我有一個 Pandas 資料框,它包含四個日期列、一個開始時間和一個定義范圍的結束時間和日期列。我希望能夠按照這些列的定義,為資料框中所有行的所有時間和日期共同創建佇列計數。
date start
1. date starttime endtime storeid
2. 2/3/20 6:20 pm 7:20 pm 12231
3. 2/3/20 6:25pm 7:25 pm 12231
4. 2/3/20 6:29pm 7:40 pm 12231
5. 2/3/20 7:21pm 7:59pm 12231
6. 2/3/20 6:21pm 7:21 pm 12232
我想生成基于佇列的列,它將通過以下方式告訴我當前佇列之前有多少佇列:
date start
1. date starttime endtime storeid queue
2. 2/3/20 6:20 pm 7:20 pm 12231 1
3. 2/3/20 6:25pm 7:25 pm 12231 2
4. 2/3/20 6:29pm 7:40 pm 12231 3
5. 2/3/20 7:21pm 7:59 pm 12231 2
6. 2/3/20 6:21pm 7:21 pm 12232 1
我對此很陌生,任何幫助將不勝感激。
uj5u.com熱心網友回復:
任何一點的佇列大小都是一個階躍函式。有一個名為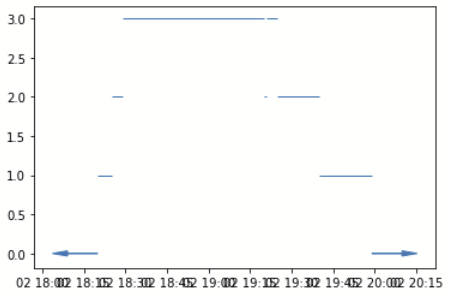
您也可以將它們添加在一起以創建組合佇列
stepfunctions[12231] stepfunctions[12232]
# or
stepfunctions.sum()
您可以在您喜歡的任何點對佇列大小進行采樣。似乎您希望在每個開始時間對佇列大小進行采樣。對于商店 12231,您可以這樣做
stepfunctions[12231](data["starts"])
這給了你
array([1, 2, 3, 3], dtype=int64)
為了將此列添加到您的資料框中,在與在 groupby-apply 中創建 step 函式相同的步驟中執行此操作會更容易。
所以整個解決方案(匯入后)是
def queue_count_sample(df):
sf = sc.Stairs(df, "start", "end")
df["queue"] = sf(df["start"])
return df
data.groupby("storeid").apply(queue_count_sample)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/339588.html
上一篇:重新分配陣列的下一個大小無效