58 all ## 24 i 871 24 58 all
## 25 all 836 25 59 all
然后繪圖:
# Zipf's law plot。
library("ggplot2")
ggplot(word_list, aes(x = seq_len(nrow(word_list))。 y =頻率。 組 = 1))
geom_line()
coord_trans(y = "log10"/span>。 x = "log10")
labs(title = "Rank Frequency Plot"。 x = "Rank"。 y = "Frequency")
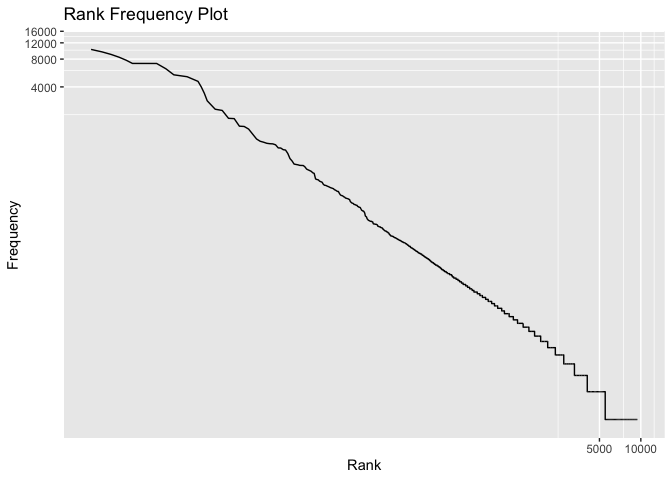
uj5u.com熱心網友回復:
我不確定你說的 "更漂亮的圖表 "是什么意思。你能說明一下嗎?因為我們沒有你的資料集,所以不可能通過你提供的代碼來重現這個例子。
也許你可以簡單地添加行號作為 X 值,如下所示。這將產生一個有序的圖形
library(ggplot2)
word_list <- data. frame(freq = c(10。 12, 18。 19))
ggplot(word_list, aes(x = 1。 nrow(word_list), y = freq。 group = 1))
geom_line()
實驗室(title = "Rank Frequency Plot"/span>。 x = "Rank"。 y = "Frequency")
uj5u.com熱心網友回復:
我需要進行對數擴展,資料集是巨大的,所以沒有出現。上面的例子,@TrineCosmusNobel,指出了這一點。謝謝。更新后的代碼如下:
ggplot(word_list。 aes(x = 1: nrow(word_list), y = freqs。 group = 1))
geom_line()
coord_trans(y ='log10'/span>。 x='log10')
labs(title = "Rank Frequency Plot"。 x = "Rank"。 y = "Frequency")
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/330196.html
標籤: