為什么寫這篇文章
我從2021年6月13號寫下第一篇Python的系列專欄算起,陸續更新了二十七篇Python系列文章,在此感謝讀者朋友們的支持和閱讀,特別感謝一鍵三連的小伙伴,
本專欄起名【Python從入門到精通】,主要分為基礎知識和專案實戰兩個部分,目前基礎知識部分已經完全介紹完畢,下一階段就是寫Python專案實戰以及爬蟲相關的知識點,
為了對前期學習的Python基礎知識做一個總結歸納,以幫助讀者朋友們更好的學習下一部分的實戰知識點,故在此我寫下此文,共勉,同進,
同時為了方便大家交流學習,我這邊還建立了一個Python的學習群,群里都是一群熱愛學習的小伙伴,不乏一些牛逼的大佬,大佬帶飛,我相信進入群里的小伙伴一定會走的更快,飛的更高, 歡迎掃碼進群,
本專欄寫了什么
下面就通過一個思維導圖,展示本專欄Python基礎知識部分的總覽圖,
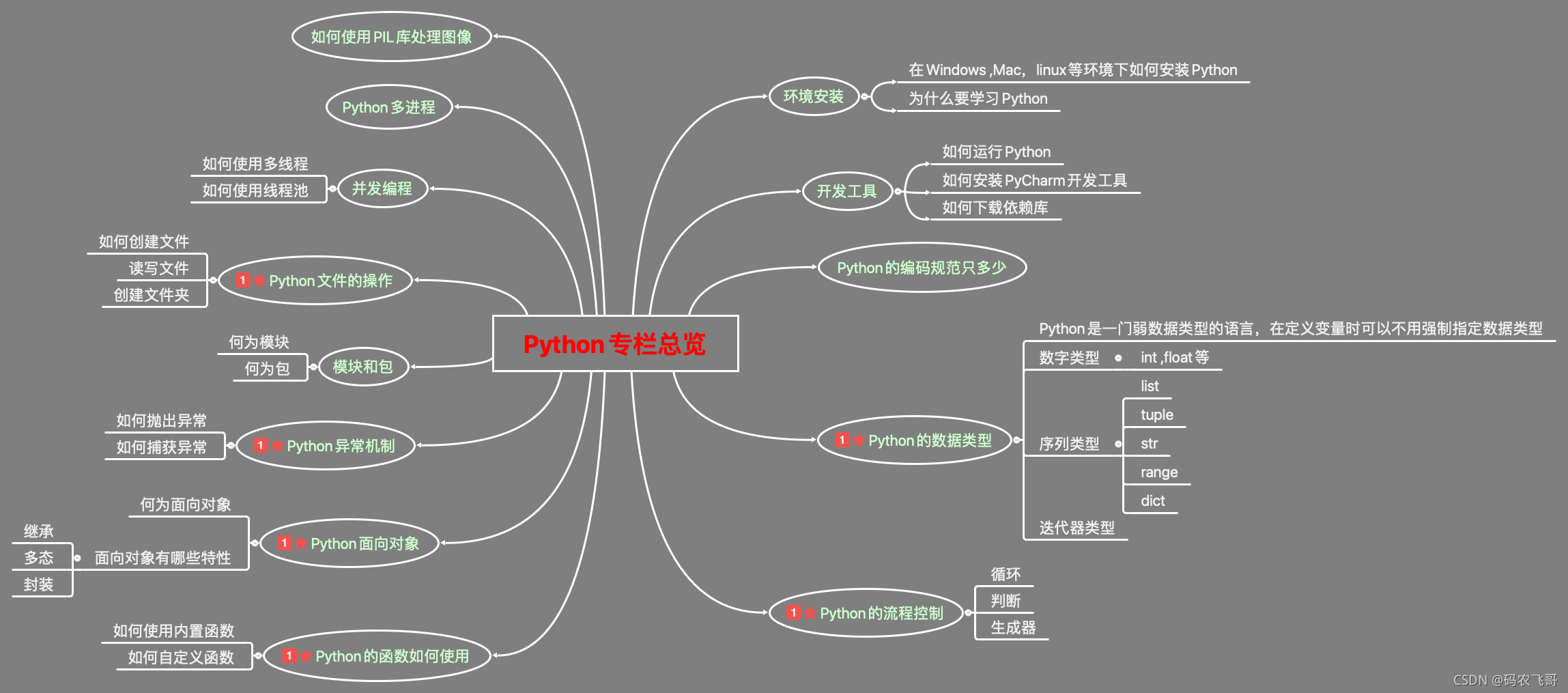
本專欄從零基礎出發,從環境的搭建到高級知識點的學習,一步步走來,相信各位讀者朋友們早已掌握相關的知識點,接下來就做一個詳細的回顧,
0.何為Python
Python是一門開源免費的,通用型的腳本編程語言,它需要在運行時將代碼一行行決議成CPU能識別的機器碼,它是一門決議型的語言,何為決議型語言呢?就是在運行時通過決議器將源代碼一行行決議成機器碼,而像C語言,C++等則是編譯型的語言,即通過編譯器將所有的源代碼一次性編譯成二進制指令,生成一個可執行的程式,決議型語言相對于編譯型語言的好處就是天然具有跨平臺的特點,一次編碼,到處運行,
1. 開發環境配置
- 下載Python解釋器
如同Java需要安裝JDK 編譯器一樣,Python也需要安裝解釋器來運行Python程式,
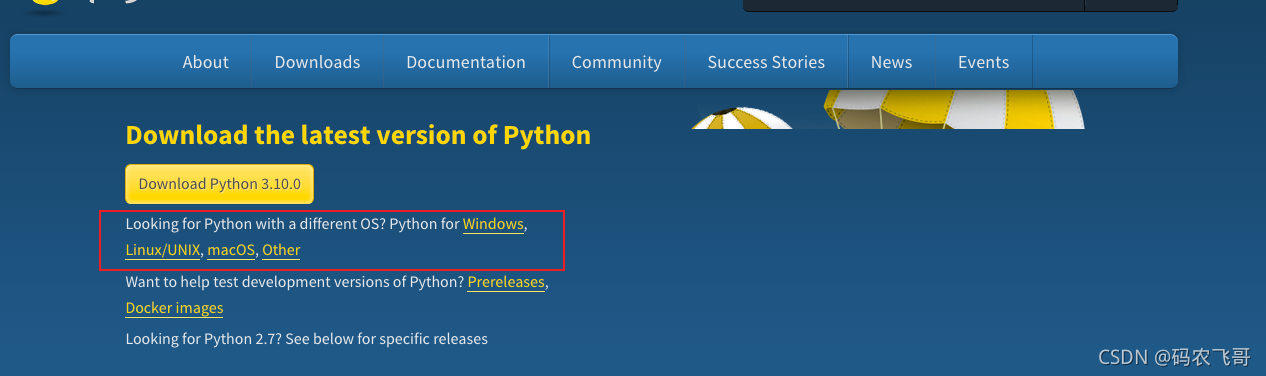
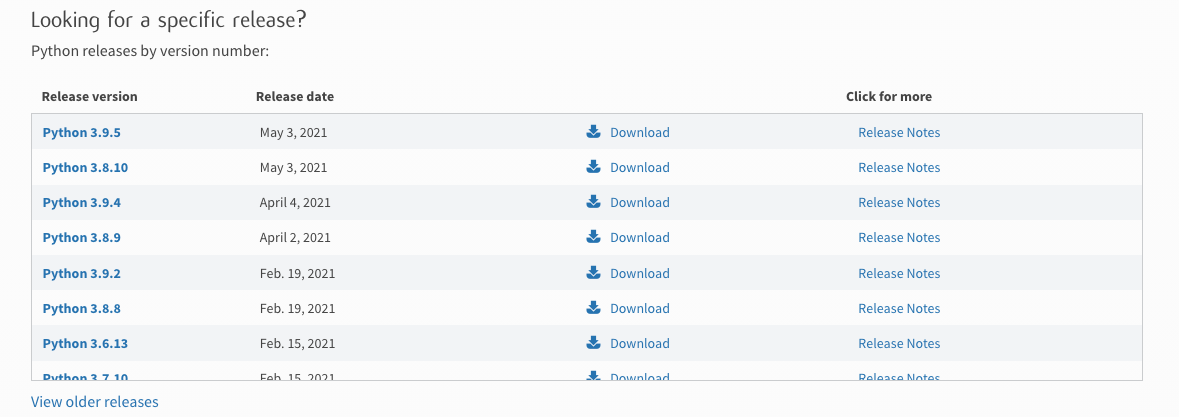
官方的下載網址是: https://www.python.org/downloads/,映入眼簾的是最新的發布版本,如果想下載其他版本的話,可以下來找到如下圖所示的資訊,當前的最新版本是 python 3.9.5 版本,根據你開發電腦的系統選擇不同系統的安裝包,
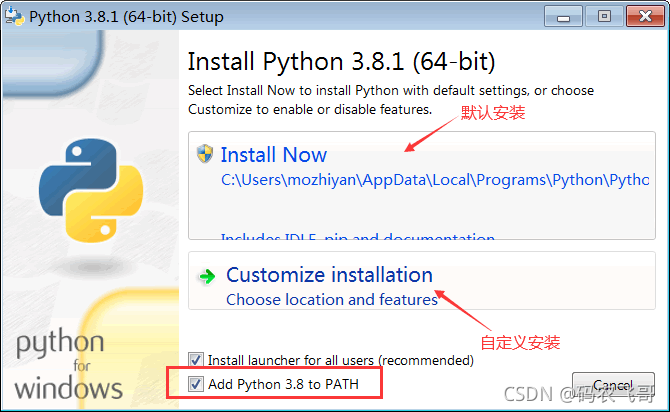
安裝包下載之后雙擊運行進行安裝,需要注意的是在Window下安裝需要勾選 Add Python 3.8 to PATH,如下圖1.2所示
安裝完成之后在命令列中輸入python3驗證安裝的結果,如果出現如下結果就表明安裝Python編譯器安裝成功了,

詳細內容可以查看【Python從入門到精通】(一)就簡單看看Python吧
2. 工具安裝
2.1. 安裝PyCharm開發工具
工欲善其事必先利其器,在實際開發中我們都是通過IDE(集成開發環境)來進行編碼,為啥要使用IDE呢?這是因為IDE集成了語言編輯器,自動建立工具,除錯器等等工具可以極大方便我們快速的進行開發,打個比方 我們可以將集成開發環境想象成一個臺式機,雖然只需要主機就能運行起來,但是,還是需要顯示幕,鍵盤等才能用的爽,
PyCharm就是這樣一款讓人用的很爽的IDE開發工具,下面就簡單介紹一下它的安裝程序
下載安裝包
點擊鏈接 https://www.jetbrains.com/pycharm/download/
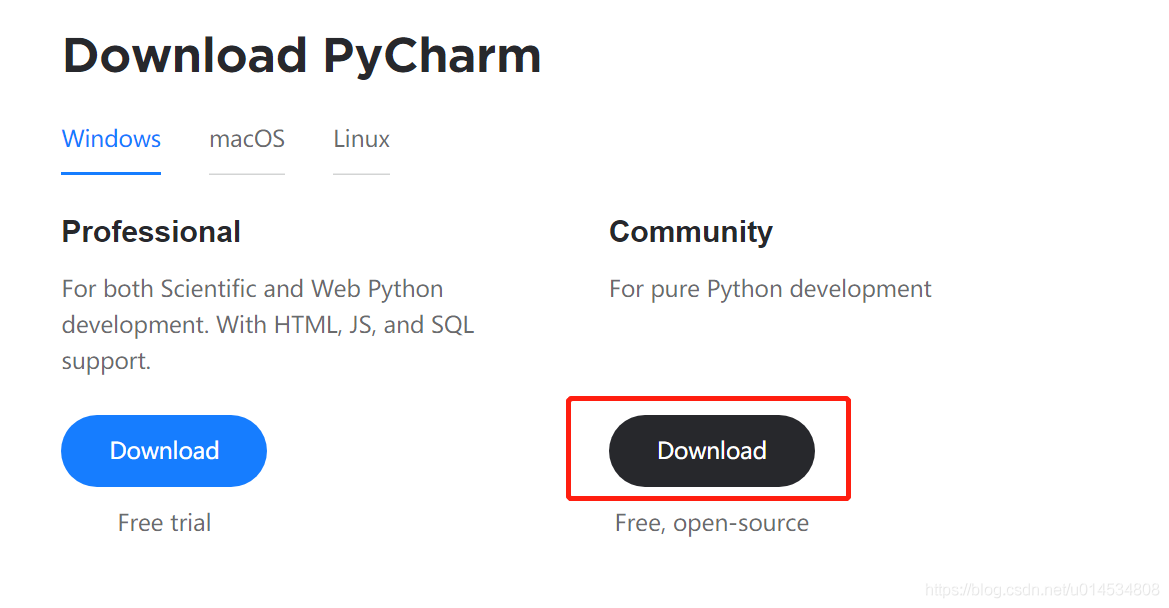
進入下來頁面,PyCharm 有專業版和社區版,其中,專業版需要購買才能使用,而社區版是免費的,社區版對于日常的Python開發完全夠用了,所以我們選擇PyCharm的社區版進行下載安裝,點擊如下圖所示的按鈕進行安裝包的下載,
安裝
安裝包下載好之后,我們雙擊安裝包即可進行安裝,安裝程序比較簡單,基本只需要安裝默認的設定每一步點擊Next按鈕即可,不過當出現下圖的視窗時需要設定一下,
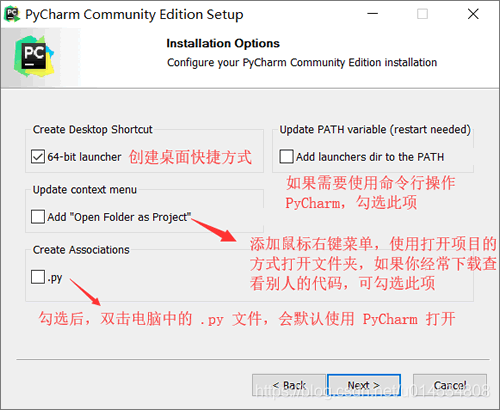
設定好之后點擊 Next 進入下一步的安裝,知道所有的安裝都完成,
使用
這里使用只需要注意一點,就是設定解釋器,默認的話在Project Interpreter的選擇框中是提示的是 No interpreter,即沒有選中解釋器,所以,我們需要手動添加,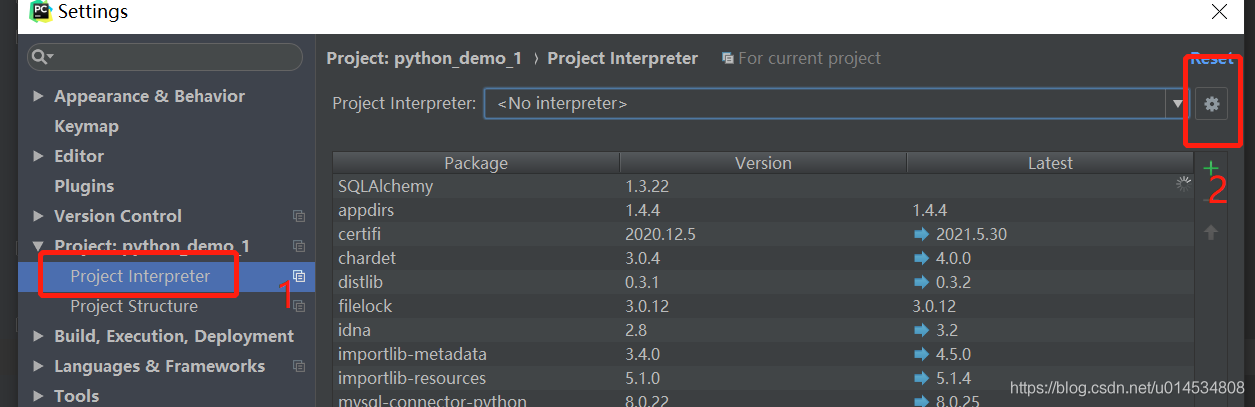
所以需要點擊設定按鈕設定解釋器,這里選擇 Add Local 設定本地的解釋器,
打開解釋器的設定頁面之后,默認選中的是Virtualenv Environment 這個tab頁,
這里Location是用來設定專案的虛擬環境,具體可以參考pycharm的使用小結,設定虛擬環境,更換鏡像源
Base interpreter 用來設定解釋器的路徑,

至此,開發Python的腳手架已經弄好,接下來就是編碼了,
如下創建了一個名為demo_1.py的檔案,然后在檔案中寫入了如下幾行代碼
print("你好,世界")
a = 120
b = 230
print(a + b)
運行這些代碼只需要簡單的右鍵選中 Run 'demo_1' 或者 Debug 'demo_1' ,這兩者的區別是Run demo_1是以普通模式運行代碼,而 Debug 'demo_1' 是以除錯模式運行代碼,
運行結果就是:

詳細內容可以查看【Python從入門到精通】(二)怎么運行Python呢?有哪些好的開發工具
3. 編碼規范&注釋
3.1.注釋
首先介紹的是Python的注釋,Python的注釋分為兩種:單行注釋和多行注釋,
- 單行注釋
Python使用 # 號作為單行注釋的符號,其語法格式為:#注釋內容從#號開始直到這行結束為止的所有內容都是注釋,例如:
# 這是單行注釋
- 多行注釋
多行注釋指一次注釋程式中多行的內容(包含一行) ,Python使用三個連續的 單引號''' 或者三個連續的雙引號""" 注釋多行內容,其語法格式是如下:
'''
三個連續的單引號的多行注釋
注釋多行內容
'''
或者
"""
三個連續的雙引號的多行注釋
注釋多行內容
"""
多行注釋通常用來為Python檔案、模塊、類或者函式等添加著作權或者功能描述資訊(即檔案注釋)
3.2.縮進規則
不同于其他編程語言(如Java,或者C)采用大括號{}分割代碼塊,Python采用代碼縮進和冒號 : 來區分代碼塊之間的層次,如下面的代碼所示:
a = -100
if a >= 0:
print("輸出正數" + str(a))
print('測驗')
else:
print("輸出負數" + str(a))
其中第一行代碼a = -100 和第二行代碼if a >= 0:是在同一作用域(也就是作用范圍相同),所以這兩行代碼并排,而第三行代碼print("輸出正數" + str(a)) 的作用范圍是在第二行代碼里面,所以需要縮進,第五行代碼也是同理,第二行代碼通過冒號和第三行代碼的縮進來區分這兩個代碼塊,
Python的縮進量可以使用空格或者Tab鍵來實作縮進,通常情況下都是采用4個空格長度作為一個縮進量的,
這里需要注意的是同一個作用域的代碼的縮進量要相同,不然會導致IndentationError例外錯誤,提示縮進量不對,如下面代碼所示:第二行代碼print("輸出正數" + str(a)) 縮進了4個空格,而第三行代碼print('測驗')只縮進了2個空格,
if a >= 0:
print("輸出正數" + str(a))
print('測驗')
在Python中,對于類定義,函式定義,流程控制陳述句就像前面的if a>=0:,例外處理陳述句等,行尾的冒號和下一行縮進,表示下一個代碼塊的開始,而縮進的結束則表示此代碼的結束,
詳細內容可以查看【Python從入門到精通】(三)Python的編碼規范,識別符號知多少?
詳細內容可以查看【Python從入門到精通】(四)Python的內置資料型別有哪些呢?數字了解一下
5. 序列
序列(sequence)指的是一塊可存放多個元素的記憶體空間,這些元素按照一定的順序排列,每個元素都有自己的位置(索引),可以通過這些位置(索引)來找到指定的元素,如果將序列想象成一個酒店,那么酒店里的每個房間就相當于序列中的每個元素,房間的編號就相當于元素的索引,可以通過編號(索引)找到指定的房間(元素),
5.1.有哪些序列型別呢?
了解完了序列的基本概念,那么在Python中一共有哪些序列型別呢?如下圖所示:
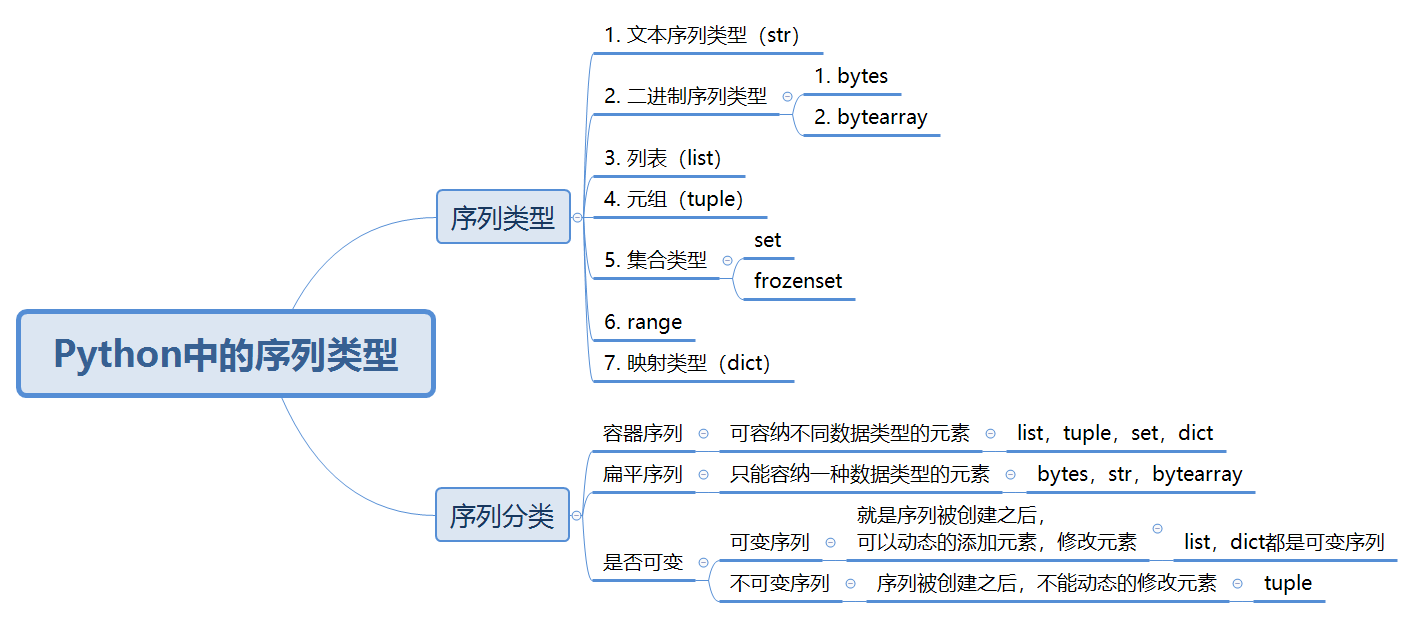
從圖中可以看出在Python中共有7種序列型別,分別是文本序列型別(str);二進制序列型別 bytes和bytearray;串列(list);元組(tuple);集合型別(set和frozenset);范圍型別(range)以及字典型別(dict),
5.2. 按照能存盤的元素劃分
按照能存盤的元素可以將序列型別劃分為兩大類:分別是:容器序列和扁平序列
容器序列:即可容納不同資料型別的元素的序列;有 list;tuple;set;dict
舉個栗子:
list=['runoob',786,2.23,'john',70.2]
這里的list保存的元素有多種資料型別,既有字串,也有小數和整數,
扁平序列:即只能容納相同資料型別的元素的序列;有bytes;str;bytearray,以str為例,同一個str只能都存盤字符,
5.2. 按照是否可變劃分
按照序列是否可變,又可分為可變序列和不可變序列,
這里的可變的意思是:序列創建成功之后,還能不能進行修改操作,比如插入,修改等等,如果可以的話則是可變的序列,如果不可以的話則是不可變序列,
可變序列有串列( list);字典(dict)等,
不可變的序列有元祖(tuple),后面的文章會詳細的對這些資料型別做詳細介紹,
5.3. 序列的索引
在介紹序列概念的時候,說到了序列中元素的索引,那么什么是序列的索引呢?其實就是位置的下標, 如果對C語言中的陣列有所了解的話,我們知道陣列的索引下標都是從0開始依次遞增的正數,即第一個元素的索引下標是0,第n個元素的索引下標是n-1,序列的索引也是同理,默認情況下都是從左向右記錄索引,索引值從0開始遞增,即第一個元素的元素的索引值是0,第n個元素的索引值是n-1,如下圖所示:

當然與C語言中陣列不同的是,Python還支持索引值是負數,該類的索引是從右向左計數,換句話說,就是從最后一個元素開始計數,從索引值-1開始遞減,即第n個元素的索引值是-1,第1個元素的索引值是-n,如下圖所示:

5.4.序列切片
切片操作是訪問序列元素的另一種方式,它可以訪問一定范圍內的元素,通過切片操作,可以生成一個新的序列,切片操作的語法格式是:
sname[start : end : step]
各個引數的含義分別是:
- sname: 表示序列的名稱
- start:表示切片的開始索引位置(包括該位置),此引數也可以不指定,不指定的情況下會默認為0,也就是從序列的開頭開始切片,
- end:表示切片的結束索引位置(不包括該位置),如果不指定,則默認為序列的長度,
- step: 表示步長,即在切片程序中,隔幾個存盤位置(包括當前位置)取一次元素,也就是說,如果step的值大于1,比如step為3時,則在切片取元素時,會隔2個位置去取下一個元素,
還是舉個栗子說明下吧:
str1='好好學習,天天向上'
# 取出索引下標為7的值
print(str1[7])
# 從下標0開始取值,一直取到下標為7(不包括)的索引值
print(str1[0:7])
# 從下標1開始取值,一直取到下標為4(不包括)的索引值,因為step等于2,所以會隔1個元素取值
print(str1[1:4:2])
# 取出最后一個元素
print(str1[-1])
# 從下標-9開始取值,一直取到下標為-2(不包括)的索引值
print(str1[-9:-2])
運行的結果是:
向
好好學習,天天
好習
上
好好學習,天天
5.5.序列相加
Python支持型別相同的兩個序列使用"+"運算子做想加操作,它會將兩個序列進行連接,但是不會去除重復的元素,即只做一個簡單的拼接,
str='他叫小明'
str1='他很聰明'
print(str+str1)
運行結果是:他叫小明他很聰明
5.6.序列相乘
Python支持使用數字n乘以一個序列,其會生成一個新的序列,新序列的內容是原序列被重復了n次的結果,
str2='你好呀'
print(str2*3)
運行結果是:你好呀你好呀你好呀 ,原序列的內容重復了3次,
5.7.檢查元素是否包含在序列中
Python中可以使用in關鍵字檢查某個元素是否為序列中的成員,其語法格式為:
value in sequence
其中,value表示要檢查的元素,sequence表示指定的序列,
舉個栗子:查找天字是否在字串str1中,
str1='好好學習,天天向上'
print('天' in str1)
運行結果是:True
6. 字串
*由若干個字符組成的集合就是一個字串(str)**,Python中的字串必須由雙引號""或者單引號''包圍,其語法格式是:
"字串內容"
'字串內容'
如果字串中包含了單引號需要做特殊處理,比如現在有這樣一個字串
str4='I'm a greate coder' 直接這樣寫有問題的,
處理的方式有兩種:
- 對引號進行轉義,通過轉義符號
\進行轉義即可:
str4='I\'m a greate coder'
- 使用不同的引號包圍字串
str4="I'm a greate coder"
這里外層用雙引號,包裹字串里的單引號,
6.1.字串拼接
通過+運算子
現有字串碼農飛哥好,,要求將字串碼農飛哥牛逼拼接到其后面,生成新的字串碼農飛哥好,碼農飛哥牛逼
舉個例子:
str6 = '碼農飛哥好,'
# 使用+ 運算子號
print('+運算子拼接的結果=',(str6 + '碼農飛哥牛逼'))
運行結果是:
+運算子拼接的結果= 碼農飛哥好,碼農飛哥牛逼
6.2.字串截取(字串切片)
切片操作是訪問字串的另一種方式,它可以訪問一定范圍內的元素,通過切片操作,可以生成一個新的字串,切片操作的語法格式是:
sname[start : end : step]
各個引數的含義分別是:
- sname: 表示字串的名稱
- start:表示切片的開始索引位置(包括該位置),此引數也可以不指定,不指定的情況下會默認為0,也就是從序列的開頭開始切片,
- end:表示切片的結束索引位置(不包括該位置),如果不指定,則默認為序列的長度,
- step: 表示步長,即在切片程序中,隔幾個存盤位置(包括當前位置)取一次元素,也就是說,如果step的值大于1,比如step為3時,則在切片取元素時,會隔2個位置去取下一個元素,
還是舉個栗子說明下吧:
str1='好好學習,天天向上'
# 取出索引下標為7的值
print(str1[7])
# 從下標0開始取值,一直取到下標為7(不包括)的索引值
print(str1[0:7])
# 從下標1開始取值,一直取到下標為4(不包括)的索引值,因為step等于2,所以會隔1個元素取值
print(str1[1:4:2])
# 取出最后一個元素
print(str1[-1])
# 從下標-9開始取值,一直取到下標為-2(不包括)的索引值
print(str1[-9:-2])
運行的結果是:
向
好好學習,天天
好習
上
好好學習,天天
6.3.分割字串
Python提供了split()方法用于分割字串,split() 方法可以實作將一個字串按照指定的分隔符切分成多個子串,這些子串會被保存到串列中(不包含分隔符),作為方法的回傳值反饋回來,該方法的基本語法格式如下:
str.split(sep,maxsplit)
此方法中各部分引數的含義分別是:
- str: 表示要進行分割的字串
- sep: 用于指定分隔符,可以包含多個字符,此引數默認為None,表示所有空字符,包括空格,換行符"\n"、制表符"\t"等
- maxsplit: 可選引數,用于指定分割的次數,最后串列中子串的個數最多為maxsplit+1,如果不指定或者指定為-1,則表示分割次數沒有限制,
在 split 方法中,如果不指定 sep 引數,那么也不能指定 maxsplit 引數,
舉例說明下:
str = 'https://feige.blog.csdn.net/'
print('不指定分割次數', str.split('.'))
print('指定分割次數為2次',str.split('.',2))
運行結果是:
不指定分割次數 ['https://feige', 'blog', 'csdn', 'net/']
指定分割次數為2次 ['https://feige', 'blog', 'csdn.net/']
6.4.合并字串
合并字串與split的作用剛剛相反,Python提供了join() 方法來將串列(或元組)中包含的多個字串連接成一個字串,其語法結構是:
newstr = str.join(iterable)
此方法各部分的引數含義是:
- newstr: 表示合并后生成的新字串
- str: 用于指定合并時的分隔符
- iterable: 做合并操作的源字串資料,允許以串列、元組等形式提供,
依然是舉例說明:
list = ['碼農飛哥', '好好學習', '非常棒']
print('通過.來拼接', '.'.join(list))
print('通過-來拼接', '-'.join(list))
運行結果是:
通過.來拼接 碼農飛哥.好好學習.非常棒
通過-來拼接 碼農飛哥-好好學習-非常棒
6.5.檢索字串是否以指定字串開頭(startswith())
startswith()方法用于檢索字串是否以指定字串開頭,如果是回傳True;反之回傳False,其語法結構是:
str.startswith(sub[,start[,end]])
此方法各個引數的含義是:
- str: 表示原字串
- sub: 要檢索的子串‘
- start: 指定檢索開始的起始位置索引,如果不指定,則默認從頭開始檢索
- end: 指定檢索的結束位置索引,如果不指定,則默認一直檢索到結束,
舉個栗子說明下:
str1 = 'https://feige.blog.csdn.net/'
print('是否是以https開頭', str1.startswith('https'))
print('是否是以feige開頭', str1.startswith('feige', 0, 20))
運行結果是:
是否是以https開頭 True
是否是以feige開頭 False
6.6.檢索字串是否以指定字串結尾(endswith())
endswith()方法用于檢索字串是否以指定字串結尾,如果是則回傳True,反之則回傳False,其語法結構是:
str.endswith(sub[,start[,end]])
此方法各個引數的含義與startswith方法相同,再此就不在贅述了,
6.7.字串大小寫轉換(3種)函式及用法
Python中提供了3種方法用于字串大小寫轉換
- title()方法用于將字串中每個單詞的首字母轉成大寫,其他字母全部轉為小寫,轉換完成后,此方法會回傳轉換得到的字串,如果字串中沒有需要被轉換的字符,此方法會將字串原封不動地回傳,其語法結構是
str.title() - lower()用于將字串中的所有大寫字母轉換成小寫字母,轉換完成后,該方法會回傳新得到的子串,如果字串中原本就都是小寫字母,則該方法會回傳原字串, 其語法結構是
str.lower() - upper()用于將字串中的所有小寫字母轉換成大寫字母,如果轉換成功,則回傳新字串;反之,則回傳原字串,其語法結構是:
str.upper(),
舉例說明下吧:
str = 'feiGe勇敢飛'
print('首字母大寫', str.title())
print('全部小寫', str.lower())
print('全部大寫', str.upper())
運行結果是:
首字母大寫 Feige勇敢飛
全部小寫 feige勇敢飛
全部大寫 FEIGE勇敢飛
6.8.去除字串中空格(洗掉特殊字符)的3種方法
Python中提供了三種方法去除字串中空格(洗掉特殊字符)的3種方法,這里的特殊字符,指的是指表符(\t)、回車符(\r),換行符(\n)等,
- strip(): 洗掉字串前后(左右兩側)的空格或特殊字符
- lstrip():洗掉字串前面(左邊)的空格或特殊字符
- rstrip():洗掉字串后面(右邊)的空格或特殊字符
Python的str是不可變的,因此這三個方法只是回傳字串前面或者后面空白被洗掉之后的副本,并不會改變字串本身
舉個例子說明下:
str = '\n碼農飛哥勇敢飛 '
print('去除前后空格(特殊字串)', str.strip())
print('去除左邊空格(特殊字串)', str.lstrip())
print('去除右邊空格(特殊字串)', str.rstrip())
運行結果是:
去除前后空格(特殊字串) 碼農飛哥勇敢飛
去除左邊空格(特殊字串) 碼農飛哥勇敢飛
去除右邊空格(特殊字串)
碼農飛哥勇敢飛
6.9.encode()和decode()方法:字串編碼轉換
最早的字串編碼是ASCll編碼,它僅僅對10個數字,26個大小寫英文字母以及一些特殊字符進行了編碼,ASCII碼最多只能表示256個字符,每個字符只需要占用1個位元組,為了兼容各國的文字,相繼出現了GBK,GB2312,UTF-8編碼等,UTF-8是國際通用的編碼格式,它包含了全世界所有國家需要用到的字符,其規定英文字符占用1個位元組,中文字符占用3個位元組,
- encode() 方法為字串型別(str)提供的方法,用于將 str 型別轉換成 bytes 型別,這個程序也稱為“編碼”,其語法結構是:
str.encode([encoding="utf-8"][,errors="strict"]) - 將bytes型別的二進制資料轉換成str型別,這個程序也稱為"解碼",其語法結構是:
bytes.decode([encoding="utf-8"][,errors="strict"])
舉個例子說明下:
str = '碼農飛哥加油'
bytes = str.encode()
print('編碼', bytes)
print('解碼', bytes.decode())
運行結果是:
編碼 b'\xe7\xa0\x81\xe5\x86\x9c\xe9\xa3\x9e\xe5\x93\xa5\xe5\x8a\xa0\xe6\xb2\xb9'
解碼 碼農飛哥加油
默認的編碼格式是UTF-8,編碼和解碼的格式要相同,不然會解碼失敗,
6.9.序列化和反序列化
在實際作業中我們經常要將一個資料物件序列化成字串,也會將一個字串反序列化成一個資料物件,Python自帶的序列化模塊是json模塊,
- json.dumps() 方法是將Python物件轉成字串
- json.loads()方法是將已編碼的 JSON 字串解碼為 Python 物件
舉個例子說明下:
import json
dict = {'學號': 1001, 'name': "張三", 'score': [{'語文': 90, '數學': 100}]}
str = json.dumps(dict,ensure_ascii=False)
print('序列化成字串', str, type(str))
dict2 = json.loads(str)
print('反序列化成物件', dict2, type(dict2))
運行結果是:
序列化成字串 {"name": "張三", "score": [{"數學": 100, "語文": 90}], "學號": 1001} <class 'str'>
反序列化成物件 {'name': '張三', 'score': [{'數學': 100, '語文': 90}], '學號': 1001} <class 'dict'>
詳細內容可以查看
【Python從入門到精通】(五)Python內置的資料型別-序列和字串,沒有女友,不是保姆,只有拿來就能用的干貨
【Python從入門到精通】(九)Python中字串的各種騷操作你已經爛熟于心了么?【收藏下來就挺好的】
7. 串列&元組
7.1.串列(list)的介紹
串列作為Python序列型別中的一種,其也是用于存盤多個元素的一塊記憶體空間,這些元素按照一定的順序排列,其資料結構是:
[element1, element2, element3, ..., elementn]
element1~elementn表示串列中的元素,元素的資料格式沒有限制,只要是Python支持的資料格式都可以往里面方,同時因為串列支持自動擴容,所以它可變序列,即可以動態的修改串列,即可以修改,新增,洗掉串列元素,看個爽圖吧!
7.2.串列的操作
首先介紹的是對串列的操作:包括串列的創建,串列的洗掉等!其中創建一個串列的方式有兩種:
第一種方式:
通過[]包裹串列中的元素,每個元素之間通過逗號,分割,元素型別不限并且同一串列中的每個元素的型別可以不相同,但是不建議這樣做,因為如果每個元素的資料型別都不同的話則非常不方便對串列進行遍歷決議,所以建議一個串列只存同一種型別的元素,
list=[element1, element2, element3, ..., elementn]
例如:test_list = ['測驗', 2, ['碼農飛哥', '小偉'], (12, 23)]
PS: 空串列的定義是list=[]
第二種方式:
通過list(iterable)函式來創建串列,list函式是Python內置的函式,該函式傳入的引數必須是可迭代的序列,比如字串,串列,元組等等,如果iterable傳入為空,則會創建一個空的串列,iterable不能只傳一個數字,
classmates1 = list('碼農飛哥')
print(classmates1)
生成的串列是:['碼', '農', '飛', '哥']
7.3. 向串列中新增元素
向串列中新增元素的方法有四種,分別是:
第一種: 使用+運算子將多個串列連接起來,相當于在第一個串列的末尾添加上另一個串列,其語法格式是listname1+listname2
name_list = ['碼農飛哥', '小偉', '小小偉']
name_list2 = ['python', 'java']
print(name_list + name_list2)
輸出結果是:['碼農飛哥', '小偉', '小小偉', 'python', 'java'],可以看出將name_list2中的每個元素都添加到了name_list的末尾,
第二種:使用append()方法添加元素
append()方法用于向串列末尾添加元素,其語法格式是:listname.append(p_object)其中listname表示要添加元素的串列,p_object表示要添加到串列末尾的元素,可以是字串,數字,也可以是一個序列,舉個栗子:
name_list.append('Adam')
print(name_list)
name_list.append(['test', 'test1'])
print(name_list)
運行結果是:
['碼農飛哥', '小偉', '小小偉', 'Adam']
['碼農飛哥', '小偉', '小小偉', 'Adam', ['test', 'test1']]
可以看出待添加的元素都成功的添加到了原串列的末尾處,并且當添加的元素是一個序列時,則會將該序列當成一個整體,
第三種:使用extend()方法
extend()方法跟append()方法的用法相同,同樣是向串列末尾添加元素,元素的型別只需要Python支持的資料型別即可,不過與append()方法不同的是,當添加的元素是序列時,extend()方法不會將串列當成一個整體,而是將每個元素添加到串列末尾,還是上面的那個例子:
name_list = ['碼農飛哥', '小偉', '小小偉']
name_list.extend('Adam')
print(name_list)
name_list.extend(['test', 'test1'])
print(name_list)
運行結果是:
['碼農飛哥', '小偉', '小小偉', 'A', 'd', 'a', 'm']
['碼農飛哥', '小偉', '小小偉', 'A', 'd', 'a', 'm', 'test', 'test1']
從結果看出,當添加字串時會將字串中的每個字符作為一個元素添加到串列的末尾處,當添加的串列時會將串列中的每個元素添加到末尾處,
第四種:使用insert()方法
前面介紹的幾種插入方法,都只能向串列的末尾處插入元素,如果想在串列指定位置插入元素則無能為力,insert()方法正式用于處理這種問題而來的,其語法結構是listname.insert(index, p_object) 其中index表示指定位置的索引值,insert()會將p_object插入到listname串列第index個元素的位置,與append()方法相同的是,如果待添加的元素的是序列,則insert()會將該序列當成一個整體插入到串列的指定位置處,舉個栗子:
name_list = ['碼農飛哥', '小偉', '小小偉']
name_list.insert(1, 'Jack')
print(name_list)
name_list.insert(2, ['test', 'test1'])
print(name_list)
運行結果是:
['碼農飛哥', 'Jack', '小偉', '小小偉']
['碼農飛哥', 'Jack', ['test', 'test1'], '小偉', '小小偉']
7.4. 修改串列中的元素
說完了串列中元素新增的方法,接著讓我們來看看修改串列中的元素相關的方法,修改串列元素的方法有兩種:
第一種:修改單個元素:
修改單個元素的方法就是對某個索引上的元素進行重新賦值,其語法結構是:listname[index]=newValue,就是將串列listname中索引值為index位置上的元素替換成newValue,
舉個栗子:
name_list = ['碼農飛哥', '小偉', '小小偉']
name_list[1] = 'Sarah'
print(name_list)
運行結果:['碼農飛哥', 'Sarah', '小小偉'] 從結果可以看出索引為1處的元素值被成功修改成了Sarch,
第二種:通過切片語法修改一組元素
通過切片語法可以修改一組元素,其語法結構是:listname[start:end:step],其中,listname表示串列名稱,start表示起始位置,end表示結束位置(不包括),step表示步長,如果不指定步長,Python就不要求新賦值的元素個數與原來的元素個數相同,這意味著,該操作可以為串列添加元素,也可以為串列洗掉元素,舉個栗子:
name_list = ['碼農飛哥', '小偉', '小小偉']
name_list[0:1] = ['飛哥', '牛逼']
print(name_list)
運行結果是:['飛哥', '牛逼', '小偉', '小小偉'] ,從結果可以看出將原串列中索引為0處的元素值已經被替換為飛哥,并且插入了牛逼 這個元素,
7.5. 洗掉串列中的元素
洗掉串列中元素的方法共有四種,
第一種:根據索引值洗掉元素的del關鍵字
根據索引值洗掉元素的del關鍵字有兩種形式,一種是洗掉單個元素,del listname[index],一種是根據切片洗掉多個元素del listname[start : end],其中,listname表示串列名稱,start表示起始索引,end表示結束索引,del會洗掉從索引start到end之間的元素,但是不包括end位置的元素,還是舉個栗子:
name_list = ['碼農飛哥', '小偉', '小小偉', '超人']
name_list2 = name_list
print('原始的name_list={0}'.format(name_list))
print('原始的name_list2={0}'.format(name_list2))
# 洗掉索引0到2之間的元素,即洗掉索引0和索引1兩個位置的元素
del name_list[0:2]
print('使用del洗掉元素后name_list={0}'.format(name_list))
print('使用del洗掉元素后name_list2={0}'.format(name_list2))
del name_list
print('使用del洗掉串列后name_list2={0}'.format(name_list2))
運行結果是:
原始的name_list=['碼農飛哥', '小偉', '小小偉', '超人']
原始的name_list2=['碼農飛哥', '小偉', '小小偉', '超人']
使用del洗掉元素后name_list=['小小偉', '超人']
使用del洗掉元素后name_list2=['小小偉', '超人']
使用del洗掉串列后name_list2=['小小偉', '超人']
可以看出用del洗掉串列元素時是真實的洗掉了記憶體資料的,但是用del洗掉串列時,則只是洗掉了變數,name_list2所指向的記憶體資料還是存在的,
第二種:根據索引值洗掉元素的pop()方法
根據索引值洗掉元素的pop()方法的語法結構是:listname.pop(index),其中,listname表示串列名稱,index表示索引值,如果不寫index引數,默認會洗掉串列中最后一個元素,類似于資料結構中的出堆疊操作,舉個例子:
name_list = ['碼農飛哥', '小偉', '小小偉', '超人']
# 洗掉list末尾的元素
name_list.pop()
print(name_list)
# 洗掉指定位置的元素,用pop(i)方法,其中i是索引位置
name_list.pop(1)
print(name_list)
運行結果是:
['碼農飛哥', '小偉', '小小偉']
['碼農飛哥', '小小偉']
第三種:根據元素值進行洗掉的remove()方法
根據元素值進行洗掉的remove()方法,其語法結構是:listname.remove(object),其中listname表示串列的名稱,object表示待洗掉的元素名稱,需要注意的是:如果元素在串列中不存在則會報ValueError的錯誤,舉個栗子:
name_list = ['碼農飛哥', '小偉', '小小偉', '超人']
name_list.remove('小小偉')
print(name_list)
運行結果是:['碼農飛哥', '小偉', '超人'],
第四種:洗掉串列中的所有元素clear()方法
通過clear()方法可以洗掉掉串列中的所有元素,其語法結構是:listname.clear(),其中listname表示串列的名稱,還是舉個栗子吧:
name_list = ['碼農飛哥', '小偉', '小小偉', '超人']
name_list.clear()
print(name_list)
運行結果是:[],可以看出串列中元素被全部清空了,
7.6.串列中元素的查找以及訪問
說完了第五淺串列元素的洗掉,略感疲憊,接著進行第六淺吧!看看串列中元素的查找以及訪問,看完這個之后,串列相關的內容也就告一段落了,
訪問串列中的元素
訪問串列中的元素有兩種方式,分別是通過索引定位訪問單個元素,通過切片訪問多個元素,
第一種:通過索引定位訪問單個元素,其語法結構是:listname[index] ,其中listname表示串列的名字,index表示要查找元素的索引值,
第二種:通過切片的方式訪問多個元素,其語法結構是:listname[start:end:step],其中,listname表示串列的名字,start表示開始索引,end表示結束索引(不包括end位置),step表示步長,同樣是舉個栗子:
list2 = ['碼農飛哥', '小偉', '小小偉',123]
print(list2[0]) # 輸出串列的第一個元素
print(list2[1:3]) # 輸出第二個至第三個元素
print(list2[2:]) # 輸出從第三個開始至串列末尾的所有元素
運行結果是:
碼農飛哥
['小偉', '小小偉']
['小小偉', 123]
查找某個元素在串列中出現的位置 index()
indext()方法用來查找某個元素在串列中出現的位置(也就是索引),如果該元素在串列中不存在,則會報ValueError錯誤,其語法結構是:listname.index(object, start, end) 其中listname表示串列的名字,object表示要查找的元素,start表示起始索引,end表示結束索引(不包括),
name_list = ['碼農飛哥', '小偉', '小小偉', '超人']
print(name_list.index('小偉', 0, 2))
運行結果是:1
7.8. Python新增元素中各個方法的區別
前面介紹了使用+運算子,使用append方法,使用extend方法都可以新增元素,那么他們到底有啥區別呢?還是舉例說明吧;
name_list = ['碼農飛哥', '小偉', '小小偉', '超人']
name_list2 = ['牛魔王']
name_list3 = name_list + name_list2
print("原始的name_list的值={0};記憶體地址={1}".format(name_list, id(name_list)))
print("使用+運算子后name_list3的值={0};記憶體地址={1}".format(name_list3, id(name_list3)))
print("使用+運算子后name_list的值{0};記憶體地址={1}".format(name_list, id(name_list)))
name_list4 = name_list.append('牛魔王')
print('使用append方法后name_list4的值={0};記憶體地址={1}'.format(name_list4, id(name_list4)))
print("使用append方法后name_list的值{0};記憶體地址={1}".format(name_list, id(name_list)))
name_list5 = name_list.extend('牛魔王')
print('使用extend方法后name_list5的值={0};記憶體地址={1}'.format(name_list4, id(name_list4)))
print("使用extend方法后name_list的值{0};記憶體地址={1}".format(name_list, id(name_list)))
運行結果是:
原始的name_list的值=['碼農飛哥', '小偉', '小小偉', '超人'];記憶體地址=2069467533448
使用+運算子后name_list3的值=['碼農飛哥', '小偉', '小小偉', '超人', '牛魔王'];記憶體地址=2069467533896
使用+運算子后name_list的值['碼農飛哥', '小偉', '小小偉', '超人'];記憶體地址=2069467533448
使用append方法后name_list4的值=None;記憶體地址=2012521616
使用append方法后name_list的值['碼農飛哥', '小偉', '小小偉', '超人', '牛魔王'];記憶體地址=2069467533448
使用extend方法后name_list5的值=None;記憶體地址=2012521616
使用extend方法后name_list的值['碼農飛哥', '小偉', '小小偉', '超人', '牛魔王', '牛', '魔', '王'];記憶體地址=2069467533448
從運行結果可以看出如下幾點:
- 使用+運算子是創建一個新的串列,新串列的地址與原串列的地址不相同,并且原始串列的內容不會改變,
- append方法和extend方法都是修改原始串列的內容,并且都沒有回傳值,所以兩者都不能使用鏈式運算式,
- 當待添加的元素是串列時,append方法會將串列當成一個整體,而extend不會,
8. 元組(tuple)
8.1. 元組(tuple)的介紹
說完了串列,接著讓我們來看看另外一個重要的序列--元組(tuple),和串列類似,元組也是由一系列按特定書序排序的元素組成,與串列最重要的區別是,元組屬于不可變序列,即元組一旦被創建,它的元素就不可更改了,
8.2.元組的創建方式
第一種:使用()直接創建
使用()創建元組的語法結構是tuplename=(element1,element2,....,elementn),其中tuplename表示元組的變數名,element1~elementn表示元組中的元素,小括號不是必須的,只要將元素用逗號分隔,Python就會將其視為元組,還是舉個栗子:
#創建元組
tuple_name = ('碼農飛哥', '小偉', '小小偉', '超人')
print(tuple_name)
#去掉小括號創建元組
tuple2 = '碼農飛哥', '小偉', '小小偉', '超人'
print(type(tuple2))
運行結果是:
('碼農飛哥', '小偉', '小小偉', '超人')
<class 'tuple'>
第二種:使用tuple()函式創建
與串列類似的,我們可以通過tuple(iterable)函式來創建元組,如果iterable傳入為空,則創建一個空的元組,iterable 引數必須是可迭代的序列,比如字串,串列,元組等,同樣的iterable不能傳入一個數字,舉個栗子:
name_list = ['碼農飛哥', '小偉', '小小偉', '超人']
print(tuple(name_list))
print(tuple('碼農飛哥'))
運行結果是:
('碼農飛哥', '小偉', '小小偉', '超人')
('碼', '農', '飛', '哥')
由于元組是不可變序列,所以沒有修改元素相關的方法,只能對元組中的元素進行查看,查看元素的方式也與串列類似,共兩種方式:
第一種:通過索引(index)訪問元組中的元素,其語法結構是tuplename[index]
第二種:通過切片的方式訪問,其語法結構是:tuplename[start:end:step]
相關引數的描述在此不再贅述了,依然是舉例說明:
tuple_name = ('碼農飛哥', '小偉', '小小偉', '超人')
# 獲取索引為1的元素值
print(tuple_name[1])
#獲取索引為1到索引為2之間的元素值,不包括索引2本身
print(tuple_name[0:2])
運行結果是:
小偉
('碼農飛哥', '小偉')
元組中的元素不能修改,不過可以通過 + 來生成一個新的元組,
詳細內容可以查看【Python從入門到精通】(六)Python內置的資料型別-串列(list)和元組(tuple),九淺一深,十個章節,不信你用不到
9.字典
9.1.創建一個字典
創建字典的方式有很多種,下面羅列幾種比較常見的方法,
第一種:使用 {} 符號來創建字典,其語法結構是dictname={'key1':'value1', 'key2':'value2', ..., 'keyn':valuen}
第二種:使用fromkeys方法,其語法結構是dictname = dict.fromkeys(list,value=https://www.cnblogs.com/Fly-Bob/p/None), 其中,list引數表示字典中所有鍵的串列(list),value引數表示默認值,如果不寫則為所有的值都為空值None,
第三種:使用dict方法,其分為四種情況:
- dict() -> 創建一個空字典
- dict(mapping) -> 創建一個字典,初始化時其鍵值分別來自于mapping中的key,value,
- dict(iterable) -> 創建一個字典,初始化時會遍歷iterable得到其鍵值,
for k, v in iterable:
d[k] = v
dict(**kwargs)->**kwargs是可變函式,其呼叫的語法格式是:dict(key1=value1,key2=value2,...keyn=valuen),例如:dict(name='碼農飛哥', age=17, weight=63)
這三種創建字典的方式都介紹完了,下面就來看看示例說明吧:
#1. 創建字典
d = {'name': '碼農飛哥', 'age': 18, 'height': 185}
print(d)
list = ['name', 'age', 'height']
# 2. fromkeys方法
dict_demo = dict.fromkeys(list)
dict_demo1 = dict.fromkeys(list, '測驗')
print(dict_demo)
print(dict_demo1)
# 通過dict()映射創建字典,傳入串列或者元組
demo = [('name', '碼農飛哥'), ('age', 19)]
dict_demo2 = dict(demo)
print(dict_demo2)
dict_demo21 = dict(name='碼農飛哥', age=17, weight=63)
print(dict_demo21)
運行結果是:
{'name': '碼農飛哥', 'age': 18, 'height': 185}
{'name': None, 'age': None, 'height': None}
{'name': '測驗', 'age': '測驗', 'height': '測驗'}
{'name': '碼農飛哥', 'age': 19}
{'name': '碼農飛哥', 'age': 17, 'weight': 63}
9.2.字典的訪問
說完了字典的創建之后,接著就讓我們來看看字典的訪問,字典不同于串列和元組,字典中的元素不是依次存盤在記憶體區域中的;所以,字典中的元素不能通過索引來訪問,只能是通過鍵來查找對應的值, ,其有兩種不同的寫法,
- 第一種方式的語法格式是
dictname[key],其中dictname表示字典的名稱,key表示指定的鍵,如果指定的鍵不存在的話,則會報KeyError 錯誤, - 第二種方式的語法格式是
dictname.get(key),其中dictname表示字典的名稱,key表示指定的鍵,如果指定的鍵不存在的話,則會回傳None,
舉個栗子說明下吧,下面代碼的意思是根據鍵名為name查找其對應的值,
dict_demo5 = {'name': '碼農飛哥', 'age': 18, 'height': 185}
print(dict_demo5['name'])
print(dict_demo5.get('name'))
print('鍵不存在的情況回傳結果=',dict_demo5.get('test'))
運行結果是:
碼農飛哥
碼農飛哥
鍵不存在的情況回傳結果= None
9.3.添加和修改鍵值對
添加鍵值對的方法很簡單,其語法結構是dictname[key]=value,如果key在字典中不存在的話,則會新增一個鍵值對,如果key在字典中存在的話,則會更新原來鍵所對應的值,依然是舉例說明下:本例中代碼的結果是增加鍵值對 sex='男',把鍵height對應的值改成了190,
# 添加鍵值對
dict_demo6 = {'name': '碼農飛哥', 'age': 18, 'height': 185}
dict_demo6['sex'] = '男'
print('新增鍵值對的結果={0}'.format(dict_demo6))
# 修改鍵值對
dict_demo6['height'] = 190
print('修改鍵值對的結果={0}'.format(dict_demo6))
運行結果是:
新增鍵值對的結果={'age': 18, 'name': '碼農飛哥', 'height': 185, 'sex': '男'}
修改鍵值對的結果={'age': 18, 'name': '碼農飛哥', 'height': 190, 'sex': '男'}
當然修改和洗掉鍵值對也可以通過update方法來實作,其具體的語法格式是:dictname.update(dict) ,其中,dictname為字典的名稱,dict為要修改的字典的值,該方法既可以新增鍵值對,也可以修改鍵值對, 該方法沒有回傳值,即是在原字典上修改元素的,下面例子中就是將鍵name的值改成了飛飛1024,鍵age對應的值改成了25,并新增了鍵值對 like=學習,
# update方法
dict_demo7 = {'name': '碼農飛哥', 'age': 18, 'height': 185, 'width': 100}
dict_demo7.update({'name': '飛飛1024', 'age': 25, 'like': '學習'})
print('update方法回傳結果={}', dict_demo7)
運行結果為:
update方法回傳結果={} {'height': 185, 'like': '學習', 'width': 100, 'name': '飛飛1024', 'age': 25}
9.4.洗掉鍵值對
洗掉鍵值對的方法有三種:
- 第一種是
del dictname[key],使用del關鍵字,其中dictname為字典的名稱,key為要洗掉的鍵,如果鍵不存在的話則會報KeyError錯誤, - 第二種方式是通過pop方法,其語法結構是:
dictname.pop(key),該方法是用于洗掉指定鍵值對,沒有回傳值,如果key不存在的話不會報錯, - 第三種方式是通過popitem方法,其語法結構是:
dictname.popitem(),該方法用于洗掉字典中最后一個鍵值對,舉例說明下吧:
dict_demo10 = {'name': '碼農飛哥', 'age': 18, 'height': 185, 'width': 100}
# 洗掉鍵值對
del dict_demo6['height']
print('洗掉鍵height對之后的結果=', dict_demo6)
# pop()方法和popitem()方法
dict_demo10.pop('width')
print('pop方法呼叫洗掉鍵width之后結果=', dict_demo10)
dict_demo10 = {'name': '碼農飛哥', 'age': 18, 'height': 185, 'width': 100}
dict_demo10.popitem()
print('popitem方法呼叫之后結果=', dict_demo10)
運行結果是:
洗掉鍵height對之后的結果= {'name': '碼農飛哥', 'sex': '男', 'age': 18}
pop方法呼叫洗掉鍵width之后結果= {'name': '碼農飛哥', 'height': 185, 'age': 18}
popitem方法呼叫之后結果= {'name': '碼農飛哥', 'age': 18, 'height': 185}
可以看出popitem方法洗掉的鍵是最后一個鍵width,
詳細內容可以查看【Python從入門到精通】(七)Python字典(dict)讓人人都能找到自己的另一半(鍵值對,成雙成對)
10. 推導式&生成器
10.1.range快速生成串列推導式
串列推導式的語法格式是
[運算式 for 迭代變數 in 可迭代物件 [if 條件運算式] ]
此格式中,[if 條件運算式]不是必須的,可以使用,也可以省略,下面就是輸出1~10的串列的乘積的一個例子:
L = [x * x for x in range(1, 11)]
print(L)
此運算式相當于
L = []
for x in range(1, 11):
L.append(x * x)
print(L)
運行結果是:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
來點復雜的吧,下面就是輸出
print([x for x in range(1, 11) if x % 2 == 0])
運行結果是[2, 4, 6, 8, 10]
再來點復雜的,使用多個回圈,生成推導式,
d_list = [(x, y) for x in range(5) for y in range(4)]
print(d_list)
運行結果是:
[(0, 0), (0, 1), (0, 2), (0, 3), (1, 0), (1, 1), (1, 2), (1, 3), (2, 0), (2, 1), (2, 2), (2, 3), (3, 0), (3, 1), (3, 2), (3, 3), (4, 0), (4, 1), (4, 2), (4, 3)]
上面代碼,x是遍歷range(5)的迭代變數(計數器),因此該x可迭代5次,y是遍歷range(4)的計數器,因此該y可迭代4次,因此,該(x,y)運算式一共迭代了20次,它相當于下面這樣一個嵌套運算式,
dd_list = []
for x in range(5):
for y in range(4):
dd_list.append((x, y))
print(dd_list)
10.2.range快速生成元組推導式
元組推導式與串列推導式類似,其語法結構是:
(運算式 for 迭代變數 in 可迭代物件 [if 條件運算式] )
此格式中,[if 條件運算式]不是必須的,可以使用,也可以省略,下面就是輸出1~10的元組的乘積的一個例子:
d_tuple = (x * x for x in range(1, 11))
print(d_tuple)
運行結果是:
<generator object <genexpr> at 0x103322e08>
從上面的執行結果可以看出,使用元組推導式生成的結果并不是一個元組,而是一個生成器物件,
使用tuple()函式,可以直接將生成器物件轉換成元組,例如:
d_tuple = (x * x for x in range(1, 11))
print(tuple(d_tuple))
輸出結果是(1, 4, 9, 16, 25, 36, 49, 64, 81, 100)
10.4. 字典推導式
字典推導式的語法結構是:
{運算式 for 迭代變數 in 可迭代物件 [if 條件運算式]}
其中[if 條件運算式]可以使用,也可以省略,舉個例子:
key_list = ['姓名:碼農飛哥', '年齡:18', '愛好:寫博客']
test_dict = {key.split(':')[0]: key.split(':')[1] for key in key_list}
print(test_dict)
運行結果是:
{'愛好': '寫博客', '年齡': '18', '姓名': '碼農飛哥'}
10.5.生成器另外一種方式 yield
通過yield關鍵字配合回圈可以做一個生成器,就像下面這樣
def generate():
a = 2
while True:
a += 1
yield a
b = generate()
print(b)
print(next(b))
print(next(b))
print(next(b))
運行結果
<generator object generate at 0x7fc01af19b30>
3
4
5
這里generate方法回傳的就是一個生成器物件generator,因為它內部使用了yield關鍵字,
呼叫一次next()方法回傳一個生成器中的結果,這就很像單例模式中的懶漢模式,他并并不像餓漢模式一樣事先將串列資料生成好,
11. 判斷以及回圈
11.1. 流程控制
流程控制有三種結構,一種是順序結構,一種是選擇(分支)結構,一種是回圈結構,
順序結構:就是讓程式按照從頭到尾的順序執行代碼,不重復執行任何一行代碼,也不跳過任何一行代碼,一步一個腳印表示的就是這個意思,
選擇(分支)結構:就是讓程式根據不同的條件執行不同的代碼,比如:根據年齡判斷某個人是否是成年人,
回圈結構: 就是讓程式回圈執行某一段代碼,順序的流程這里不做介紹了,
11.2. 選擇結構(if,else):
if陳述句
只使用if陳述句是Python中最簡單的形式,如果滿足條件則執行運算式,則跳過運算式的執行,其偽代碼是:
if 條件為真:
代碼塊
如果if 后面的條件為真則執行代碼塊,否則則跳過代碼的執行,
其流程圖是:
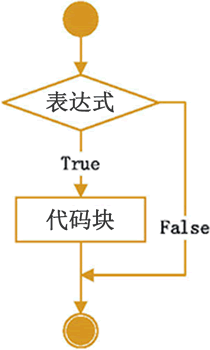
就是說只使用if的話,則運算式成立的話執行代碼塊,不成立的話就結束,
下面就是一個簡單的例子,如果滿足a==1這個條件則列印a,否則跳過該陳述句,
a = 1
if a == 1:
print(a)
if else陳述句
if else陳述句是if的變體,如果滿足條件的話則執行代碼塊1,否則則執行代碼塊2,其偽代碼是:
if 條件為真:
代碼塊1
else
代碼塊2
流程圖是:
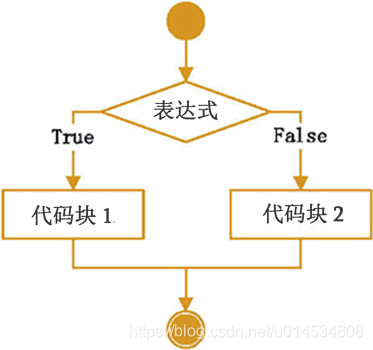
同時使用if和else的話,則運算式成立的話執行一個代碼塊,運算式不成立的話則執行另一個代碼塊,
舉個簡單的例子吧,
age = 3
if age >= 18:
print('your age is', age)
print('adult')
else:
print("your age is", age)
print('kid')
根據輸入的年齡判斷某人是否是成年人,如果age大于等于18歲,則輸出adult,否則輸出kid,
if elif else陳述句
if elif else陳述句針對的就是多個條件判斷的情況,如果if條件不滿足則執行elif的條件,如果elif的條件也不滿足的話,則執行else里面的運算式,其偽代碼是:
if 條件為真:
運算式a
elif 條件為真:
運算式b
....
elif 條件為真:
表達是n-1
else
運算式n
其中elif可以有多個,但是elif不能單獨使用,必須搭配if和else一起使用,
需要注意的是if,elif和else后面的代碼塊一定要縮進,而且縮進量要大于if,elif和else本身,建議的縮進量是4個空格,同一代碼中所有陳述句都要有相同的縮進, 依然是舉例說明:
bmi = 80.5 / (1.75 * 1.75)
if bmi < 18.5:
print('過輕')
elif 18.5 <= bmi < 25:
print('正常')
elif 25 <= bmi < 28:
print('過重')
elif 28 <= bmi < 32:
print('肥胖')
else:
print('嚴重肥胖')
pass
下面就是根據bmi標準來判斷一個人是過輕,正常還是肥胖,pass是Python中的關鍵字,用來讓解釋器跳過此處,什么都不做,
11.3. while回圈陳述句詳解
while是作為回圈的一個關鍵字,其偽代碼是:
while 條件運算式:
代碼塊
一定要保證回圈條件有變成假的時候,否則這個回圈將成為一個死回圈,即該回圈無法結束, 其流程圖是:
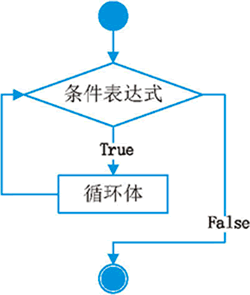
如果while中的運算式成立的話則執行回圈體,否則的話則直接結束,
舉個栗子:計算從1~100的求和,這就是一個經典的運用回圈的場景
sum = 0
n = 1
while n <= 100:
sum = sum + n
n = n + 1
print('sum=', sum)
運行結果是sum= 5050,這個回圈的結束條件是n>100,也就是說當n>100是會跳出回圈,
11.4.for回圈
在介紹range函式時用到了for關鍵字,這里介紹一下for關鍵字的使用,其語法結構是:
for 迭代變數 in 字串|串列|元組|字典|集合:
代碼塊
字串,串列,元祖,字典,集合都可以還用for來迭代,其流程圖是:
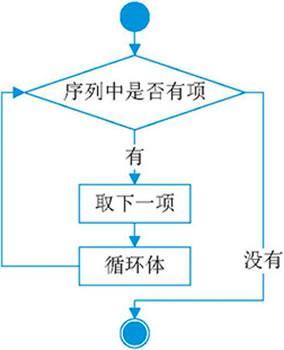
for 回圈就是:首先根據in 關鍵字判斷序列中是否有項,如果有的話則取下一項,接著執行回圈體,如果沒有的話則直接結束回圈,
詳細內容可以查看【Python從入門到精通】(十)Python流程控制的關鍵字該怎么用呢?串列推導式,生成器【收藏下來,常看常新】
總結
至此Python的基礎內容已經全部介紹完了,
干貨太多,編輯器都有點卡頓了,
還是那句話,收藏下來邁出了學習的第一步,
B站的小姐姐看一千遍還是別人的,C站的文章看一遍就是自己的了,
干貨握在手,妹子跟你走,
我是碼農飛哥,再次感謝您讀完本文,
需要原始碼的小伙伴關注下方公眾號,回復【python】
全網同名【碼農飛哥】,不積跬步,無以至千里,享受分享的快樂
我是碼農飛哥,再次感謝您讀完本文,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/331962.html
標籤:Python