我正在嘗試用Python制作網路搜刮器,在提取公司名稱時出現了問題。
def extract_indeed_job():
jobs = []
result = requests.get(f"{url}&start={0*LIMIT}">)
result_soup = BeautifulSoup(result.text, "html.parser")
result = result_soup.find_all("a"/span>, {"class"/span>: "tapItem"})
for result in results:
title = result.find("h2"/span>, {"class"/span>: "jobTitle"}).find("span")["title"]
company = result.find("span"/span>, {"class"/span>: "companyName"}.get_text()
location = result.find("div"/span>, {"class"/span>: "companyLocation"}).get_text()
print(title, company, location)
有些帖子,在h2 class="jobTitle "標簽中有兩個span標簽 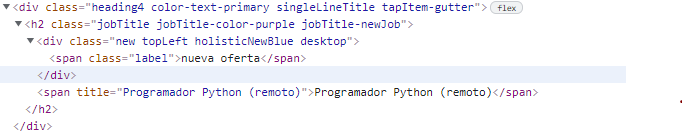
而我需要得到的只是span標題。所以我用這個標簽寫了進去。但是,Python注意到了關鍵的錯誤,它沒有作業。
我應該怎么做?
我能做些什么來解決?我的代碼中有什么問題嗎?
我應該怎樣解決?
uj5u.com熱心網友回復:
注意,在<span>里面有多個<h2>元素。你想要的是<span>是<h2>的直接子元素,而不是<span>內的<div>,為了得到它你可以替換
result.find("h2"/span>, {"class": "jobTitle"}).find("span")
使用
result.find("h2", {"class": "jobTitle"}).find("span", recursive=False)
這將防止遞回搜索(即尋找子女的子女和進一步的)
CodePudding
True確保你正在過濾那些帶有該屬性的span,所以當你試圖訪問其值時,你不會得到一個錯誤。find只是回傳一個span,而不關心你需要的屬性。
result.find("span", title=True)[title']
你提供的代碼和HTML是模糊的。你的陳述句title = result.find("h2", {"class": "jobTitle"})將永遠不會匹配h2標簽,因為它的類屬性更復雜,``jobTitle jobTitle-color-purple jobTitle-newJob'。為了與之匹配,你需要
import re
...
result.find("h2", class_=re.compile(r'jobTitle')
使用正則運算式來改進湯中的搜索。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/331283.html
標籤:
上一篇:無法搜刮懸停顯示的隱藏資料
下一篇:沒有回傳到美麗的湯中