開心一刻
今天和朋友們去K歌,看著這群年輕人一個個唱的賊嗨,不禁感慨道:年輕真好啊!
想到自己年輕的時候,那也是拿著麥克風不放的人
現在的我沒那激情了,只喜歡坐在角落里,默默的聽著他們唱,就連旁邊的妹子都勸我說:大哥別摸了,唱首歌吧

Stream 初體驗
很多時候,我們往往會選擇在資料庫層面進行資料的過濾、匯聚,這就導致我們對 JDK8 的 Stream 應用的特別少,對它也就特別陌生了
但有時候,我們可以將原始資料加載到記憶體,在記憶體中進行資料的過濾和匯聚,這樣可以減少資料庫操作,提高查詢效率(非絕對,資料量不大或走索引的情況下,資料庫查詢也是很快的)
假設我們在記憶體中進行資料的過濾、匯聚,在 JDK8 之前(或不用 JDK8 的 Stream),我們會如何處理? 多次 for 回圈結合 if ,并創建多個集合來存放中間結果,最后對中間結果進行匯聚,代碼量會非常大;如果想牛逼一點,用多執行緒來處理,那就更復雜了(執行緒池、并發等問題),Stream 就解決了這些痛點,如果你的 JDK 版本是 8(或更高),你還在用 for 回圈進行資料的過濾和匯聚,那就有點這味了

那 Stream 到底是何方神圣,讓樓主如此推崇,我們往下看(再不講重點,樓主怕是要收刀片了!)
先聞其聲
我們先來看看她媽是怎么介紹她的: A sequence of elements supporting sequential and parallel aggregate operations.
我們能從中獲取到兩個資訊:
1、Stream 是元素的集合(有點類似 Iterator)
2、對原 Stream 支持順序或并行的匯聚操作
這她媽的介紹還是比較抽象,我們需要從 Stream 自身下手,慢慢去了解她
常見的 Stream 介面繼承關系如下
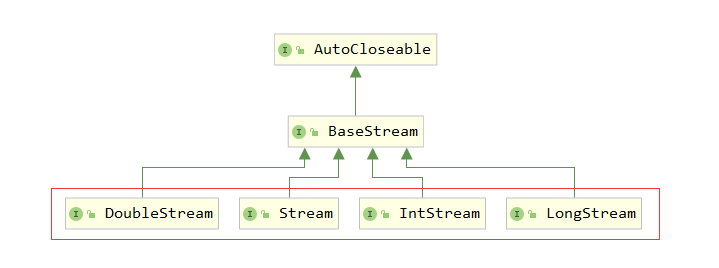
IntStream, LongStream, DoubleStream 對應的是三種基本型別(int, long, double,不是包裝型別),Stream 對應所有剩余型別
為什么不是這樣
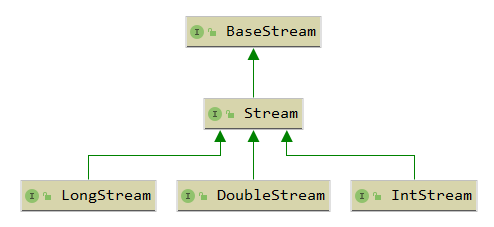
或者取消掉 IntStream, LongStream, DoubleStream,由 Stream 對應所有型別 ?
我們知道基本型別與包裝型別之前的裝箱與拆箱是有性能消耗的,頻繁的轉換會有比較嚴重的性能損耗,所以為不同資料型別設定不同stream介面,可以提高性能,也可以增加特定介面
一睹芳容
上面說了那么多,卻始終未一睹 Stream 的芳容,心里著急呀!我們先來瞟一眼
List<Integer> nums = Arrays.asList(1, 8, 0, 5, 3, 2); // 統計大于 3 的元素個數 long count = nums.stream().filter(e -> e > 3).count();
是不是很美?千萬不要以為 Stream 就這?這還只是她的一條腿,她渾身上下都是寶

通過上面的簡單示例,我們可以剖析出 Stream 的通用語法

也就是說使用 Stream 基本分三步:創建 Steam、轉換Stream、匯聚,下面我們就從這三步詳細介紹 Stream
創建 Stream
Stream 的創建方式有很多,我們只講最常用的兩種
基于陣列: Stream<String> arrayStream = Arrays.stream(new String[]{"123", "abc", "A", "張三"});
基于 Collection: Stream<String> collectionStream = Arrays.asList("123", "abc", "A", "張三").stream();
把陣列變成 Stream 使用 Arrays.stream() 方法;對于 Collection(List、Set、Queue 等),直接呼叫 stream() 方法就可以獲得 Stream
轉換 Stream
轉換 Stream 的目的是對原 Stream 做出某種程度的資料映射/過濾,然后回傳一個新的流,交給下一個操作使用,對原 Stream 是沒有任何影響的,這類操作都是惰性化的(lazy),就是說,僅僅呼叫到這類方法,并沒有真正開始流的遍歷
由于獲取的是一個新的流,而不是我們需要的最終結果,所以 轉換 Stream 這個操作有個官方的稱呼: Intermediate ,即中間操作
具體的轉換操作有很多,我們挑一些常用的來說明一下
distinct
對 Stream 中的元素進行去重操作(去重邏輯依賴元素的 equals 方法),新生成的 Stream 中沒有重復的元素
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5);
Stream<Integer> distinctStream = nums.stream().distinct();

filter
對 Stream 中的每個元素使用給定的過濾條件進行過濾操作,新生成的 Stream 只包含符合條件的元素
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5);
Stream<Integer> filterStream = nums.stream().filter(e -> e >= 2);

map
對 Stream 中的每個元素按給定的轉換規則進行轉換操作,新生成的 Stream 只包含轉換生成的元素
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5);
Stream<String> mapStream = nums.stream().map(e -> e * e + "");

JDK1.8 還提供了三個專門針對基本資料型別的 map 變種方法:mapToInt,mapToLong 和 mapToDouble,這三個方法也比較好理解,就是把原始 Stream 轉換成一個新的 Stream,這個新生成的 Stream 中的元素都是對應的基本型別,之所以會有這三個變種方法,是考慮到自動裝箱/拆箱的額外消耗
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5); IntStream intStream = nums.stream().mapToInt(e -> e * 2); LongStream longStream = nums.stream().mapToLong(e -> 3L * e); DoubleStream doubleStream = nums.stream().mapToDouble(e -> 3.0 * e);
flatMap
與 map 類似
<R> Stream<R> map(Function<? super T, ? extends R> mapper); <R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
不同的是 flatMap 中每個元素轉換得到的是 Stream 物件,然后會把子 Stream 中的元素都放到新的 Stream 中
List<List<String>> groupList = Arrays.asList(Arrays.asList("q","w","e"), Arrays.asList("a", "s", "d"), Arrays.asList("z","x", "c"));
Stream<String> superStarStream = groupList.stream().flatMap(group -> group.stream().map(e -> e + 1));

簡單點理解就是:把幾個小的集合中的元素經過處理后合并到一個大的集合中
類似的,JDK1.8 也提供了三個專門針對基本資料型別的 flatMap 變種方法:flatMapToInt,flatMapToLong 和 flatMapToDouble
limit
拷貝原 Stream 中的前 N 個元素到新的 Stream 中,如果原 Stream 中包含的元素個數小于 N,那就獲取其所有的元素
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5);
Stream<Integer> limitStream = nums.stream().limit(4);

skip
拷貝原 Stream 除了前 N 個元素后剩下的所有元素到新 Stream,如果原 Stream 中包含的元素個數小于 N,那么回傳空 Stream
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5);
Stream<Integer> skipStream = nums.stream().skip(4);

sorted
對原 Stream 進行排序操作,得到一個新的、有序的 Stream
排序函式有兩個,一個是用自然順序排序,一個是使用自定義比較器排序
Stream<T> sorted(); Stream<T> sorted(Comparator<? super T> comparator);
使用起來非常簡單,如下所示
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5); // 自然排序,默認升序排序 Stream<Integer> sortedStream = nums.stream().sorted(); // 自定義排序 Stream<Integer> sortedCompareStream = nums.stream().sorted((a, b) -> b.compareTo(a));
peek
Stream<T> peek(Consumer<? super T> action);
生成一個包含原 Stream 所有元素的新 Stream,同時會提供一個消費函式(Consumer 實體),新 Stream 每個元素被消費的時候都會執行給定的消費函式
與 map 很像,但不會影響新 Stream 中的元素(還是原 Stream 中的元素),可以做一些輸出,外部處理等輔助操作
這個在實際專案中用的不多,知道是怎么回事就好
匯聚
匯聚操作接受一個 Stream 為輸入,反復使用某個匯聚操作,把 Stream 中的元素合并成一個匯總的結果,匯總結果可能是某個值,也可能是一個集合
匯聚操作能夠得到我們需要的最終結果,相當于一個終止操作,所以也有另一個稱呼: Terminal ,即結束操作
一個流只能有一個 terminal 操作,當這個操作執行后,流就被使用“光”了,無法再被操作,所以這必定是流的最后一個操作,Terminal 操作的執行,才會真正開始流的遍歷
JDK1.8 提供了很多常用的匯聚操作,我們一起來看看
foreach
這個類似我們平時的 for 回圈,遍歷 Stream 中的元素,執行指定的操作
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5);
nums.stream().forEach(num -> System.out.println(num));
max min count
作用就是字面意思
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5); // 求最大值 Integer max = nums.stream().max(Comparator.naturalOrder()).get(); // 求最小值 Integer min = nums.stream().min(Comparator.naturalOrder()).get(); // 求元素個數 long count = nums.stream().count(); System.out.println("max = " + max); System.out.println("min = " + min); System.out.println("count = " + count);
findFirst
回傳一個 Optional,它包含了 Stream 中的第一個元素,若 Stream 是空的,則回傳一個空的 Optional
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5);
Integer firstNum = nums.stream().findFirst().get();
findAny
回傳一個 Optional,它包含了 Stream 中的任意一個元素,若 Stream 是空的,則回傳一個空的 Optional
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5);
Integer anyNum = nums.stream().findAny().get();
在串行的流中,findAny 和 findFirst回傳的,都是第一個物件;而在并行的流中,findAny 回傳的是最快處理完的那個執行緒的資料,所以說,在并行操作中,對資料沒有順序上的要求,那么 findAny 的效率會比 findFirst 要快的,但是沒有 findFirst 穩定
anyMatch
Stream 中是否有任意一個元素滿足判斷條件,有則回傳 true
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5); boolean matchResult = nums.stream().anyMatch(num -> num > 2);
allMatch
Stream 中所有元素都滿足判斷條件則回傳 true
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5); boolean matchResult = nums.stream().allMatch(num -> num > 2);
noneMatch
與 allMatch 相反,Stream 中所有元素都不滿足判斷條件,則回傳 true
List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5); boolean matchResult = nums.stream().noneMatch(num -> num > 7);
reduce
reduce 的主要作用是把 Stream 元素組合起來
它提供一個起始值(種子),然后依照運算規則(BinaryOperator),和 Stream 中的第一個、第二個、第 n 個元素組合,生成一個我們需要的值
JDK 提供了三種 reduce
T reduce(T identity, BinaryOperator<T> accumulator); Optional<T> reduce(BinaryOperator<T> accumulator); <U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
引數不同,其回傳值型別是有所不同的,但其語意、作用還是一樣的
max()、min()其實都是特殊的 reduce,只是因為它們比較常用,所以就簡化書寫專門設計出了它們
@Override public final Optional<P_OUT> max(Comparator<? super P_OUT> comparator) { return reduce(BinaryOperator.maxBy(comparator)); } @Override public final Optional<P_OUT> min(Comparator<? super P_OUT> comparator) { return reduce(BinaryOperator.minBy(comparator)); }
reduce 在實際專案中用的不多,又非常靈活,我們就簡單看幾個示例


List<Integer> nums = Arrays.asList(1, 2, 1, 3, 2, 5); // 求和,相當于sum(); 有起始值 Integer sum1 = nums.stream().reduce(0, Integer::sum); Integer sum2 = nums.stream().reduce(0, (a,b) -> a + b); // 求和,相當于sum(); 無起始值 Integer sum3 = nums.stream().reduce(Integer::sum).get(); System.out.println("sum = " + sum1 + ", sum2 = " + sum2 + ", sum3 = " + sum3); // 求最大值,相當于max() Integer max = nums.stream().reduce(Integer.MIN_VALUE, Integer::max); System.out.println("max = " + max); // 求最小值,相當于min() Integer min = nums.stream().reduce(Integer.MAX_VALUE, Integer::min); System.out.println("min = " + min);View Code
reduce 擅長的是生成一個值,如果想要從 Stream 生成一個集合或者 Map 等復雜的物件該怎么辦呢?就需要 collect 出馬了
collect
collect 是 Stream 介面中最靈活的,也是最強大的;JDK 中提供了兩種 collect
// Supplier supplier是一個工廠函式,用來生成一個新的容器; // BiConsumer accumulator也是一個函式,用來把Stream中的元素添加到結果容器中 // BiConsumer combiner還是一個函式,用來把中間狀態的多個結果容器合并成為一個(并發的時候會用到) <R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner); <R, A> R collect(Collector<? super T, A, R> collector);
我們來各看一個案例
List<String> strList = Arrays.asList("123","abc", "1w1");
String concat = strList.stream().collect(StringBuilder::new, StringBuilder::append, StringBuilder::append).toString();
System.out.println(concat);
List<String> stringList = strList.stream().collect(Collectors.toList());
實際應用中,基本上用的是第二種,而且用的是 JDK 中已經提供好的 Collector,在 Collectors 中提供了很多常用的 Collector, 如下
我們挑一些比較常用的來說明下,有興趣的可以去通讀下
轉集合
toList、toSet、toMap
public class StreamTest { public static void main(String[] args) { Person[] personArray = { new Person("shangsan", 23), new Person("張三", 23), new Person("lisi", 24), new Person("李四", 24), new Person("wangwu", 20), new Person("王五", 20)}; // 轉 list List<Person> personList = Arrays.stream(personArray).collect(Collectors.toList()); // 轉 set Set<Person> personSet = Arrays.stream(personArray).collect(Collectors.toSet()); // 轉 map, key為 name, value 為 Person 實體 Map<String, Person> personMap = Arrays.stream(personArray).collect(Collectors.toMap(Person::getName, person -> person)); System.out.println(personList); System.out.println(personSet); System.out.println(personMap); } static class Person { private String name; private Integer age; Person(){} Person(String name, Integer age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } } }View Code
toMap 有兩個注意點
1、底層呼叫的是 map.merge 方法,該方法遇到 value 為 null 的情況會報 npe
2、遇到重復的 key 會直接拋 IllegalStateException,因為未指定沖突合并策略,也就是第三個引數BinaryOperator<U> mergeFunction
分組
public class StreamTest { public static void main(String[] args) { Person[] personArray = { new Person("shangsan", 23), new Person("張三", 23), new Person("lisi", 24), new Person("李四", 24), new Person("wangwu", 20), new Person("王五", 20)}; // 根據年齡進行分組 Map<Integer, List<Person>> ageGroup = Arrays.stream(personArray).collect(Collectors.groupingBy(Person::getAge)); System.out.println(ageGroup); } static class Person { private String name; private Integer age; Person(){} Person(String name, Integer age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } } }View Code
求和
// 年齡求和 summingInt、summingLong、summingDouble 類似 Integer ageSum = Arrays.stream(personArray).collect(Collectors.summingInt(Person::getAge)); System.out.println("age sum = " + ageSum);
求平均值
// 求平均值 averagingInt、averagingLong、averagingDouble 類似 Double averageAge = Arrays.stream(personArray).collect(Collectors.averagingInt(Person::getAge)); System.out.println("average age = " + averageAge);
其他
// 統計人數 Long count = Arrays.stream(personArray).collect(Collectors.counting()); System.out.println("人數 = " + count); List<Integer> intList = Arrays.asList(1, 2, 3, 1, 5, 2); // 求和 Integer sum = intList.stream().collect(Collectors.reducing(0, (a, b) -> a + b)); System.out.println("sum = " + sum); // 字串拼接 List<String> strList = Arrays.asList("123", "abc", "666"); String str = strList.stream().collect(Collectors.joining(",", "(", ")")); System.out.println(str);
并行流
前面講了那么多,都是基于順序流(Stream),JDK1.8 也提供了并行流: parallelStream ,使用起來非常簡單,通過 parallelStream() 可能創建并行流,流的操作還是和順序流一樣
List<Integer> intList = Arrays.asList(1, 2, 3, 1, 5, 2); boolean result = intList.parallelStream().anyMatch(e -> e > 5); System.out.println("result = " + result);
顧名思義,并行流可以運用多核特性(forkAndJoin)進行并行處理,從而大幅提高效率,既然能提高效率,為什么實際專案中,順序流用的更多,而并行流用的非常少了,還是有一些原因的
1、parallelStream 是執行緒不安全的
一旦出現并發問題,大家都懂的,非常頭疼
2、parallelStream 適用于 CPU 密集型任務
如果 CPU 負載已經很大,還用并行流,不但不會提高效率,反而會降低效率
并行流不適用于 I/O 密集型任務,很可能會造成 I/O 阻塞
3、并行流無法保證元素順序,輸出結果具有不確定性
如果我們的業務需要關注元素先后順序,那么不能用并行流
4、lambda 的執行并不是瞬間完成的,所有使用 parallel stream 的程式都有可能成為阻塞程式的源頭
總結
Stream 特點
無存盤:Stream 不是資料結構并不保存資料,它是有關演算法和計算的,它只是某種資料源的一個視圖,資料源可以是一個陣列,Java 容器或 I/O channel
函式式編程:每次轉換,原有 Stream 不改變,回傳一個新的 Stream 物件,這就允許對其操作可以像鏈條一樣排列;轉換程序可以多次
惰性執行:Stream 上的轉換操作(中間操作)并不會立即執行,只有執行匯聚操作(終止操作)時,轉換操作才會執行
一次消費:Stream 只能被使用一次,一旦遍歷過就會失效,就像容器的迭代器那樣,想要再次遍歷必須重新生成
Stream 優點
代碼簡潔且易理解,這個感受是最明顯的,用與不用 Stream,代碼量與可閱讀性相差甚遠
多核友好,如果想多執行緒處理,只需要調一下 parallel() 方法,僅此而已
Stream 操作分類
分兩類:中間操作(Intermediate)、結束操作(Terminal)
中間操作總是會惰式執行,呼叫中間操作只會生成一個標記了該操作的新 stream,僅此而已
結束操作會觸發實際計算,計算發生時會把所有中間操作積攢的操作以 pipeline 的方式執行,這樣可以減少迭代次數;計算完成之后stream就會失效

性能問題
在對于一個 Stream 進行多次轉換操作 (Intermediate 操作),每次都對 Stream 的每個元素進行轉換,而且是執行多次,這樣時間復雜度就是 N(轉換次數)個 for 回圈里把所有操作都做掉的總和嗎?其實不是這樣的,轉換操作都是 lazy 的,多個轉換操作只會在 Terminal 操作的時候融合起來,一次回圈完成,我們可以這樣簡單的理解,Stream 里有個操作函式的集合,每次轉換操作就是把轉換函式放入這個集合中,在 Terminal 操作的時候回圈 Stream 對應的集合,然后對每個元素執行所有的函式
關于順序流、并行流、傳統 for 的性能問題,大家看看這個:Java Stream API性能測驗、for回圈與串行化、并行化Stream流性能對比
參考
Java 8 中的 Streams API 詳解
JDK8函式式編程之Stream API
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/33606.html
標籤:Java