今天是1024程式員節,不得整點活~
雖然不太好教爬1024,但是可以爬點其它的!
比如妹子圖,這不都是各位喜歡的~

代碼流程
模擬瀏覽器向服務器發送一個http請求,網站接收到請求后回傳資料,
在寫爬蟲代碼的時候一定先要去模擬瀏覽器訪問,因為現在的網站當接收到http請求后會校驗當前請求是否是一個瀏覽器,如果是,允許訪問,如果不是,禁止訪問!

環境啥的我就不說了,還是老樣子~
首先把我們要用的包導進去
import os # 自動創建檔案夾 import requests # requests 爬蟲包 需要下載 pip install requests from bs4 import BeautifulSoup # 網頁選擇器 pip install bs4
然后我們就要開始模擬瀏覽器
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36', # 反盜鏈 'referer': 'https://www.mzitu.com/' }
既然我們要下載,當然要有檔案夾去保存對吧,這里就實作自動創建檔案夾,不用我們去額外創建,
def get_girls(url): # 自動創建檔案夾 if not os.path.exists('./學習資料/'): os.mkdir('./學習資料/')
當然,為了不讓你的小秘密被別人看到,咱們這里就把它命名為學習資料吧~

我們現在來發送請求,http協議中 有幾種請求方法:
- get 獲取資料
- post 資料提交 [賬號密碼提交]
html = requests.get(url, headers=headers).text
print(html)
對剛剛抓取到的資料進行二次篩選
需要兩個引數,想要二次提取的網頁 html變數臨時保存了,
html決議庫 lxml pip install lxml
html決議庫可以將html代碼轉成我們的python物件
soup = BeautifulSoup(html, 'lxml')
通過剛剛分析得出一個結論,一張圖片是由img標簽保存的,li標簽包含一個img標簽,如果我們獲取了所有的li標簽,相當于獲取到了所有的img標簽,因為一個ul標簽包含了所有的li標簽,所以獲取一個ul就相當于獲取到了所有的li標簽,
遍歷所有的li標簽
all_list = soup.find('ul', id='pins').find_all_next('li') for _ in all_list: girl_title = _.get_text() girl_url = _.find('img')['data-original'] print(girl_title, girl_url)
這個時候就可以開始下載了
response = requests.get(girl_url, headers=headers) fileName = girl_title + '.jpg' print('正在保存圖片:', girl_title) with open('./學習資料/' + fileName, 'wb') as f: f.write(response.content)
當然,只下載一頁的話當然不過癮,咱們這里就來實作翻頁下載,當然,別爬多了,克制一下自己,
代碼雖好,但還是要克制一下自己喲~
for page in range(1, 256): url = 'https://www.mzitu.com/page/%s' % page get_girls(url)
你要下載多少頁,直接改成多少頁就好了,
兄弟們學習python,有時候不知道怎么學,從哪里開始學,掌握了基本的一些語法或者做了兩個案例后,不知道下一步怎么走,不知道如何去學習更加高深的知識,
那么對于這些大兄弟們,我準備了大量的免費視頻教程,PDF電子書籍,以及視頻源的源代碼!
還會有大佬解答!
包括本文源代碼、對應視頻都在這里了 點擊藍色字體即可獲取這些福利
歡迎加入,一起討論 一起學習!
我們看看結果
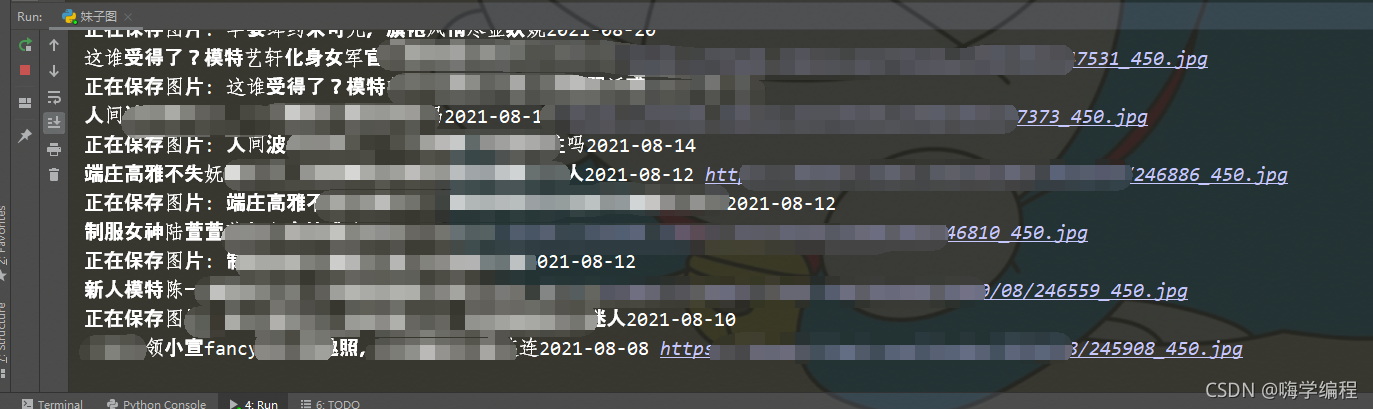

只能打碼了,委婉一點,
檔案夾我也不打開了,大家等下自己去試試,然后再慢慢打開把哈哈~

兄弟們,如果看完了感徑訓過的去的話,記得來個三連,你的三連就是我最大的動力!
有啥問題和建議都可以在評論區一起交流~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/333247.html
標籤:Python