前言
寫這篇文章的目的是因為我大學四年的室友,龍哥在培訓java,剛好最近學習HashMap,于是我寫一篇文章來模擬他以后面試被問到HashMap的場景;另外就是因為HashMap的使用確實廣泛,深受面試官的喜愛,大廠的面試官也有很多會用HashMap來考察你的基礎到底如何,

面試經過
面試官: 我們開始吧,看發型就知道是老程式員了,自我介紹一下吧,
龍哥: 我叫龍哥,剛過完三十大壽,平時喜歡打籃球,優勢是身體好,可以996,
面試官: 嗯,還不錯嘛,都30了,集合框架肯定熟悉吧,我們先從HashMap開始吧,簡單的說一下內部的資料結構是怎么樣的吧?
龍哥: 大航子果然沒有騙我,HashMap果然是開頭菜,幸好我連夜讓他給我培訓了一番(內心狂喜中…),咳咳,HashMap嘛,在jdk7是陣列+鏈表,jdk8資料結構做了升級,變成了陣列+鏈表+紅黑樹了,
面試官: 哦?這傻小子笑啥呢,,,看我探探你的底,嗯,那你說說為什么這么設計,以及jdk8為什么要做出這種升級呢?
龍哥: 是這個樣子的,Map這種集合容器,最主要的應用就是想通過一個key最快的時間找到對應的value,事實上這個時間復雜度接近為O(1),那么怎么樣才能實作這么快的速度呢?于是就引入了陣列,陣列可以理解為記憶體中一塊連續的記憶體空間,且每一小塊空間都有自己的索引,通過這個索引就能直接找到對應空間的值,
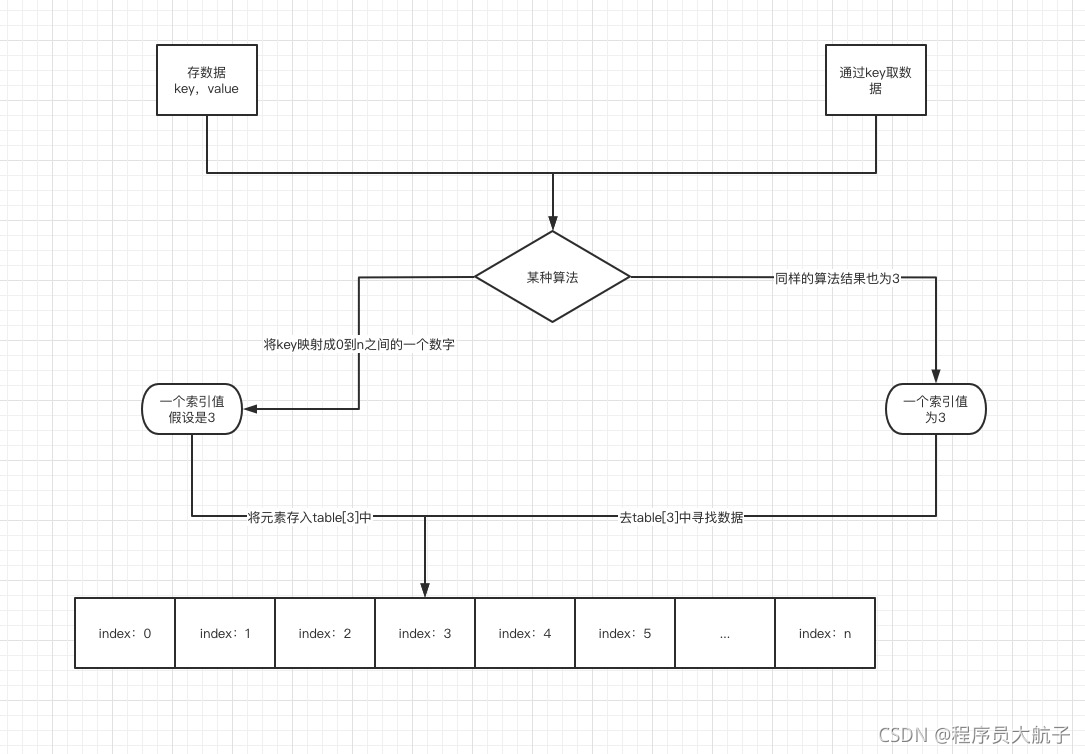
那么是想一下,我通過某種演算法,可以直接把key和陣列中的某個索引對應上,我放也放到這個索引里面,取也直接取這個索引去取,是不是依賴陣列的特性,我就可以用O(1)的時間復雜度快速定位到我想要的值了,
面試官: 嗯嗯嗯,有點意思,那鏈表和紅黑樹又是怎么回事?
龍哥: 瞧給你急的,猴急猴急的,我接著說,在把key映射成陣列索引值這件事情上,期望的不同的key映射到不同的陣列索引值中,但是天不遂人愿,就比如我之前勵志想成為優秀的數學老師,奈何教育減重,,,咳咳,遠了、遠了,繼續哈,但是天不遂人愿,總有可能兩個key好巧不巧就映射成了同一個陣列索引值,這就是哈希碰撞,那么碰撞之后就有兩種情況了,一是同一個key,我就要把原有的key的值覆寫掉,二就是真的是好巧不巧,兩個key算出來的真就是一樣的,那就只能把兩個key和value放到同一個陣列索引的記憶體里面,也就自然而然形成了鏈表,當然,如果碰撞的越來越多,這個鏈表就會越來越長,長,
面試官: 咳咳,禁止開車,好好說,
龍哥: 不是說鏈表過長么,于是,紅黑樹就出來了,就是解決jdk7中,鏈表可能過長的情況,那么為什么紅黑樹就能解決呢?要從鏈表和紅黑樹的查找效率說起,鏈表這種資料結構是不需要連續的記憶體空間的,內部通常是持有了下一個節點的參考,所以,鏈表要查詢出某一個元素,就要從頭節點開始查,不是的話,再去看next是不是,直到next為null才能確定整條鏈表沒有我想要的元素,在最壞情況下,鏈表的長度是n,就是遍歷n次才能找到元素,所以,鏈表的時間復雜度為O(n),
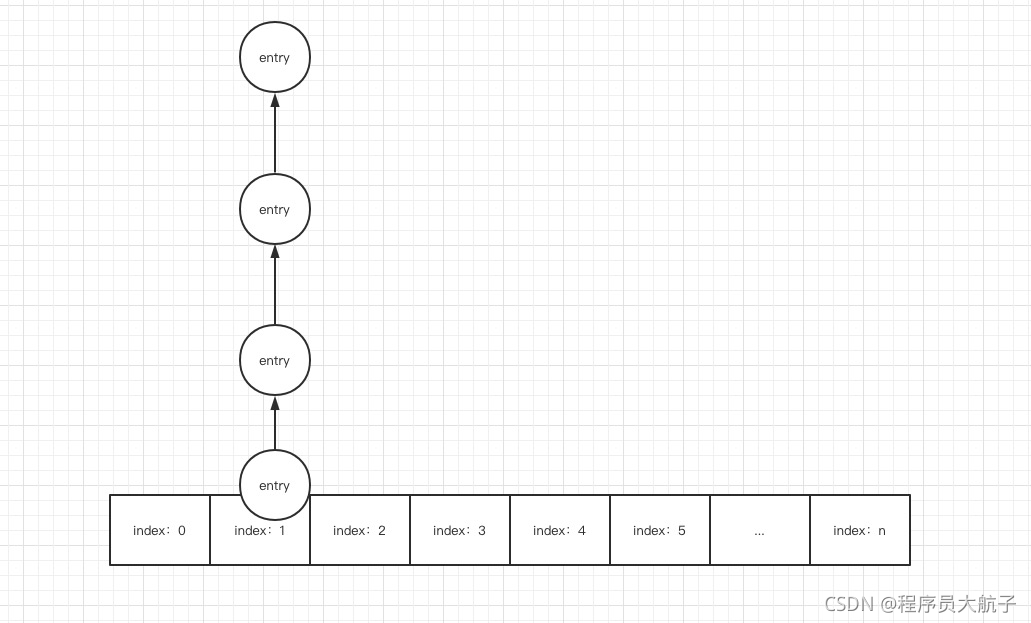
這種的查詢速度如果資料多了是不可以容忍的,要知道HashMap這個工具用的地方有多少,所以jdk8做出了優化,如果鏈表的長度大于了8,達到了9,就變成紅黑樹,當然還要滿足整個hash表中的元素達到了64,之所以條件比較苛刻,是因為鏈表轉陣列本身就很耗性能,不到萬不得已,萬萬使不得啊,紅黑樹這種資料結構首先是二叉搜索樹,二叉搜索樹就滿足了查找的時間復雜度是O(lgn),是一種折半查找,折半查找的效率就很恐怖了,一次排除一半的資料,就算你有100W資料,查找固定的數,也只需要20次,就是這么拽,而紅黑樹在有二叉搜索樹的查詢效率的前提下,又保證了樹的平衡,所以鏈表在上述情況下會進化成紅黑樹,當然,又進化也有退化,退化的節點就是同一個哈希桶中的元素數小于6,就會從紅黑樹變回鏈表,之所以中間留了個7,就是為了防止頻繁的樹化、鏈表化、樹化、鏈表化,

面試官:(我天,這算是這幾天來最會說的了,大航子不來,恐怕沒人能限制的了他了)那你說下,這個key是怎么轉換成陣列索引的呢?
龍哥:(這個問題,嘿嘿嘿,show,time),我們都知道在java中所有的物件繼承自Object,而Object類里面有一個方法,
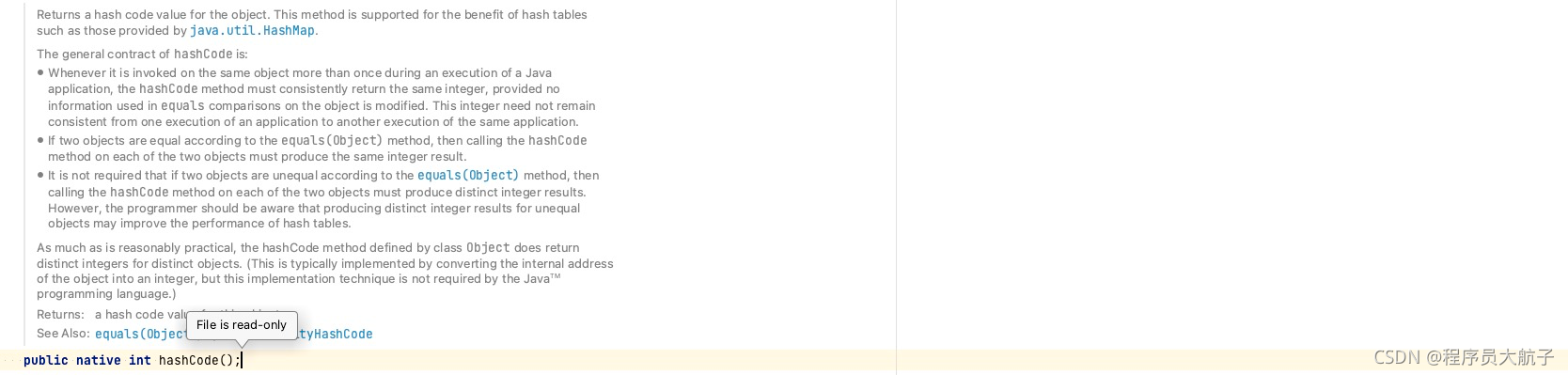
這個方法可以回傳一個32位的數字,當然,這個32位的數字是不能直接去當陣列的索引的,因為一般情況下不會有那么大的陣列,所以這個hashcode肯定是要經過某種轉換,如果陣列的長度是16的話,應該轉換成為的值在0到15之間,才能保證落在陣列的某一個索引值里面,這種的實作方式,常規的能想到的是取模,但是我們都知道,在計算機中,位運算的效率是最高的,于是,這個公式是這個樣子的 (n - 1) & hash ,這種運算的結果和取模不一定相同(有很多博客說相同是錯誤的),至于這么做為什么就能達到和取模一樣的效果的呢?我們還是拿16舉例,
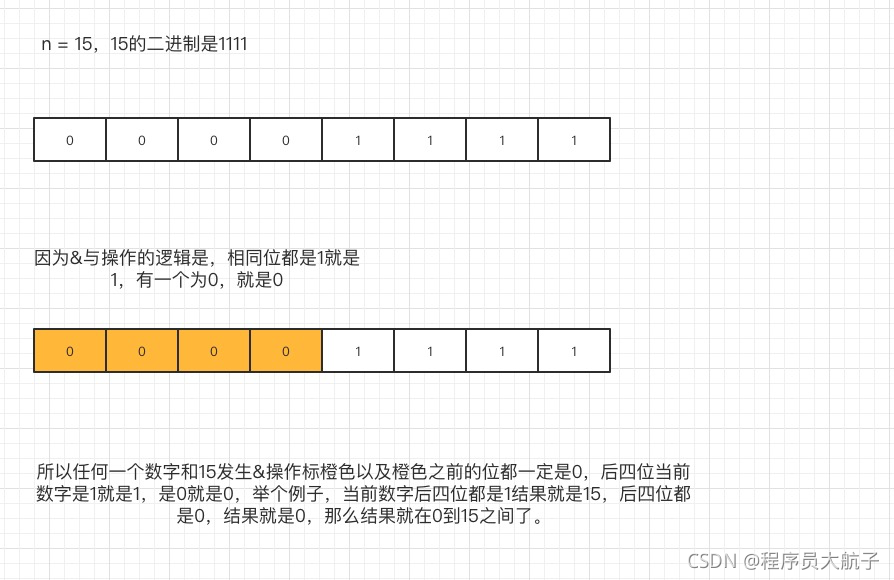
再加上位運算的速度相當快,所以HashMap是采用這種方式尋找陣列索引的,好吧,你問我具體快多少?我曾經對相同的100W樣本做過取模和位運算,大概快了幾十倍把,
面試官: 哦?有破綻,看我坑他一把,這么說,我明白了,是用物件的hashcode然后&陣列的長度啊,
龍哥: 不是的不是的,(急了),公式 (n - 1) & hash 中的hash不是直接用到hashcode,這個jdk7和jdk8還是不同的,我們先來看看jdk7和jdk8的代碼,

我們可以看到,jdk8的相對簡單一點,做了1次異或操作,而jdk7做了四次,而且都是向低位做異或操作,這是為了什么呢?那是因為在計算put的元素應該放到哪個哈希桶中,也就是陣列中的哪一個位置的時候,剛才說了,是通過公式 (n - 1) & hash 計算的,而&運算的特性是兩位同時為“1”,結果才為“1”,否則為0,而我們陣列的長度一般不會特別大,所以hash值中的高位的特性會用不到,所以為了更加分散,將高位和低位的特性融合,使得元素更容易分散到不同的哈希桶中,避免哈希碰撞的發生,這就叫擾動函式,至于jdk8為什么只異或一次,可能是開發人員覺得這樣就夠分散了吧,
面試官: 嗯嗯,不錯不錯,那我懂了,先取得key的hashcode,然后擾動函式高位低位特性融合,最后算出在陣列中的索引,就比如我陣列長度為14,就會索引出0到13的值,這回沒錯了把?
龍哥:(mmmmm,,,你咋老給我挖坑,我雖然禿但是并不強啊,你老把我當琦玉可還行)不是的面試官,陣列的長度只會是2的整數倍,不是有14這種情況發生的,
面試官: 略加思索,不對把,我年輕的時候new過一個HashMap,建構式里面就是扔的14啊,沒有報錯啊(內心os,這看你怎么接),
龍哥: 是這樣的,雖然你給建構式的是14,但是HashMap幫你轉換成了離14最近的而得整數倍的數字,如果你是14就會變成16(也是陣列長度的默認值),但是你給的是32,已經是2的整數倍了,就還是32,具體怎么做的呢?

因為int是32位的,所以只要經過五次的或運算就能從最高位到最低位都變成1,之所以先減一,就是為了防止傳入32的情況,如果不減一就會變成64的,
面試官:( 我怎么感覺場子hold不住了)嗯,之前我們公司,有一次線上cpu100%,好像和HashMap有關,你知道怎么發生的么?
龍哥: 那咱們公司(呸,不要臉,是你們公司),當時一定是用的jdk1.7,jdk1.7是采用的頭插法會造成鏈表成環,jdk8是尾插發,就不會了,
面試官: 詳細說說,
龍哥: 是這樣的,這是jdk7的擴容代碼,

jdk7的大體流程是這樣子,在單執行緒下,遍歷老陣列的所有節點,并且遍歷每一個節點下鏈表的所有節點,重新hash計算在新陣列中的位置,然后將這個節點的next指標指向原本新陣列中對應位置的節點,自己成為新陣列那個位置上的頭節點,就是把原有節點頂下去的程序,
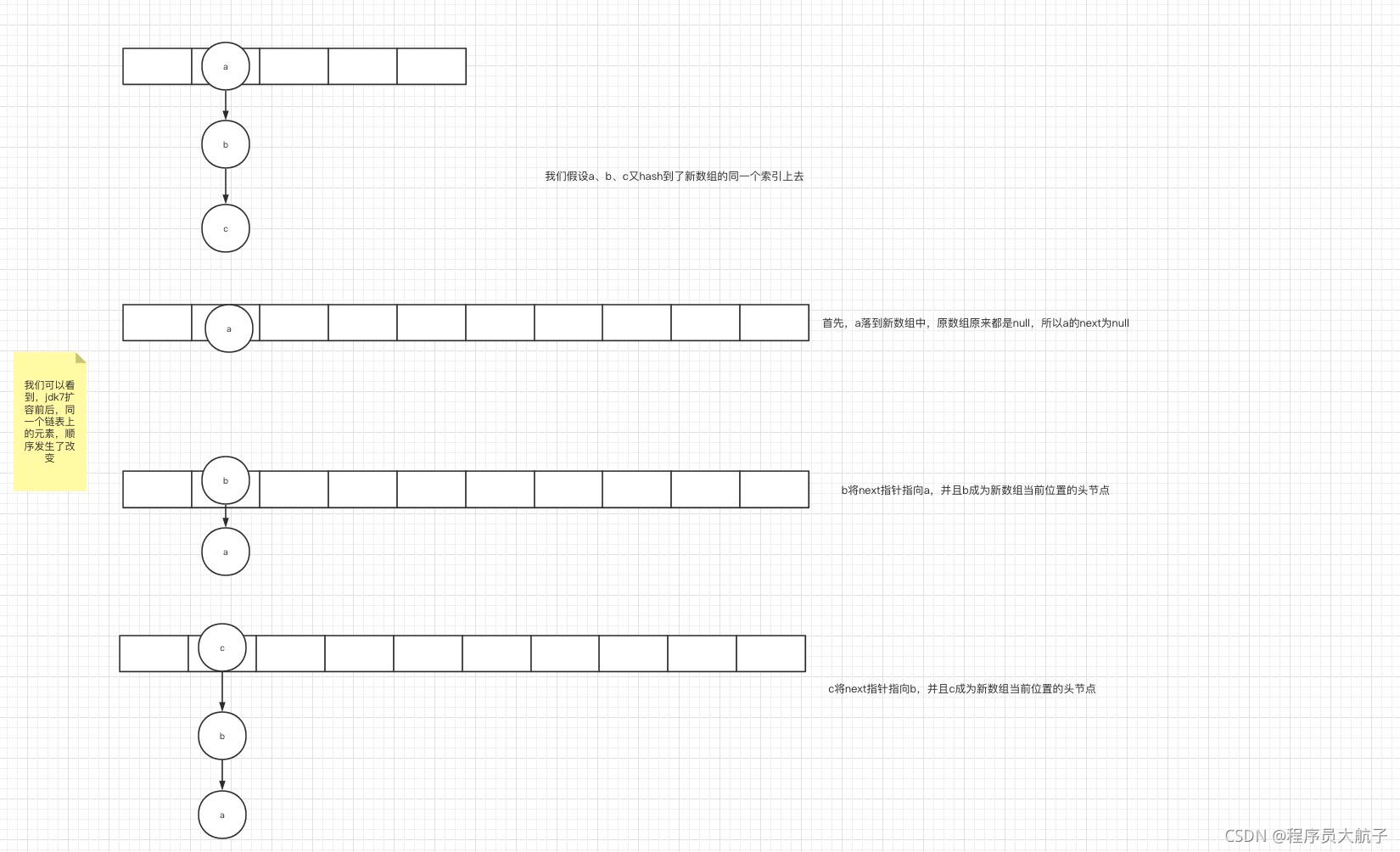
在單執行緒情況下是沒有問題的,但是多執行緒請款下就有可能造成您說的cpu100%,因為成了死回圈,按理說不應該在多執行緒情況下使用HashMap,但是造成cpu100%還是太過嚴重了,所以jdk8才變成了尾插法,那造成死回圈的原因,還是根據擴容的代碼,走一遍就知道了,
假設原HashMap是這個樣子的(圖中陣列長度不準確,應該是2的整數倍,這里省空間,大家記得區分),
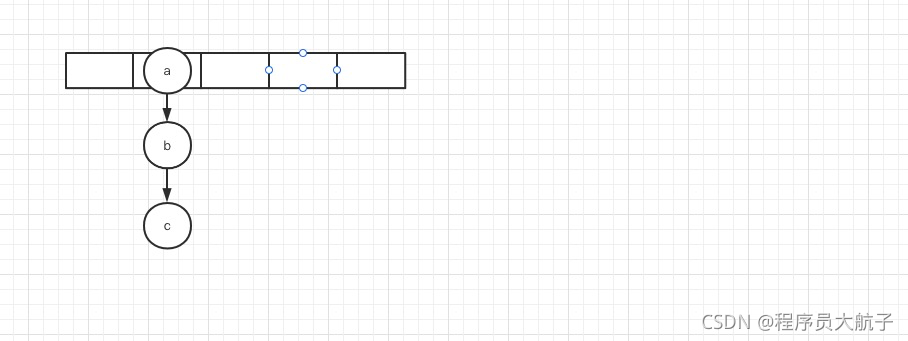
這時候,t1、t2兩個執行緒同時請求擴容,t1,執行到了下圖這里被cpu釋放了執行權,
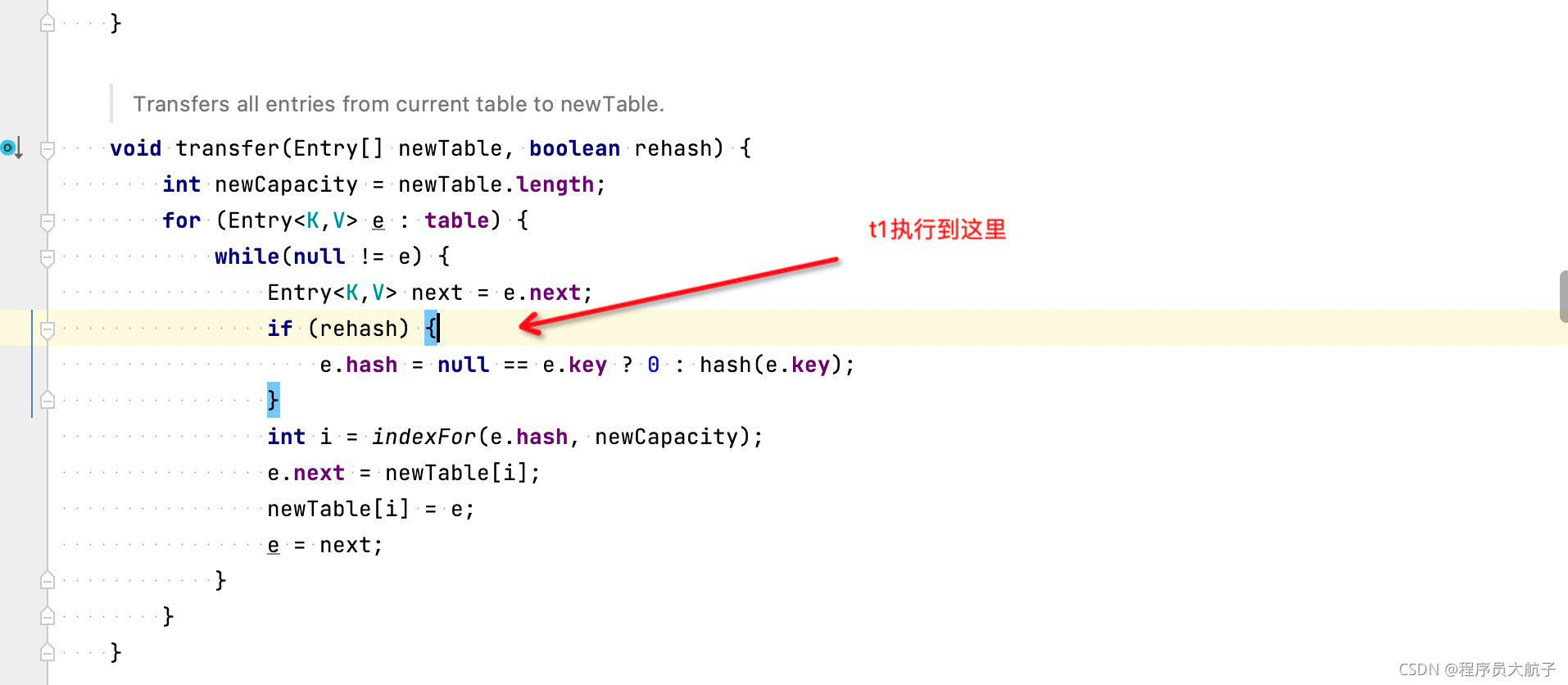
此時t1、t2都有自己擴容之后的陣列,此時t2完成擴容,值得注意的是,t1、t2的陣列不是一個,但是陣列中的鏈表物件參考的都是一個,
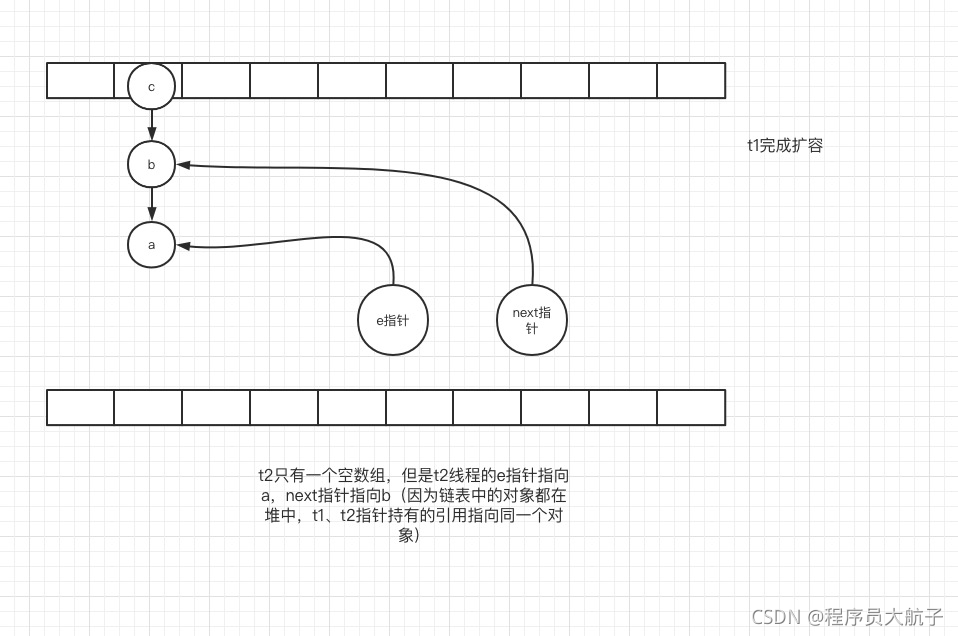
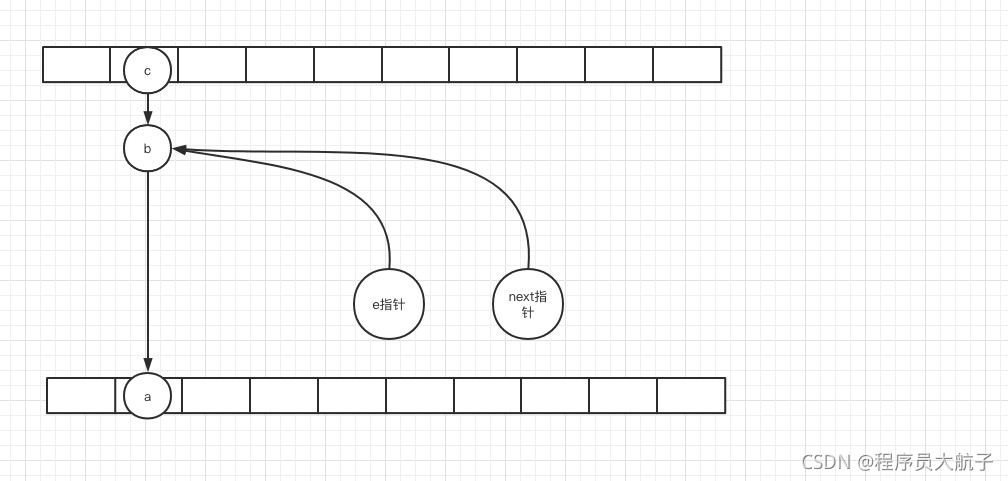
這時候t1從睡夢中醒來了,它會主要做這三步操作,
操作完了之后是這個樣子的,
進第二次回圈,這時候,e指標和next指標都是b,再走那三步,
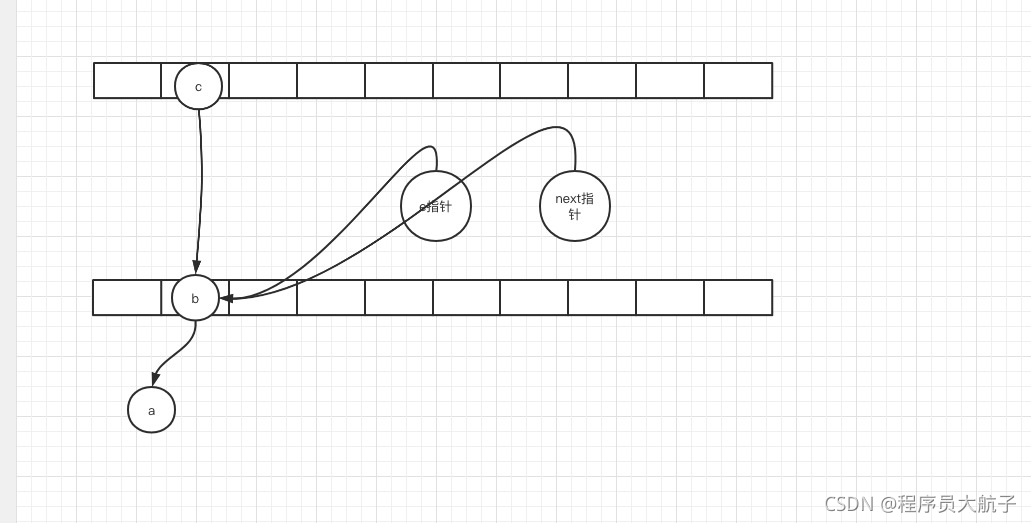
這時候,e和next還都是b,但是t1執行緒下,索引2的位置的頭節點由a,變成了b,然后執行了這么一段代碼,e.next = newTable[i];,把a的next指向b,當當當當,環出來了,
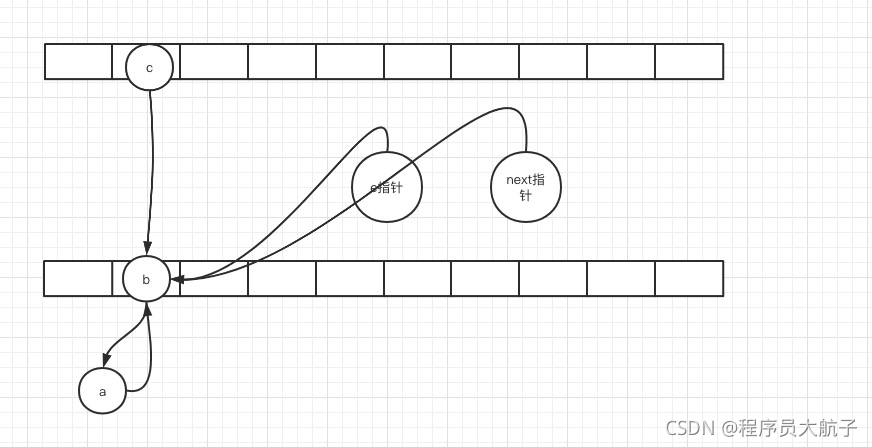
于是,a的next是b,b的next是a,a的next是b,b的next是a,a的next是b,b的next是a,cpu就這么執行啊執行啊,沒完沒了,就100%了,
面試官: 好了好了,說的還算詳細,看來原始碼沒少看啊,剛才你說jdk7要重新rehash,jdk8也是這樣了唄?
龍哥: 不是的,不是的,當然不是的,
面試官: 好好說話,挺大歲數了,別賣萌,
龍哥: 好的哈,jdk8避免了擴容之后重新的rehash計算,因為jdk8計算在陣列中的位置的方式是 hash &(n - 1) ,n是2的整數,舉個例子,如果n是16的時候,(n-1)也就是15的二進制就是1111;如果n是32的時候,那么(n-1)也就是31的二進制就是11111,可以看出,二者的差別就是31比15的高位多了一個1,對于整個 hash &(n - 1) 的結果來看,因為&的運算邏輯是相同的二進制位都是1就是1,一個是0就是0,那么,n等于16和32的運算結果的是否相同就取決于hashcode第五位到底是0還是1,如果是0的話,同一個hashcode對于 hash &(n - 1),n=16、n=32的運算結果就是相同的;如果如果是1的話,同一個hashcode對于 hash &(n - 1) ,n=16、n=32的運算結果就是多了一個16(就是擴容前的容量),因為,n-1的最高位置的1代表的數字,就是n/2的結果,
面試官: 嗯,那jdk8之后HashMap是不是就執行緒安全了,
龍哥: 不是的,jdk8只是不會發生鏈表成環的情況,但是在put操作的時候,會出現元素被覆寫的情況,并且size++也是有執行緒安全問題的,如果要考慮多執行緒的情況下使用,建議使用ConcurrentHashMap,里面有分段鎖,所謂分段鎖,jdk7中ConcurrentHashMap外面有一個Segment陣列,這個Segment繼承了ReentrantLock,我們就可以對每一個Segment單獨上鎖,既能保證執行緒安全,鎖的粒度又不會太大,性能又不會太差,,,
面試官: 停停停,今天主要面試HashMap,最后問一個簡單的問題,陣列什么時候會擴容,
龍哥: 我不會啊,,,, (回家之后問大航子,大航子:有一個東西叫負載因子,默認是0.75,但是科學家前輩算出來的0.69幾才是最完美的值,這個值是用來在空間和時間上取得平衡,比如原來陣列長度是16,那么達到 16 *0.75=12 就會擴容了,一般擴容是原有陣列的兩倍,龍哥,你好棒!)
面試官: 好了你先回家吧,我們改天再面,
龍哥: 別別別,我還會很多,你問問我AQS啥的啊,mysql原理我都懂得,
面試官: 滾!!!!
龍哥: 好嘞!!!!
總結
hashmap的知識點還是比較多的,想要多理解,原始碼還是要多看看的,
常見的比較有深度的HashMap的面試題,應該在這次模擬面試中,龍哥都經歷過了,
最后,感謝大家的觀看,我是大航子,有問題,歡迎留言哈,
最后
如果你是一個新手,下面有龍哥的個人微信,你可以加他進群,一起學習,我會在群里答疑,大家一起進步!奧利給,另外龍哥單身,美女加微信看照片哈!!!!
微信號:nbl94953,昵稱:nbl
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/340733.html
標籤:java