行定位符、單詞定界符實體用法(正則運算式字符集1)
行定位符(^和$):行定位符就是用來描述字串的邊界,"^"表示行的開始;"$"表示行的結尾,如:
^tm
這個運算式表示要匹配字串I的開始位置是行頭,如:tm equal Tomorrow Moon就可以匹配,而Tomorrow Moon equal tm就不可以匹配
tm$
則后者可以匹配而前者不可以,如果想要匹配的字串可以出現在字串的任意部分,那么可以直接寫成:
tm
單詞定界符(\b、\B):
使用tm可以匹配在字串中出現的任何位置,那么類似html,utmost中的tm也會被查找出來,但現在需要匹配的是單詞tm,而不是單詞的一部分,這時可以使用單詞定界符\b,表示要查找的字串為一個完整的單詞,如:
\btm\b
還有一個大寫的\B,意思和\b相反,它匹配的字串不能是一個完整的單詞,而是其他單詞或字串的一部分,如:
\Btm\B
非列印字符、特殊字符、限定符實體用法
非列印字符
\cx 匹配由x指明的控制字符,例如, \cM 匹配一個 Control-M 或回車符,x 的值必須為 A-Z 或 a-z 之一,否則,將 c 視為一個原義的 ‘c’ 字符,
\f 匹配一個換頁符,等價于 \x0c 和 \cL,
\n 匹配一個換行符,等價于 \x0a 和 \cJ,
\r 匹配一個回車符,等價于 \x0d 和 \cM,
\s 匹配任何空白字符,包括空格、制表符、換頁符等等,等價于 [ \f\n\r\t\v],
\S 匹配任何非空白字符,等價于 [^ \f\n\r\t\v],
\t 匹配一個制表符,等價于 \x09 和 \cI,
\v 匹配一個垂直制表符,等價于 \x0b 和 \cK,
特殊字符
$ 匹配輸入字串的結尾位置,如果設定了 RegExp 物件的 Multiline 屬性,則 $ 也匹配 ‘\n’ 或 ‘\r’,要匹配 $ 字符本身,請使用 \$,
( ) 標記一個子運算式的開始和結束位置,子運算式可以獲取供以后使用,要匹配這些字符,請使用 \( 和 \),
* 匹配前面的子運算式零次或多次,要匹配 * 字符,請使用 \*,
+ 匹配前面的子運算式一次或多次,要匹配 + 字符,請使用 \+,
. 匹配除換行符 \n之外的任何單字符,要匹配 .,請使用 \,
[ 標記一個中括號運算式的開始,要匹配 [,請使用 \[,
? 匹配前面的子運算式零次或一次,或指明一個非貪婪限定符,要匹配 ? 字符,請使用 \?,
\ 將下一個字符標記為或特殊字符、或原義字符、或向后參考、或八進制轉義符,例如, ‘n’ 匹配字符 ‘n’,’\n’ 匹配換行符,序列 ‘\\’ 匹配 “\”,而 ‘\(’ 則匹配 “(”,
^ 匹配輸入字串的開始位置,除非在方括號運算式中使用,此時它表示不接受該字符集合,要匹配 ^ 字符本身,請使用 \^,
{ 標記限定符運算式的開始,要匹配 {,請使用 \{,
| 指明兩項之間的一個選擇,要匹配 |,請使用 \|,
限定符
有*或+或?或{n}或{n,}或{n,m}共6種,
*、+和?限定符都是貪婪的,因為它們會盡可能多的匹配文字,只有在它們的后面加上一個?就可以實作非貪婪或最小匹配,
* 匹配前面的子運算式零次或多次,例如,zo* 能匹配 “z” 以及 “zoo”,* 等價于{0,},
+ 匹配前面的子運算式一次或多次,例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”,+ 等價于 {1,},
? 匹配前面的子運算式零次或一次,例如,”do(es)?” 可以匹配 “do” 或 “does” 中的”do” ,? 等價于 {0,1},
{n} n 是一個非負整數,匹配確定的 n 次,例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的兩個 o,
{n,} n 是一個非負整數,至少匹配n 次,例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o,’o{1,}’ 等價于 ‘o+’,’o{0,}’ 則等價于 ‘o*’,
{n,m} m 和 n 均為非負整數,其中n <= m,最少匹配 n 次且最多匹配 m 次,例如,”o{1,3}” 將匹配 “fooooood” 中的前三個 o,’o{0,1}’ 等價于 ‘o?’,請注意在逗號和兩個數之間不能有空格,
正則運算式字符簇
[a-z] //匹配所有的小寫字母
[A-Z] //匹配所有的大寫字母
[a-zA-Z] //匹配所有的字母
[0-9] //匹配所有的數字
[0-9\.\-] //匹配所有的數字,句號和減號
[ \f\r\t\n] //匹配所有的白字符
PHP的正規運算式有一些內置的通用字符簇,串列如下:
[[:alpha:]] 任何字母
[[:digit:]] 任何數字
[[:alnum:]] 任何字母和數字
[[:space:]] 任何白字符
[[:upper:]] 任何大寫字母
[[:lower:]] 任何小寫字母
[[:punct:]] 任何標點符號
[[:xdigit:]] 任何16進制的數字,相當于[0-9a-fA-F]
子運算式、子運算式計數、分支用法淺析
子運算式
例如:
(very) *large
可以匹配"large","very large","very very large"等,
子運算式計數
例如:
(very){1,3}
表示匹配“very”,“very very”和“very very very”,
分支
例如,如果要匹配com、edu、或net,就可以使用如下所示的運算式:
com|edu|net
與Perl兼容的正則運算式函式
字串的匹配與查找
preg_match()函式和preg_match_all()函式
<?php $str = 'cyy is cute.'; $preg = '/\b\w{2}/'; $num1 = preg_match($preg,$str,$str1); echo $num1.'<br>'; var_dump($str1); $num2 = preg_match_all($preg,$str,$str2); echo $num2.'<br>'; var_dump($str2);
匹配結果如下:

preg_quote()函式
函式功能:該函式講字串str中的所有特殊字符進行自動轉義,如果有引數delimiter,那么該引數
所包含的字串也將被轉義,函式回傳轉義后的字串,
<?php $str = '!、$、^、*、+、.、[、]、\\、/、cyy、<、>'; $str2 = 'cyy'; $res = preg_quote($str,$str2); echo $res.'<br>';
函式preg_grep()
<?php $preg = '/^\d{3,4}-\d{7,8}$/'; $arr = array('043212345678','0431-7654321','12345678'); $res = preg_grep($preg,$arr); var_dump($res);
在陣列$arr中匹配具有正確格式的電話號(010-1234****等),并保存到另一個陣列中,
字串處理函式strstr()、strpos()、strrpos()、substr()
如果只是查找一個字串中是否包含某個子字串,建議使用strstr()或strpos()函式,如果只是簡單地從一個字串中取出一段子字串,建議使用substr()函式,雖然PHP提供的字串處理函式不能完成復雜的字串匹配,但處理一些簡單的字串匹配,執行效率則要比使用正則運算式稍高一些,
函式strstr()搜索一個字串在另一個字串中的第一次的出現,該函式回傳字串的其余部分(從匹配點),如果未找到所搜索的字串,則回傳FALSE,該函式對大小寫敏感,如需進行大小寫不敏感的搜索,可以使用stristr()函式,該函式有兩個引數,第一個引數提供被搜索的字串,第二個引數為所搜索的字串,如果該引數是數字,則搜索匹配數字ASCII值的字符,該函式的使用代碼如下所示:
<?php echo strstr('cyy is cute.','cyy').'<br>'; echo strstr('cyy is cute.',chr(115));
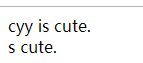
php用正則運算式匹配中文
gbk編碼下漢字正則
1.判斷字串是否全是漢字
<?php $str1 = '全部是中文'; if (preg_match_all("/^([x81-xfe][x40-xfe])+$/", $str1, $match)) { echo '全部是中文'; }else{ echo '不全是中文'; } echo '<br>'; $str2 = '全部是中文~'; if (preg_match_all("/^([x81-xfe][x40-xfe])+$/", $str2, $match)) { echo '全部是中文'; }else{ echo '不全是中文'; }
2.判斷字串是否包含漢字
$str1 = '含有中文'; if (preg_match("/^([x81-xfe][x40-xfe])+$/", $str1, $match)) { echo '含有中文'; }else{ echo '不含有中文'; } echo '<br>'; $str2 = '~~~'; if (preg_match("/^([x81-xfe][x40-xfe])+$/", $str2, $match)) { echo '全含有中文'; }else{ echo '不含有中文'; }
UTF編碼下匹配全部是中文:
$str1 = '全部是中文'; if (preg_match("/^[\x{4e00}-\x{9fa5}]+$/u", $str1)) { echo '全部是中文'; }else{ echo '不全是中文'; } echo '<br>'; $str2 = '全部是中文~'; if (preg_match("/^[\x{4e00}-\x{9fa5}]+$/u", $str2)) { echo '全部是中文'; }else{ echo '不全是中文'; }

UTF編碼下匹配含有中文:
$str1 = '全部是中文'; if (preg_match("/^[\x{4e00}-\x{9fa5}]+$/u", $str1)) { echo '含有中文'; }else{ echo '不含有中文'; } echo '<br>'; $str2 = '~'; if (preg_match("/^[\x{4e00}-\x{9fa5}]+$/u", $str2)) { echo '含有中文'; }else{ echo '不含有中文'; }

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/33646.html
標籤:PHP
上一篇:PHP PDO mysql抽象層