文章目錄
- 一、前言
- 二、HashMap
- 2.1 HashMap資料結構
- 2.2 HashMap執行緒不安全
- 2.3 哈希沖突
- 三、JDK1.7中HashMap的實作
- 3.1 基本元素Entry
- 3.2 插入邏輯
- 3.2.1 插入邏輯
- 3.2.2 新建節點添加到鏈表
- 3.3 陣列擴容邏輯
- 3.4 null處理
- 3.5 辨析擴容、樹化和哈希沖突
- 四、JDK1.8中HashMap的實作
- 4.1 基本元素Node
- 4.2 插入邏輯
- 4.3 鏈表樹化邏輯
- 4.4 鏈表樹化
- 五、HashMap在1.7和1.8之間四個不同
- 六、尾聲
一、前言
二、HashMap
2.1 HashMap資料結構
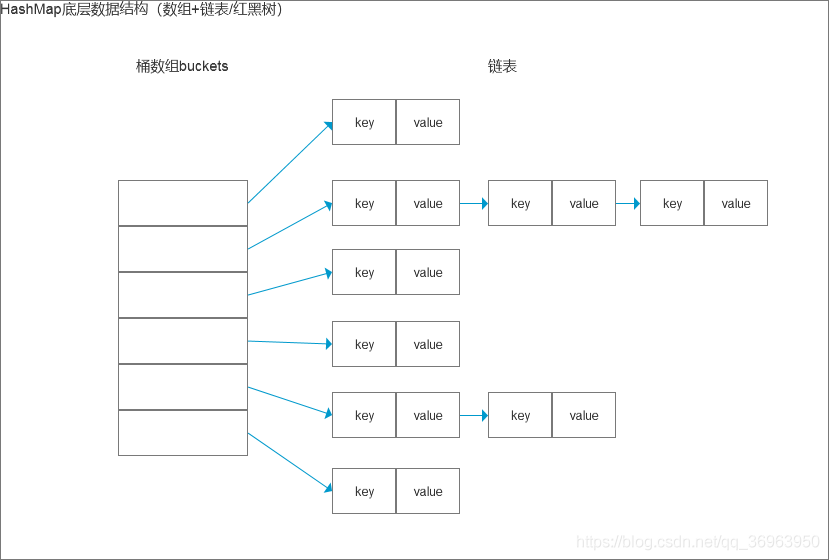
學習的時候,先整體后細節,HashMap整體結構是 底層陣列+鏈表 ,先記住,再開始看下面的
HashMap相關知識點:
(1) 底層資料結構:HashMap基于哈希散串列實作 ,可以實作對資料的讀寫,
(2) 插入邏輯put()方法:將鍵值對傳遞給put方法時,它呼叫鍵物件的hashCode()方法來計算hashCode,然后找到相應的bucket位置(即陣列)來儲存值物件,當獲取物件時,通過鍵物件的equals()方法找到正確的鍵值對,然后回傳值物件,
(3) 哈希沖突:插入邏輯中,如果發生哈希沖突,使用鏈表來解決hash沖突問題,即當發生沖突了,物件將會儲存在鏈表的頭節點中,HashMap在每個鏈表節點中儲存鍵值對物件,當兩個不同的鍵物件的hashCode相同時(HashMap在兩個key-value,hashcode相同導致index相同,就認為發生哈希沖突,equals相同任務同一個,不重復插入,HashSet在hashcode和equals相同,認為同一個,不重復插入),它們會儲存在同一個bucket位置的鏈表中,如果鏈表大小超過閾值(TREEIFY_THRESHOLD,8),鏈表就會被改造為樹形結構,
(4) HashMap和HashSet:HashMap在兩個key-value,hashcode相同導致index相同,哈希沖突,equals相同任務同一個,不重復插入,HashSet在hashcode和equals相同,認為同一個,不重復插入,
2.2 HashMap執行緒不安全
HashMap是應用更廣泛的哈希表實作,而且大部分情況下,都能在常數時間性能的情況下進行put和get操作,但是,HashMap在多執行緒并發的情況下是不安全的,通過兩個問題的回答來解釋原因,
問題1:為什么說HashMap是執行緒不安全的?
回答1:在接近臨界點時,若此時兩個或者多個執行緒進行put操作,都會進行resize(擴容)和reHash(為key重新計算所在位置),而reHash在并發的情況下可能會形成鏈表環,即在多執行緒環境下,使用HashMap進行put操作會引起死回圈,導致CPU利用率接近100%,所以在并發情況下不能使用HashMap,
問題2:為什么在并發執行put操作會引起死回圈?
回答2:因為多執行緒會導致HashMap的Entry鏈表形成環形資料結構,一旦形成環形資料結構,Entry的next節點永遠不為空,就會產生死回圈獲取Entry,值得注意的是,JDK1.7的情況下,并發擴容時容易形成鏈表環,此情況在1.8時就好太多太多了,因為在1.8中當鏈表長度大于閾值(默認長度為8)時,鏈表會被改成樹形(紅黑樹)結構,
2.3 哈希沖突
哈希沖突定義:若干Key的哈希值按陣列大小取模后,如果落在同一個陣列下標上,將組成一條Entry鏈,對Key的查找需要遍歷Entry鏈上的每個元素執行equals()比較(tip:知道了HashMap的“陣列+鏈表”結構,就很好懂哈希沖突了),
加載因子:為了降低哈希沖突的概率,默認當HashMap中的鍵值對達到陣列大小的75%時,即會觸發擴容,因此,如果預估容量是100,即需要設定100/0.75=134的陣列大小,又因為HashMap大小必須是2的整數次冪,所以是大于134的最小的2的整數次冪,即256,
減少哈希沖突兩方法:降低加載因子,加大初始大小,
HashMap中陣列擴容相關概念(size capacity size/capacity):
(1) size是當前現實的記錄數;capacity是理論上的容量,第一次由初始化決定,之后由擴容決定;initial capacity是初始的capacity,第一次的capacity,
(2) 負載因子等于“size/capacity”,全稱為當前負載因子,其作用是當負載因子達到負載極限的時候擴容,當負載因子為0,表示空的hash表;負載因子為0.5,表示半滿的散串列,依此類推,輕負載的散串列具有沖突少、適宜插入與查詢的特點(但是使用Iterator迭代元素時比較慢),
(3) 負載極限:“負載極限”是一個0~1的數值,“負載極限”決定了hash表的最大填滿程度,當hash表中的負載因子達到指定的“負載極限”時,hash表會自動成倍地增加容量(桶的數量),并將原有的物件重新分配,放入新的桶內,這稱為rehashing,HashMap和HashTable的構造器允許指定一個負載極限,HashMap和HashTable默認的“負載極限”為0.75,這表明當該hash表的3/4已經被填滿時,hash表會發生rehashing,
(4) “負載極限”的默認值(0.75)是時間和空間成本上的一種折中:
較高的“負載極限”可以降低hash表所占用的記憶體空間,但會增加查詢資料的時間開銷,而查詢是最頻繁的操作(HashMap的get()與put()方法都要用到查詢),所以會影響時間性能;
較低的“負載極限”會提高查詢資料的性能,但會增加hash表所占用的記憶體開銷,影響空間性能;
程式員可以根據實際情況來調整“負載極限”值,
以上專有名詞連接起來是:size是記錄數,capacity是桶數量,兩者size/capacity得到負載因子,當負載因子達到理論設定的負載極限的時候擴容,專有名詞(size、capacity、負載因子、負載極限、擴容(具體擴容邏輯)),所有的這些都可以在原始碼中找到邏輯,
三、JDK1.7中HashMap的實作
3.1 基本元素Entry
陣列中的每一個元素其實就是Entry<K,V>[] table,Map中的key和value就是以Entry的形式存盤的,Entry包含四個屬性:key、value、hash值和用于單向鏈表的next,關于Entry<K,V>的具體定義參看如下原始碼:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
JDK7中的HashMap,小結為以下幾點:
(1) 基本元素為Entry,Entry包含四個屬性:key、value、int型別的hash值和用于單向鏈表的Node型別的next;
(2) hash不是用于新插入的Entry和原有的鏈表節點的hashcode比較的,只是用于計算一下陣列index的;
(3) key,value 是用于新插入的Entry和原有的鏈表的節點的 key,value 比較的,只有到equals和hashcode(index)比較都先相同,就認為是相同元素,被認為是相同就不會插入HashMap;
(4) next用于下一個鏈表中下一個節點,
3.2 插入邏輯
3.2.1 插入邏輯
HashMap插入邏輯由put()方法來完成,實際上是先執行hash()方法,再執行indexFor()方法,再執行equals()方法,即當向 HashMap 中 put一對鍵值時,它會根據 key的 hashCode 值計算出一個位置, 該位置就是此物件準備往陣列中存放的位置, 該計算程序參看如下代碼:
transient int hashSeed = 0;
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
插入邏輯
第一步,確定陣列下標:indexFor使用hash方法計算出來的值得到陣列下標,hash(Object)方法是用來計算哈希值的,indexFor(hash,length)方法是用來計算陣列下標的, 兩者關系:indexFor方法根據hash(Object)方法的回傳值作為實參來計算陣列下標;
第二步,插入,如果指定的陣列下標無物件存在,不發生哈希沖突,直接插入;如果指定的陣列下標有物件存在,發生哈希沖突,使用equals對鏈條上物件比較,全部為false插入,其中一個為true,表示已經存在(hash和equals都相同就是存在)
put操作中的hashcode方法和equals方法:僅以put操作為例,插入操作中hash方法用來作為計算陣列下標的輸入,equals用于比較物件是否存在,
問題1:指定陣列下標有值,哈希沖突后如何處理?
回答1:put操作的時候,當兩個key通過hashCode計算相同時,則發生了hash沖突(碰撞),HashMap解決hash沖突的方式是用鏈表(拉鏈法),當發生hash沖突時,則將存放在陣列中的Entry設定為新值的next(比如A和B都hash后都映射到下標i中,之前已經有A了,當map.put(B)時,將B放到下標i中,A則為B的next,所以新值存放在鏈表最頭部的陣列中,舊值在新值的鏈表上),
問題2:哈希沖突發生后,為什么后插入的值要放在鏈表頭部?
回答2:因為后插入的Entry是“熱乎的”,被查找的可能性更大(因為get查詢的時候會遍歷整個鏈表),既然后插入的Entry是“熱乎的”,那么這個后插入的Entry應該放在哪里呢?當然是放在鏈表頭部,因為鏈表查找復雜度為O(n),插入和洗掉復雜度為O(1),如果將新值插在末尾,就需要先經過一輪遍歷,這個開銷大,如果是插在頭結點,省去了遍歷的開銷,還發揮了鏈表插入性能高的優勢,
3.2.2 新建節點添加到鏈表
HashMap中,新建節點添加到鏈表需要由addEntry()和createEntry()方法來完成,addEntry()表示鏈表中頭插法插入節點和createEntry()表示新建一個Entry節點,
先找到陣列下標后,先進行key判重,如果沒有重復,就準備將新值放入到鏈表的表頭,
void addEntry(int hash, K key, V value, int bucketIndex) {
// addEntry方法中,如果當前 HashMap 大小已經達到了閾值,并且新值要插入的陣列位置已經有元素了,那么要擴容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 擴容
resize(2 * table.length);
// 擴容以后,重新計算 hash 值
hash = (null != key) ? hash(key) : 0;
// 重新計算擴容后的新的下標
bucketIndex = indexFor(hash, table.length);
}
// createEntry就是插入新值
createEntry(hash, key, value, bucketIndex); // key value由方法引數提供,未擴容,hash bucketIndex使用方法引數傳遞的,擴容,hash bucketIndex使用新計算的
}
// 這個很簡單,其實就是將新值放到鏈表的表頭,然后 size++
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
上述代碼解釋了JDK7情況下的陣列擴容流程:
(1) addEntry方法中,如果當前 HashMap 大小已經達到了閾值,并且新值要插入的陣列位置已經有元素了,那么要擴容
(2) HashMap中陣列擴容方式:兩倍擴容
(3) 擴容后重新計算要已經插入了的key的陣列下標:先hash,然后indexFor
(4) 新元素插入指定陣列下標的鏈頭,table[bucketIndex] = new Entry<>(hash, key, value, e); 新建一個Entry就是一個元素
這個方法的主要邏輯就是先判斷是否需要擴容,需要帶的話先擴容,然后再將這個新的資料插入到擴容后的陣列的相應位置處的鏈表的表頭,即先擴容再插入,
1.7中是先擴容后插入新值的,1.8中是先插值再擴容,
3.3 陣列擴容邏輯
定義:擴容就是用一個新的大陣列替換原來的小陣列,并將原來陣列中的值遷移到新的陣列中,實作擴容的方法是resize()
由于是雙倍擴容,遷移程序中,會將原來table[i]中的鏈表的所有節點,分拆到新的陣列的newTable[i]和newTable[i+oldLength]位置上,比如:原來陣列長度是16,那么擴容后,原來table[0]處的鏈表中的所有元素會被分配到新陣列中newTable[0]和newTable[16]這兩個位置,擴容期間,由于會新建一個新的空陣列,并且用舊的項填充到這個新的陣列中去,所以,在這個填充的程序中,如果有線程獲取值,很可能會取到 null 值,而不是我們所希望的、原來添加的值,
我們對照HashMap的結構來說,如下:

上圖中,左邊部分即代表哈希表,也稱為哈希陣列(默認陣列大小是16,每對key-value鍵值對其實是存在map的內部類entry里的),陣列的每個元素都是一個單鏈表的頭節點,跟著的藍色鏈表是用來解決沖突的,如果不同的key映射到了陣列的同一位置處,就將其放入單鏈表中,
當size>=threshold( threshold等于“容量*負載因子”)時,會發生擴容,
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); // 擴容
hash = (null != key) ? hash(key) : 0; // 擴容后要用新的hash,不能用引數的
bucketIndex = indexFor(hash, table.length); // 擴容后要用新的bucketIndex,不用用引數的
}
createEntry(hash, key, value, bucketIndex); // key value由方法引數提供,未擴容,hash bucketIndex使用方法引數傳遞的,擴容,hash bucketIndex使用新計算的
}
特別提示:JDK1.7中resize,只有當 size>=threshold 并且 table中的那個槽中已經有Entry時,才會發生resize,即有可能雖然size>=threshold,但是必須等到相應的槽至少有一個Entry時,才會觸發擴容,可以通過上面的代碼看到每次resize都會擴大一倍容量(2 * table.length),
JDK7情況插入情況下的擴容
(1) 擴容方式:HashMap擴容方式:兩倍擴容 newsize=oldsize *2
(2) 陣列擴容的觸發-兩個條件:addEntry方法中,如果當前 HashMap 大小已經達到了閾值75%,并且新值要插入的陣列位置已經有元素了,才執行擴容(兩個條件,即有可能雖然size>=threshold,但是必須等到相應的槽至少有一個Entry時,才會擴容)
(3) 擴容后重新計算要已經插入了的key的陣列下標:使用hash和tab.lenght計算陣列下標index,準備插入,index=hash&(tab.length-1);
(4) 擴容后的插入,對于原來陣列的位置:擴容就是用一個新的大陣列替換原來的小陣列,并將原來陣列中的值遷移到新的陣列中,由于是雙倍擴容,遷移程序中,會將原來table[i]中的鏈表的所有節點,分拆到新的陣列的newTable[i]和newTable[i+oldLength]位置上,如原來陣列長度是16,那么擴容后,原來table[0]處的鏈表中的所有元素會被分配到新陣列中newTable[0]和newTable[16]這兩個位置,從而減小鏈表長度,
(5) 擴容后的新插入:equals比較全部為false,然后將新元素插入指定陣列下標的鏈頭table[bucketIndex] = new Entry<>(hash, key, value, e); 新建一個Entry就是一個元素,
(6) 擴容程序中的隱患:擴容期間,由于會新建一個新的空陣列,并且用舊的項填充到這個新的陣列中去,所以,在這個填充的程序中,如果有執行緒獲取值,很可能會取到 null 值,而不是我們所希望的、原來添加的值,
tip:ArrayList 1.5倍擴容,Vector兩倍擴容,HashTable newsize=2 * oldsize +1 ,HashMap newsize=2 * oldsize
3.4 null處理
前面說過HashMap的key是允許為null的,當出現這種情況時,會放到table[0]中,
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
3.5 辨析擴容、樹化和哈希沖突
1、擴容:擴容的物件是陣列
擴容兩個條件:addEntry方法中,如果當前 HashMap 大小已經達到了閾值75%,且新值要插入的陣列位置已經有元素了,才觸發擴容(擴容的第二個條件一定要put操作才能滿足)
擴容的時機:擴容一定要在put操作才會出現(因為擴容的第二個條件一定要put操作才能滿足)
2、樹化:樹化的物件是鏈表
樹化的條件:鏈表節點數達到8,且要求陣列長度大于64
樹化的時機:鏈表樹化一定要在put操作才會出現,樹鏈表化一定要在remove操作才會出現,
3、 哈希沖突:哈希沖突的定義是要插入的陣列index位置有元素了,
JDK7(涉及哈希沖突、陣列擴容):
(1)如果未發生哈希沖突,直接放到陣列中;
(2)如果哈希沖突,沒有達到閾值的75%,插入到鏈表前面(頭插法);
(3)如果哈希沖突,達到閾值75%,陣列擴容操作,擴容后原陣列元素和新插入的陣列元素都要變動的;
JDK8(涉及哈希沖突、陣列擴容、鏈表樹化):
(1)如果未發生哈希沖突,直接放到陣列中;
(2)如果哈希沖突,鏈表節點數未達到8,但是陣列長度小于64,尾插法放在鏈表后面,插入完成后判斷閾值是否擴容(陣列閾值是否達到75%);
(3)如果哈希沖突,鏈表節點數未達到8,但是陣列長度大于等于64,尾插法放在鏈表后面,插入完成后判斷閾值是否擴容(陣列閾值是否達到75%);
(4)如果哈希沖突,鏈表節點數達到8,但是陣列長度小于64,尾插法放在鏈表后面,插入完成后判斷閾值是否擴容(陣列閾值是否達到75%);
(5)如果哈希沖突,鏈表節點數達到8,且要求陣列長度大于等于64,尾插法插入到鏈表后面,鏈表樹化,插入完成后判斷閾值是否擴容(陣列閾值是否達到75%),
小結:擴容、樹化、哈希沖突都是在put操作出現,但是三種不同,擴容和樹化都是put操作發生哈希沖突導致的,put操作如果不哈希沖突啥事沒有,所以只最重要的是設計分布均衡的哈希演算法,陣列擴容和鏈表樹化都是緩解措施,JDK7是put涉及哈希沖突、陣列擴容,JDK8是put涉及哈希沖突、陣列擴容、鏈表樹化,JDK8中remove可以涉及樹鏈表化,
解釋:擴容和樹化都是put操作發生哈希沖突導致的
因為擴容的一個條件是要插入的陣列位置已經有元素了,樹化的條件是鏈表節點數大于8,鏈表節點數都達到8了,陣列位置也一定有元素,而哈希沖突的定義是要插入的陣列位置已經有元素,
四、JDK1.8中HashMap的實作
4.1 基本元素Node
HashMap底層維護的是陣列+鏈表,我們可以通過一小段原始碼來看看:
/**
* The default initial capacity - MUST be a power of two.
* 即 默認初始大小,值為16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
* 即 最大容量,必須為2^30
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
* 負載因子為0.75
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
* 大致意思就是說hash沖突默認采用單鏈表存盤,當單鏈表節點個數大于8時,會轉化為紅黑樹存盤
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
* hash沖突默認采用單鏈表存盤,當單鏈表節點個數大于8時,會轉化
為紅黑樹存盤,
* 當紅黑樹中節點少于6時,則轉化為單鏈表存盤
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
* hash沖突默認采用單鏈表存盤,當單鏈表節點個數大于8時,會轉化為紅黑樹存盤,
* 但是有一個前提:要求陣列長度大于64,否則不會進行轉化
*/
static final int MIN_TREEIFY_CAPACITY = 64;
通過以上代碼可以看出初始容量(16)、負載因子以及對陣列的說明,
HashMap相關的變數:
(1) 初始化默認大小是16 initial capacity 16 JDK7+JDK8都一樣
(2) 最大容量,必須為2^30 JDK7+JDK8都一樣
(3) 默認負載因子為0.75 達到0.75就擴容,JDK7+JDK8都一樣
(4) 樹化閾值為8,鏈表化閾值為6 JDK8新增
樹化的兩個條件: 鏈表節點數達到8,且要求陣列長度大于64,
HashMap中最重要的兩個操作是陣列擴容和插入元素時陣列哈希沖突,但是要注意以下幾點:
(1) 擴容是陣列擴容,哈希沖突是要插入的陣列下標已有元素,兩者的物件都是陣列,兩者的關系是擴容是為了減低負載因子,減少哈希沖突;
(2) 減少哈希沖突兩個設計:設計一個好的哈希演算法 + 陣列擴容;
(3) 如果put操作真正發生了哈希沖突:使用equals方法比較,如果為true不插入,否則JDK7是使用頭插法插入鏈表,JDK8使用尾插法插入鏈表,JDK8額外添加了樹化邏輯;
從JDK7到JDK8,Entry的名字變成了Node,原因是和紅黑樹的實作TreeNode相關聯,1.8與1.7最大的不同就是利用了紅黑樹,即由陣列+鏈表(或紅黑樹)組成,JDK1.8中,當同一個hash值的節點數不小于8時,將不再以單鏈表的形式存盤了,會被調整成一顆紅黑樹(上圖中null節點沒畫),這就是JDK1.7與JDK1.8中HashMap實作的最大區別,
transient Node<K,V>[] table;
(1) 在JDK1.8中HashMap的內部結構可以看作是陣列(Node<K,V>[] table)和鏈表的復合結構,
(2) 陣列被分為一個個桶(bucket),通過哈希值決定了鍵值對在這個陣列中的尋址(哈希值相同的鍵值對,就是哈希沖突,則以鏈表形式存盤,
(3) 如果鏈表大小超過閾值(TREEIFY_THRESHOLD,8),圖中的鏈表就會被改造為樹形(紅黑樹)結構,
在分析JDK1.7中HashMap的哈希沖突時,不知大家是否有個疑問就是萬一發生碰撞的節點非常多怎么辦?如果說成百上千個節點在hash時發生碰撞,存盤一個鏈表中,那么如果要查找其中一個節點,那就不可避免的花費O(N)的查找時間,這將是多么大的性能損失,這個問題終于在JDK1.8中得到了解決,在最壞的情況下,鏈表查找的時間復雜度為O(n),而紅黑樹一直是O(logn),這樣會提高HashMap的效率,
JDK1.7中HashMap采用的是位桶+鏈表的方式,即我們常說的散列鏈表的方式;
JDK1.8中采用的是位桶+鏈表/紅黑樹的方式,雖然加快鏈表查找效率,但是也是非執行緒安全的,因為只有當某個位桶的鏈表的長度達到某個閥值的時候,這個鏈表才會轉換成紅黑樹,
從JDK7的Entry變為JDK8的Node
(1) 基本元素使用Node,意為紅黑樹的節點,Node包含四個屬性:key、value、hash值和用于單向鏈表的next,和JDK7的Entry節點一樣;
(2) hash不是用于新插入的Entry和原有的鏈表節點的hashcode比較的,只是用于計算一下陣列index的;
(3) key,value 是用于新插入的Entry和原有的鏈表的節點的 key,value 比較的,只有到equals和hashcode(index)比較都先相同,就認為是相同元素,被認為是相同元素的不插入HashMap;
(4) next用于下一個鏈表中下一個節點,
4.2 插入邏輯
通過分析put方法的原始碼,可以讓這種區別更直觀:
static final int TREEIFY_THRESHOLD = 8; // 樹化
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); // 呼叫putVal
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//如果當前map中無資料,執行resize方法,并且回傳n JDK7先擴容再插入,可能無效擴容,JDK8先插入再擴容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果要插入的鍵值對要存放的這個位置剛好沒有元素,那么把他封裝成Node物件,放在這個位置上即可,插入的時候沒有哈希沖突
if ((p = tab[i = (n - 1) & hash]) == null) // 這里對p賦值,就是新的要插入的節點
tab[i] = newNode(hash, key, value, null); // 插入
//否則的話,說明這陣列上面有元素,插入的時候發生哈希沖突
else {
Node<K,V> e; K k;
//如果這個元素的key與要插入的一樣,那么就替換一下,
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; // 直接將p賦值給區域變數e
// 1.如果這個元素的key與要插入的不一樣,如果當前節點是TreeNode型別的資料,執行putTreeVal方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // else表示如果這個元素的key與要插入的不一樣,如果還是遍歷這條鏈子上的資料,跟JDK7沒什么區別
for (int binCount = 0; ; ++binCount) { // 回圈
if ((e = p.next) == null) { // 回圈找到一個空位置的就插入鏈表
p.next = newNode(hash, key, value, null);
//2.完成了操作后多做了一件事情,判斷,并且可能執行treeifyBin方法
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break; // 插入并判斷是否樹化,break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break; // 如果鏈表上已經存在了,直接break;這里不用樹化了,應該根本沒插入
p = e; // 不斷將e賦值給p,更新p,就是p在鏈條上不斷往后移動
}
}
// e 不為null 要么第一個if替換,要么else if樹插入,要么鏈表插入,總之插入成功了,回傳oldValue
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) //true || --
e.value = value;
//3.
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判斷閾值,決定是否陣列擴容 插入后決定是否擴容
if (++size > threshold)
resize();
//4. 插入之后的操作
afterNodeInsertion(evict);
return null;
}
以上代碼中的特別之處如下:
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
treeifyBin()就是將鏈表轉換成紅黑樹,
原始碼決議putVal()操作(語言組織),如下:
擴容:如果當前map中無資料,執行resize方法,并且回傳n JDK8先擴容再插入,JDK7先插入再擴容,可能無效擴容
沒有哈希沖突:如果要插入的鍵值對要存放的這個位置剛好沒有元素,那么把他封裝成Node物件,放在這個位置上即可,插入的時候沒有哈希沖突
這里對p賦值,就是新的要插入的節點
else 表示 否則的話,說明這陣列上面有元素,插入的時候發生哈希沖突
if表示 //如果這個元素的key與要插入的一樣,那么就替換一下,
else if 表示 1.如果這個元素的key與要插入的不一樣,如果當前節點是TreeNode型別的資料,執行putTreeVal方法
else表示如果這個元素的key與要插入的不一樣,如果還是遍歷這條鏈子上的資料,跟JDK7沒什么區別
// 回圈
// 回圈找到一個空位置的就插入鏈表
//2.完成了操作后多做了一件事情,判斷,并且可能執行treeifyBin方法
// 插入并判斷是否樹化,break;
// 如果鏈表上已經存在了,直接break;這里不用樹化了,應該根本沒插入
// 不斷將e賦值給p,更新p,就是p在鏈條上不斷往后移動
回傳oldValue: e 不為null 要么第一個if替換,要么else if樹插入,要么鏈表插入,總之插入成功了,回傳oldValue
插入后判斷是否擴容:判斷閾值,決定是否陣列擴容 插入后決定是否擴容
最后 插入之后的操作
完成了,
關于putVal(),注意以下三點:
(1) 樹化有個要求就是陣列長度必須大于等于MIN_TREEIFY_CAPACITY(64),否則繼續采用擴容策略;
(2) resize方法兼顧兩個職責,創建初始存盤表格,或者在容量不滿足需求的時候;
(3) 在JDK1.8中取消了indefFor()方法,直接用(tab.length-1)&hash計算出下標,所以看到這個,代表的就是陣列的下角標,
4.3 鏈表樹化邏輯
樹化操作的程序有點復雜,可以結合原始碼來看看,將原本的單鏈表轉化為雙向鏈表,再遍歷這個雙向鏈表轉化為紅黑樹,
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//樹形化還有一個要求就是陣列長度必須大于等于64,否則繼續采用擴容策略
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;//hd指向首節點,tl指向尾節點
do {
TreeNode<K,V> p = replacementTreeNode(e, null);//將鏈表節點轉化為紅黑樹節點
if (tl == null) // 如果尾節點為空,說明還沒有首節點
hd = p; // 當前節點作為首節點
else { // 尾節點不為空,構造一個雙向鏈表結構,將當前節點追加到雙向鏈表的末尾
p.prev = tl; // 當前樹節點的前一個節點指向尾節點
tl.next = p; // 尾節點的后一個節點指向當前節點
}
tl = p; // 把當前節點設為尾節點
} while ((e = e.next) != null); // 繼續遍歷單鏈表
//將原本的單鏈表轉化為一個節點型別為TreeNode的雙向鏈表
if ((tab[index] = hd) != null) // 把轉換后的雙向鏈表,替換陣列原來位置上的單向鏈表
hd.treeify(tab); // 將當前雙向鏈表樹形化
}
}
特別注意:樹化有個要求就是陣列長度必須大于等于MIN_TREEIFY_CAPACITY(64),否則繼續采用擴容策略,
總的來說,HashMap默認采用陣列+單鏈表方式存盤元素,當元素出現哈希沖突時,會存盤到該位置的單鏈表中,但是單鏈表不會一直增加元素,當元素個數超過8個時,會嘗試將單鏈表轉化為紅黑樹存盤,但是在轉化前,會再判斷一次當前陣列的長度,只有陣列長度大于64才處理,否則,進行擴容操作,
將雙向鏈表轉化為紅黑樹的實作:
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null; // 定義紅黑樹的根節點
for (TreeNode<K,V> x = this, next; x != null; x = next) { // 從TreeNode雙向鏈表的頭節點開始逐個遍歷
next = (TreeNode<K,V>)x.next; // 頭節點的后繼節點
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x; // 頭節點作為紅黑樹的根,設定為黑色
}
else { // 紅黑樹存在根節點
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) { // 從根開始遍歷整個紅黑樹
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h) // 當前紅黑樹節點p的hash值大于雙向鏈表節點x的哈希值
dir = -1;
else if (ph < h) // 當前紅黑樹節點的hash值小于雙向鏈表節點x的哈希值
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) // 當前紅黑樹節點的hash值等于雙向鏈表節點x的哈希值,則如果key值采用比較器一致則比較key值
dir = tieBreakOrder(k, pk); //如果key值也一致則比較className和identityHashCode
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) { // 如果當前紅黑樹節點p是葉子節點,那么雙向鏈表節點x就找到了插入的位置
x.parent = xp;
if (dir <= 0) //根據dir的值,插入到p的左孩子或者右孩子
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x); //紅黑樹中插入元素,需要進行平衡調整(程序和TreeMap調整邏輯一模一樣)
break;
}
}
}
}
//將TreeNode雙向鏈表轉化為紅黑樹結構之后,由于紅黑樹是基于根節點進行查找,所以必須將紅黑樹的根節點作為陣列當前位置的元素
moveRootToFront(tab, root);
}
然后將紅黑樹的根節點移動端陣列的索引所在位置上:
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash; //找到紅黑樹根節點在陣列中的位置
TreeNode<K,V> first = (TreeNode<K,V>)tab[index]; //獲取當前陣列中該位置的元素
if (root != first) { //紅黑樹根節點不是陣列當前位置的元素
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null) //將紅黑樹根節點前后節點相連
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null) //將陣列當前位置的元素,作為紅黑樹根節點的后繼節點
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
putVal方法處理的邏輯比較多,包括初始化、擴容、樹化,近乎在這個方法中都能體現,針對原始碼簡單講解下幾個關鍵點:
如果Node<K,V>[] table是null,resize方法會負責初始化,即如下代碼:
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
resize方法兼顧兩個職責:創建初始存盤表格 + 在容量不滿足需求的時候進行擴容(resize),
在放置新的鍵值對的程序中,如果發生下面條件,就會發生擴容,
if (++size > threshold)
resize();
具體鍵值對在哈希表中的位置(陣列index)取決于下面的位運算:
i = (n - 1) & hash
仔細觀察哈希值的源頭,會發現它并不是key本身的hashCode,而是來自于HashMap內部的另一個hash方法,為什么這里需要將高位資料移位到低位進行異或運算呢?這是因為有些資料計算出的哈希值差異主要在高位,而HashMap里的哈希尋址是忽略容量以上的高位的,那么這種處理就可以有效避免類似情況下的哈希碰撞,
在JDK1.8中取消了indefFor()方法,直接用(tab.length-1)&hash,所以看到這個,代表的就是陣列的下角標,
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
4.4 鏈表樹化
問題1:為什么HashMap為什么要樹化?
回答1: 一句話概括:制造哈希碰撞從而造成DOS攻擊,樹化后優化哈希碰撞產生后的存取,
解釋1:其實這本質上一個安全問題,因為在元素放置程序中,如果一個物件哈希沖突,都被放置到同一個桶里,則會形成一個鏈表,我們知道鏈表查詢是線性的,會嚴重影響存取的性能,而在現實世界,構造哈希沖突的資料并不是非常復雜的事情,惡意代碼就可以利用這些資料大量與服務器端互動,導致服務器端CPU大量占用,這就構成了哈希碰撞拒絕服務攻擊,國內一線互聯網公司就發生過類似攻擊事件,
哈希碰撞攻擊: 用哈希碰撞發起拒絕服務攻擊(DOS,Denial-Of-Service attack),常見的場景是攻擊者可以事先構造大量相同哈希值的資料(制造哈希碰撞從而造成DOS攻擊,樹化后優化哈希碰撞產生后的存取),然后以JSON資料的形式發送給服務器,服務器端在將其構建成為Java物件程序中,通常以HashTable或HashMap等形式存盤,哈希碰撞將導致哈希表發生嚴重退化,演算法復雜度可能上升一個資料級,進而耗費大量CPU資源,
問題2:鏈表樹化的兩個條件?
回答2:鏈表樹化的兩個條件是當鏈表長度大于或等于閾值(默認為 8)的時候,如果同時還滿足容量大于或等于 MIN_TREEIFY_CAPACITY(默認為 64)的要求,就會把鏈表轉換為紅黑樹,同樣,后續如果由于洗掉或者其他原因調整了大小,當紅黑樹的節點小于或等于 6 個以后,又會恢復為鏈表形態,
解釋2:時間和空間平衡的思想:默認是鏈表長度達到 8 就轉成紅黑樹,而當長度降到 6 就轉換回去,這體現了時間和空間平衡的思想,
(1) 鏈表樹化的目的在于提交查找效率:每次遍歷一個鏈表,平均查找的時間復雜度是 O(n),n 是鏈表的長度,紅黑樹有和鏈表不一樣的查找性能,由于紅黑樹有自平衡的特點,可以防止不平衡情況的發生,所以可以始終將查找的時間復雜度控制在 O(log(n)),最初鏈表還不是很長,所以可能 O(n) 和 O(log(n)) 的區別不大,但是如果鏈表越來越長,那么這種區別便會有所體現,所以為了提升查找性能,需要把鏈表轉化為紅黑樹的形式,
(2) 樹鏈表化的目的在于減少空間占用:最開始使用鏈表的時候,空間占用是比較少的,而且由于鏈表短,所以查詢時間也沒有太大的問題,可是當鏈表越來越長,需要用紅黑樹的形式來保證查詢的效率,但是又遇到空間占用問題,單個 TreeNode 需要占用的空間大約是普通 Node 的兩倍,所以只有當包含足夠多的 Nodes 時才會轉成 TreeNodes,用空間占用換取查詢速度加快,而是否足夠多就是由TREEIFY_THRESHOLD 的值決定的,所以,當桶中節點數由于移除或者 resize 變少后,又會變回普通的鏈表的形式,以便節省空間,
處理哈希沖突兩個方法:一個好的哈希演算法、鏈表樹化(前者才是根本,后者只是網路安全制造哈希,實際開發中,發現 HashMap 內部出現了紅黑樹的結構,那可能是我們的哈希演算法出了問題,所以需要選用合適的hashCode方法,以便減少沖突,
問題3:為什么在JDK1.8中進行對HashMap優化的時候,把鏈表轉化為紅黑樹的閾值是8,而不是7或者不是20呢?
回答3:碰撞從而造成DOS攻擊和不合理哈希演算法的處理,所以設計為8,
解釋3:
(1) 避免頻繁轉換,樹化鏈表化轉換成本與二叉樹優化查詢性能之間的平衡:如果選擇6和8(如果鏈表小于等于6樹還原轉為鏈表,大于等于8轉為樹),中間有個差值7可以有效防止鏈表和樹頻繁轉換,假設一下,如果設計成鏈表個數超過8則鏈表轉換成樹結構,鏈表個數小于8則樹結構轉換成鏈表,如果一個HashMap不停的插入、洗掉元素,鏈表個數在8左右徘徊,就會頻繁的發生樹轉鏈表、鏈表轉樹,效率會很低,
(2) 數學證明,泊松分布:在理想情況下,鏈表長度符合泊松分布,各個長度的命中概率依次遞減,當長度為 8 的時候,是最理想的值,由于treenodes的大小大約是常規節點的兩倍,因此我們僅在容器包含足夠的節點以保證使用時才使用它們,當它們變得太小(由于移除或調整大小)時,它們會被轉換回普通的node節點,容器中節點分布在hash桶中的頻率遵循泊松分布,桶的長度超過8的概率非常非常小,所以底層設計者應該是根據概率統計而選擇了8作為閥值,
(3) 統計學問題:一個統計的問題,java設計一定使用數學方法和統計方法,知道得到這個8,就像豐巢快遞為什么是12小時而不是24小時一樣,
應該說,鏈表長度超過 8 就轉為紅黑樹的設計,更多的是為了防止用戶自己實作了不好的哈希演算法時導致鏈表過長,從而導致查詢效率低,而此時轉為紅黑樹更多的是一種保底策略,用來保證極端情況下查詢的效率,通常如果 hash 演算法正常的話,那么鏈表的長度也不會很長,那么紅黑樹也不會帶來明顯的查詢時間上的優勢,反而會增加空間負擔,所以通常情況下,并沒有必要轉為紅黑樹,所以就選擇了概率非常小,小于千萬分之一概率,也就是長度為 8 的概率,把長度 8 作為轉化的默認閾值,
五、HashMap在1.7和1.8之間四個不同
我們可以簡單列下HashMap在1.7和1.8之間的變化,四點變化:
第一,底層資料結構不同
1.7中采用陣列+鏈表,1.8采用的是陣列+鏈表/紅黑樹,即在1.7中鏈表長度超過一定長度后就改成紅黑樹存盤,
第二,index:擴容后index的計算
1.7擴容時需要重新計算哈希值hash,根據hash計算索引位置index,equals比較鏈表上的元素,
1.8并不重新計算哈希值hash,巧妙地采用和擴容后容量進行&操作來計算新的索引位置index,即index = hash & (tab.length - 1) ,
第三,新節點插入鏈表位置:哈希沖突的時候插入的值
插入的時候哈希沖突,需要插入鏈表元素的時候,1.7是采用表頭插入法插入鏈表,1.8采用的是尾部插入法,
在1.7中采用表頭插入法
缺點:因為頭插法,在擴容時會改變鏈表中元素原本的順序,以至于在并發場景下導致鏈表成環的問題;
優點:JDK7考慮剛剛插入的值是熱乎的,所以放在表頭,
在1.8中采用尾部插入法
優點:因為尾插法,所以在擴容時會保持鏈表元素原本的順序,就不會出現鏈表成環的問題了;
缺點:因為尾插法,所有剛剛插入的節點放在最后面了,要找很麻煩,所以引入鏈表樹化,超過8個節點就可以樹化,找新插入的節點只要O(lgN),
第四,陣列擴容的時機:擴容與插入的先后順序
插入的時候哈希沖突,且達到閾值75%,陣列擴容的時候,1.7中是先擴容后插入新值的,1.8中是先插值再擴容,
問題:為什么在JDK1.7的時候是先進行擴容后進行插入,而在JDK1.8的時候則是先插入后進行擴容的呢?
答案:代碼就是這樣寫的,JDK8插入的時候使用了樹化,所以將陣列擴容放到了后面,
在JDK1.8中的話,是先進行插入新值然后進行擴容操作的,主要是因為對鏈表轉為紅黑樹進行的優化,因為你插入這個節點的時候有可能是普通鏈表節點,也有可能是紅黑樹節點,所以導致先插入后擴容,擴容判斷與resize()函式呼叫如下:
//其實就是當這個Map中實際插入的鍵值對的值的大小如果大于這個默認的閾值的時候(初始是16*0.75=12)的時候才會觸發擴容,
//這個是在JDK1.8中的先插入后擴容
if (++size > threshold)
resize();
在JDK1.7中的話,是先進行擴容操作然后進行插入新值的,就是當你發現你插入的桶是不是為空:
(1)如果不為空說明存在值,當前插入會發生哈希沖突,那么就必須得擴容;
(2)如果為空說明不存在值,當前插入不會發生哈希沖突,那么本次插入不需要擴容,那就等到下一次發生Hash沖突的時候在進行擴容,但是當如果以后都沒有發生hash沖突產生,那么就不會進行擴容了,減少了一次無用擴容,也減少了記憶體的使用,
先擴容后插入代碼邏輯如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
//這里當錢陣列如果大于等于12(假如)閾值的話,并且當前的陣列的Entry陣列還不能為空的時候就擴容
if ((size >= threshold) && (null != table[bucketIndex])) {
//擴容陣列,比較耗時
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
//把新加的放在原先在的前面,原先的是e,現在的是new,next指向e
table[bucketIndex] = new Entry<>(hash, key, value, e);//假設現在是new
size++;
}
六、尾聲
HashMap底層特性全決議,完成了,
天天打碼,天天進步!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/340739.html
標籤:java