(* 這可能是一個重復的問題,但如果我們還沒有這個功能會令人驚訝。*)
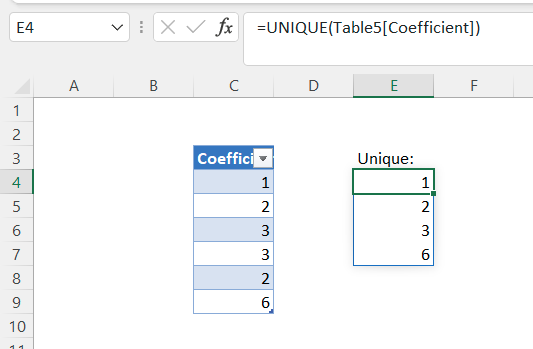
我Table5在 C 列有一張桌子,它的高度可能會改變。在 E 列中,我有一個公式來例如提取唯一值,因此生成的溢位范圍具有動態高度。
我想對結果溢位范圍進行條件格式設定,例如,突出顯示大于 5 的值。
但我沒有找到如何在溢位范圍內定義條件格式規則(例如,通過使用#)。我不想在整列上應用條件格式規則。
有誰知道如何實作這一目標?
uj5u.com熱心網友回復:
我能想到的唯一方法是:
=AND(ROW($E1)>=4,ROW($E1)<=COUNTA(UNIQUE(INDIRECT("Table5[Coefficient]"))) 4,$E1>5)
使用上述公式作為整個 E:E 列的條件格式規則。
uj5u.com熱心網友回復:
您可以在整個列上設定條件格式規則,但使用一些額外的邏輯來確保它只適用于您想要的范圍,即:
=AND(ROW(E1)>=4, ROW(E1)<=4 COUNT(UNIQUE(INDIRECT("Table5[Coefficient]"))), [your condition here])
將規則應用于E:E,它只會對True您想要的范圍內的行進行評估。
uj5u.com熱心網友回復:
另一種解決方法是使用一個命名范圍,該范圍將接受溢位范圍#分配。
將命名范圍“CF_1”分配為:
=OFFSET($E$4,0,0,COUNTA($E$4#))
應用于 E:E 的條件格式可以是:
=AND(ROW(E1)=MEDIAN(ROW(E1),MIN(ROW(CF_1)),MAX(ROW(CF_1))),E1>5)
從本質上講,這與 JvdV 和 Pantsless 教授的答案并沒有太大不同,因為它歸結為同一件事,但它確實有一個好處,即它僅適用于溢位范圍的行(迄今為止,其他答案尚未考慮單元格 E1-E3)。
更新
實際上,您根本不必使用命名范圍,因為此代碼也可以接受#(盡管仍然無法弄清楚如何僅在溢位范圍內應用)
=AND(ROW(E1)=MEDIAN(ROW(E1),MIN(ROW(E$4#)),MAX(ROW(E$4#))),E1>5)
uj5u.com熱心網友回復:
我一直在使用應用于整個列或一組列的幾種不同的條件格式。該表如下所示:

以下公式是應用于整個行/行的條件格式,而不是單個單元格:
標題:
=AND(OR(ISERR(OFFSET(A1,-1,0)),ISBLANK(OFFSET(A1,-1,0)))=TRUE,ISBLANK(A1)=FALSE)
樂隊:
=AND(CELL("row",A1)=EVEN(CELL("row",A1)),ISBLANK(A1)=FALSE)
最后一行(或總行):
=AND(ISBLANK(A1)=FALSE,ISBLANK(A2)=TRUE)
使用以下格式:

如果您不想將此格式應用于非溢位單元格,您可以確定單元格是溢位還是直接輸入。您可以使用公式或撰寫 UDF 來完成此操作。
使用公式,您需要偽造它。您可以使用ISFORMULA查找溢位公式的輸入位置,并NOT(ISBLANK())識別溢位的行。然后,您將不得不假設后跟非空白、非公式單元格的公式是溢位的公式。輔助列可能會有所幫助。
使用 UDF,您可以直接確定單元格是否溢位。下面是一個基本的例子。如果需要,您可以添加更多檢查以確定公式是否實際溢位。
Public Function isFormulaOrSpill(ByVal rRange As Range) As Boolean
Dim this_bIsSpill As Boolean
Dim this_bIsFormula As Boolean
this_bIsSpill = rRange.HasSpill
this_bIsFormula = rRange.HasFormula
isFormulaOrSpill = (this_bIsSpill Or this_bIsFormula)
End Function
最近我一直在構建整個表作為溢位范圍(包括標題和總行)。以下是那些想試一試的人的例子:
=LET(
Column_Key, Table_Status[System],
Column_FtEstimated, Table_Status[Estimated],
Column_FtModeled, IF(Table_Status[Modeled]>Table_Status[Estimated],Table_Status[Estimated],Table_Status[Modeled]),
Categories, SORT(UNIQUE(Column_Key)),
Array_BoolKey, (TRANSPOSE(Column_Key)=Categories) 0,
Mask1, TRANSPOSE(ISNUMBER(XMATCH(Column_Filter1,List_Filter1))),
Mask2, TRANSPOSE(ISNUMBER(XMATCH(Column_Filter2,List_Filter2))),
Array_BoolMasked, Array_BoolKey,
Masked_FtModeled, IFERROR(Array_BoolMasked*TRANSPOSE(Column_FtModeled),0),
Masked_FtEstimated, IFERROR(Array_BoolMasked*TRANSPOSE(Column_FtEstimated),0),
Array_Ones, SEQUENCE(COLUMNS(Array_BoolMasked),1,1,0),
Body_Count_Lines, MMULT(Array_BoolKey, Array_Ones),
Body_Sum_FtModeled, MMULT(Masked_FtModeled, Array_Ones),
Body_Sum_FtEstimated, MMULT(Masked_FtEstimated, Array_Ones),
Body_Percent_FtModeled, IFERROR(Body_Sum_FtModeled/Body_Sum_FtEstimated,"-"),
Total_Count_Lines, IFERROR(SUM(Body_Count_Lines),"-"),
Total_Sum_FtModeled, IFERROR(SUM(Body_Sum_FtModeled),"-"),
Total_Sum_FtEstimated, IFERROR(SUM(Body_Sum_FtEstimated),"-"),
Total_Percent_FtModeled, IFERROR(Total_Sum_FtModeled/Total_Sum_FtEstimated,"-"),
Array_Seq, {1,2,3,4,5},
Array_Header, CHOOSE( Array_Seq, "System", "Lines", "Modeled Feet", "Estimated Feet", "Percent Modeled"),
Array_Body, CHOOSE( Array_Seq, Categories, Body_Count_Lines, Body_Sum_FtModeled, Body_Sum_FtEstimated, Body_Percent_FtModeled),
Array_Total, CHOOSE( Array_Seq, "Total", Total_Count_Lines, Total_Sum_FtModeled, Total_Sum_FtEstimated, Total_Percent_FtModeled),
Range1,Array_Header,
Range2,Array_Body,
Range3,Array_Total,
Rows1,ROWS(Range1), Rows2,ROWS(Range2), Rows3,ROWS(Range3), Cols1,COLUMNS(Range1),
RowIndex, SEQUENCE(Rows1 Rows2 Rows3), ColIndex,SEQUENCE(1, Cols1),
RangeTable,IF(
RowIndex<=Rows1,
INDEX(Range1,RowIndex,ColIndex),
IF(RowIndex<=Rows1 Rows2,
INDEX(Range2,RowIndex-Rows1,ColIndex),
INDEX(Range3,RowIndex-Rows1-Rows2,ColIndex)
)),
Return, RangeTable,
Return
)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/338674.html