Google Sheet 在其單元格中有多行資訊,例如地址。
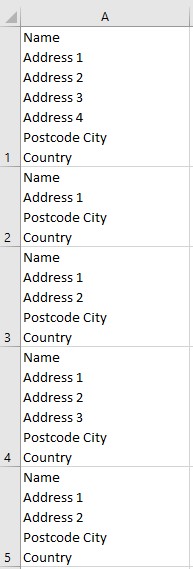
每個地址可以有不同的行數,但我們知道:
第一行總是名稱
倒數第二行總是郵政編碼和城市
最后一行總是國家
我們試圖將地址分成 4 列:
Name
Street address(即提取姓名,郵政編碼和城市,國家后留下的地址)
郵政編碼和城市
Country
So col B(name)讀取第一行=REGEXEXTRACT(A1,”(\w.*)”)
當然,我可以通過計算下一行字符來算出每個單元格有多少行
=LEN(A1)-LEN(SUBSTITUTE(A1,CHAR(10),””))
如果公式回傳 6,則有 7 行
我們如何得到 C(街道地址)、D(郵政編碼和城市)和 E 列(國家)公式化?
我的意思是,當然,我可以得到這個單元格的國家,
=REGEXEXTRACT(A2,”(\n.*){6}”)
但我不能復制公式......上面的 6 是手動輸入,這違背了目的。由于這是正則運算式,因此顯然不能使用單元格參考而不是 6,例如
=REGEXEXTRACT(Amazon!B4,”(\n.*){F1}”)
(例如,如果我在 F 列中存盤了 A 列中的下一行字符數)
uj5u.com熱心網友回復:
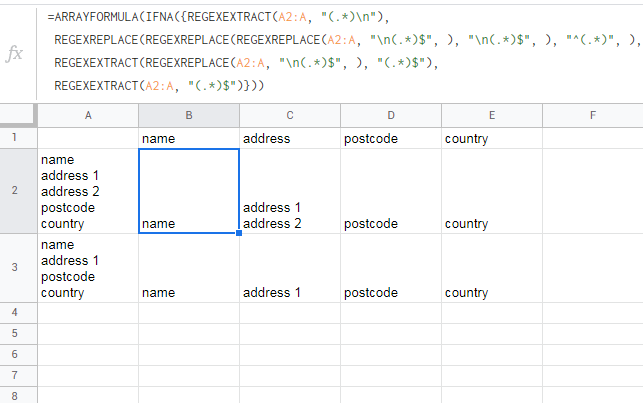
嘗試:
=ARRAYFORMULA(IFNA({REGEXEXTRACT(A2:A, "(.*)\n"),
REGEXREPLACE(REGEXREPLACE(REGEXREPLACE(A2:A, "\n(.*)$", ), "\n(.*)$", ), "^(.*)\n", ),
REGEXEXTRACT(REGEXREPLACE(A2:A, "\n(.*)$", ), "(.*)$"),
REGEXEXTRACT(A2:A, "(.*)$")}))
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/337880.html
上一篇:深入淺出Java記憶體模型
下一篇:IDEA 這個小技巧太實用了。。