您好,我是碼農飛哥,感謝您閱讀本文,歡迎一鍵三連哦,
本文是爬蟲專欄的第一篇,重點介紹爬蟲的基本概念,提供一個爬蟲的標準步驟,
干貨滿滿,建議收藏,需要用到時常看看, 小伙伴們如有問題及需要,歡迎踴躍留言哦~ ~ ~,
前言(為什么寫這篇文章)
本文是爬蟲專欄的第一篇,這里默認你已經掌握了Python的基礎,如果您還沒來得及看Python基礎的話,請你抽出時間看下【Python從入門到精通】(二十八)五萬六千字對Python基礎知識做一個了結吧!【值得收藏】
本文主要解答如下幾個問題:
- 什么是爬蟲?
- 為什么要學爬蟲?
- 怎么進行爬蟲?
最后會展示一個簡單的爬蟲的實體教大家加深印象,
什么是爬蟲
爬蟲顧名思義就是通過技術手段獲取網站上的公開資料,并將這些非結構化的資料決議成結構化的資料保存起來,
舉個?? 打開碼農飛哥的博客主頁 可以看到如圖1的結果:
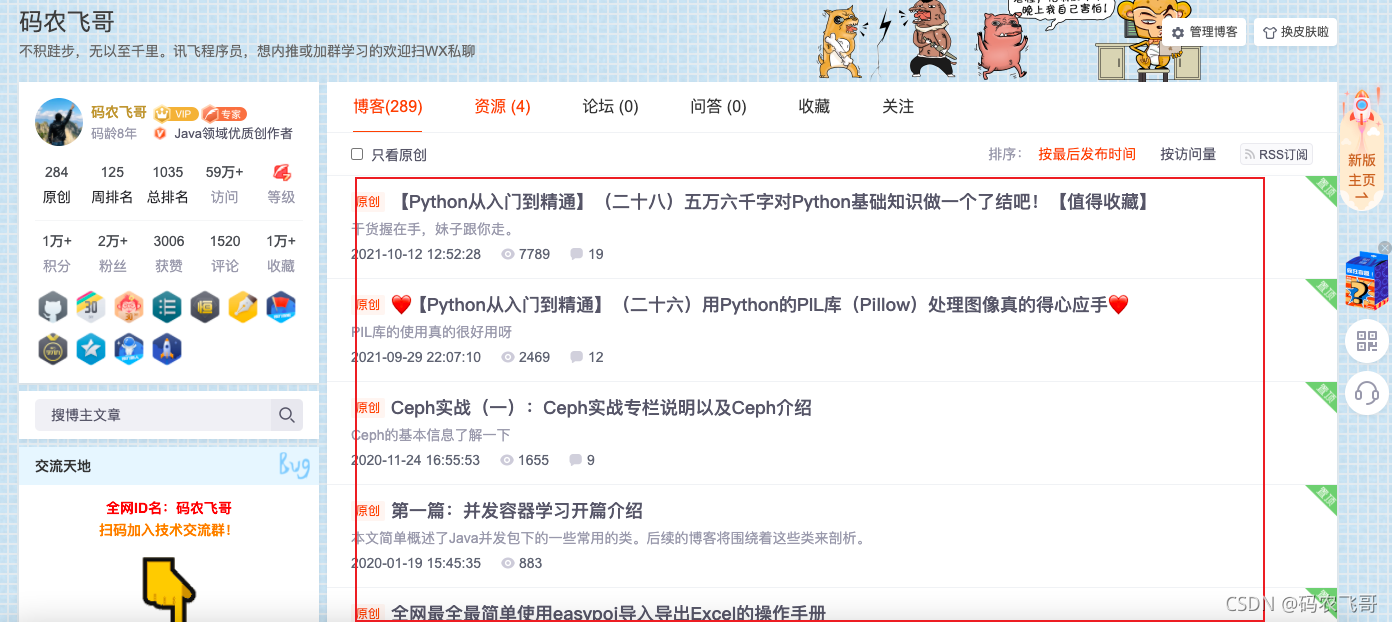
如果我們想將圖中文章的標題,簡介拉取到本地并保存下來本地就需要用到爬蟲技術,
為什么要學爬蟲
網路上有海量的公開資料,比如我們每天看到的各種新聞資料,看到的各種學習博客都是公開的,可以獲取的資料,如果將這些資料爬取下來進行資料分析就可以對構建用戶畫像,從而對每個用戶進行個性化的推薦,今日某條早期就是一個通過爬蟲程式獲取其他網站的新聞資料,從而獲取海量資料的,
總之,爬蟲很有用,用處大大的,
其實很多語言都可以實作撰寫爬蟲程式,比如Java,php,Python,但是我們這里選擇Python語言作為爬蟲的首選語言是因為
| 語言 | 優勢 | 缺點 |
|---|---|---|
| Java | 語言強大,支持復雜的爬蟲場景,并發性能強 ,生態完善 | 代碼臃腫,需要撰寫很多代碼 |
| php | 語法簡單,可以直接操作頁面,生態不好 | 復雜的場景不支持 |
| Python | 語法簡單,撰寫代碼少,生態完善,支持復雜的爬蟲場景 | 暫時沒發現 |
綜上所述就選擇用Python撰寫爬蟲程式,
學習爬蟲所需要的預備知識
會利用瀏覽器查看網頁
我們都知道網頁是通過超文本標記語言Html語言渲染出來的,Html通過一系列的標簽和樣式將網頁內容渲染出來,但是這些這些標簽是我們爬蟲不需要的,所以我們首先需要找到我們想要爬取的內容在哪個標簽里從而進行爬蟲, 這里用Chrom瀏覽器做一個說明,
- 選中網頁---》右鍵---》檢查 即可調出Chrome的除錯視窗,如下圖2所示,
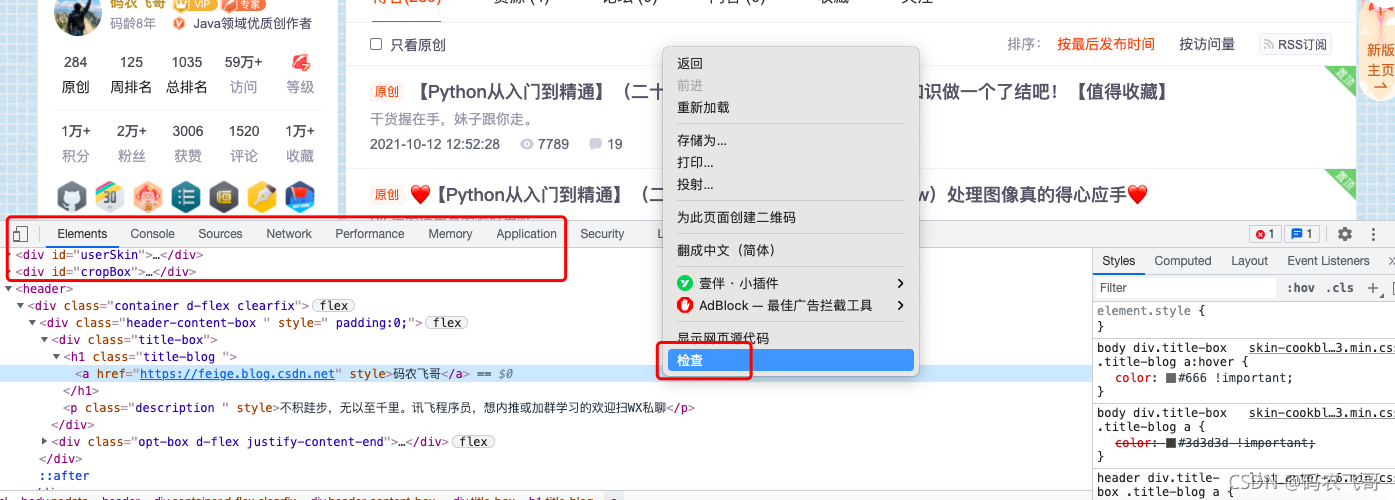
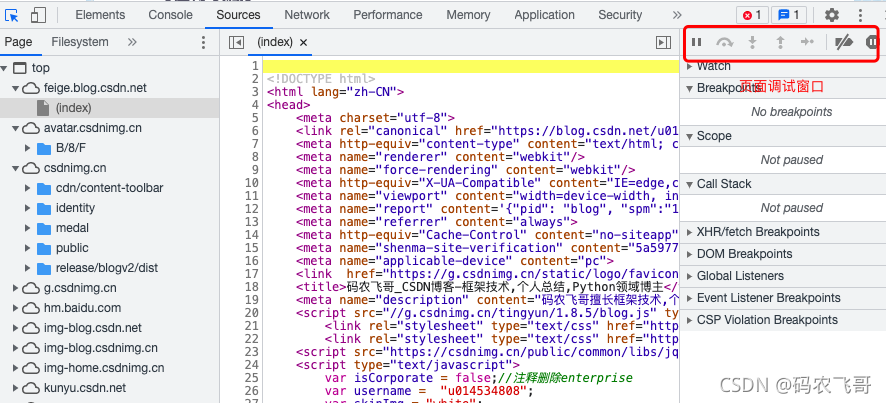
其中:- Elements模塊展示了頁面的元素,說白了就是展示當前頁面的完整html代碼, 可以查看頁面的樣式以及每個文本被包含在那個元素中,如果要查看頁面中的某個元素,只需要選中
這個圖示,然后將焦點放在你需要查看的文本處就可以查看文本在哪個標簽中了,就像下圖3所示:
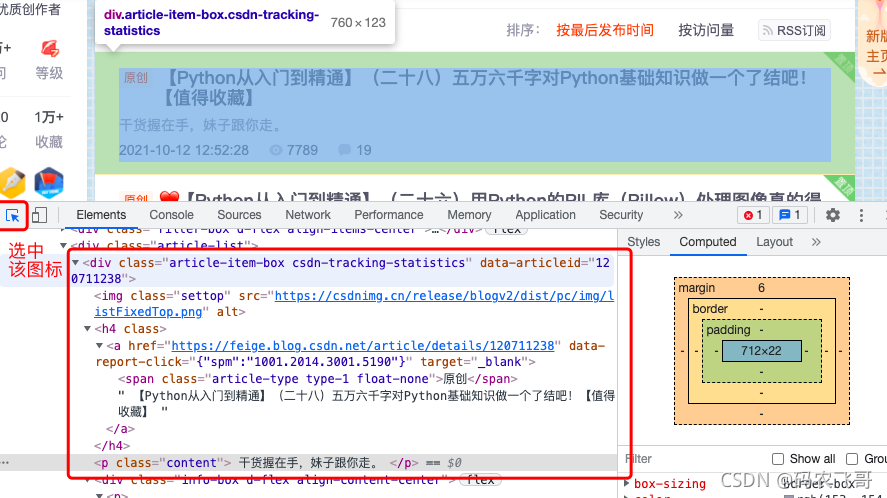
這里我們的文章標題被保存到了<a></a>標簽中,文章摘要被保存在了<p ></p>標簽中,- Console 模塊是控制臺視窗,可以在該視窗下撰寫一些簡單的代碼并查看輸出結果,就像下面比較a和b的大小
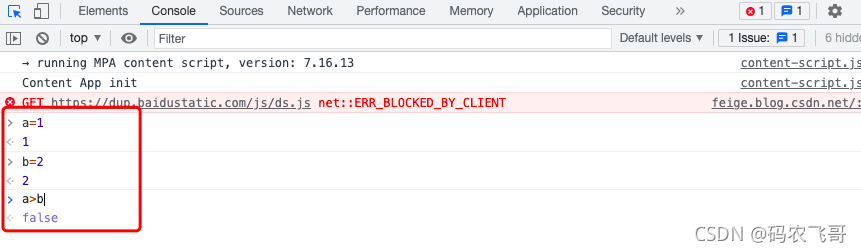
- Console 模塊是控制臺視窗,可以在該視窗下撰寫一些簡單的代碼并查看輸出結果,就像下面比較a和b的大小
- Elements模塊展示了頁面的元素,說白了就是展示當前頁面的完整html代碼, 可以查看頁面的樣式以及每個文本被包含在那個元素中,如果要查看頁面中的某個元素,只需要選中
- Sources 模塊展示了該頁面所涉及的所有源代碼檔案,包括了html檔案,js檔案以及css檔案等等,我們可以在該視窗進行除錯,
- Network 模塊展示了頁面的所有請求,包括資料的請求,圖片的請求等等,選中其中一個請求就可以看到該請求的詳細資訊,包括請求頭,回應頭,回應結果等等,
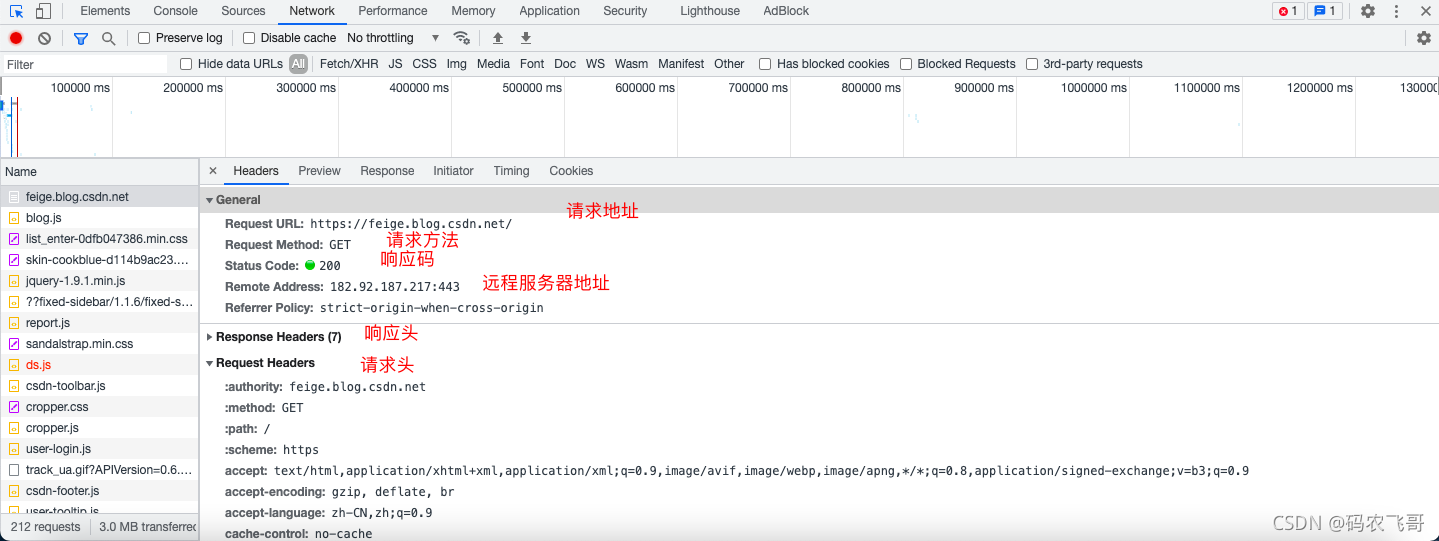
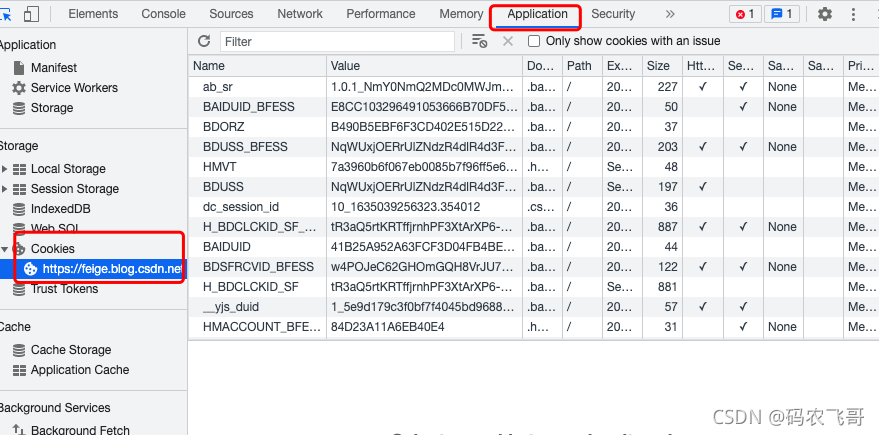
這里需要重點關注 accept ,cookie,user-agent 等引數,其中accept引數指定了該請求所接受的請求資料格式,cookie保存了瀏覽器的快取,user-agent 可以理解為通行證, - Application 模塊主要是展示本次存盤,Session存盤,以及Cookies等,
怎么爬蟲程式
撰寫爬蟲程式分為三步:
- 利用 urllib庫或者requests 庫獲取網頁原始碼
- 利用BeautifulSoup4以及正則運算式決議原始碼
- 利用xls 、MySQL 、MongoDB等存盤介質來存盤資料
下面就以碼農飛哥的博客首頁為例,爬取首頁的所有文章的標題和概況
0. 依賴庫的安裝
安裝requests庫
pip install requests
安裝beautifulsoup4庫
自動安裝的話可以直接通過
pip install beautifulsoup4 -i https://pypi.douban.com/simple
命令進行安裝,如果安裝失敗的可以手動安裝
手動安裝就是先把beautifulsoup4-4.6.0-py3-none-any.whl 下載下來,我已經放在了原始碼中,然后執行:
pip install beautifulsoup4-4.6.0-py3-none-any.whl
安裝與你Python版本相容的lxml庫
這里還需要安裝lxml庫,lxml是XML和HTML的決議器,其主要功能是決議和提取XML和HTML中的資料,它是一款高性能的python HTML、XML決議器,也可以利用XPath語法,來定位特定的元素及節點資訊,
pip install lxml -i https://pypi.douban.com/simple
如果不安裝的話你可能會喜提如下圖所示的bug

安裝pandas庫
- 安裝pandas庫首先需要在電腦中安裝anaconda,anaconda下載地址,安裝之后就是簡單的安裝了,在此就不在贅述了,

- 安裝matplotlib庫和pandas庫
pip install matplotlib
pip install pandas
將所必須的庫安裝好之后就是樸實無華的編碼程序了,
1.利用requests 庫獲取網頁原始碼(就是前面說的那個html檔案)
import requests
r = requests.get('https://feige.blog.csdn.net/')
r.encoding = 'utf-8'
通過requests.get方法就可以獲取網頁的原始碼,通過r.encoding 將原始碼的編碼格式設定為utf-8,
2. 利用beautifulsoup4決議原始碼資料
這里我們的文章標題被保存到了 <a></a>標簽中,文章摘要被保存在了 <p ></p> 標簽中,所以我們需要對這兩個標簽進行決議,
# 使用BeautifulSoup決議資料
soup = BeautifulSoup(r.text, 'lxml')
# 獲取所有的摘要
pattern = soup.find_all('p', 'content')
content = []
# 回圈遍歷內容
for i, item in enumerate(pattern):
content.append(item.string)
3. 利用pandas庫來保存資料
df = pandas.DataFrame(content)
df.to_csv('content.csv')
將資料保存到conten.csv 檔案中,
完整的源代碼
import requests
from bs4 import BeautifulSoup
import pandas
# 使用request抓取資料
r = requests.get('https://feige.blog.csdn.net/')
r.encoding = 'utf-8'
# 使用BeautifulSoup決議資料
soup = BeautifulSoup(r.text, 'lxml')
# 獲取所有的摘要
pattern = soup.find_all('p', 'content')
content = []
# 回圈遍歷內容
for i, item in enumerate(pattern):
content.append(item.string)
df = pandas.DataFrame(content)
df.to_csv('content.csv')
總結
本文詳細介紹了Python的爬蟲入門的基礎知識,讓我們一起學起來,
全網同名【碼農飛哥】,不積跬步,無以至千里,享受分享的快樂
我是碼農飛哥,再次感謝您讀完本文,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/335069.html
標籤:Python