資料爬取與分析
1. 基礎知識
1.1 資料分析的基礎知識
資料分析的一般流程:
明確目標-》采集資料-》資料清洗與分析-》繪制圖表并且可視化-》得出結論
1.2 具有python特色的程式
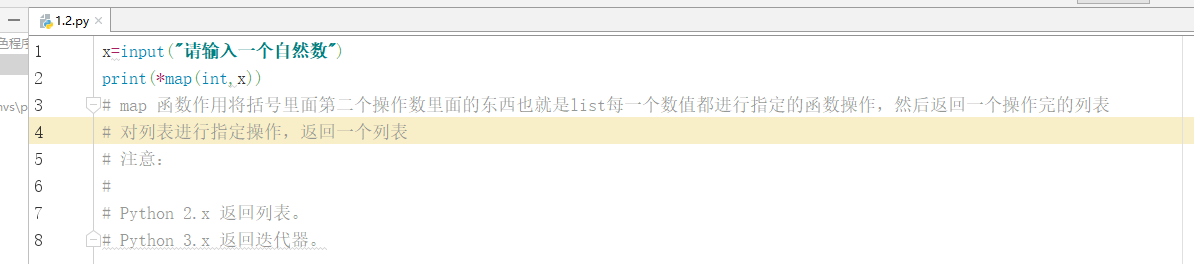
1.3 字串切片
1 回圈列印嵌套串列:movies=[“the holy”,1975,“terry jones”,91,[“graham”,
[“michael”,“john”,“gilliam”,“idle”,“haha”]]],實作以下形式的輸出:
The holy
1975
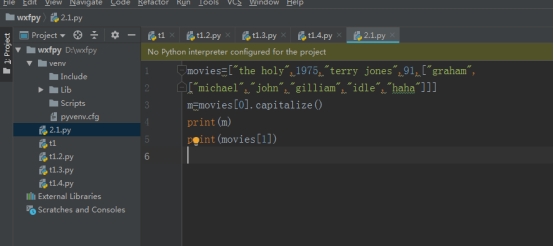
2、字典值操作
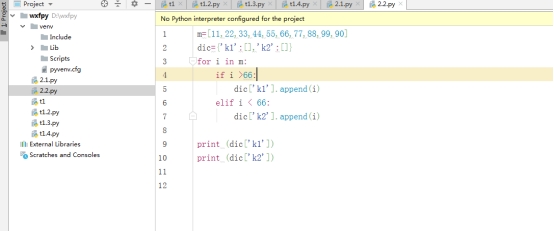
有如下值集合[11,22,33,44,55,66,77,88,99,90],將所有大于66的值保存至字典的第一個key中,將小于66的值保存至第二個key的值中,即:{‘k1’:大于66的所有值,‘k2’:小于66的所有值}
2. 資料采集-爬蟲的設計與實作
2.1 兩條技術路線:
-
爬蟲框架:scrapy 、selenium
-
request庫,urlib原生爬蟲
2.2 爬蟲概念:
-
網路爬蟲
網路爬蟲是一種按照一定規則,自動抓取互聯資訊的程式或者腳本,
由于互聯網資料的多樣性,資源的有限性,現在根據用戶需求定向抓取相關網頁并分析,已經成為當今主流爬取策略
-
爬蟲的本質
模擬瀏覽器打開網頁,獲取網頁中我們想要的部分資料
-
爬蟲作業流程
- 觀察頁面特征:使用Ctrl+u查看網頁原始碼,選中某元素,進行審查
- 請求目標網頁并獲得相應
- 定義資訊提取規則,使用re(正則)第三方網頁決議器,beautiful soup xpath bs4
- 提取網頁資料并保存
-
資料通常需要通過決議,決議方式:
定義資訊提取規則,使用re(正則)第三方網頁決議器,beautiful soup xpath bs4
2.4 Scrapy 爬蟲
2.4.1 Scrapy 爬蟲的主要部件以及作用
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-pHCwfals-1634735959385)(C:/Users/Lenovo/AppData/Roaming/Typora/typora-user-images/image-20211019203520100.png)]
- Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、資料傳遞等,
- Scheduler(調度器): 它負責接受引擎發送過來的Request請求,并按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎,
- Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理
- Spider(爬蟲):它負責處理所有Responses,從中分析提取資料,獲取Item欄位需要的資料,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器)
- Item Pipeline(管道):它負責處理Spider中獲取到的Item,并進行進行后期處理(詳細分析、過濾、存盤等)的地方.
- Downloader Middlewares(下載中間件):可以自定義擴展下載功能的組件(代理、cokies等),
- Spider Middlewares(Spider中間件):可以自定擴展和操作引擎和Spider中間通信的功能組件(比如進入Spider的Responses;和從Spider出去的Requests)
2.4.2 Scrapy 爬蟲的作業流程
- 引擎從調度器中取出一個鏈接(URL)用于接下來的抓取
- 引擎把URL封裝成一個請求(Request)傳給下載器
- 下載器把資源下載下來,并封裝成應答包(Response)
- 爬蟲決議Response
- 決議出物體(Item),則交給物體管道進行進一步的處理
- 決議出的是鏈接(URL),則把URL交給調度器等待抓取
2.4.3 與傳統的request爬蟲對比
- scrapy是封裝起來的框架,他包含了下載器,決議器,日志及例外處理,基于多執行緒, twisted的方式處理,對于固定單個網站的爬取開發,有優勢,但是對于多網站爬取 100個網站,并發及分布式處理方面,不夠靈活,不便調整與括展,
- request 是一個HTTP庫, 它只是用來,進行請求,對于HTTP請求,他是一個強大的庫,下載,決議全部自己處理,靈活性更高,高并發與分布式部署也非常靈活,對于功能可以更好實作
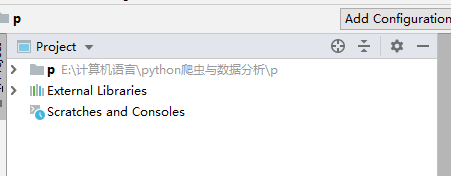
2.4.4 scrapy創建爬蟲的流程
-
手動創建scrapy專案夾 p (mkdir p)
-
啟動命令列,進入到該專案如 cd 到p夾下

-
scrapy startproject 專案名稱
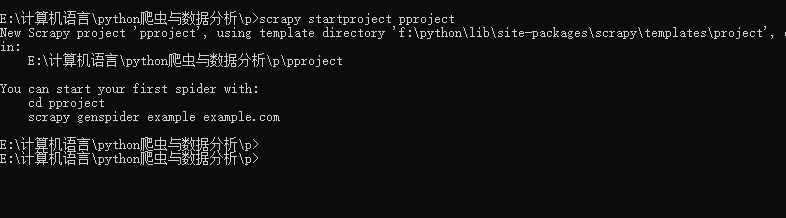

cd E:/p/專案名稱進入到該專案夾后,然后執行 scrapy genspider XXX XXX

-
配置資訊,配置itempiplines等的設定
后面就是修改組態檔settings.py部分的配置,定義item存資料
-
撰寫爬蟲邏輯
在我們的ptest里面撰寫爬蟲邏輯
2.5 Selenium 爬蟲框架
2.5.1 適用場景
爬取動態頁面,用于web應用測驗的工具,selenium測驗直接在瀏覽器運行,可以模仿人的操作,可以有效應對反爬機制
2.5.2 安裝與配置
- pip install
- 用anaconda環境
- pycharm 直接下載庫
2.5.3 定位元素方式
有很多種元素定位的方法,比如基于id、name、xpath、css selector等方式來定位
-
回傳單個元素:
- find_element_by_id()
- find_element_by_name()
- find_element_by_xpath()
- find_element_by_link_text()
- find_element_by_partial_link_text()
- find_element_by_tag_name()
- find_element_by_class_name()
- find_element_by_css_selector()
-
回傳串列:
-
find_elements_by_name()
-
find_elements_by_xpath()
-
find_elements_by_link_text()
-
find_elements_by_partial_link_text()
-
find_elements_by_tag_name()
-
find_elements_by_class_name()
-
find_elements_by_css_selector()
因為id是唯一的所以我覺得不能回傳串列
-
3 . 資料庫連接與查詢
3.1 Mysql資料庫
3.1.1安裝與配置
- 安裝mysql
- 最好再安裝一個mysql用戶圖形化管理界面比如navicate
- 配置環境變數
- 下載pymysql庫
3.1.2 python操作mysql資料庫
操作步驟:
- 新建資料庫
- 新建表
- 連接資料庫
- 向當前資料庫中的表插入資料
3.2 MongoDB 資料庫
3.2.1安裝與配置
- 安裝MongoDB
- 最好再安裝一個MongoDB用戶圖形化管理界面比如navicate
- 配置環境變數
- 下載pymongo庫
3.2.2 python操作mysql資料庫
操作步驟:
- 新建連接
- 新建資料庫
- 連接資料集
- 向當前資料集下插入資料
4. 資料分析
4.1 numpy
4.1.1 陣列的創建
import numpy as np
np.ones(5)
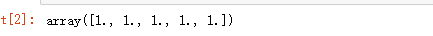
A=np.array([[1,2],[3,4]])

np.zeros((2,3))
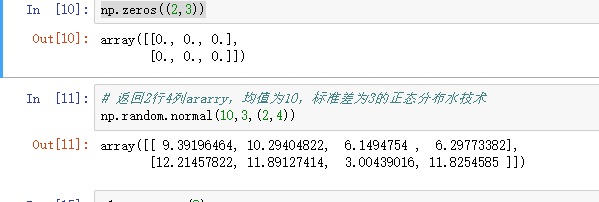
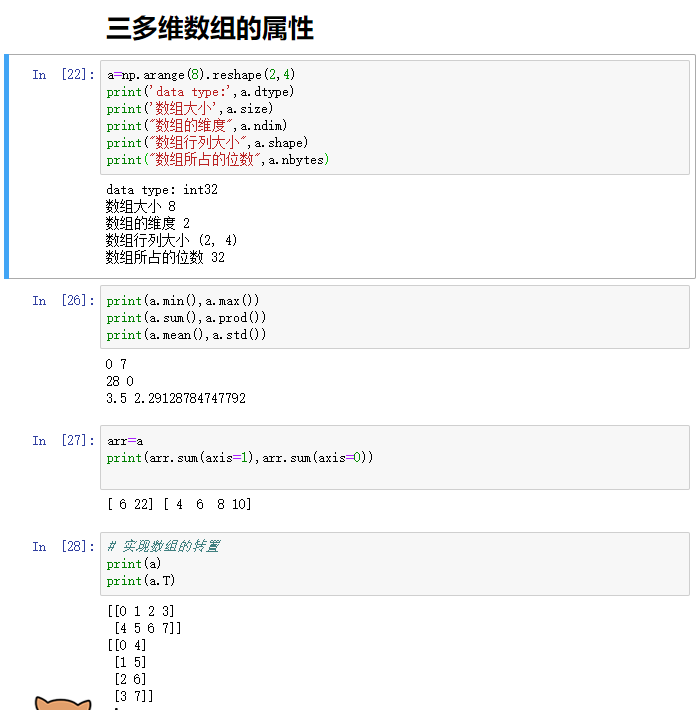
4.1.2 陣列的變形
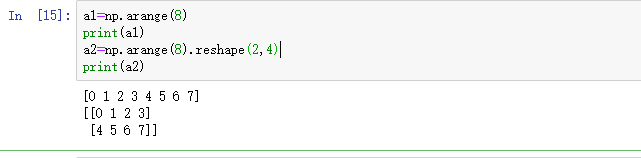
a2=np.arange(8).reshape(2,4)
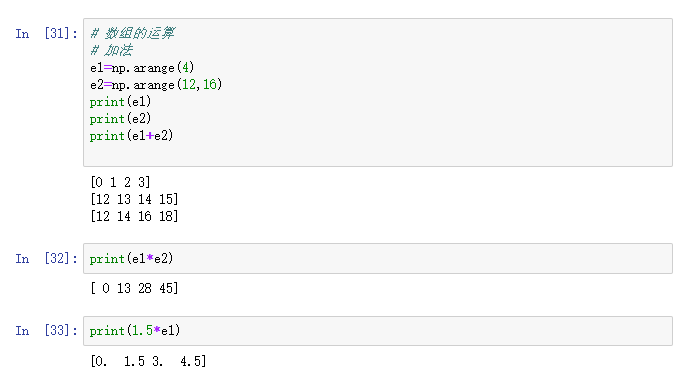
4.1.3 陣列的計算
4.2 pandas
4.2.1 資料讀寫、選擇、整理和描述
-
從csv中讀取資料
import pandas as pddf =pd.read_csv("./資料阿巴巴巴.csv")其實還可以讀取html、txt
高級操作:
df=pd.read_csv("./shujv.cvs",delimiter=",",encoding="utf-8",header=0)#delimiter以怎么樣的方式來分割;解碼方式utf-8;設定0行為頭部 -
向csv中寫入資料
df.to_csv("./ababab.csv",columns=["寶貝","價格"],index=False,header=True)不要索引,以列頭這兩行匯入
-
資料選取
-
行的選取
rows =df[0:3]選擇第0行到第2行資料
r=df.head()選取前五行
-
列的選取
cols =df[['寶貝','價格']] -
塊
取0到3行的寶貝和價格
df.loc[0:3,['寶貝','價格']] -
操作行和塊
從已有的列中創建一個新列
df['銷售額']=df['價格']*df['成交量']df.head()#查看一下前五行資料 -
根據條件過濾行
df1=[(df["價格"]<100)&(df["成交量"]>1000)]篩選出,價格小于100,成交量大于1000的資料
-
-
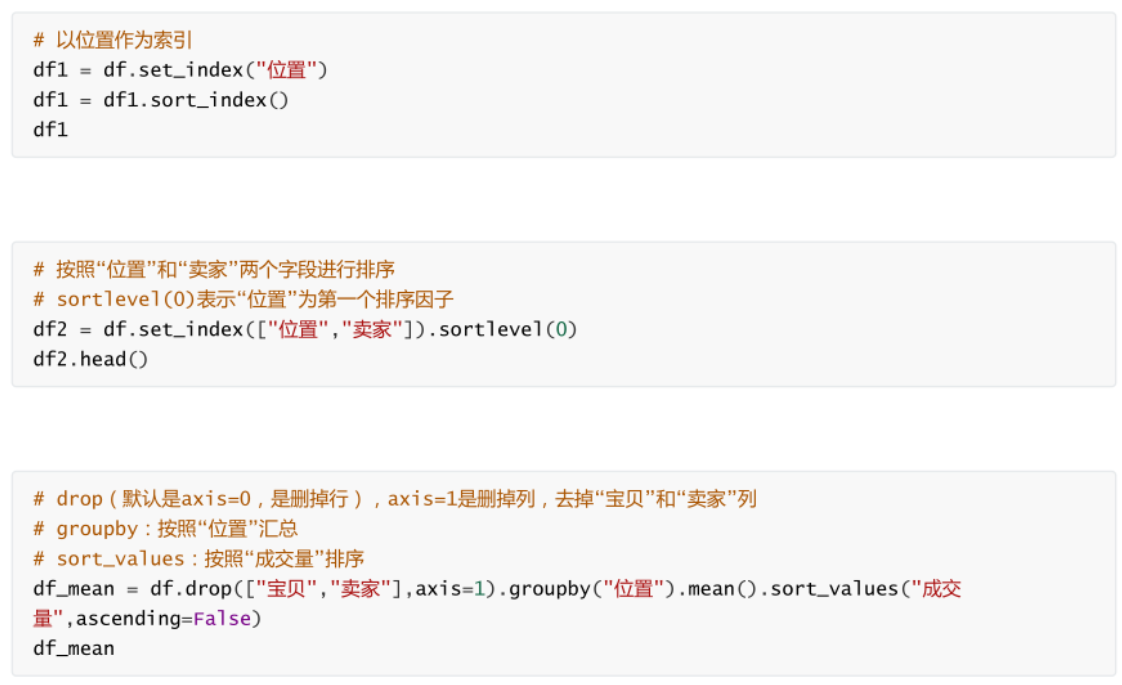
資料整理

-
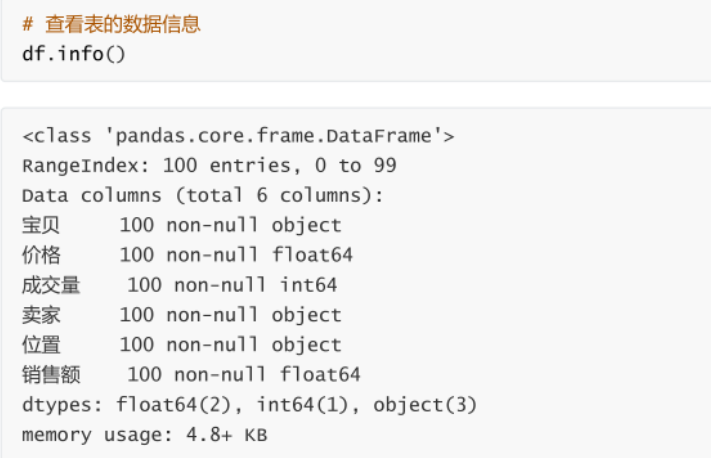
資料描述

4.2.2 資料分組、分割、合并和變形
-
分組
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-EzhROGsp-1634735959479)(C:/Users/Lenovo/AppData/Roaming/Typora/typora-user-images/image-20211019232946860.png)]

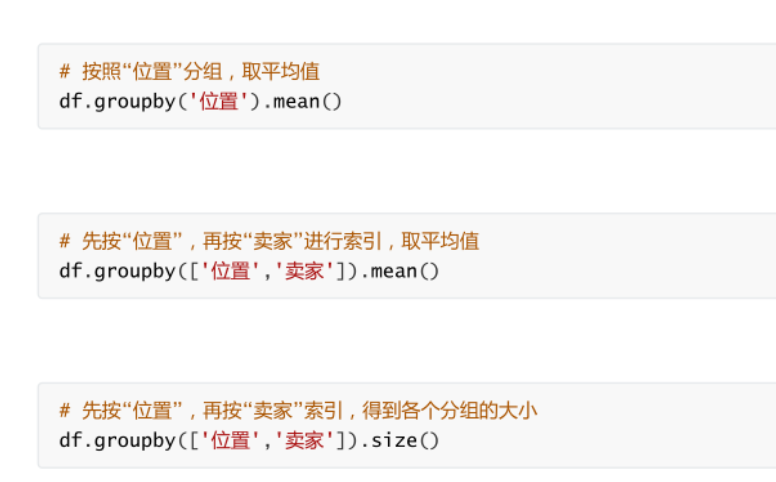
-
分割
前閉后開
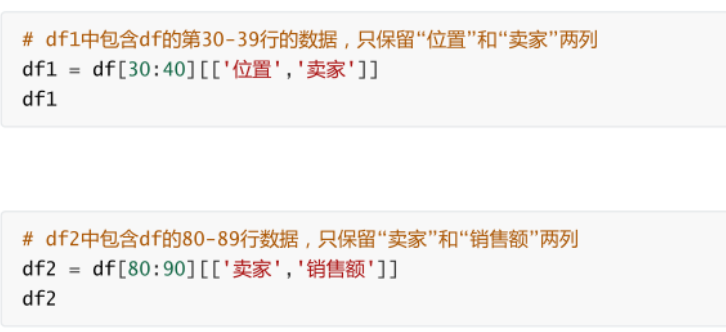
-
合并
-
dataframe合并
pd.merge(df1,df2,how='left',on="賣家")#左連接pd.merge(df1,df2,how='outer',on="賣家")#外連接pd.merge(df1,df2,how='right',on="賣家")#右不指定on那個列就默認相同的選擇列名相同的一列
-
索引合并
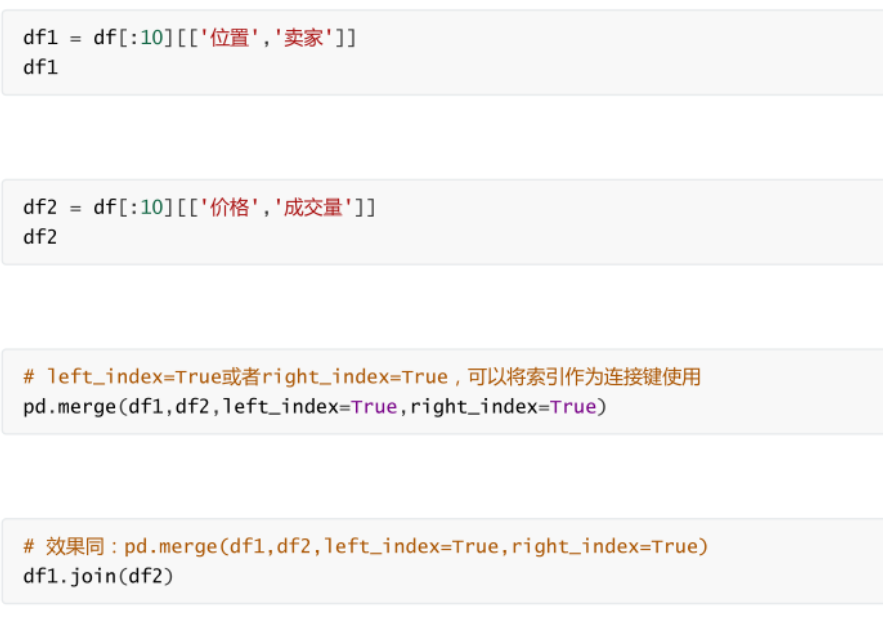
-
軸向連接
按axis=1列拼接,axis為0就是按行,默認就是行,
pd.contact([col1,col2,col3],axis=1)
-
-
變形
-
重塑層次化


-
資料透視表:
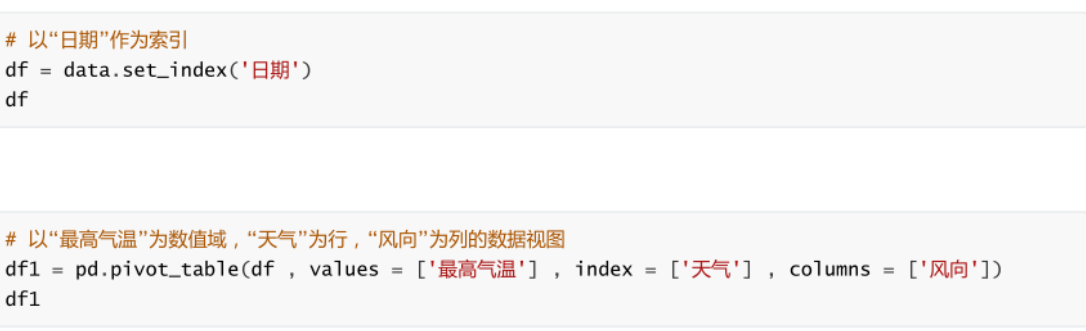
-
-
4.2.3 缺失值


5. 資料可視化
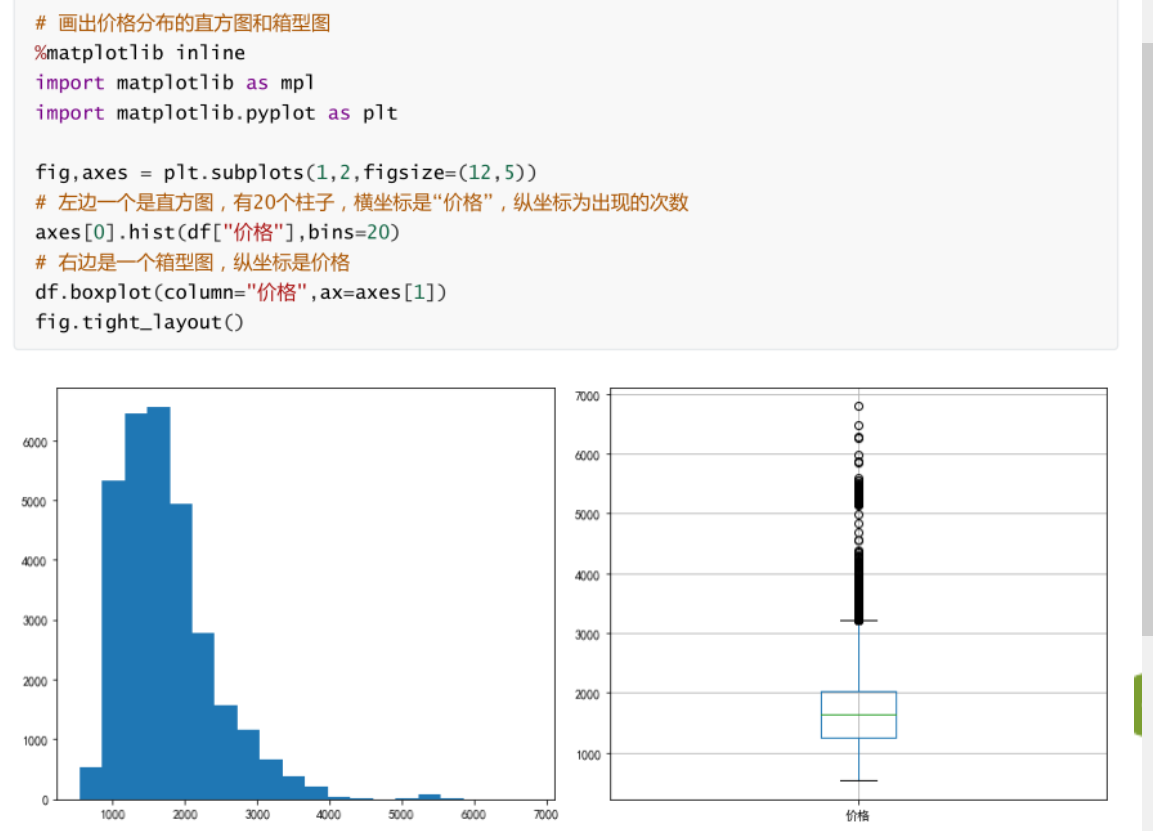
5.1 matplotlib繪圖操作:
-
初始化,導庫,亂碼,設定背景
import matplotlibimport matplotlit.pylot -
生成一個畫布(規定畫布大小,坐標系)
fig,axes =plt.subplots(1,2,figsize=(12,5)) -
繪圖(形狀)
axes[0].hit(df,bins=20) -
自動調整樣式
fig.tight_layout()
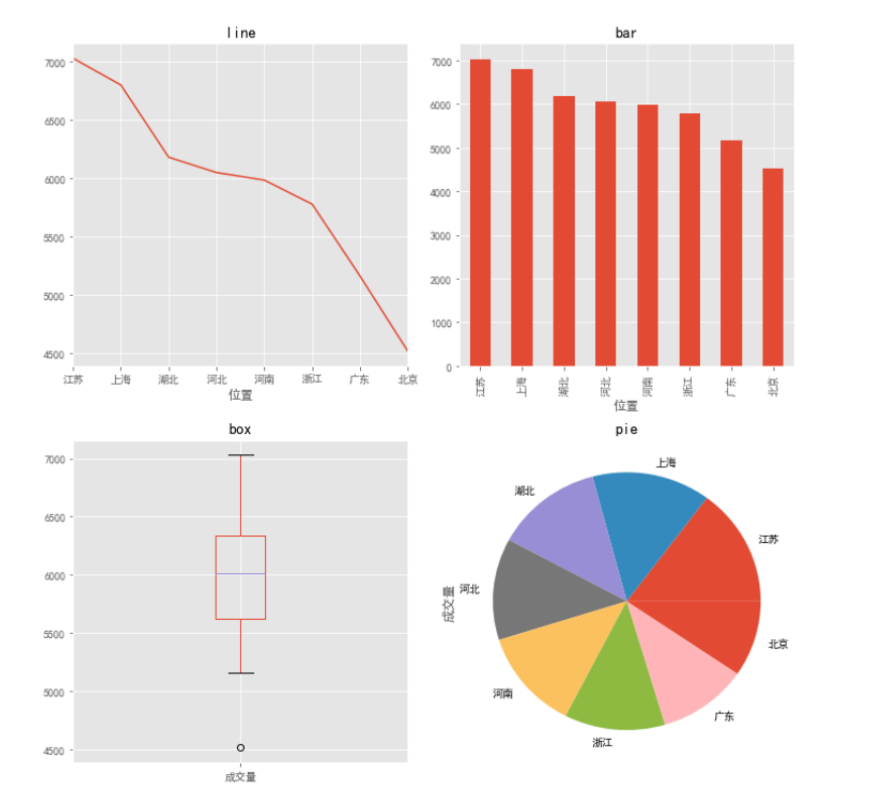
5.2 案例

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/330327.html
標籤:python
上一篇:根據經緯度計算兩地之間的距離