很多同學或多或少都用到了Zookeeper,并知道它能實作兩個功能
- 配置中心,實作表分片規則的統一配置管理
- 注冊中心,實作sharding-proxy節點的服務地址注冊
那么Zookeeper到底是什么?以及為什么能實作這樣的功能?接下來我們就來了解一下Zookeeper,
Zookeeper的前世今生
Apache ZooKeeper是一個高可靠的分布式協調中間件,它是Google Chubby的一個開源實作,那么它主要是解決什么問題的呢?那就得先了解Google Chubby
Google Chubby是谷歌的一個用來解決分布式一致性問題的組件,同時,也是粗粒度的分布式鎖服務,
分布式一致性問題
什么是分布式一致性問題呢?簡單來說,就是在一個分布式系統中,有多個節點,每個節點都會提出一個請求,但是在所有節點中只能確定一個請求被通過,而這個通過是需要所有節點達成一致的結果,所以所謂的一致性就是在提出的所有請求中能夠選出最終一個確定請求,并且這個請求選出來以后,所有的節點都要知道,
這個就是典型的拜占庭將軍問題
拜占庭將軍問題說的是:拜占庭帝國軍隊的將軍們必須通過投票達成一致來決定是否對某一個國家發起進攻,但是這些將軍在地里位置上是分開的,并且在將軍中存在叛徒,叛徒可以通過任意行動來達到自己的目標:
-
欺騙某些將軍采取進攻行動
-
促使一個不是所有將軍都統一的決定,比如將軍們本意是不希望進攻,但是叛徒可以促成進攻行動
-
迷惑將軍使得他們無法做出決定
如果叛徒達到了任意一個目標,那么這次行動必然失敗,只有完全達成一致那么這次進攻才可能勝利
拜占庭問題的本質是,由于網路通信存在不可靠的問題,也就是可能存在訊息丟失,或者網路延遲,如何在這樣的背景下對某一個請求達成一致,
為了解決這個問題,很多人提出了各種協議,比如大名鼎鼎的Paxos; 也就是說在不可信的網路環境中,按照paxos這個協議就能夠針對某個提議達成一致,
所以:分布式一致性的本質,就是在分布式系統中,多個節點就某一個提議如何達成一致
這個和Google Chubby有什么關系呢
在Google有一個GFS(google file system),他們有一個需求就是要從多個gfs server中選出一個master server,這個就是典型的一致性問題,5個分布在不同節點的server,需要確定一個master server,而他們要達成的一致性目標是:確定某一個節點為master,并且所有節點要同意,
而GFS就是使用chubby來解決這個問題的,
實作原理是:所有的server通過Chubby提供的通信協議到Chubby server上創建同一個檔案,當然,最終只有一個server能夠獲準創建這個檔案,這個server就成為了master,它會在這個檔案中寫入自己 的地址,這樣其它的server通過讀取這個檔案就能知道被選出的master的地址,
分布式鎖服務
從另外一個層面來看,Chubby提供了一種粗粒度的分布式鎖服務,chubby是通過創建檔案的形式來提供鎖的功能,server向chubby中創建檔案其實就表示加鎖操作,創建檔案成功表示搶占到了鎖,
由于Chubby沒有開源,所以雅虎公司基于chubby的思想,開發了一個類似的分布式協調組件Zookeeper,后來捐贈給了Apache,
所以,大家一定要了解,zookeeper并不是作為注冊中心而設計,他是作為分布式鎖的一種設計,而注冊中心只是他能夠實作的一種功能而已,
Zookeeper的安裝和部署
安裝
zookeeper有兩種運行模式:集群模式和單擊模式,
下載zookeeper安裝包:https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
下載完成,通過tar -zxvf解壓
常用命令
- 啟動ZK服務:
bin/zkServer.sh start
- 查看ZK服務狀態:
bin/zkServer.sh status
- 停止ZK服務:
bin/zkServer.sh stop
- 重啟ZK服務:
bin/zkServer.sh restart
- 連接服務器
zkCli.sh -timeout 0 -r -server ip:port
單機環境安裝
一般情況下,在開發測驗環境,沒有這么多資源的情況下,而且也不需要特別好的穩定性的前提下,我們可以使用單機部署;
初次使用zookeeper,需要將conf目錄下的zoo_sample.cfg檔案copy一份重命名為zoo.cfg
修改dataDir目錄,dataDir表示日志檔案存放的路徑(關于zoo.cfg的其他配置資訊后面會講)
集群環境安裝(后續再講)
在zookeeper集群中,各個節點總共有三種角色,分別是:leader,follower,observer
集群模式我們采用模擬3臺機器來搭建zookeeper集群,分別復制安裝包到三臺機器上并解壓,同時copy一份zoo.cfg,
-
修改組態檔
- 修改埠
- server.1=IP1:2888:3888 【2888:訪問zookeeper的埠;3888:重新選舉leader的埠】
- server.2=IP2.2888:3888
- server.3=IP3.2888:2888
-
server.A=B:C:D:其 中
- A 是一個數字,表示這個是第幾號服務器;
- B 是這個服務器的 ip地址;
- C 表示的是這個服務器與集群中的 Leader 服務器交換資訊的埠;
- D 表示的是萬一集群中的 Leader 服務器掛了,需要一個埠來重新進行選舉,選出一個新的 Leader,而這個埠就是用來執行選舉時服務器相互通信的埠,如果是偽集群的配置方式,由于 B 都是一樣,所以不同的 Zookeeper 實體通信埠號不能一樣,所以要給它們分配不同的埠號,
- 在集群模式下,集群中每臺機器都需要感知到整個集群是由哪幾臺機器組成的,在組態檔中,按照格式server.id=host:port:port,每一行代表一個機器配置,id: 指的是server ID,用來標識該機器在集群中的機器序號
-
新建datadir目錄,設定myid
在每臺zookeeper機器上,我們都需要在資料目錄(dataDir)下創建一個myid檔案,該檔案只有一行內容,對應每臺機器的Server ID數字;比如server.1的myid檔案內容就是1,【必須確保每個服務器的myid檔案中的數字不同,并且和自己所在機器的zoo.cfg中server.id的id值一致,id的范圍是1~255】
-
啟動zookeeper
Zookeeper的資料模型
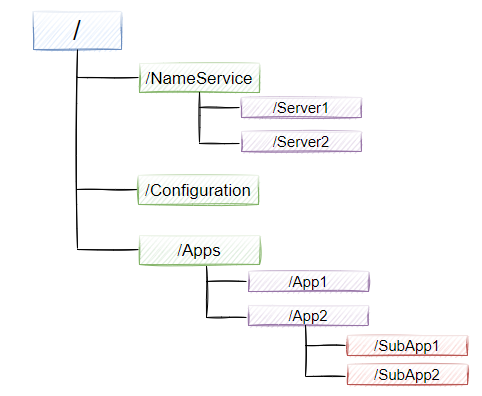
如果我們把zookeeper當成是一個記憶體資料庫的話,那么crud就是對zookeeper記憶體資料庫進行一個資料的增刪改查操作,那zookeeper的資料結構是什么樣的呢?如圖9-4所示,zookeeper的視圖結構和標準的檔案系統非常類似,每一個節點稱之為ZNode, 是zookeeper的最小單元,每個znode上都可以保存資料以及掛載子節點,構成一個層次化的樹形結構
節點型別
Zookeeper中包含4種型別的節點,分別說明如下,
持久化節點
持久化節點可以細分為兩種節點,分別是:
-
PERSISTENT:持久化,不會隨客戶端的斷開而自動洗掉,默認型別,如圖9-5所示
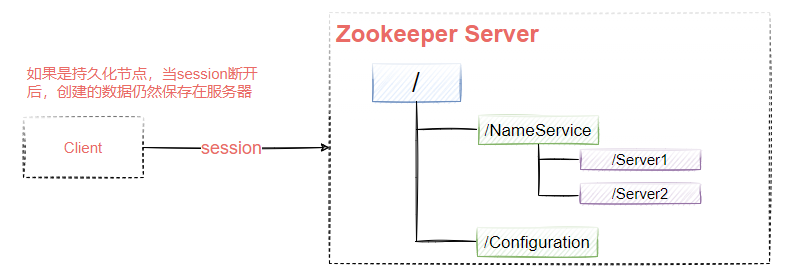
圖9-5 -
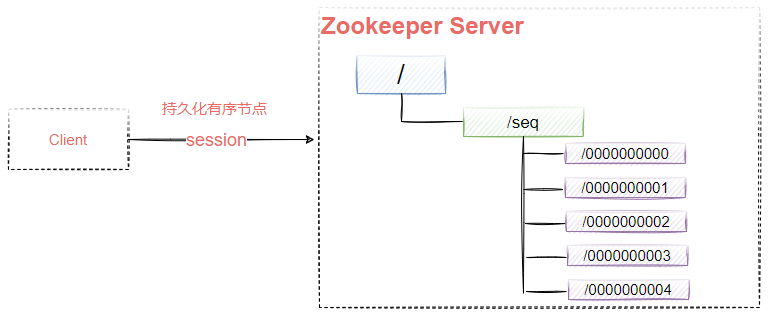
PERSISTENT_SEQUENTIAL:帶序號的持久化,znode的名字將被附加一個單調遞增的數字,如圖9-6所示
臨時節點
-
EPHEMERAL:臨時節點,當客戶端斷開時自動洗掉,如圖9-6所示,如果該Client創建了/Server1和/Server2這兩個節點,當Client的session斷開后,這兩個節點會被Zookeeper自動洗掉,
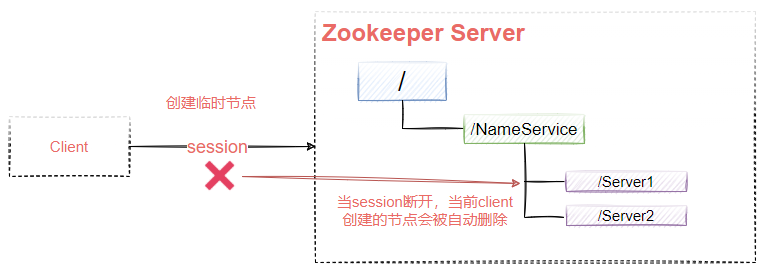
圖9-6 -
EPHEMERAL_SEQUENTIAL:帶序號的臨時節點,znode的名字將被附加一個單調遞增的數字,如圖9-7所示
注意,臨時節點不能存在子節點
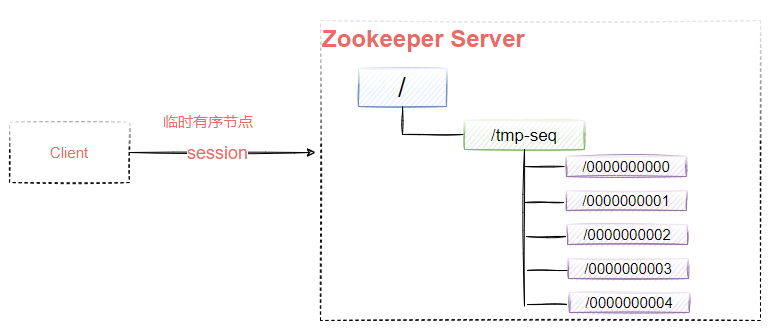
Container節點
CONTAINER:container節點是一個特殊用途的節點,它是為Leader、Lock等操作而設計的節點型別,它的作用是: 當容器節點的最后一個子節點被洗掉后,容器節點將會被標注并且在一段時間后洗掉,
由于容器節點存在這個特性,所以當我們在容器節點下創建一個子節點時,需要捕獲KeeperException.NoNodeException例外,如果捕獲到這個例外,就需要重新創建容器節點,
TTL節點
如果某個節點設定為TTL節點型別,那么這個節點在指定TTL時間(單位為毫秒)段內沒有修改并且沒有子節點時,該節點會在一段時間后被洗掉,
- PERSISTENT_WITH_TTL:zookeeper的擴展型別,如果znode在給定的TTL內沒有被修改,它將在沒有子節點時被洗掉,要想使用該型別,必須在zookeeper的bin/zkService.sh中的啟動zookeeper的java環境中設定環境變數zookeeper.extendedTypesEnabled=true(具體做法在下邊),否則KeeperErrorCode = Unimplemented for /**,
設定zookeeper.extendedTypesEnabled=true
打開zookeeper bin/zkServer.sh(win是zkService.cmd),修改啟動zookeeper的命令,加上-Dzookeeper.extendedTypesEnabled=true,也就是設定java的一個環境變數,
nohup "$JAVA" $ZOO_DATADIR_AUTOCREATE "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" \
"-Dzookeeper.log.file=${ZOO_LOG_FILE}" "-Dzookeeper.extendedTypesEnabled=true" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \
-XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError='kill -9 %p' \
-cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &
- PERSISTENT_SEQUENTIAL_WITH_TTL:同上,是不過是帶序號的
Zookeeper的操作命令
創建節點
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
[-s]:sequential 序列化的,即可以重復創建,在路徑后面加上序列號
[-e]:ephemeral 臨時的,斷開連接后自動失效
[-c] :表示container node(容器節點),
[-t ttl]:表示TTL Nodes(帶超時時間的節點)
[acl]:是針對這個節點創建一個權限的,如果創建權限了,則擁有權限的才可以訪問
洗掉節點
洗掉節點,-v表示版本號,實作樂觀鎖機制
delete [-v version] path
更新節點
給節點賦值 -s回傳節點狀態
set [-s] [-v version] path data
查詢節點資訊
獲取指定節點的值
get [-s] [-w] path
節點狀態資訊stat
節點除了存盤資料內容以外,還存盤了資料節點本身的一些狀態資訊,通過get命令可以獲得狀態資訊的詳細內容,如圖9-8所示,
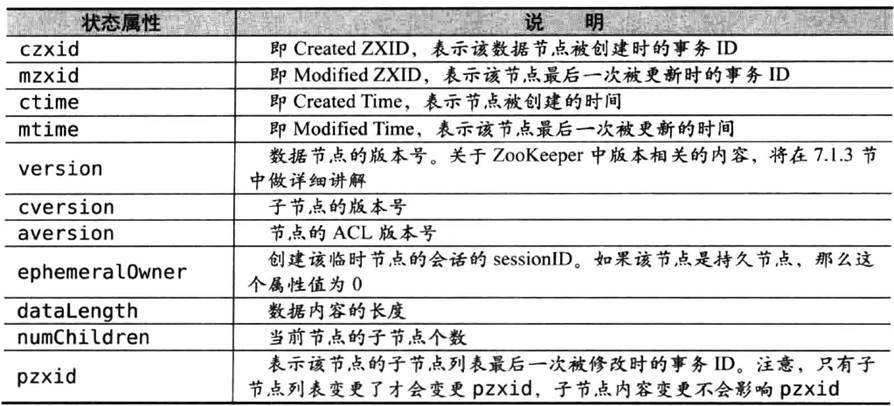
版本-保證分布式資料原子性
zookeeper為資料節點引入了版本的概念,每個資料節點都有三類版本資訊,對資料節點任何更新操作都會引起版本號的變化

版本有點和我們經常使用的樂觀鎖類似,這里有兩個概念說一下,一個是樂觀鎖,一個是悲觀鎖
悲觀鎖:是資料庫中一種非常典型且非常嚴格的并發控制策略,假如一個事務A正在對資料進行處理,那么在整個處理程序中,都會將資料處于鎖定狀態,在這期間其他事務無法對資料進行更新操作,
樂觀鎖:樂觀鎖和悲觀鎖正好想法,它假定多個事務在處理程序中不會彼此影響,因此在事務處理程序中不需要進行加鎖處理,如果多個事務對同一資料做更改,那么在更新請求提交之前,每個事務都會首先檢查當前事務讀取資料后,是否有其他事務對資料進行了修改,如果有修改,則回滾事務
再回到zookeeper,version屬性就是用來實作樂觀鎖機制的“寫入校驗”
Watcher監聽節點事件變化
zookeeper提供了分布式資料的發布/訂閱功能,zookeeper允許客戶端向服務端注冊一個watcher監聽,當服務端的一些指定事件觸發了watcher,那么服務端就會向客戶端發送一個事件通知,zookeeper提供以下幾種命令來對指定節點設定監聽,
- get [-s] [-w] path:監聽指定path節點的修改和洗掉事件,同樣該事件也是一次性觸發,
get -w /node
# 在其他視窗執行下面命令,會觸發相關事件
set /node 123
delete /node
- ls [-s] [-w] [-R] path : 監控指定path的子節點的添加和洗掉事件,
ls -w /node
# 在其他視窗執行下面命令,會觸發相關事件
create /node/node1
delete /node/node1
注意: 當前命令設定的監聽是一次性的,就是說一旦觸發了一次事件監聽,后續的事件都不會回應,當然我們可以通過重復訂閱來解決
-
stat [-w] path:作用和get完全相同,
-
addWatch [-m mode] path # optional mode is one of [PERSISTENT, PERSISTENT_RECURSIVE] - default is PERSISTENT_RECURSIVE
addWatch的作用是針對指定節點添加事件監聽,支持兩種模式
- PERSISTENT,持久化訂閱,針對當前節點的修改和洗掉事件,以及當前節點的子節點的洗掉和新增事件,
- PERSISTENT_RECURSIVE,持久化遞回訂閱,在PERSISTENT的基礎上,增加了子節點修改的事件觸發,以及子節點的子節點的資料變化都會觸發相關事件(滿足遞回訂閱特性)
Session會話機制
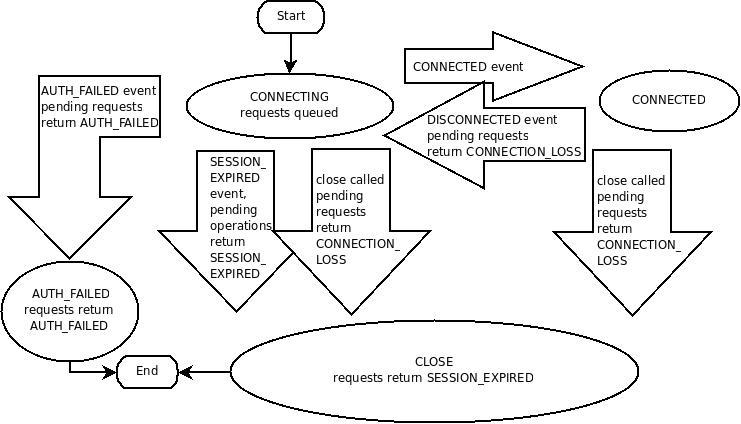
如圖9-10所示,表示Zookeeper的session會話狀態機制,
- 首先,客戶端向Zookeeper Server發起連接請求,此時狀態為CONNECTING
- 當連接建立好之后,Session狀態轉化為CONNECTED,此時可以進行資料的IO操作,
- 如果Client和Server的連接出現丟失,則Client又會變成CONNECTING狀態
- 如果會話過期或者主動關閉連接時,此時連接狀態為CLOSE
- 如果是身份驗證失敗,直接結束
Zookeeper的應用場景
配置中心
程式總是需要配置的,如果程式分散部署在多臺機器上,要逐個改變配置就變得困難,好吧,現在把這些配置全部放到zookeeper上去,保存在 Zookeeper 的某個目錄節點中,然后所有相關應用程式對這個目錄節點進行監聽,一旦配置資訊發生變化,每個應用程式就會收到 Zookeeper 的通知,然后從 Zookeeper 獲取新的配置資訊應用到系統中就好,
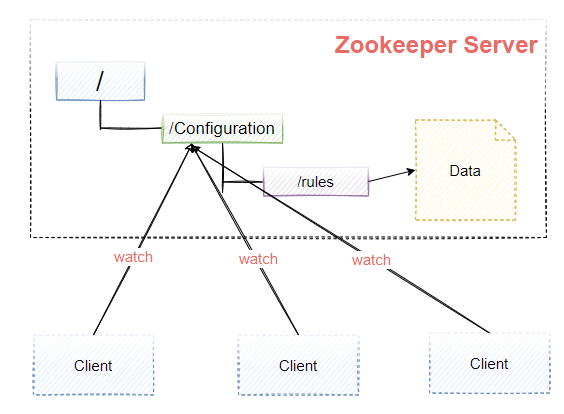
服務注冊中心
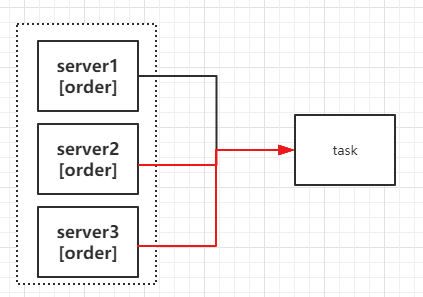
如圖9-12所示,Zookeeper可以用來實作服務注冊中心,簡單來說就是管理目標服務端的地址,客戶端呼叫目標服務端之前,從zookeeper上獲得地址進行訪問,
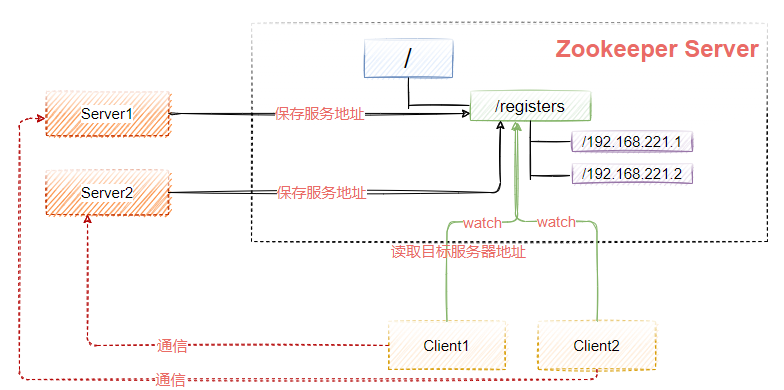
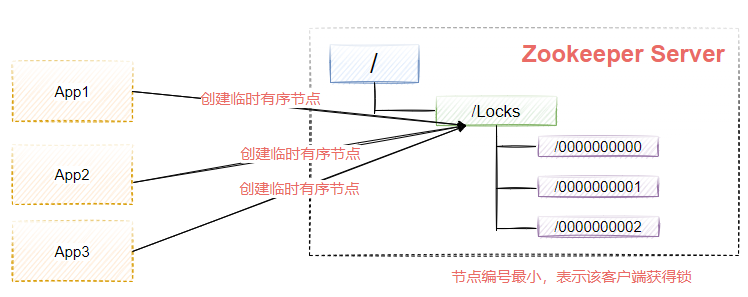
分布式鎖
利用臨時有序節點實作分布式鎖,如圖9-13所示,每個App節點要搶占分布式鎖,可以先去Zookeeper上創建一個臨時有序節點,節點最小的表示該客戶端獲得了鎖,其他沒獲得鎖的客戶端先等待,直到獲得鎖的客戶端洗掉了該節點或者斷開會話連接,
關注[跟著Mic學架構]公眾號,獲取更多精品原創

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/335057.html
標籤:Java
上一篇:改變世界的 5 位程式員!