您好,我是碼農飛哥,感謝您閱讀本文,歡迎一鍵三連哦,
本文是爬蟲專欄的第二篇,重點介紹requests庫的使用,
干貨滿滿,建議收藏,需要用到時常看看, 小伙伴們如有問題及需要,歡迎踴躍留言哦~ ~ ~,
前言(為什么寫這篇文章)
上一篇文章簡單的介紹了爬蟲相關的基礎知識點,介紹了一個標準爬蟲程式的三個步驟,這篇文章就讓我們接著來學習,
本文重點介紹requests庫的使用以及爬蟲協議,之前也寫了一篇Requests庫使用的博客,有興趣的小伙伴可以去看看,
文章目錄
- 前言(為什么寫這篇文章)
- Requests庫的介紹
- get請求方法(不帶引數)
- 傳遞URL引數
- post請求方法
- 以表單的方式提交
- 以json字串的方式提交
- 檔案上傳
- 重定向
- 設定超時
- 獲取回應碼
- 禁止證書驗證
- 爬蟲協議
- 豆瓣登錄案例
- 總結
- 粉絲專屬福利
Requests庫的介紹
前面介紹了Requests庫是用來抓取網頁原始碼,請求介面的利器,整體上是要比urllib庫的request更加好用的庫,官網上將其稱之為唯一一個非轉基因的Python HTTP庫,人類可以安全享用,
Requests庫有7個主要方法,
| 方法 | 說明 |
|---|---|
| requests.request() | 構造一個請求,支撐以下各方法的基礎方法 |
| requests.get() | 獲取HTML網頁的主要方法,對應于HTTP的GET |
| requests.head(() | 獲取HTML網頁頭資訊的方法,對應于HTTP的HEAD |
| requests.post() | 向服務器指定的介面發起POST請求方法,對應于HTTP的POST |
| requests.put() | 向服務器指定的介面發起PUT請求的方法,對應于HTTP的PUT |
| requests.patch() | 向服務器指定的介面提供區域修改請求,對應于HTTP的PATCH |
| requests.delete() | 向HTML頁面提交洗掉請求,對應于HTTP的DELETE |
不過我們平常最常用的方法還是GET方法和POST方法,
get請求方法(不帶引數)
get請求方法是爬蟲中最常用到的方法,因為爬蟲主要就是爬取網頁的資訊,最基礎的使用是
res = requests.get('https://feige.blog.csdn.net/')
res.encoding = 'utf-8'
print(res.text)
這里需要通過res.encoding='utf-8' 設定回應結果的編碼格式是utf-8,不然可能會出現中文亂碼
如果回應結果是二進制資料的話則需要通過 res.content 方法來提取回應結果,
設定編碼的方式也可以是res.content.decode('utf-8'),
即
res = requests.get('https://feige.blog.csdn.net/')
print(res.content.decode('utf-8'))
傳遞URL引數
有時候get請求也需要傳入引數,這里可以直接將引數拼接到URL上或者通過params引數傳入一個字典,
params = {'id': 12, 'name': 'zhangsan'}
# url拼接
res = requests.get(url='https://feige.blog.csdn.net/', params=params)
# 列印url
print(res.url)
# 或者
res = requests.get(url='https://feige.blog.csdn.net/?id={0}&name={1}'.format(13, 'lisi'))
print(res.url)
運行結果是:
https://feige.blog.csdn.net/?id=12&name=zhangsan
https://feige.blog.csdn.net/?id=13&name=lisi
post請求方法
get請求只能傳入簡單的引數,如果引數比較復雜或者傳入的引數比較多的話則GET請求就不再適用了,這時候就需要適用post請求方法了,
Post請求的請求型別有三種:
application/x-www-form-urlencoded這是以form表單的方式來提交post請求,application/json;charset=utf-8這是以json字串的格式,將請求引數放在RequestBody中的方式,form-data這種方式一般是用來上傳檔案用的,
以表單的方式提交
以表單的方式提交資料是POST請求的默認的請求格式,只需要將引數放在一個字典中進行傳入即可,
url = "http://127.0.0.1:8080/v1/ls/voice/save"
data = {"dst_audio": "9d62ca66-326f-4070-9993-5f89f790dc68.wav"}
res = requests.post(url, data)
content = res.content.decode('utf-8')
print(content)
以json字串的方式提交
# 自定義Headers
header = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'content-type': 'application/json;charset=utf-8'
}
data = '{\"coupon\": true}'
res = requests.post('https://msg.csdn.net/v1/web/message/view/unread', headers=header, data=data)
print(res.content.decode('utf-8'))
這里將請求頭的資料放在一個名為header的字典中,然后在請求時通過headers引數傳入,在請求中設定了內容型別是application/json,編碼格式是charset=utf-8
傳入的是一個json字串,通過data引數進行傳入,json字串可以直接寫也可以通過json.dumps(dict)方法將一個字典序列化,就像下面這樣,
import json
data = json.dumps({'coupon': True})
檔案上傳
檔案上傳與本節爬蟲的內容無關,在此就不過多介紹了,有興趣的小伙伴可以看看Python中如何撰寫介面,以及如何請求外部介面 這篇文章,
重定向
在網路請求中,我們常常會遇到狀態碼是3開頭的重定向問題,在Requests中是默認開啟允許重定向的,即遇到重定向時,會自動繼續訪問,通過將allow_redirects 屬性設定為False不允許重定向,
requests.get('https://www.baidu.com/', allow_redirects=False)
設定超時
通過timeout屬性可以設定超時時間,單位是秒,get方法和post方法均可設定,
requests.get('https://www.baidu.com/', timeout=0.1)
獲取回應碼
通過status_code屬性可以獲取介面的回應碼,
# 狀態碼(status_code)
res = requests.get('https://www.baidu.com/')
print('回應碼是=', res.status_code)
禁止證書驗證
有時候我們使用了抓包工具,這時候由于抓包證書提供的證書并不是受信任的數字證書頒發機構頒發的,所以證書的驗證會失敗,所以我們就需要關閉證書驗證,在請求的時候把verify引數設定為False就可以關閉證書驗證了,
requests.get('https://www.baidu.com/', verify=False)
爬蟲協議
爬蟲協議也叫做robots協議,告訴網路蜘蛛哪些頁面可以爬取,哪些頁面不能爬取
爬蟲檔案的規范是:
- 必須將robots.txt 代碼保存為文本檔案
- 必須將該檔案保存到網站的頂級目錄下
- robots.txt 檔案必須命名為robots.txt 檔案
比如要查看百度網站的robots.txt檔案,只需要輸入 https://www.baidu.com/robots.txt 即可
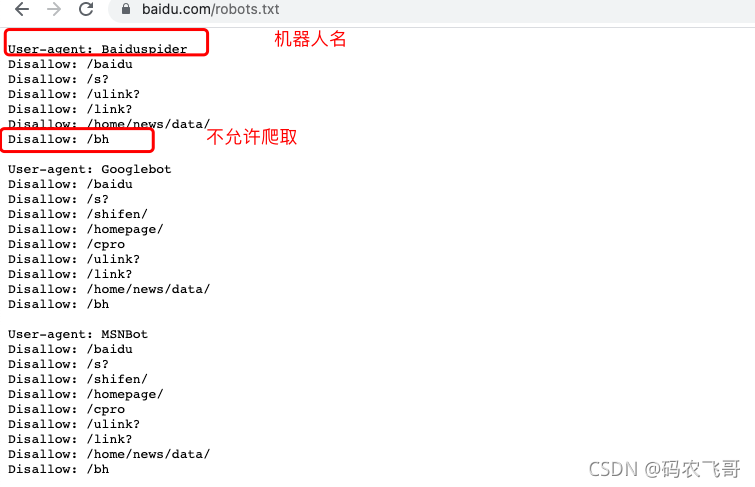
攔截所有的機器人:
User-agent:*
Disallow:/
允許所有的機器人
User-agent:*
Disallow:
豆瓣登錄案例
import requests
# 登錄頁面
img_url = "https://accounts.douban.com/j/mobile/login/basic"
# 添加請求頭
header = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
data = {
'ck': '5oo_',
'name': '1211****',
'password': '121211',
'remember': 'false'
}
# 發送登錄資訊到服務器
images = requests.post(img_url, data=data, verify=False, headers=header)
# 接收服務器回傳的cookies
cookies = images.cookies
# 發送請求
idex = requests.get('https://www.douban.com/', headers=header, cookies=cookies)
print(idex.text)
總結
本文詳細介紹了Request庫的使用
粉絲專屬福利
軟考資料:實用軟考資料
面試題:5G 的Java高頻面試題
學習資料:50G的各類學習資料
脫單秘籍:回復【脫單】
并發編程:回復【并發編程】
👇🏻 驗證碼 可通過搜索下方 公眾號 獲取👇🏻
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/335553.html
標籤:python