微信搜索公眾號路人zhang,回復面試手冊,領取更多高頻面試題PDF版及更多面試資料,

文章目錄
- 1.了解static嗎,static資料存在哪?生命周期什么樣的
- 2.了解final嗎,講講下面這段代碼的結果
- 3.講講volatile吧
- 4.講講兩個鎖的區別(`reentrantlock`和`synchronized`)
- 5.講講執行緒池的創建與銷毀,核心執行緒可以銷毀嗎?
- 6.高并發怎么減少鎖的競爭
- 7.了解類加載機制嗎,講講下面這段代碼運行結果
- 8.hashMap為什么大小是冪次
- 9.euqal和==的區別,equal沒有重寫的時候默認是什么
- 10.寫個sql吧,學號 學生姓名 科目 成績 班級,選出每個班的每個科目最高分
- 11.linux的tail -f命令里的f是什么意思
- 12.用過grep嗎,會正則嗎
- 13.mysql 事務的特性
- 14.char和varchar的區別
- 15.如果我一個欄位是char(10),我只存三個位元組進去,它底層檔案占幾個位元組
- 16.計算機網路:TCP如何保證資料包不丟、不重、不亂、完整性
- 17.自動拆箱裝箱了解嗎
- 18.有重復元素的升序陣列里找到下標最小的目標值
1.了解static嗎,static資料存在哪?生命周期什么樣的
從Java虛擬機相關知識可知,和運行資料區主要分為五個部分,分別是程式計數器、Java虛擬機堆疊、本地方法堆疊、堆、方法區,
其中方法區主要用于存盤已被虛擬機加載的類資訊、常量、靜態變數、即時編譯后的代碼等資料,
static資料的生命周期就是類的生命周期,Java虛擬機會在加載類的程序中為靜態變數分配記憶體,一個類的完整的生命周期會經歷加載、連接、初始化、使用、和卸載五個階段,
2.了解final嗎,講講下面這段代碼的結果
String s = "hello2";
final String s2 = "hello";
String s3 = s2+2;
System.out.println(s==s3);
這個題很有意思,以后可以展開寫寫篇博客,這里先簡單解釋下,結論是True,原因也很簡單,就是s指向的是常量池中的hello2,經過final修飾的s2在編譯器也會被決議為常量放到常量池,s2+2相當于兩個常量相加,結果還是常量,所以s3也指向常量池中的hello2,常量池中的值都是唯一的,所以s和s3指向的值是同一個值,所以結果是True,
String s = "hello2"
String s1 = "hello2"
String s2 = new String("hello2")
為了方便理解,可以看下圖,不過字串常量區也是在堆中的,有些資料也說在方法區,我是傾向于在堆中,這里就先不展開解釋了
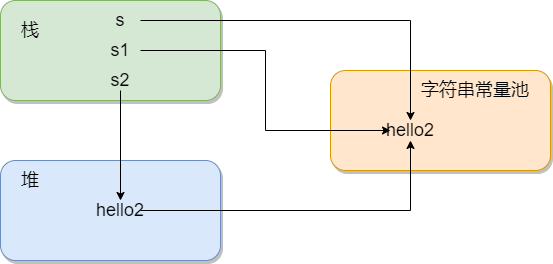
其中,s和s1都是指向字串常量池中的hello2,而s2則是通過new關鍵字生成的一個新的物件,因為字串常量池中已經有了hello2,所以會將他們直接聯系起來,如果也會在字串常量池中創建一個hello2
有了上面這些基礎,就好辦多了,先看這個代碼:
String s = "hello2";
String s1 = "hello";
String s2 = "hello" + 2;
System.out.println(s==s2);
**分析:**不難猜出這個答案是true,因為s指向字串常量池中的hello2,而hell0和2兩個常量相加也會直接存放到字串常量池中,所以s2也是直接指向字串常量池中的hello2,前面也說過了字串常量池中的值都是唯一的,所以s和s2指向的是同一個值,
下面再來看這個代碼,猜猜看運行結果是什么樣的
String s = "hello2";
String s1 = "hello";
String s2 = "2"
String s3 = s1 + s2;
System.out.println(s==s3);
**分析:**這個答案是false,是不是有些意外,了解這個代碼流程就能搞明白了:
- 在堆疊中存在s,s指向字串常量池中的
hello2 - 在堆疊中存在s1,s1指向字串常量池中的
hello - 在堆疊中存在s2,s2指向字串常量池中的
2 - 在堆疊中存放s3,而
s1+s2則會通過StringBuilder中的toString()方法在堆中創建一個hello2
結合上面的圖,這時就可以看出來s指向字串常量池中的hello2,而s3則指向堆中的hello2,輸出為false
同理,再看看這段代碼就不能猜到結果了:
String s = "hello2";
String s1 = "hello";
String s2 = s1 + 2;
System.out.println(s==s2);
**分析:**沒錯,答案是false,原因同上,從jvm的角度來理解就是,字串常量之間的+操作是在編譯期就已經確定的了,而參考的值是在編譯期無法確定的,所以是在運行期進行的,新創建的物件也會放在堆中,
最后活到原問題,看問題中的代碼,用final關鍵字修飾了s2
String s = "hello2";
final String s2 = "hello";
String s3 = s2+2;
System.out.println(s==s3);
s2被final關鍵字修飾后則會在編譯期就決議為一個常量值放到常量池中,所以這個題目的最終結果是True
3.講講volatile吧
話不多說直接上鏈接:
4.講講兩個鎖的區別(reentrantlock和synchronized)
這也是一個高頻面試題
從幾個方面簡單說下兩者的區別:
-
底層實作
synchronized是JVM層面的鎖,也是Java的關鍵字,通過monitor物件進行完成的,ReentrantLock是JDK提供的API層面的鎖 -
是否需要手動釋放
synchronized不需要用戶去手動釋放鎖,ReentrantLock則需要用戶去手動釋放鎖, -
是否可中斷
synchronized是不可中斷型別的鎖,ReentrantLock是可以中斷的 -
是否可以系結條件
synchronized不能系結,ReentrantLock可以通過系結Condition并結合await()/singal()方法對執行緒進行精準喚醒
關于synchronized的更多細節可以看這篇文章:
5.講講執行緒池的創建與銷毀,核心執行緒可以銷毀嗎?
執行緒池的創建:
執行緒池的常用創建方式主要有兩種,通過Executors工廠方法創建和**通過new ThreadPoolExecutor**方法創建,
- Executors工廠方法創建,在工具類 Executors 提供了一些靜態的工廠方法
newSingleThreadExecutor:創建一個單執行緒的執行緒池,newFixedThreadPool:創建固定大小的執行緒池,newCachedThreadPool:創建一個可快取的執行緒池,newScheduledThreadPool:創建一個大小無限的執行緒池,
new ThreadPoolExecutor方法創建: 通過newThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)自定義創建
執行緒池的關閉:
執行緒池的關閉可以呼叫執行緒池中的shutdown或shutdownNow方法進行關閉,它們會遍歷執行緒池中的作業執行緒,然后呼叫每個執行緒的interrupt方法來中斷執行緒,
核心執行緒可以銷毀嗎?這個問題需要看下原始碼,這里就不展開了,當執行緒池未呼叫 shutdown 方法時,是通過佇列的take方法阻塞核心執行緒的run方法從而保證核心執行緒不會被銷毀的,如果想銷毀核心執行緒可以通過呼叫執行緒池物件的allowCoreThreadTimeOut(true)方法,
6.高并發怎么減少鎖的競爭
- 降低鎖的粒度
- 縮小鎖的范圍
- 避免使用獨占鎖
7.了解類加載機制嗎,講講下面這段代碼運行結果
class Father{
private String a = "father";
public Father(){
say();
}
public void say(){
System.out.println("i'm father"+a);
}
}
class Sub extends Father{
private String a = "child";
@Override public void say(){
System.out.println("i'm child"+a);
}
}
public class Test {
public static void main(String[] args) {
Father father = new Father();
Sub sub = new Sub();
}
}
類的加載機制:虛擬機把描述類的資料從class檔案加載到記憶體,并對資料進行校驗,轉換決議和初始化,最終形成可以被虛擬機直接使用的Java型別,這就是虛擬機的類加載機制,
這段代碼的運行結果還是有些古怪的
i'm fatherfather
i'm childnull
大家可以先記住代碼執行順序:
靜態代碼塊(父) > 靜態代碼塊(子) > 實體成員變數(父) > 構造代碼塊(父) > 構造方法(父) > 實體成員變數(子) > 構造代碼塊(子) > 構造方法(子)
在本題中的執行順序如下:
Father father = new Father();—>private String a = "father";—>public Father( { say() ;}—>執行say()方法,結果為i'm fatherfather
Sub sub = new Sub();—>private String a = "father";—>public Father( { say() ;}—>呼叫子類的say()方法,因為子類的實體成員變數并未初始化,所以結果為i'm childnull
8.hashMap為什么大小是冪次
因為HashMap是通過key的hash值來確定存盤的位置,但Hash值的范圍是-2147483648到2147483647,不可能建立一個這么大的陣列來覆寫所有hash值,所以在計算完hash值后會對陣列的長度進行取余操作,如果陣列的長度是2的冪次方,(length - 1)&hash等同于hash%length,可以用(length - 1)&hash這種位運算來代替%取余的操作進而提高性能,
更多HashMap相關面試題:
9.euqal和==的區別,equal沒有重寫的時候默認是什么
區別:
-
==
對于基本資料型別,
==比較的是值;對于參考資料型別,==比較的是記憶體地址, -
eauals
對于沒有重寫
equals方法的類,equals方法和==作用類似;對于重寫過equals方法的類,equals比較的是值,
如果沒有重寫equal(),那么equals和==的作用相同,比較的是物件的地址值,
更詳細的相關面試題:
10.寫個sql吧,學號 學生姓名 科目 成績 班級,選出每個班的每個科目最高分
SELECT MAX(成績) FROM 學生 GROUP BY 班級,科目
11.linux的tail -f命令里的f是什么意思
tail 命令可用于查看檔案的內容,其中-f是回圈讀取的意思
12.用過grep嗎,會正則嗎
grep 命令主要用于查找檔案里符合條件的字串,簡單背它的常用引數就行了
13.mysql 事務的特性
- 原子性:原子性是指包含事務的操作要么全部執行成功,要么全部失敗回滾,
- 一致性:一致性指事務在執行前后狀態是一致的,
- 隔離性:一個事務所進行的修改在最終提交之前,對其他事務是不可見的,
- 持久性:資料一旦提交,其所作的修改將永久地保存到資料庫中,
14.char和varchar的區別
字串常用的主要有CHAR和VARCHAR,VARCHAR主要用于存盤可變長字串,相比于定長的CHAR更節省空間,CHAR是定長的,根據定義的字串長度分配空間,
15.如果我一個欄位是char(10),我只存三個位元組進去,它底層檔案占幾個位元組
10個,剩余七個會用空格填充,
16.計算機網路:TCP如何保證資料包不丟、不重、不亂、完整性
其實就是問TCP如何保證可靠傳輸
主要有校驗和、序列號、超時重傳、流量控制及擁塞避免等幾種方法,
-
校驗和:在發送算和接收端分別計算資料的校驗和,如果兩者不一致,則說明資料在傳輸程序中出現了差錯,TCP將丟棄和不確認此報文段,
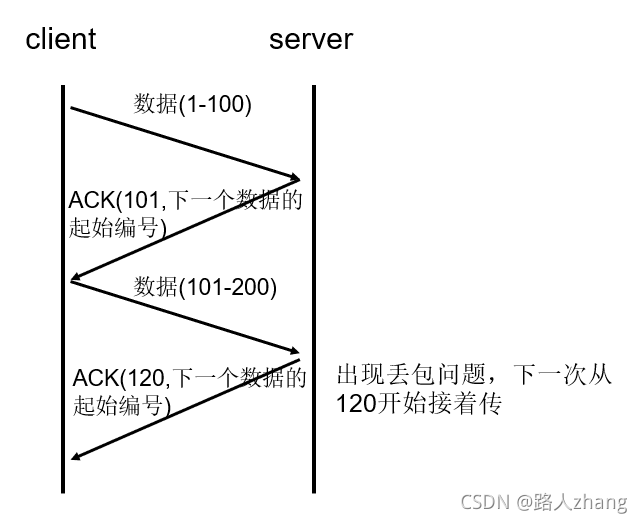
-
序列號:TCP會對每一個發送的位元組進行編號,接收方接到資料后,會對發送方發送確認應答(ACK報文),并且這個ACK報文中帶有相應的確認編號,告訴發送方,下一次發送的資料從編號多少開始發,如果發送方發送相同的資料,接收端也可以通過序列號判斷出,直接將資料丟棄,如果
-
超時重傳:在上面說了序列號的作用,但如果發送方在發送資料后一段時間內(可以設定重傳計時器規定這段時間)沒有收到確認序號ACK,那么發送方就會重新發送資料,
這里發送方沒有收到ACK可以分兩種情況,如果是發送方發送的資料包丟失了,接收方收到發送方重新發送的資料包后會馬上給發送方發送ACK;如果是接收方之前接收到了發送方發送的資料包,而回傳給發送方的ACK丟失了,這種情況,發送方重傳后,接收方會直接丟棄發送方沖重傳的資料包,然后再次發送ACK回應報文,
如果資料被重發之后還是沒有收到接收方的確認應答,則進行再次發送,此時,等待確認應答的時間將會以2倍、4倍的指數函式延長,直到最后關閉連接,
-
流量控制:如果發送端發送的資料太快,接收端來不及接收就會出現丟包問題,為了解決這個問題,TCP協議利用了滑動視窗進行了流量控制,在TCP首部有一個16位欄位大小的視窗,視窗的大小就是接收端接收資料緩沖區的剩余大小,接收端會在收到資料包后發送ACK報文時,將自己的視窗大小填入ACK中,發送方會根據ACK報文中的視窗大小進而控制發送速度,如果視窗大小為零,發送方會停止發送資料,
-
擁塞控制:如果網路出現擁塞,則會產生丟包等問題,這時發送方會將丟失的資料包繼續重傳,網路擁塞會更加嚴重,所以在網路出現擁塞時應注意控制發送方的發送資料,降低整個網路的擁塞程度,擁塞控制主要有四部分組成:慢開始、擁塞避免、快重傳、快恢復,如下圖(圖片來源于網路),
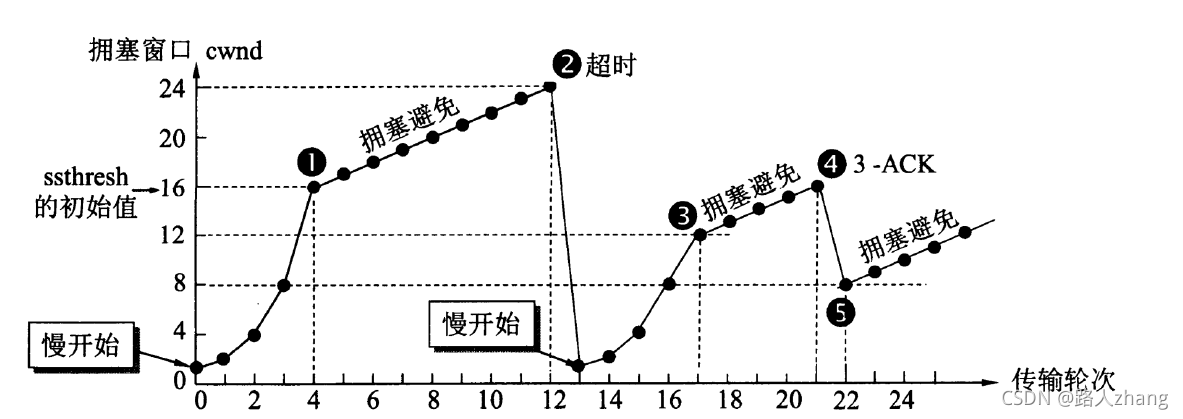
這里的發送方會維護一個擁塞視窗的狀態變數,它和流量控制的滑動視窗是不一樣的,滑動視窗是根據接收方資料緩沖區大小確定的,而擁塞視窗是根據網路的擁塞情況動態確定的,一般來說發送方真實的發送視窗為滑動視窗和擁塞視窗中的最小值,-
慢開始:為了避免一開始發送大量的資料而產生網路阻塞,會先初始化cwnd為1,當收到ACK后到下一個傳輸輪次,cwnd為2,以此類推成指數形式增長,
-
擁塞避免:因為cwnd的數量在慢開始是指數增長的,為了防止cwnd數量過大而導致網路阻塞,會設定一個慢開始的門限值ssthresh,當cwnd>=ssthresh時,進入到擁塞避免階段,cwnd每個傳輸輪次加1,但網路出現超時,會將門限值ssthresh變為出現超時cwnd數值的一半,cwnd重新設定為1,如上圖,在第12輪出現超時后,cwnd變為1,ssthresh變為12,
-
快重傳:在網路中如果出現超時或者阻塞,則按慢開始和擁塞避免演算法進行調整,但如果只是丟失某一個報文段,如下圖(圖片來源于網路),則使用快重傳演算法,
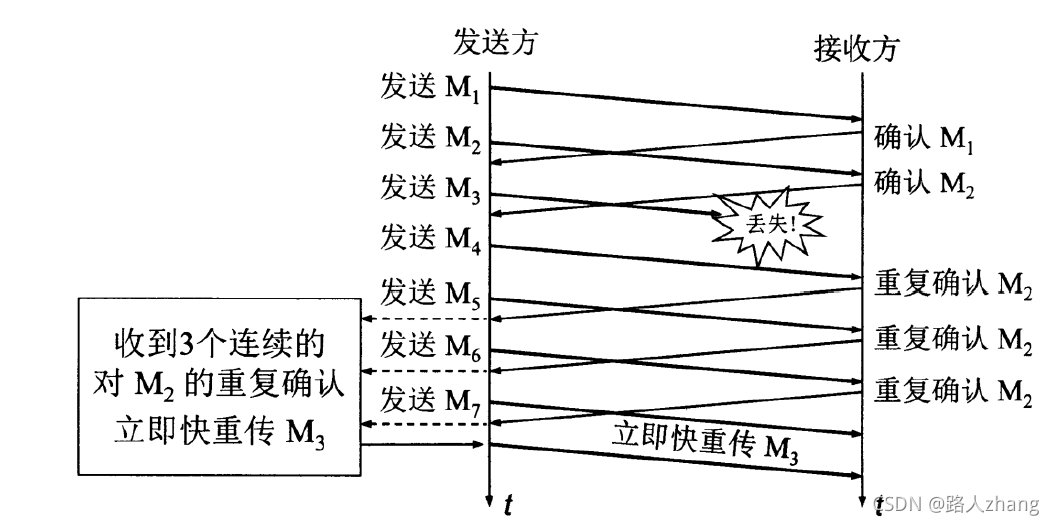
從上圖可知,接收方正確地接收到M1和M2,而M3丟失,由于沒有接收到M3,在接收方收到M5、M6和M7時,并不會進行確認,也就是不會發送ACK,這時根據前面說的保證TCP可靠性傳輸中的序列號的作用,接收方這時不會接收M5,M6,M7,接收方可以什么都不會,因為發送方長時間未收到M3的確認報文,會對M3進行重傳,除了這樣,接收方也可以重復發送M2的確認報文,這樣發送端長時間未收到M3的確認報文也會繼續發送M3報文,但是根據快重傳演算法,要求在這種情況下,需要快速向發送端發送M2的確認報文,在發送方收到三個M2的確認報文后,無需等待重傳計時器所設定的時間,可直接進行M3的重傳,這就是快重傳,(面試時說這一句就夠了,前面是幫助理解)
-
快恢復:從上上圖圈4可以看到,當發送收到三個重復的ACK,會進行快重傳和快恢復,快恢復是指將ssthresh設定為發生快重傳時的cwnd數量的一半,而cwnd不是設定為1而是設定為為門限值ssthresh,并開始擁塞避免階段,
-
17.自動拆箱裝箱了解嗎
- 裝箱:將基本型別用包裝器型別包裝起來
- 拆箱:將包裝器型別轉換為基本型別
18.有重復元素的升序陣列里找到下標最小的目標值
這題目不難,有序陣列基本就是二分,不要對其直接進行遍歷就好了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/336229.html
標籤:java
上一篇:Java后端學習路線梳理