您好,我是碼農飛哥,感謝您閱讀本文,歡迎一鍵三連哦,
本文是爬蟲專欄的第三篇,重點介紹網頁決議神器XPath,
干貨滿滿,建議收藏,需要用到時常看看, 小伙伴們如有問題及需要,歡迎踴躍留言哦~ ~ ~,
前言(為什么寫這篇文章)
前面兩篇文章我們分別介紹了爬蟲程式的標準步驟,以及如何熟練的使用Requests庫拉取網頁資料,這一篇文章就重點介紹決議網頁資料利器XPath,由于其比較重要,接下來我會用兩篇文章進行介紹,
文章目錄
- 前言(為什么寫這篇文章)
- XPath介紹
- XPath開發工具
- XML檔案介紹
- HTML檔案(網頁)
- XML和HTML的區別
- XML檔案示例
- HTML的示例
- HTML元素的關系
- 父節點(Parent)
- 子節點(Children)
- 同胞(Sibling)
- 先輩(Ancestor)
- 后代(Descendant)
- 選取節點
- 實體
- 謂語
- 通配符
- 舉例
- 選取若干路徑
- XPath的運算子
- 總結
- 粉絲專屬福利
XPath介紹
XPath(XML Path Language)是一門XML檔案中查找資訊的語言,XPath可用來在XML(包括HTML)檔案中對元素和屬性進行查找以及遍歷,后面會詳細介紹XML和HTML檔案的結構組成
XPath開發工具
既然XPath是用來決議網頁的資料,就必須要能夠通過一定的規則匹配到所需要爬取的資料,這里就要用到XPath的開發工具,
-
Chrome插件 XPath Helper 密碼: 166h
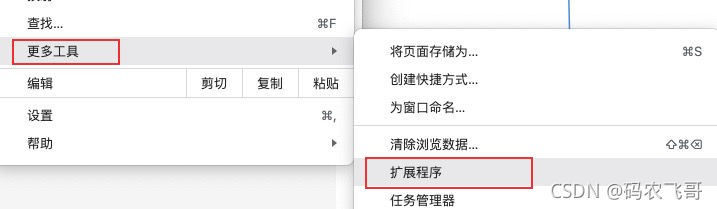
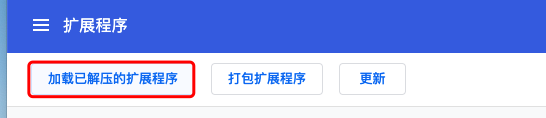
下載好之后:設定---> 更多工具--->擴展程式--->加載已解壓的擴展程式
-
Firefox插件 XPath Checker
XML檔案介紹
在正式介紹XPath之前還是讓我們來重新認識一個XML檔案,XML是一種可擴展的標記語言(Extensible Markup Language)
它主要用來來傳輸資料,它的標簽需要我們自行定義,
HTML檔案(網頁)
HTML檔案也就是我們前面反復提到的網頁,它是一種超文本標記語言,主要用來在瀏覽器上展示資料以及構建頁面樣式,它本質上跟XML類似,也是通過各種標簽包裝資料,不過它的標簽不是我們自行定義的,
XML和HTML的區別
| 資料格式 | 描述 | 設計目的 |
|---|---|---|
| XML | Extensible Markup Language(可擴展標記語言) | 用于傳輸資料,重點是資料的內容 |
| HTML | HyperText Markup Language (超文本標記語言) | 用于顯示資料和頁面樣式 |
| HTML DOM | Document Object Model for HTML (檔案物件模型) | 通過HTML DOM,可以訪問所有HTML元素,連同它們所包含的文本和屬性,可以對其中的內容進行修改和洗掉,同時也可以創建新的元素 |
XML檔案示例
<?xml version="1.0" encoding="UTF-8"?>
<responseXML>
<!--注釋-->
<Detail>
<CardNo>11111</CardNo>
<CardPwd lang="en">2222</CardPwd>
</Detail>
</responseXML>
其中:
<?xml version="1.0" encoding="UTF-8"?> 命名空間節點
<responseXML> 檔案節點即根節點
<CardNo>1111</CardNo>是元素節點,元素節點直接包含資料,沒有子節點,
lang="en" 表示屬性節點,
從上面的示例就可以清晰的看出XML檔案就是由一個個節點組成,在XPath中,有七種型別的節點(Node),分別是元素、屬性、文本、命名空間、處理指令、注釋以及檔案(根)節點,最外面的節點被稱為檔案節點或根節點,
HTML的示例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>HTML示例</title>
</head>
<body>
<div id="content_views" class="htmledit_views">
<p style="text-align:center;"><strong>全網ID名:<b>碼農飛哥</b></strong></p>
<p style="text-align:right;"><strong>掃碼加入技術交流群!</strong></span></p>
<p style="text-align:right;"><img src="https://img-blog.csdnimg.cn/5df64755954146a69087352b41640653.png"/></p>
<div style="text-align:left;"></div>
</div>
</body>
</html>
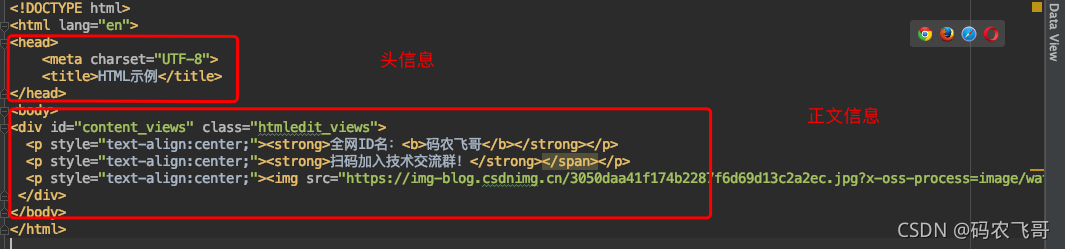
一個標準的HTML主要包括Head元素以及Body元素,head元素內主要包括標題<title> 等資訊,body 元素內主要就頁面的主內容了,用DOM樹表示上面的HTML的結構就如下圖所示,
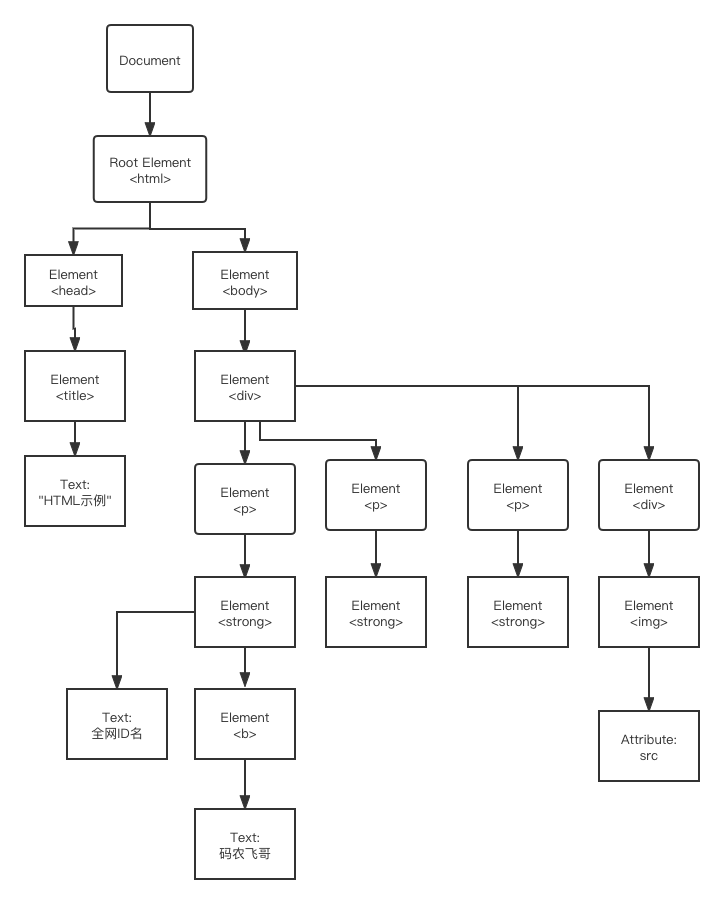
HTML元素的關系
如上圖所示,我們可以整理出HTML元素的關系,
父節點(Parent)
除了根節點之外,每個元素都有一個父節點,就像每個孩子都有一個父親一個意思,
子節點(Children)
一個元素可以有零個,一個或者多個子節點,就像每個父親都可能有零個,一個或者多個孩子
同胞(Sibling)
擁有相同的父節點的元素,就是擁有相同父親的兄弟
先輩(Ancestor)
某個節點的父節點的父節點,就是祖父級別,就是爺爺輩
后代(Descendant)
某個節點的子,子的子,等等,就是孫子輩
選取節點
XPath使用路徑運算式在XML檔案(HTML檔案)中選取節點,節點通過沿著路徑或者跳躍(step)選取,下面就羅列比較常用的路徑運算式,下面的示例還是以前面提到的HTML為例,這里將代碼放在了一個XPath.html檔案中,然后訪問該檔案,
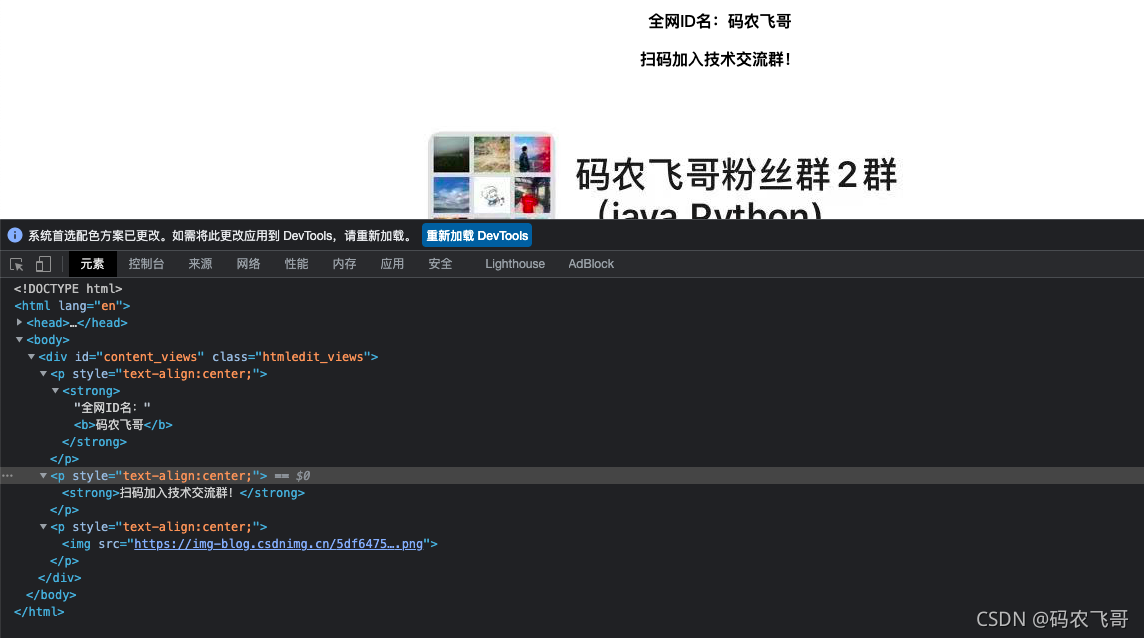
| 運算式 | 描述 |
|---|---|
| nodename | 選取此節點的所有子節點, |
| / | 從根節點選取 |
| // | 從匹配選擇的當前節點選擇檔案中的節點,而不考慮它們的位置 |
| . | 選取當前節點 |
| … | 選取當前節點的父節點 |
| @ | 選取屬性 |
實體
/html獲取根節點下的 html 節點
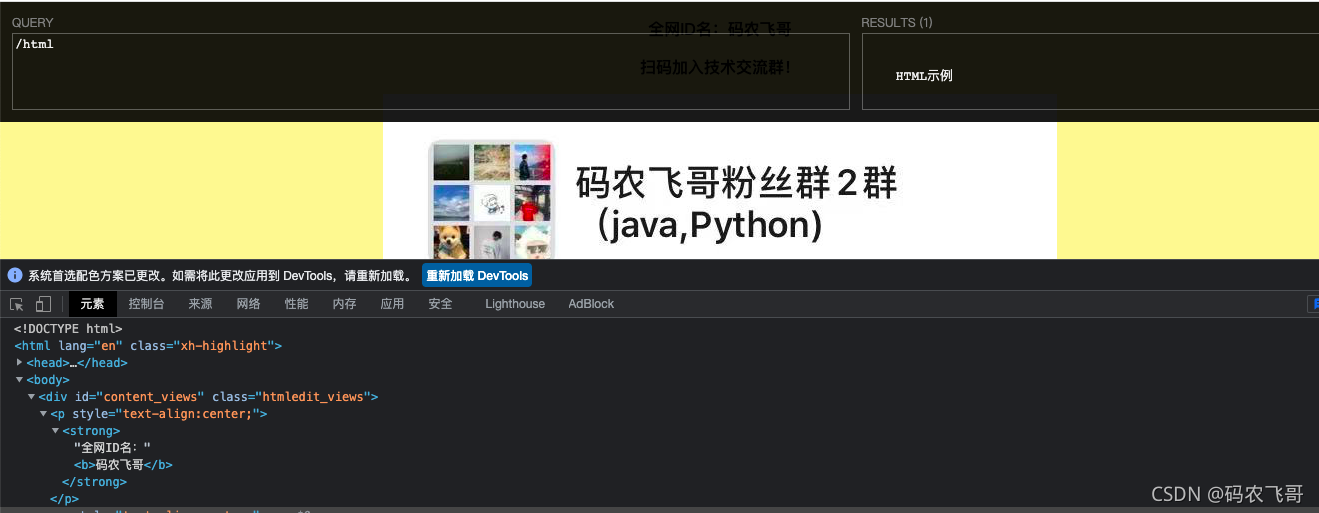
//div匹配所有的div標簽以及其子節點,而不管它們在檔案中的位置,
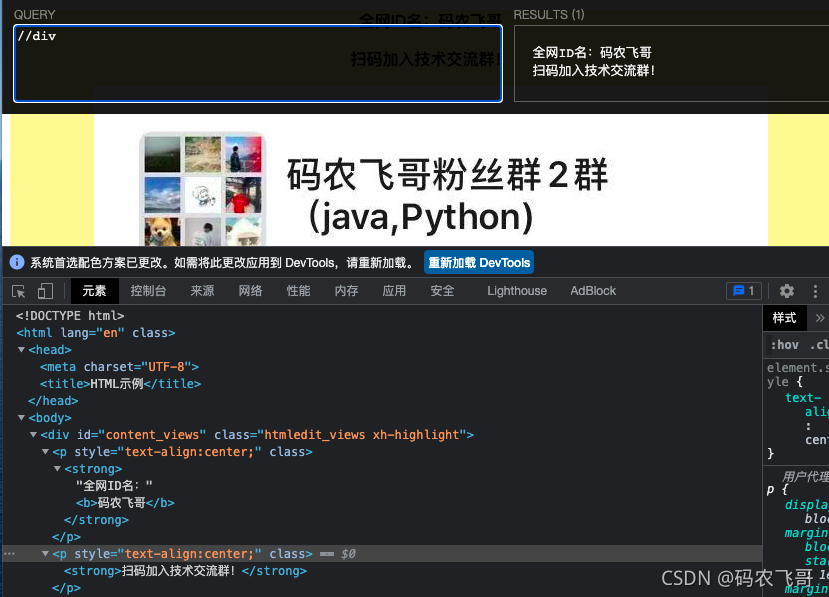
//div/p/strong/.匹配strong 當前這個元素
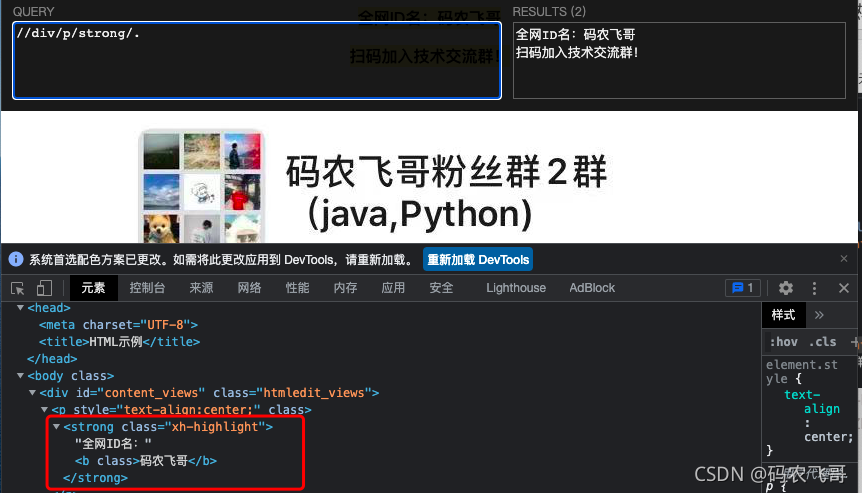
//div/p/strong/..匹配div元素下的p元素的strong元素的父節點
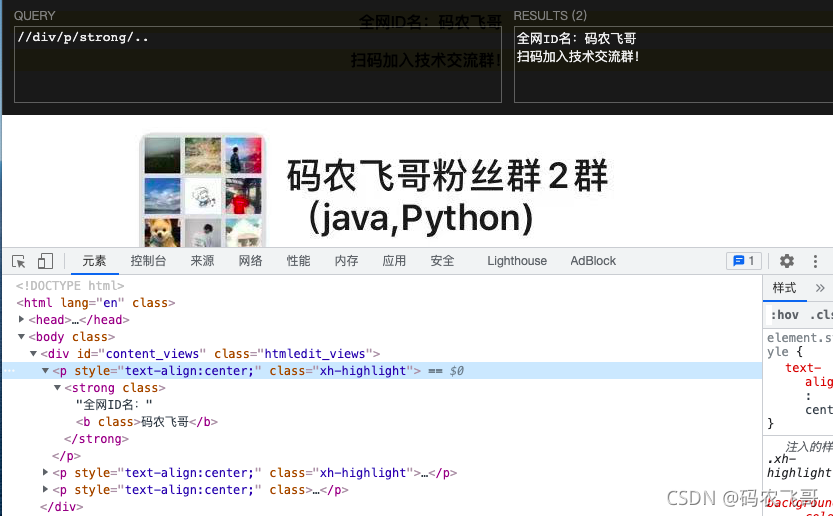
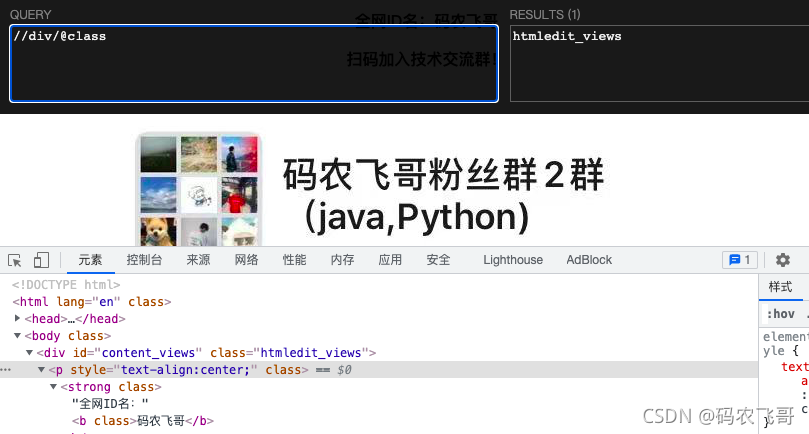
//div/@class匹配div節點下名為class屬性,
謂語
謂語用來查找某個特定的節點或者包含某個指定值的節點,被嵌在方括號中,
| 路徑運算式 | 結果 |
|---|---|
| //div/p[1] | 選取屬于div子元素的第一個p元素 |
| //div/p[last()] | 選取屬于div子元素的最后一個p元素 |
| //div/p[last()-1] | 選取屬于div子元素的倒數第二個p元素 |
| //div/p[position()??] | 選取最前面的兩個屬于div元素的子元素的p元素 |
| //b[@class] | 選取擁有class屬性的b元素 |
| //p[@style=“text-align:right;”] | 選取包含屬性style="text-align:right;"的p元素 |
通配符
XPath 通配符可用來獲取未知的XML元素(包括HTML元素)
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素節點 |
| @* | 匹配任何屬性節點 |
| node() | 匹配任何型別的節點, |
舉例
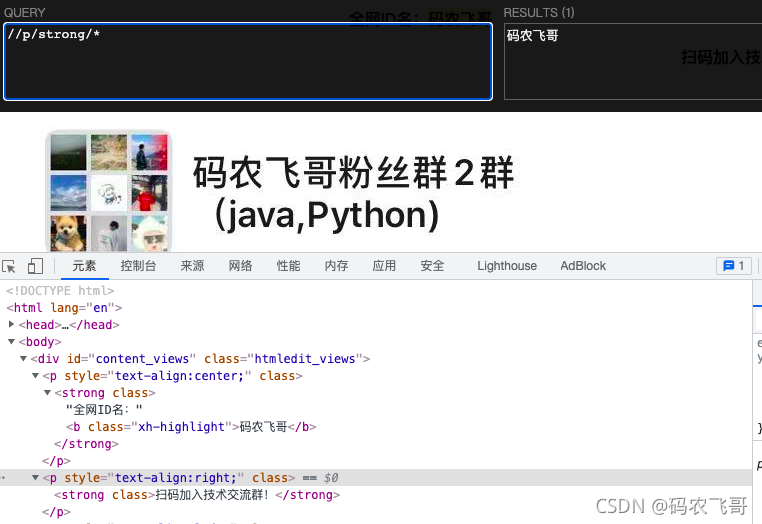
//p/strong/*選取屬于p元素的子元素strong元素的所有子元素,不包括strong元素本身,
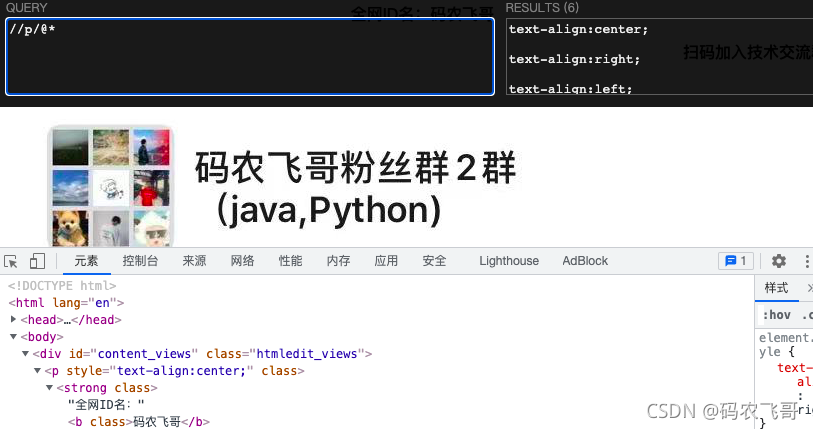
//p/@*選取屬于p元素的所有屬性,
選取若干路徑
通過在路徑運算式中使用“|”運算子,您可以選取若干個路徑,
| 路徑運算式 | 結果 |
|---|---|
//div/p|//div/div | 選取div元素的所有p和div元素 |
//p | //strong | 選取檔案中所有的p元素和strong元素 |
XPath的運算子
下面列出了可用在 XPath 運算式中的運算子:
| 運算子 | 描述 | 實體 | 結果 |
|---|---|---|---|
| | 計算兩個節點集 | //p | //strong |
+ | 加法 | 6+4 | 10 |
- | 減法 | 5-2 | 3 |
* | 乘法 | 10*10 | 100 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | style=“text-align:right;” | 匹配屬性等于text-align:right;的style屬性 |
| < | 小于 | ||
| < = | 小于等于 | ||
| > | 大于 | ||
| > = | 大于等于 | ||
| or | 或 | ||
| and | 與 | ||
| mod | 計算除法的余數 | 5 mod 2 | 1 |
總結
本文詳細介紹了XPath的語法內容,在運用到Python抓取時要先轉換為xml,
粉絲專屬福利
軟考資料:實用軟考資料
面試題:5G 的Java高頻面試題
學習資料:50G的各類學習資料
脫單秘籍:回復【脫單】
并發編程:回復【并發編程】
👇🏻 驗證碼 可通過搜索下方 公眾號 獲取👇🏻
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/340766.html
標籤:python
上一篇:為什么有人1個月就學會Python,而有人兩三個月還入不了門?很大原因是這些
下一篇:【18】資料可視化+爬蟲:基于 Echarts + Python 實作的動態實時大屏范例 - 行業搜索指數排行榜