1、預備知識-python核心用法常用資料分析庫(上)
目錄- 1、預備知識-python核心用法常用資料分析庫(上)
- 概述
- 實驗環境
- 任務一:環境安裝與配置
- 【實驗目標】
- 【實驗步驟】
- 任務二:Pandas資料分析實戰
- 【任務目標】
- 【任務步驟】
概述
Python 是當今世界最熱門的編程語言,而它最大的應用領域之一就是資料分析,在python眾多資料分析工具中,pandas是python中非常常用的資料分析庫,在資料分析,機器學習,深度學習等領域經常被使用,使用 Pandas 我們可以 Excel/CSV/TXT/MySQL 等資料讀取,然后進行各種清洗、過濾、透視、聚合分析,也可以直接繪制折線圖、餅圖等資料分析圖表,在功能上它能夠實作自動化的對大檔案處理,能夠實作 Excel 的幾乎所有功能并且更加強大,
本實驗將通過實戰的方式,介紹pandas資料分析庫的基本使用,讓大家在短時間內快速掌握python的資料分析庫pandas的使用,為后續專案編碼做知識儲備
實驗環境
- Python 3.7
- PyCharm
任務一:環境安裝與配置
【實驗目標】
本實驗主要目標為在Windows作業系統中,完成本次實驗的環境配置任務,本實驗需要的軟體為PyCharm+Python 3.7
【實驗步驟】
1、安裝Python 3.7
2、安裝Pycharm
3、安裝jupyter、pandas、numpy、notebook
打開CMD,并輸入以下命令,安裝jupyter、notebook、pandas和numpy
pip install jupyter notebook pandas numpy
安裝完成后會有類似如下文字提示:
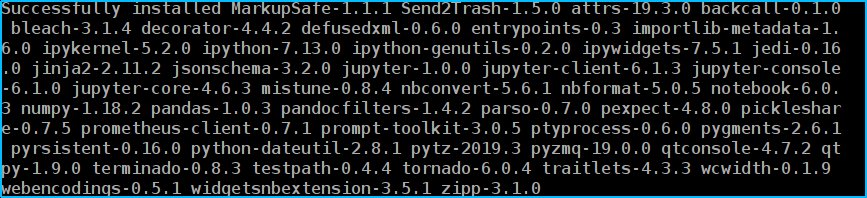
以上步驟完成后,實驗環境配置作業即已完成,關閉CMD視窗
任務二:Pandas資料分析實戰
【任務目標】
本任務主要目標為使用pandas進行資料分析實戰,在實戰程序中帶大家了解pandas模塊的一下功能:
- 準備作業
- 檢查資料
- 處理缺失資料
- 添加默認值
- 洗掉不完整的行
- 洗掉不完整的列
- 規范化資料型別
- 重命名列名
- 保存結果
【任務步驟】
1、打開CMD,執行如下命令,開啟jupyter
jupyter notebook
成功執行以上命令后,系統將自動打開默認瀏覽器,如下圖所示:
成功打開瀏覽器后,按如下流程創建 notebook 檔案
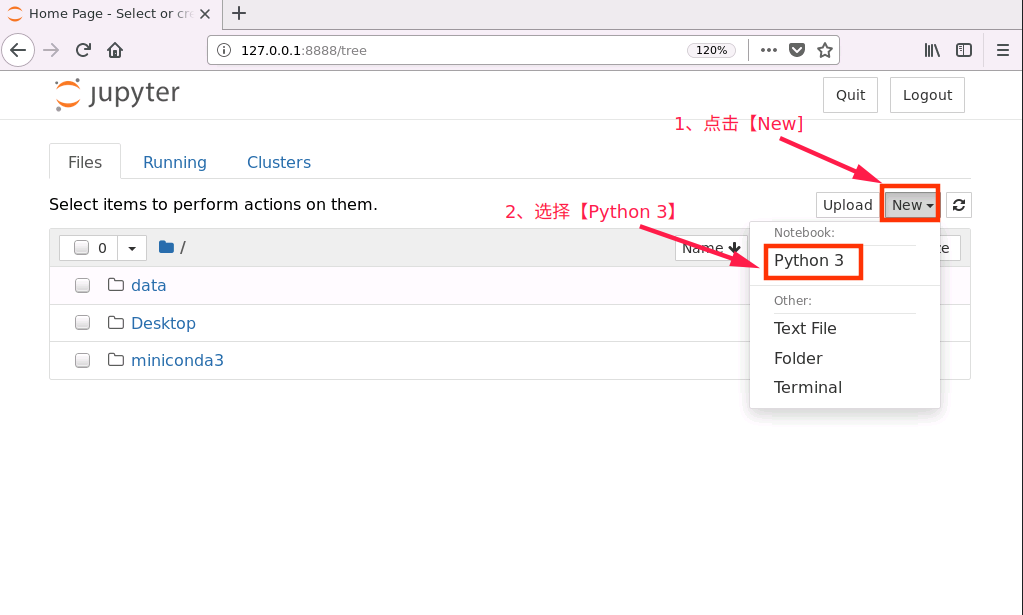
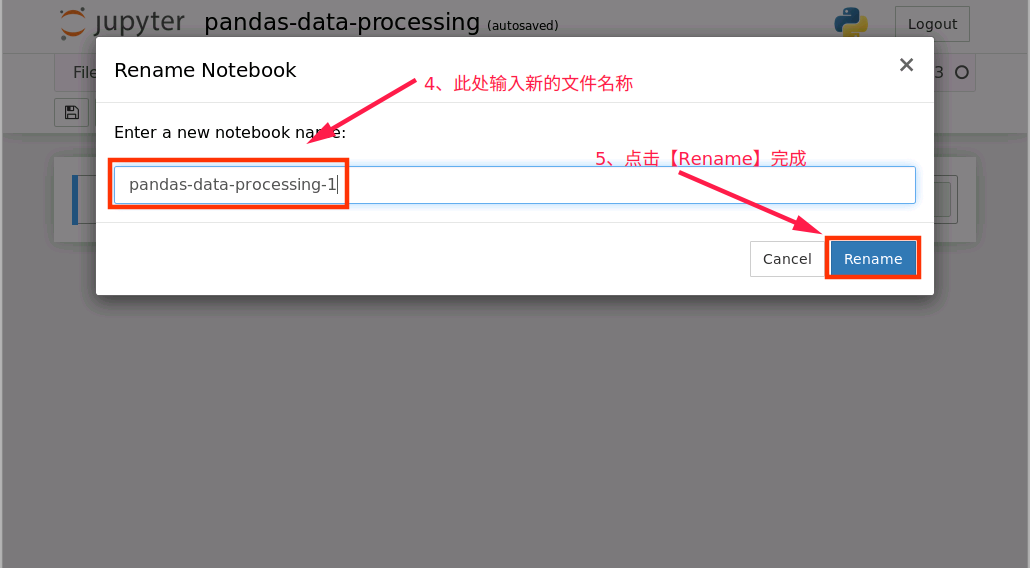
對新建notebook進行重命名操作
2、notebook 檔案新建完成后,接下來在新建的 notebook 中撰寫代碼
匯入 Pandas 到我們的代碼中,代碼如下
import pandas as pd
小提示:輸入完成代碼后,按下【Shift + Enter】組合鍵即可運行該單元格中的代碼,后面輸入完每個單元格的代碼后都需要進行類似操作,代碼才會運行
加載資料集,代碼如下:
data = https://www.cnblogs.com/lmandcc/p/pd.read_csv('./data/movie_metadata.csv')
3、檢查資料
查看資料集前5行
data.head()
運行結果如下圖所示:
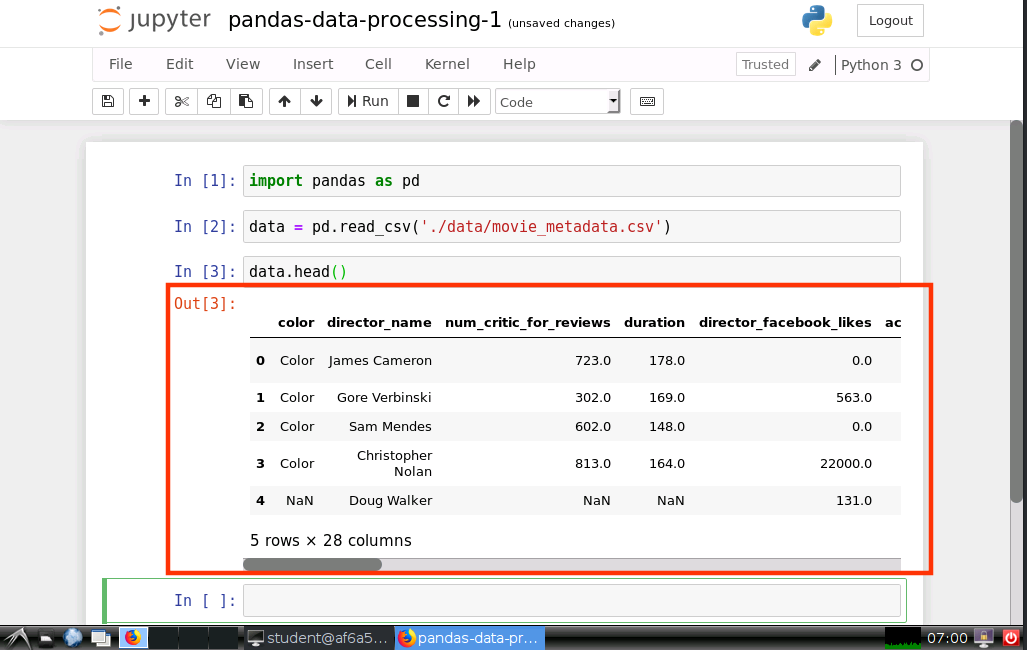
我們可以通過上面介紹的 Pandas 的方法查看資料,也可以通過傳統的 Excel 程式查看資料
Pandas 提供了一些選擇的方法,這些選擇的方法可以把資料切片,也可以把資料切塊,下面我們簡單介紹一下:
- 查看一列的一些基本統計資訊:data.columnname.describe()
- 選擇一列:data['columnname']
- 選擇一列的前幾行資料:data['columnsname'][:n]
- 選擇多列:data[['column1','column2']]
- Where 條件過濾:data[data['columnname'],condition]
4、處理缺失資料
缺失資料是最常見的問題之一,產生這個問題有以下原因:
- 從來沒有填正確過
- 資料不可用
- 計算錯誤
無論什么原因,只要有空白值得存在,就會引起后續的資料分析的錯誤,下面介紹幾個處理缺失資料的方法:
- 為缺失資料賦值默認值
- 去掉/洗掉缺失資料行
- 去掉/洗掉缺失率高的列
4.1、添加默認值
使用空字串來填充country欄位的空值
data.country= data.country.fillna('')
使用均值來填充電影時長欄位的空值
data.duration = data.duration.fillna(data.duration.mean())
4.2、洗掉不完整的行
data.dropna()
運行結果如下(由于輸出內容給較多,結果中省略了中間部分資料,只顯示開頭和結尾部分):
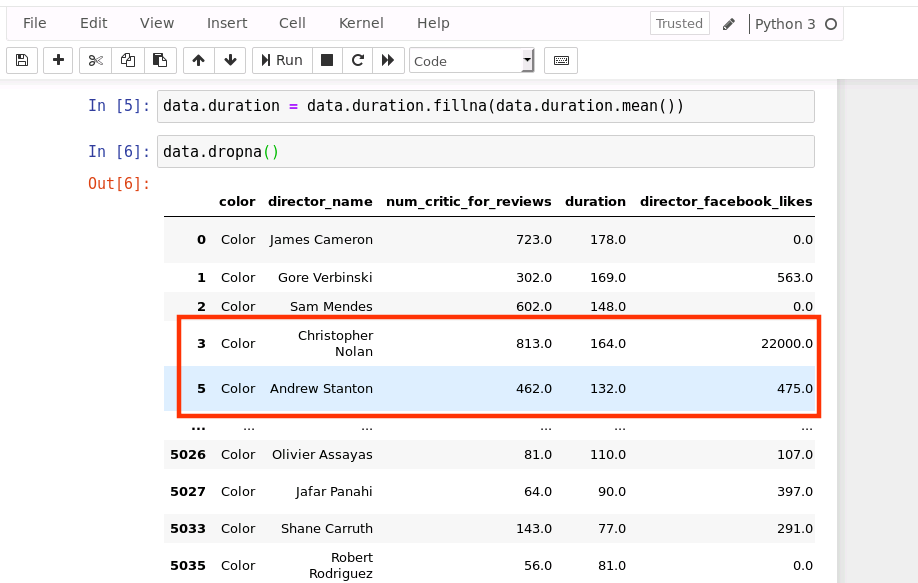
由上圖可以看出,由于第4行資料存在缺失值,因此被洗掉
提示:dropna操作并不會在原始資料上做修改,它修改的是相當于原始資料的一個備份,因此原始資料還是沒有變
洗掉一整行的值都為 NA:
data.dropna(how='all')
運行結果如下:
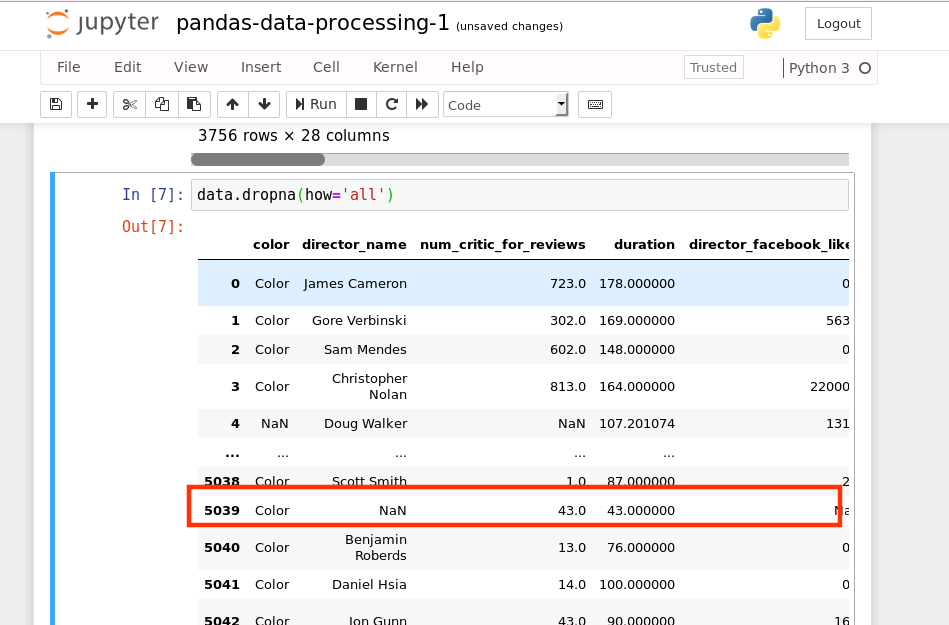
從上圖可知,由于限定條件為:洗掉一整行都為NA的數據,因此不滿足此條件的資料行還是會被保留
我們也可以增加一些限制,在一行中有多少非空值的資料是可以保留下來的(在下面的代碼中,行資料中至少要有 5 個非空值)
data.dropna(thresh=5)
運行結果如下:
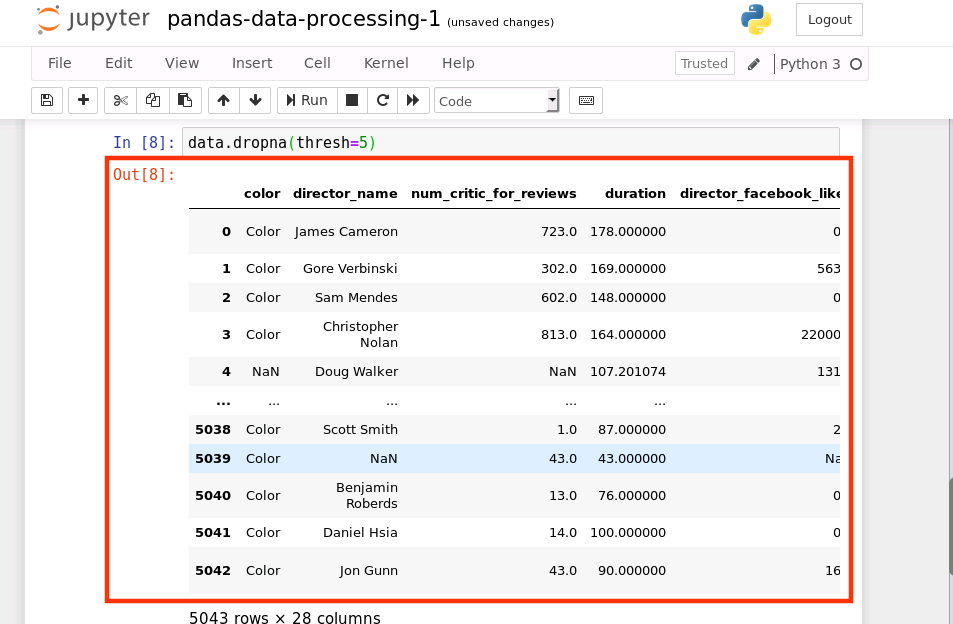
也可指定需要洗掉缺失值的列
我們以 title_year 這一列為例,首先查看 title_year 這一列中存在的缺失值:
data['title_year'].isnull().value_counts()
結果如下:
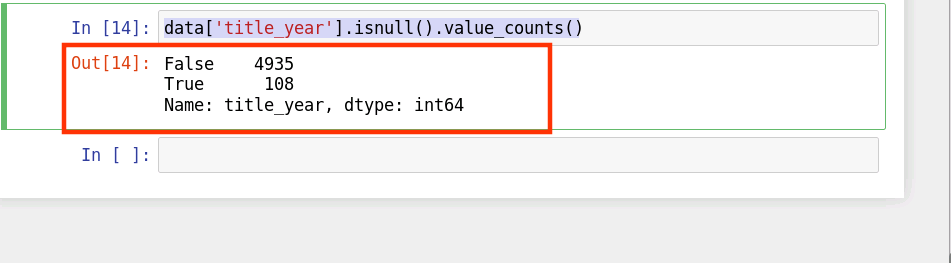
由上圖可知,title_year 這一列中存在108個缺失值
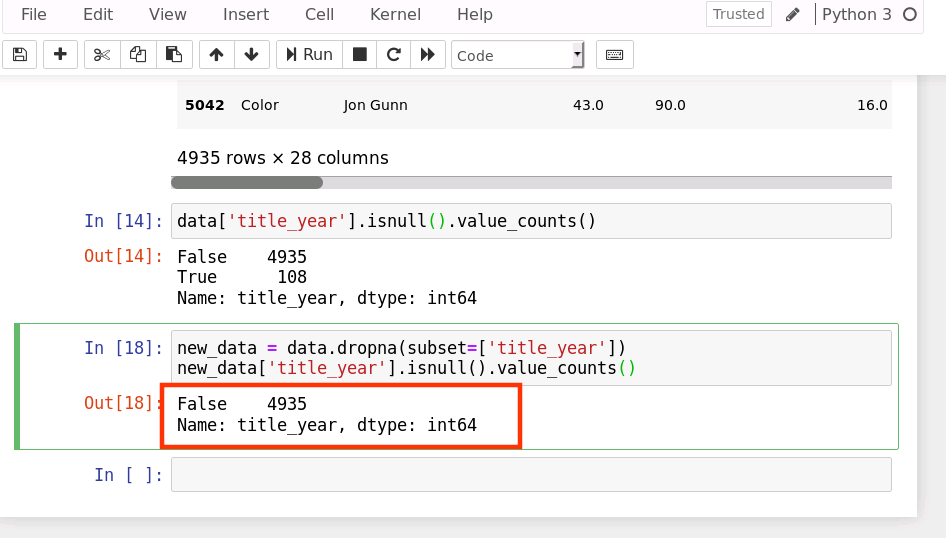
接下來查看 title_year 洗掉完缺失值后的情況
new_data = https://www.cnblogs.com/lmandcc/p/data.dropna(subset=['title_year'])
new_data['title_year'].isnull().value_counts()
上面的 subset 引數允許我們選擇想要檢查的列,如果是多個列,可以使用列名的 list 作為引數,
運行結果如下:
4.3、洗掉不完整的列
我們可以上面的操作應用到列上,我們僅僅需要在代碼上使用 axis=1 引數,這個意思就是操作列而不是行,(我們已經在行的例子中使用了 axis=0,因為如果我們不傳引數 axis,默認是axis=0)
洗掉一整列為 NA 的列:
data.dropna(axis=1, how='all')
運行結果如下:
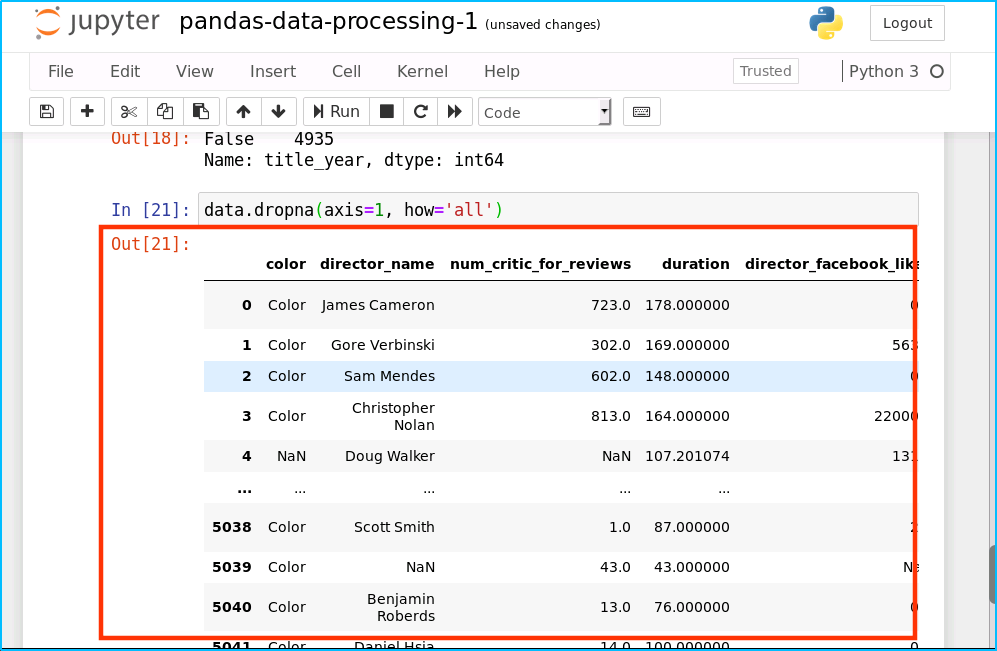
洗掉任何包含空值的列:
data.dropna(axis=1,how='any')
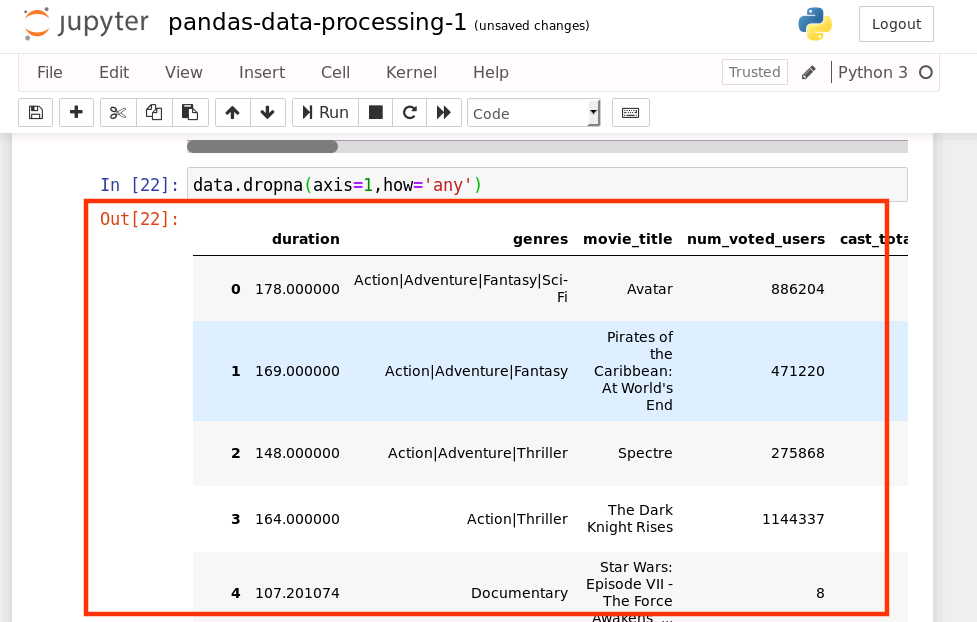
這里也可以使用像上面一樣的 threshold 和 subset
5、規范化資料型別
加載資料集時指定欄位資料型別
data = https://www.cnblogs.com/lmandcc/p/pd.read_csv('./data/movie_metadata.csv', dtype={'title_year':str})
這就是告訴 Pandas ‘duration’列的型別是數值型別,查看加載后各資料列的型別
data.info()
運行結果如下:
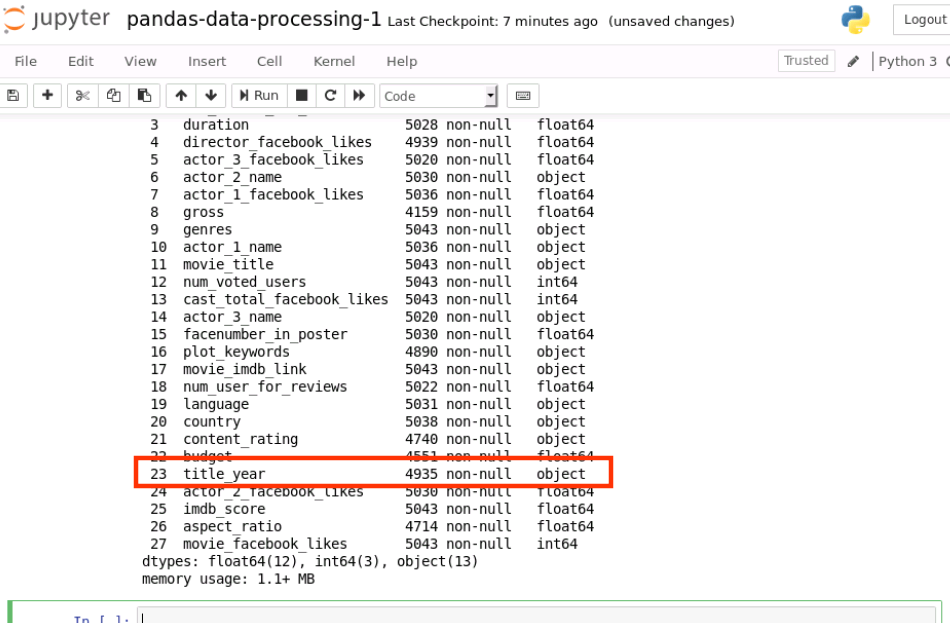
object 即代表資料型別為字串型別
6、必要的變換
人工錄入的資料可能都需要進行一些必要的變換,例如:
- 錯別字
- 英文單詞時大小寫的不統一
- 輸入了額外的空格
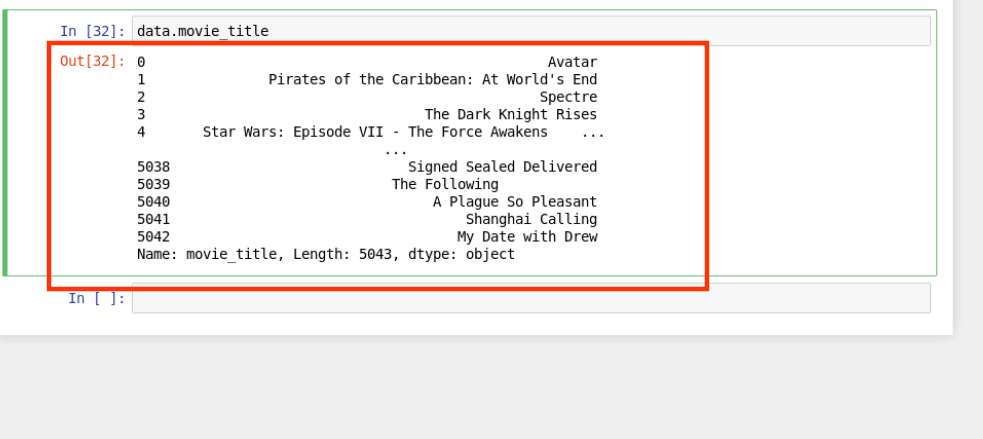
首先查看 movie_title 列資料
data.movie_title
結果如下:
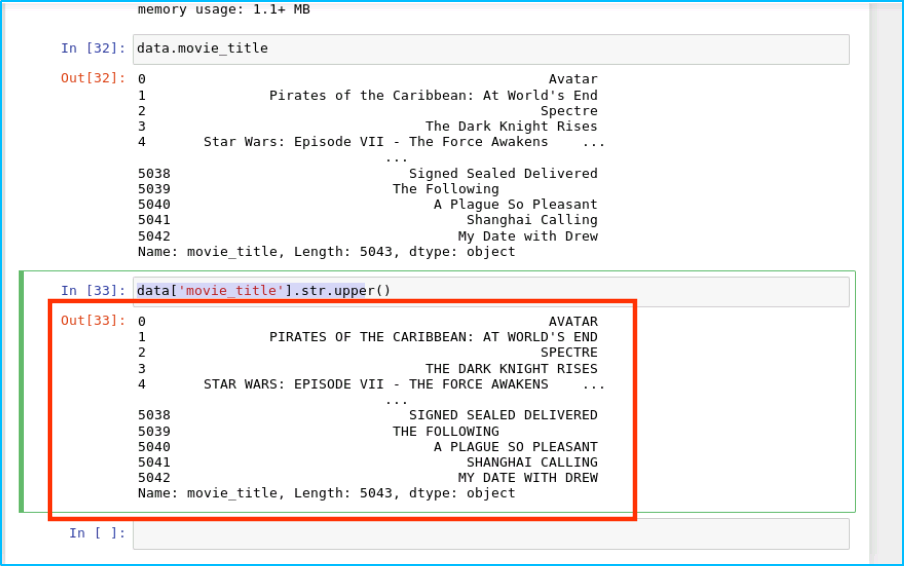
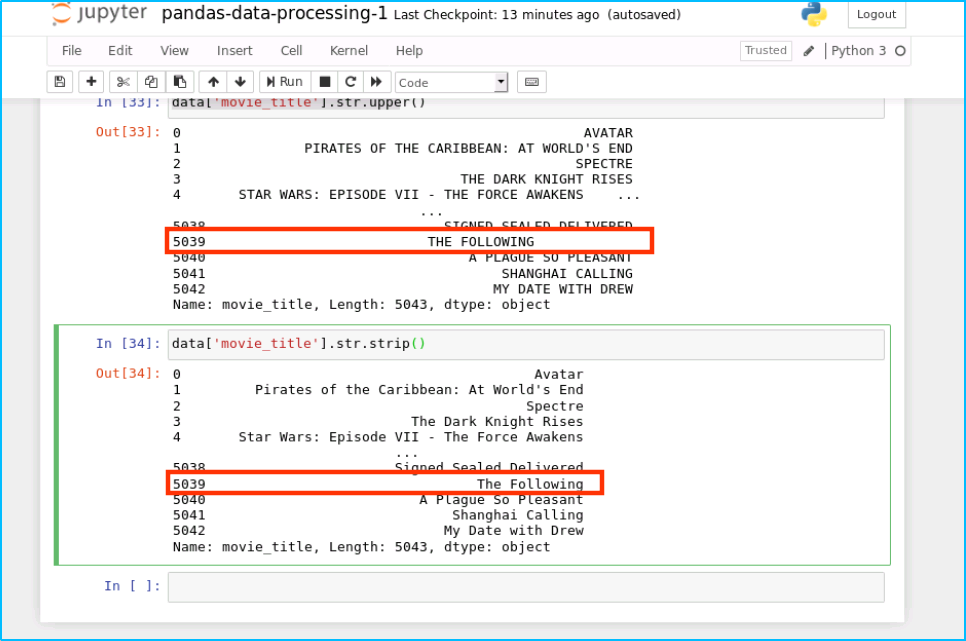
我們資料中所有的 movie_title 改成大寫:
data['movie_title'].str.upper()
結果如下:
同樣的,我們可以去掉末尾余的空格:
data['movie_title'].str.strip()
運行結果如下:
7、重命名列名
我們需要進行重新賦值才可以:
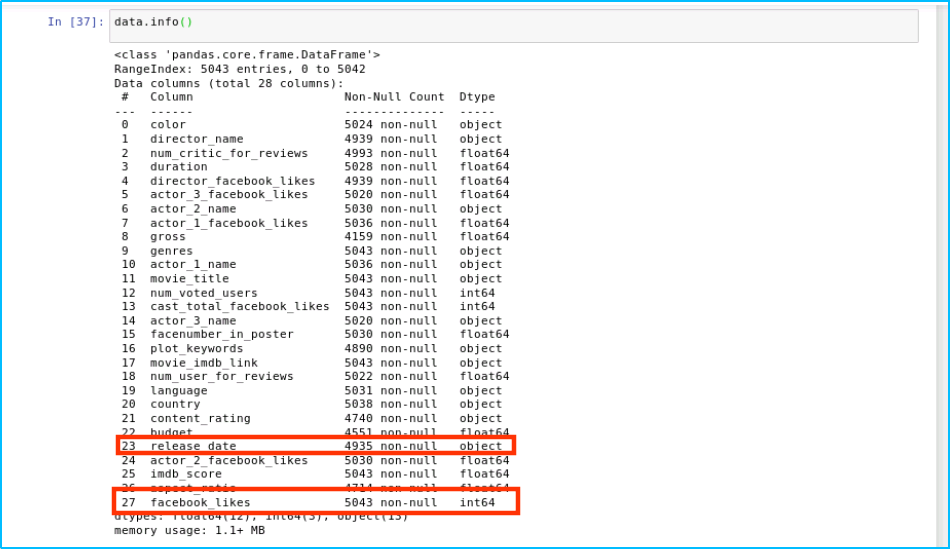
data = https://www.cnblogs.com/lmandcc/p/data.rename(columns={'title_year':'release_date', 'movie_facebook_likes':'facebook_likes'})
查看重命名后的資料列名稱
data.info()
輸出結果如下:
8、保存結果
完成資料清洗之后,一般會把結果再以 csv 的格式保存下來,以便后續其他程式的處理,同樣,Pandas 提供了非常易用的方法:
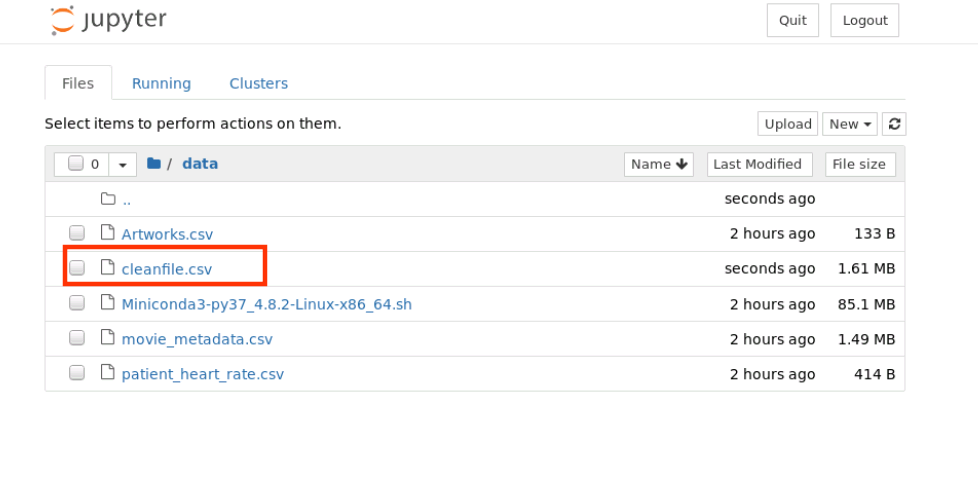
data.to_csv('./data/cleanfile.csv',encoding='utf-8')
查看 /home/student/data 目錄內容如下,新增保存的 cleanfile.csv 檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/340330.html
標籤:Python