二分查找
- Ⅰ 前言
- Ⅱ 無處不在的二分思想
- Ⅲ 二分查找的速度
- Ⅳ 二分查找的遞回與非遞回實作
- 1. 非遞回實作
- 2. 遞回實作
- Ⅴ 二分查找應用場景的局限性
- 1. 資料結構
- 2. 排列方式
- 3. 資料規模
- Ⅵ 進階——二分查找的變形
- 1. 查找第一個值等于給定值的元素
- 2. 查找最后一個值等于給定值的元素
- 3. 查找第一個大于等于給定值的元素
- 4. 查找最后一個小于等于給定值的元素
Ⅰ 前言
這篇文章我將詳細分析一種針對有序資料集合的查找演算法:二分查找(Binary Search) 演算法,也叫 折半查找演算法,二分查找的思想非常簡單,但是看似越簡單的東西往往越難掌握,
唐納德·克努特(Donald E.Knuth)在《計算機程式設計藝術》的第三卷《排序和查找》中說道:“盡管第一個二分查找演算法于 1946 年出現,然而第一個完全正確的二分查找演算法實作直到 1962 年才出現,”
所以千萬不要小看了二分查找,我將會帶領大家由淺入深地去探究一下這個演算法,
Ⅱ 無處不在的二分思想
二分查找是一種非常簡單易懂的快速查找演算法,生活中隨處可見,最常見的例子就是猜數游戲,一個人在比如說 0 ~ 99 中隨便想一個數,另一個人猜,每猜一次,這個人會告訴他是大了還是小了,直到猜中為止,一般來說猜數的人都會猜中間的數,比如第一次猜 49,如果大了,下一次就猜 23,如果小了,就猜75,這樣重復下去,
100以內的數字,七次就可以猜出來了,如果是 0 ~ 999,也只需要 10 次,這就是二分查找的思想,
現在回到實際的開發場景中,假設有有 1000 條訂單資料,已經按照訂單金額從小到大排序,每個訂單金額都不同,并且最小單位是元,我們現在想知道是否存在金額等于 19 元的訂單,如果存在,就回傳訂單資料,如果不存在則回傳 null,
最簡單的辦法當然是從第一個訂單開始,一個一個遍歷這 1000 個訂單,直到找到金額等于 19 元的訂單為止,但這樣查找會比較慢,最壞情況下,可能要遍歷完這 1000條記錄才能找到,這時候就應該用二分查找了,
我們先假設只有 10 個訂單,金額分別是:7,12,19,32,52,61,74,86,88,99,
還是利用二分思想,每次都與區間的中間資料比對大小,縮小查找區間的范圍,
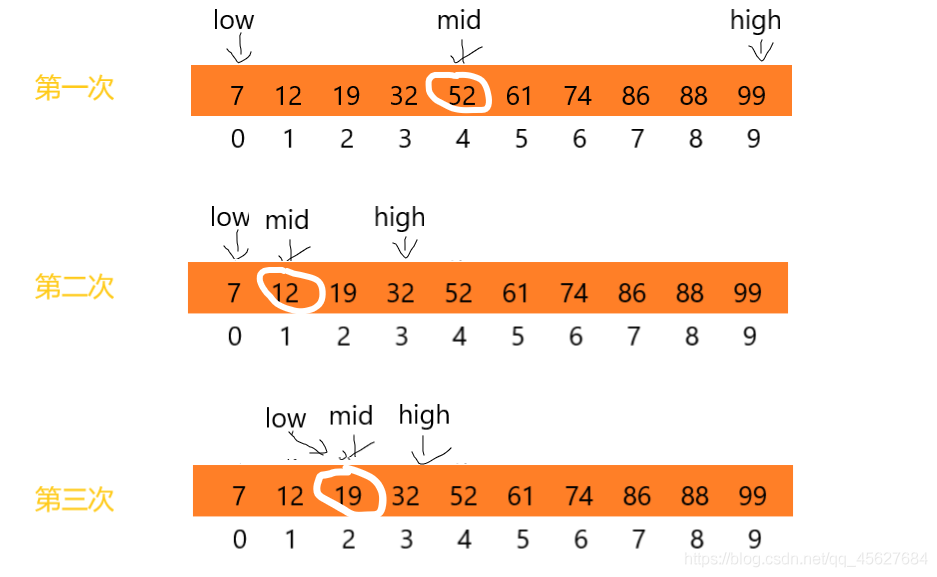
其中,low 和 high 表示待查區間的下標,mid 表示帶查找區間的中間元素下標,
總結一下,二分查找針對的是一個有序的資料集合,查找思想有點類似分治思想,每次都通過跟區間的中間元素對比,將待查找的區間縮小為之前的一半,直到找到要查找的元素,或者區間被縮小為 0,
Ⅲ 二分查找的速度
二分查找是一種非常高效的查找演算法,我們來分析一下它的時間復雜度,
假設資料大小是 n ,每次查找后資料都會縮小為原來的一半,也就是會除以 2.最壞情況下,直到查找區間被縮小為空,才停止,

可以看出來,這是一個等比數列,其中 n/2k = 1 時,k 的值就是總共縮小的次數,而每一次縮小操作只涉及到兩個資料的大小比較,所以,經過了 k 次區間縮小操作,時間復雜度就是 O(k),通過 n/2k = 1,我們可以求得 k = log2n,所以時間復雜度就是 O(log2n),
O(log2n) 這種對數時間復雜度,是極其高效的,有時候比時間復雜度是常量級 O(1) 的演算法還要高效,為什么呢?這就是 log2n的恐怖之處了,
即使 n 非常大,對應的 log2n 也非常小,比如 n = 232,這個數很大了吧,大約是 42 億,也就是說,我們在 42 億個資料里用二分查找一個資料,最多需要比較 32 次,
我們知道,用 大 O 標記法表示時間復雜度的時候,會省略掉常數、系數和低階,對于常量級時間復雜度的演算法來說,O(1) 有可能表示的是一個非常大的常量值,比如 O(1000)、O(10000),所以,常量級時間復雜度的演算法有可能還沒有 O(log2n) 的演算法執行效率高,
反過來,對數對應的就是指數,像我們知道的棋格上放麥子的故事,還有金融學中的復利效應,都很好地體現了指數的可怕,所以指數時間復雜度的演算法在大規模資料面前是無效的,
Ⅳ 二分查找的遞回與非遞回實作
實際上,簡單的二分查找并不難寫,我們先從最簡單、最基本的寫起,再往后看燒腦的,
最簡單的情況就是有序陣列中不存在重復元素,我們在其中用二分查找值等于給定的資料,
1. 非遞回實作
public static int binarySearch(int[] arr, int length, int value) {
int low = 0;
int high = length - 1;
while (low <= high) {
int mid = (low + high) / 2;
if (arr[mid] == value) {
return mid;
} else if (arr[mid] < value) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return -1;
}
這段代碼很簡單,但是有三個容易出錯的地方,
-
回圈退出條件
注意是low <= high,而不是low < high -
mid 的取值
實際上,mid = (low +high) / 2這種寫法是有問題的,因為如果 low 和 high 比較大的話,二者相加就有可能會溢位,改進的方法是將其計算方式改為low + (high - low) / 2,更進一步,如果要將性能優化到極致的話,我們可以用位運算來替代除法,low + ((high - low) >> 1), -
low 和 high 的更新
注意是low = mid +1,high = mid - 1,如果直接寫成low = mid或high = mid,就有可能會發生死回圈,比如,當high = 3,low = 3時,如果arr[3]不等于value,就會導致一直回圈不退出,
實際上,二分查找除了用回圈來實作,還可以用遞回來實作,
2. 遞回實作
package com.tyz.recursion_b_search.core;
public class BinarySearch {
public BinarySearch() {
}
public static int binarySearch(int[] arr, int length, int value) {
return binarySearchInternally(arr, 0, length - 1, value);
}
private static int binarySearchInternally(int[] arr, int low, int high, int value) {
if (low > high) {
return -1;
}
int mid = low + ((high - low) >> 1);
if (arr[mid] == value) {
return mid;
} else if (arr[mid] < value) {
return binarySearchInternally(arr, mid + 1, high, value);
} else {
return binarySearchInternally(arr, low, mid - 1, value);
}
}
}
Ⅴ 二分查找應用場景的局限性
1. 資料結構
二分查找依賴的是順序表結構,簡單說就是陣列,
那二分查找能否依賴其他資料結構嗎?比如鏈表,答案是不可以,主要原因是二分查找演算法需要按照下標隨機訪問元素,在之前的陣列和鏈表資料結構講解中我寫過,陣列按照下標隨機訪問資料的時間復雜度是 O(1),而鏈表隨機訪問的時間復雜度是 O(n),所以,如果使用鏈表存盤,二分查找的時間復雜度就會變得很高,
2. 排列方式
二分查找針對的是有序資料, 這一點二分查找要求比較苛刻,資料必須是有序的,如果資料無序,我們需要先排序,在排序的講解中我們知道,排序的時間復雜度最低是 O(nlog2n),所以,如果我們針對的是一組靜態的資料,沒有頻繁地插入、洗掉,我們可以進行一次排序,多次二分查找,這樣排序的成本就被均攤了,二分查找的邊際成本就會降低,
但是,如果我們的資料集合有頻繁的插入和洗掉操作,要想用二分查找,要么每次插入、洗掉操作之后保證資料仍然有序,要么在每次二分查找之前都先進行排序,針對這種動態資料集合,無論哪種方法,維護有序的成本都很高,
因此,二分查找只能用在插入、洗掉操作不頻繁,一次排序多次查找的場景中,針對動態變化的資料集合,二分查找將不再適用,
3. 資料規模
資料量太小不適合用二分查找,
如果要處理的資料量很小,順序遍歷就足夠了,二分查找和順序遍歷速度都差不多,二分查找只有在資料量比較大的時候,優勢才比較明顯,
不過這里也有例外,如果資料之間的比較操作非常耗時,不管資料量大小,都最好使用二分查找,比如,陣列中存盤的都是長度超過 400 的字串,那么比較起來就會很耗時,我們需要盡可能減少比較次數,這時候二分查找就比順序遍歷更有優勢,
那資料量小不建議用二分查找,那資料量很大呢?其實也不建議,資料量太大是不適合二分查找的,
二分查找的底層需要依賴陣列這種資料結構,而陣列為了支持隨機訪問的特性,記憶體空間是連續的,如果我們有 1GB 的資料,用陣列來儲存,那就需要 1GB 的連續記憶體空間,我們的二分查找就是建立在這種資料結構之上的,所以資料量太大,無法用陣列存盤,也就無法使用二分查找演算法了,
Ⅵ 進階——二分查找的變形
前面簡單的部分過去了,現在我們開始難的部分,在前言我引述了一段唐納德·克努特的話,足以說明二分查找的看似簡單卻非常容易寫錯的特性,不知道你有沒有聽過一句話,“十個二分九個錯”,所以希望大家能好好對待二分查找,不要輕浮它,
閑話到此,我們開始正題,
其實二分查找的變形問題很多,但這里我選取四個最典型的來講解,大道歸一,其他的問題可以基于這四個問題的思想推出,特別說明一下,這幾個變形我都是以資料從小到大排列為前提的,如果你要處理的資料是從大到小排列的,思路是一樣的,
1. 查找第一個值等于給定值的元素
比如下面這樣一個有序陣列,其中,arr[5],arr[6],arr[7] 的值都等于 8,是重復的資料,我們希望查找到第一個等于 8 的資料,也就是下標為 5 的元素,

如果用簡單的二分查找,那最后找到的下標就是 7 ,但是這并不是我們要找的第一個元素,所以前面簡單的二分查找是無法處理這種情況的,我們需要做個變形,改造一下這個代碼,
網上這個變形的代碼很多了,有的思路非常簡潔,但是并不好理解,我寫在下面做個參考,??
public static int binarySearch(int[] arr, int length, int value) {
int low = 0;
int high = length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] >= value) {
high = mid - 1;
} else {
low = mid + 1;
}
}
if (low < length && arr[low] == value) {
return low;
} else {
return -1;
}
}
這個思路其實是比較難想的,也很容易寫錯,下面我用一個我認為更好理解的方式來實作,大家可以選一個自己喜歡的來看,
public static int bsearch(int[] arr, int length, int value) {
int low = 0;
int high = length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] > value) {
high = mid - 1;
} else if (arr[mid] < value) {
low = mid + 1;
} else {
if (mid == 0 || arr[mid - 1] != value) {
return mid;
} else {
high = mid - 1;
}
}
}
return -1;
}
arr[mid]和要找的 value 的大小關系有三種情況:大于、小于、等于,對于 arr[mid] < value 的情況,我們需要更新 low = mid + 1;對于arr[mid] > value的情況,我們需要更新 high = mid - 1;這兩點和最初是一樣的,那arr[mid] == value的時候應該如何處理呢?
由于我們需要查找value 第一次出現的位置,所以找到和它相等的值時,我們需要先確認這是不是第一個,如果 mid == 0,那就說明這個元素已經是陣列的第一個元素了,所以肯定也是我們要找的,如果 mid != 0,但是 arr[mid]的前一個元素 arr[mid-1]不等于value,那也說明 arr[mid] 就是我們要找的第一個值等于給定值的元素,
如果經過檢查之后發現, arr[mid-1]也等于value,那說明arr[mid]肯定不是我們要查找的第一個值等于給定值的元素,那我們就更新 high = mid - 1,因為要找的元素肯定出現在 [low, mid - 1] 之間,
很多人都覺得變形的二分查找很難寫,主要原因是太追求第一種那樣完美、簡潔的寫法,但是其實對于做工程開發的人來說,代碼易讀懂、沒 Bug,更重要,
2. 查找最后一個值等于給定值的元素
這個其實和第一個變形是很像的,思路是一致的,我直接將代碼給出,
public static int bsearch(int[] arr, int length, int value) {
int low = 0;
int high = length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] > value) {
high = mid - 1;
} else if (arr[mid] < value) {
low = mid + 1;
} else {
if ((mid == length - 1) || arr[mid + 1] != value) {
return mid;
} else {
low = mid + 1;
}
}
}
return -1;
}
如果 arr[mid]這個元素已經是陣列中的最后一個元素了,那它肯定是我們要找的;如果 arr[mid]的后面一個元素 arr[mid + 1]不等于 value,那也說明arr[mid]就是我們要找的最后一個值等于給定值的元素,
如果 arr[mid + 1]也等于 value,那說明當前的這個arr[mid]并不是最后一個值等于給定值的元素,我們就更新 low = mid + 1,因為要找的元素肯定在 [mid +1, high] 之間,
3. 查找第一個大于等于給定值的元素
現在我們再來看另一類變形問題,在有序陣列中,查找第一個大于等于給定值的元素,比如,陣列中存盤著 {1, 2, 3, 6, 8},如果查找第一個大于等于 4 的元素,那就是 6,
實際上,實作的思路和前面兩種變形很類似,并且實作更簡潔一點,
public static int bsearch(int[] arr, int length, int value) {
int low = 0;
int high = length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] >= value) {
if ((mid == 0) || arr[mid - 1] < value) {
return mid;
} else {
high = mid - 1;
}
} else {
low = mid + 1;
}
}
return -1;
}
如果 arr[mid]小于要查找的值 value,那要查找的值肯定在 [mid +1, high] 之間,所以,我們更新 low = mid + 1,
對于arr[mid] 大于等于給定值 value的情況,我們要先看下這個 arr[mid]是不是我們要找的第一個值大于等于給定值的元素,如果 arr[mid]前面已經沒有元素,或者前面一個元素小于要查找的值 value,那arr[mid]就是我們要找的元素,
如果 arr[mid - 1]也大于等于要查找的值 value,那說明要查找的元素在 [low, mid - 1] 之間,所以要將 high 更新為 high = mid - 1,
4. 查找最后一個小于等于給定值的元素
現在來看最后一種變形問題,比如一個陣列 {1, 3, 5, 7, 9, 11, 24},要找最后一個小于等于 8 的元素,那就是 7,和第三種變形是很類似的,思路也是一樣的,我不再做分析,直接將代碼貼出來,
public static int bsearch(int[] arr, int length, int value) {
int low = 0;
int high = length - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (arr[mid] > value) {
high = mid - 1;
} else {
if ((mid == 0) || (arr[mid + 1] > value)) {
return mid;
} else {
low = mid + 1;
}
}
}
return -1;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/3327.html
標籤:python