假設我有以下資料:
library(tidyverse)
set.seed(123)
col <- tibble(
name = toupper(letters[1:20]),
share = round(rnorm(20, 0.5, 0.1), 2),
active_days = sample.int(50, 20)
)
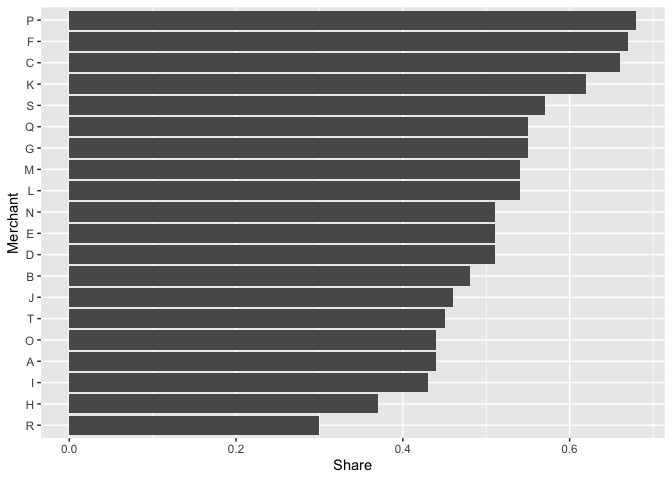
根據上面的代碼繪制它而不使用scale_y_discrete(),我們得到:
col %>%
ggplot(aes(y = reorder(name, share), x = share))
geom_col()
labs(x = "Share",
y = "Merchant")
我想將 的值添加active_days到圖中每個商家的標簽中。這可以使用scale_y_discrete:
col %>%
ggplot(aes(y = reorder(name, share), x = share))
geom_col()
labs(x = "Share",
y = "Merchant")
scale_y_discrete(labels = paste0(col$name, " (", col$active_days, ")"))
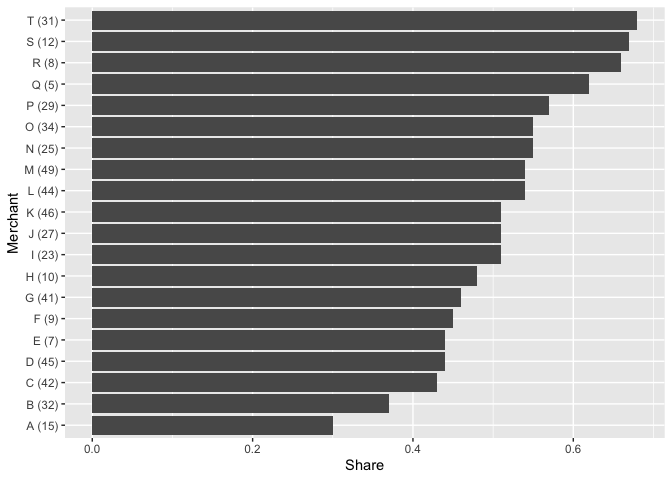
但是,添加會scale_y_discrete更改標簽的順序以反轉字母順序,但值/條以降序正確顯示,給人的印象是,在這種情況下,商家 T 的份額最高,而實際上是商家 P!這顯然是非常不受歡迎的。任何人都知道這里發生了什么,以及如何補救?
uj5u.com熱心網友回復:
由于重新排序,原始 data.frame 中的順序與離散比例感知的順序不同步。如果name資料中沒有重復的s,可以將軸標簽的值與原始資料進行匹配,查找對應的值。
library(tidyverse)
#> Warning: package 'tibble' was built under R version 4.1.1
#> Warning: package 'tidyr' was built under R version 4.1.1
#> Warning: package 'readr' was built under R version 4.1.1
set.seed(123)
col <- tibble(
name = toupper(letters[1:20]),
share = round(rnorm(20, 0.5, 0.1), 2),
active_days = sample.int(50, 20)
)
col %>%
ggplot(aes(y = reorder(name, share), x = share))
geom_col()
labs(x = "Share",
y = "Merchant")
scale_y_discrete(
labels = ~ paste0(
.x, " (", col$active_days[match(.x, col$name)], ")"
)
)
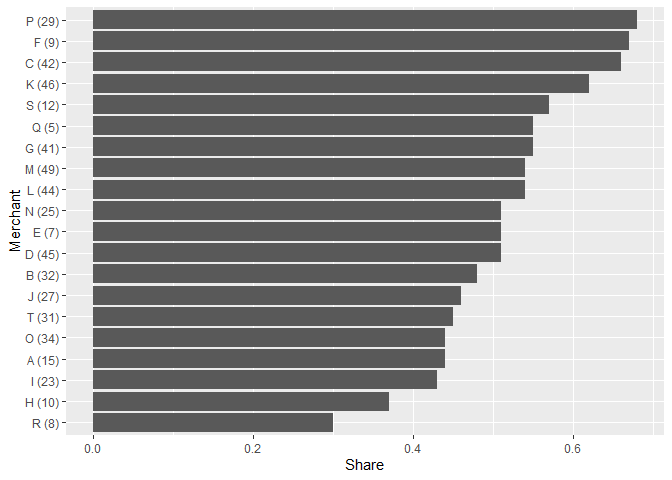
由reprex 包(v2.0.1)于 2021 年 10 月 22 日創建
uj5u.com熱心網友回復:
@teunbrand 的回答完全正確。
如果您的情況允許,在繪圖之前設定因子水平可能更容易。
library(tidyverse)
set.seed(123)
col <- tibble(
name = toupper(letters[1:20]),
share = round(rnorm(20, 0.5, 0.1), 2),
active_days = sample.int(50, 20)
)
col %>%
mutate(breaks = paste0(name, "(", active_days, ")" )) %>%
mutate(breaks = fct_reorder(breaks, share)) %>%
ggplot(aes(y = breaks, x = share))
geom_col()
labs(x = "Share",
y = "Merchant")
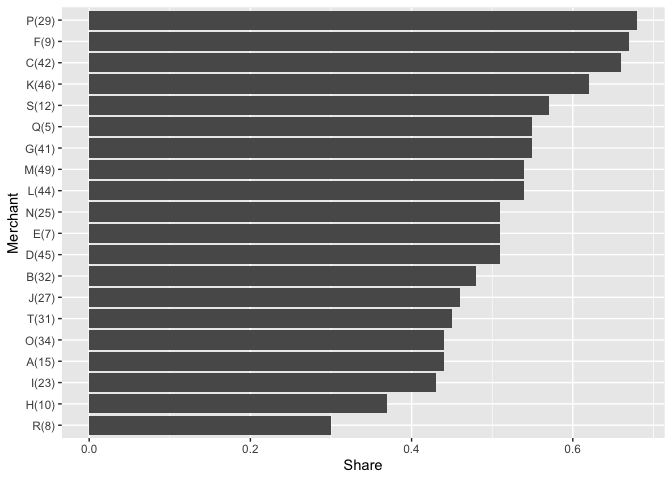
由reprex 包(v2.0.1)于 2021 年 10 月 22 日創建
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/335784.html
上一篇:平行坐標圖中每個級別的單獨y軸