深度學習和 Python 開始
摘要
使用 Keras 訓練您的第一個簡單神經網路不需要很多代碼,但我們將開始緩慢,一步一步地進行,確保您了解如何在自己的自定義資料集中培訓網路的程序,
我們今天將涵蓋的步驟包括:
- 安裝 Keras 和其他對系統的依賴
- 從磁盤中加載資料
- 創建您的訓練和測驗拆分
- 定義您的 Keras 模型架構
- 編譯您的 Keras 模型
- 根據培訓資料培訓模型
- 根據測驗資料評估您的模型
- 使用訓練有素的 Keras 模型進行預測
我還包括一個額外的部分,培訓你的第一個凸起神經網路,
這似乎是很多步驟,但我向你保證,一旦我們開始進入示例,你會看到,示例是線性的,使直觀的意義,并會幫助您了解與Keras訓練神經網路的基本原理,
資料集
資料集選用了貓狗大戰的部分資料集,貓狗個選2000張,Pandas類別是我從網上搜索的,一百多張,如下圖:

此資料集的目的是將影像正確分類為包含:
- 貓
- 狗
- 熊貓
專案結構
.
├── data
│ ├── cats
│ ├── dogs
│ └── panda
├── images
│ ├── cat.jpg
│ ├── dog.jpg
│ └── panda.jpg
├── output
│ ├── simple_nn.model
│ ├── simple_nn_lb.pickle
│ ├── simple_nn_plot.png
│ ├── smallvggnet.model
│ ├── smallvggnet_lb.pickle
│ └── smallvggnet_plot.png
├── models
│ ├── __init__.py
│ └── smallvggnet.py
├── predict.py
├── train_simple_nn.py
└── train_vgg.py
從磁盤中加載資料
**圖4:**將影像從磁盤加載到記憶體中,
現在,Keras 安裝在我們的系統上,我們可以開始使用 Keras 實施我們的第一個簡單的神經網路訓練腳本,我們稍后將實施一個成熟的共周神經網路,但讓我們從輕松開始,并努力向上,
train_simple_nn.py
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
import os
2-19行匯入我們所需的包裹,
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset of images")
ap.add_argument("-m", "--model", required=True,
help="path to output trained model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", required=True,
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
當我們執行我們的腳本時,我們的腳本將動態處理通過命令列提供的附加資訊, 附加資訊采用命令列引數的形式, 該模塊內置于 Python 中,將處理決議您在命令字串中提供的資訊,
我們有四個命令線引數要決議:
-
–dataset:通往磁盤上影像資料集的路徑,
-
-model: 我們的模型將序列化,輸出到磁盤,此引數包含輸出模型檔案的路徑,
-
–label-bin: 資料集標簽被序列化為磁盤,以便于在其他腳本中回憶,這是通往輸出標簽二元化器檔案的路徑,
-
–plot:輸出訓練圖影像檔案的路徑,我們將審查此圖,以檢查我們的資料是否過度/不足,
# initialize the data and labels
print("[INFO] loading images...")
data = []
labels = []
# grab the image paths and randomly shuffle them
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# loop over the input images
for imagePath in imagePaths:
# load the image, resize the image to be 32x32 pixels (ignoring
# aspect ratio), flatten the image into 32x32x3=3072 pixel image
# into a list, and store the image in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (32, 32)).flatten()
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
將資料排序,然后打亂這些序列,
回圈讀讀取圖片,將圖片resize為(32×32)的圖片,然后展平成一列資料,然后將資料放到data里面,將label放到labels里面,
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
對資料做歸一化,
切分訓練集和測驗集
**Figure 5:**在訓練深度學習或機器學習模型之前,您必須將資料拆分為訓練集和測驗集, 這篇博文中使用了 Scikit-learn 來分割我們的資料,
現在我們已經從磁盤加載了我們的影像資料,接下來我們需要構建我們的訓練和測驗分割:
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.25, random_state=42)
按照4:1的比例將資料切分為訓練集和測驗集,
# convert the labels from integers to vectors (for 2-class, binary
# classification you should use Keras' to_categorical function
# instead as the scikit-learn's LabelBinarizer will not return a
# vector)
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
將標簽做二值化操作
1, 0, 0# 對應貓
0, 1, 0# 對應狗
0, 0, 1# 對應熊貓
請注意,只有一個陣列元素是"hot"的,這就是為什么我們稱之為"one-hot"編碼,
定義您的 Keras 模型架構
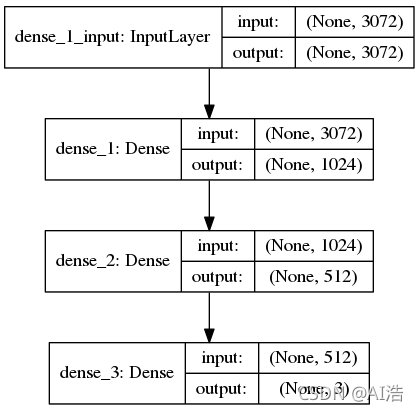
**圖6:**我們簡單的神經網路是使用Keras在這個深度學習教程創建的,
下一步是使用 Keras 定義我們的神經網路架構,在這里,我們將使用一個網路,其中一個輸入層、兩個隱藏層和一個輸出層:
# define the 3072-1024-512-3 architecture using Keras
model = Sequential()
model.add(Dense(1024, input_shape=(3072,), activation="sigmoid"))
model.add(Dense(512, activation="sigmoid"))
model.add(Dense(len(lb.classes_), activation="softmax"))
由于我們的模型非常簡單,我們繼續在此腳本中定義它(通常我喜歡在單獨的檔案中為模型架構創建一個單獨的類),
第一個隱藏層將有節點,input_shape是3072(32x32x3=3072)輸出:1024,
第二個隱藏層將有節點輸入就是上一個節點的輸出所以是1024,輸出是512
最后,最終輸出層(第 78 行)中的節點數將是可能的類標簽的數量——在這種情況下,輸出層將有三個節點,一個用于我們的每個類標簽(“貓”、“狗” ”和“熊貓”),
編譯你的 Keras 模型
上一步我們定義了我們的神經網路架構,下一步是"compile"它:
# initialize our initial learning rate and # of epochs to train for
INIT_LR = 0.01
EPOCHS = 80
# compile the model using SGD as our optimizer and categorical
# cross-entropy loss (you'll want to use binary_crossentropy
# for 2-class classification)
print("[INFO] training network...")
opt = SGD(lr=INIT_LR)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
學習率在優化器中設定,優化器使用SGD,
分類交叉熵被用作幾乎所有訓練進行分類的網路的損失,唯一的例外是2類分類,其中只有兩個可能的類標簽,在這種情況下,你會想交換"categorical_crossentropy"為"binary_crossentropy",
訓練

**圖8:**訓練資料和匯編模型培訓深度學習模型,
現在,我們的 Keras 模型已編譯,我們可以在我們的培訓資料上"擬合"(即訓練)它:
# train the neural network
H = model.fit(x=trainX, y=trainY, validation_data=(testX, testY),
epochs=EPOCHS, batch_size=32)
batch_size:控制通過網路傳遞的每組資料的大小,較大的 GPU 將能夠容納更大的批次大小,我建議從32或64(實際大小需要考慮顯存的大小)
評估您的Keras模型
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-jOd6McZD-1635420207841)(https://pyimagesearch.com/wp-content/uploads/2018/09/keras_tutorial_step7.png)]
**圖9:**在符合我們的模型后,我們可以使用我們的測驗資料進行預測并生成分類報告,
我們已經培訓了我們的實際模型,但現在我們需要根據我們的測驗資料來評估它,
重要的是,我們評估我們的測驗資料,以便我們可以獲得一個公正的(或盡可能接近公正)的表示,我們的模型如何表現良好的資料,它從來沒有受過培訓,
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
# plot the training loss and accuracy
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy (Simple NN)")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["plot"])
運行此腳本時,您會注意到我們的 Keras 神經網路將開始訓練,一旦培訓完成,我們將評估測驗集上的網路:
$ python train_simple_nn.py --dataset animals --model output/simple_nn.model \
--label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
Using TensorFlow backend.
[INFO] loading images...
[INFO] training network...
Train on 2250 samples, validate on 750 samples
Epoch 1/80
2250/2250 [==============================] - 1s 311us/sample - loss: 1.1041 - accuracy: 0.3516 - val_loss: 1.1578 - val_accuracy: 0.3707
Epoch 2/80
2250/2250 [==============================] - 0s 183us/sample - loss: 1.0877 - accuracy: 0.3738 - val_loss: 1.0766 - val_accuracy: 0.3813
Epoch 3/80
2250/2250 [==============================] - 0s 181us/sample - loss: 1.0707 - accuracy: 0.4240 - val_loss: 1.0693 - val_accuracy: 0.3533
...
Epoch 78/80
2250/2250 [==============================] - 0s 184us/sample - loss: 0.7688 - accuracy: 0.6160 - val_loss: 0.8696 - val_accuracy: 0.5880
Epoch 79/80
2250/2250 [==============================] - 0s 181us/sample - loss: 0.7675 - accuracy: 0.6200 - val_loss: 1.0294 - val_accuracy: 0.5107
Epoch 80/80
2250/2250 [==============================] - 0s 181us/sample - loss: 0.7687 - accuracy: 0.6164 - val_loss: 0.8361 - val_accuracy: 0.6120
[INFO] evaluating network...
precision recall f1-score support
cats 0.57 0.59 0.58 236
dogs 0.55 0.31 0.39 236
panda 0.66 0.89 0.76 278
accuracy 0.61 750
macro avg 0.59 0.60 0.58 750
weighted avg 0.60 0.61 0.59 750
此網路很小,當與小資料集結合時,我的 CPU 上每個epoch只需 2 秒,
在這里你可以看到,我們的網路正在獲得60%的準確性,
由于我們隨機挑選給定影像的正確標簽的幾率為 1/3,我們知道我們的網路實際上已經學會了可用于區分三個類別的模式,
我們還保存了我們的情節:
- 訓練損失
- 驗證損失
- 訓練精度
- 驗證精度
…確保我們能夠輕松地發現我們的結果中過度擬合或不合適,
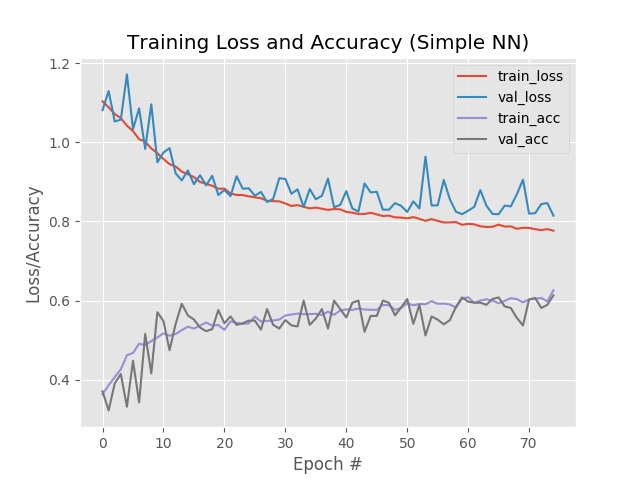
**圖10:**我們簡單的神經網路訓練腳本(與Keras一起創建)生成精確/丟失情節,以幫助我們發現不足/過度擬合,
看看我們的情節,我們看到少量的過度適合開始發生超過epoch+45,我們的訓練和驗證損失開始分歧,并出現了明顯的差距,
最后,我們可以將模型保存到磁盤中,以便以后可以重復使用,而無需重新訓練它:
# save the model and label binarizer to disk
print("[INFO] serializing network and label binarizer...")
model.save(args["model"], save_format="h5")
f = open(args["label_bin"], "wb")
f.write(pickle.dumps(lb))
f.close()
使用 Keras 模型對新資料進行預測
在這一點上, 我們的模型是訓練有素的, 但如果我們想在我們的網路已經培訓后對影像做出預測呢?
那我們該怎么辦?
我們如何從磁盤中加載模型?
我們如何加載影像,然后對影像進行預處理以進行分類?
在predict.py 腳本中,我將向您展示如何操作,因此打開它并插入以下代碼:
# import the necessary packages
from tensorflow.keras.models import load_model
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image we are going to classify")
ap.add_argument("-m", "--model", required=True,
help="path to trained Keras model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to label binarizer")
ap.add_argument("-w", "--width", type=int, default=28,
help="target spatial dimension width")
ap.add_argument("-e", "--height", type=int, default=28,
help="target spatial dimension height")
ap.add_argument("-f", "--flatten", type=int, default=-1,
help="whether or not we should flatten the image")
args = vars(ap.parse_args())
首先,我們將匯入所需的包和模塊, 每當您撰寫腳本以從磁盤加載 Keras 模型時,您都需要顯式匯入 from, OpenCV 將用于注釋和顯示,該模塊將用于加載我們的標簽 binarizer.load_modeltensorflow.keras.modelspickle 接下來,讓我們決議我們的命令列引數:
–image :我們輸入影像的路徑,
–model :我們經過訓練和序列化的 Keras 模型路徑,
–label-bin :序列化標簽二值化器的路徑,
–width :我們的 CNN 輸入形狀的寬度,本次設定為32,
–height :輸入到 CNN 的影像的高度,本次設定為32,
–flatten :我們是否應該展平影像,默認情況下,我們不會展平影像,如果您需要展平影像,將其設定為1,
接下來,讓我們根據命令列引數加載影像并調整其大小:
# load the input image and resize it to the target spatial dimensions
image = cv2.imread(args["image"])
output = image.copy()
image = cv2.resize(image, (args["width"], args["height"]))
# scale the pixel values to [0, 1]
image = image.astype("float") / 255.0
# check to see if we should flatten the image and add a batch
# dimension
if args["flatten"] > 0:
image = image.flatten()
image = image.reshape((1, image.shape[0]))
# otherwise, we must be working with a CNN -- don't flatten the
# image, simply add the batch dimension
else:
image = image.reshape((1, image.shape[0], image.shape[1],
image.shape[2]))
將影像展平,
# load the model and label binarizer
print("[INFO] loading network and label binarizer...")
model = load_model(args["model"])
lb = pickle.loads(open(args["label_bin"], "rb").read())
# make a prediction on the image
preds = model.predict(image)
# find the class label index with the largest corresponding
# probability
i = preds.argmax(axis=1)[0]
label = lb.classes_[i]
加載模型然后預測模型
- 貓: 54.6%
- 狗: 45.4%
- 熊貓: +0%
換句話說,我們的網路"認為"它看到*“貓”,它肯定"知道"它沒有看到"熊貓",*
找到最大值的索引(第 0 個"貓"指數),
標簽二進制器中提取‘“貓”字串標簽,
很簡單, 對吧?
現在,讓我們顯示結果:
# draw the class label + probability on the output image
text = "{}: {:.2f}%".format(label, preds[0][i] * 100)
cv2.putText(output, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7,
(0, 0, 255), 2)
# show the output image
cv2.imshow("Image", output)
cv2.waitKey(0)

**圖11:**在我們的 Keras 教程中,貓被正確地分類為一個簡單的神經網路,
在這里你可以看到,我們簡單的Keras神經網路已經分類輸入影像為"貓"55.87%的概率,盡管貓的臉被一塊面包部分遮蓋,
搭建CNN網路
無可否認,使用標準的饋入神經網路對影像進行分類并不是一個明智的選擇,
相反,我們應該利用卷積神經網路 (CNN),該網路旨在對影像的原始像素強度進行操作,并學習可用于高精度對影像進行分類的歧視性濾鏡,
我們今天在這里討論的模型是Vggnet的較小變體, 我稱之為 “小 Vggnet” ,
VGGNet 樣型號具有兩個共同特征:
- 只使用 3×3 卷積核
- 在應用池操作之前,在網路架構中,相互疊加在一起
現在,讓我們繼續實施小型VGGNet,
打開
smallvggnet.py
檔案并插入以下代碼:
# import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras import backend as K
匯入需要的包,
class SmallVGGNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
創建SmallVGGNet類,在類中增加build方法,
build需要四個引數,分別是寬,高,深度和類別,
# CONV => RELU => POOL layer set
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
第一個卷積層,經過池化后,尺寸減少一半,
# (CONV => RELU) * 2 => POOL layer set
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
第二個卷積層,經過池化后,尺寸減少一半,
# (CONV => RELU) * 3 => POOL layer set
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
第三個卷積層,經過池化后,尺寸減少一半,
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
展平,然后輸入全連接層,到這里模型就完成了,下面開始撰寫train代碼:
train_vgg.py
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.smallvggnet import SmallVGGNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
import os
匯入需要的包,
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset of images")
ap.add_argument("-m", "--model", required=True,
help="path to output trained model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", required=True,
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
我們有四個命令線引數要決議:
-
–dataset集
:通往磁盤上影像資料集的路徑,
-
–model: 我們的模型將序列化,輸出到磁盤,此引數包含輸出模型檔案的路徑,請務必相應地命名您的模型,以便您不會覆寫任何以前訓練過的模型(如簡單的神經網路模型),
-
–label-bin: 資料集標簽被序列化為磁盤,以便于在其他腳本中回憶,這是通往輸出標簽二元化器檔案的路徑,
-
-plot:輸出訓練圖影像檔案的路徑,我們將審查此圖,以檢查我們的資料是否過度/不足,
每次訓練模型時,應更改引數,應在命令列中指定不同的圖段檔案名,以便您擁有與筆記本或筆記檔案中的訓練筆記對應的圖集歷史記錄,這個教程使深度學習看起來很容易,但請記住,我經歷了幾次迭代的訓練之前,我確定了所有引數與您分享這個腳本,
讓我們加載并預處理我們的資料:
# initialize the data and labels
print("[INFO] loading images...")
data = []
labels = []
# grab the image paths and randomly shuffle them
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# loop over the input images
for imagePath in imagePaths:
# load the image, resize it to 64x64 pixels (the required input
# spatial dimensions of SmallVGGNet), and store the image in the
# data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (64, 64))
data.append(image)
# extract the class label from the image path and update the
# labels list
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
和前面的類似,這里resize大小是64×64,下一步是切分資料集,
# partition the data into training and testing splits using 75% of
# the data for training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.25, random_state=42)
# convert the labels from integers to vectors (for 2-class, binary
# classification you should use Keras' to_categorical function
# instead as the scikit-learn's LabelBinarizer will not return a
# vector)
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
按照4:1拆分訓練集和測驗集,然后二值化,
# construct the image generator for data augmentation
aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,
height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode="nearest")
# initialize our VGG-like Convolutional Neural Network
model = SmallVGGNet.build(width=64, height=64, depth=3,
classes=len(lb.classes_))
初始化影像資料生成器以執行影像增強,
影像增強允許我們通過隨機旋轉、移動、剪切、縮放和翻轉,從現有培訓資料中構建"附加"培訓資料,
資料增強通常是關鍵步驟,作用:
- 避免過度擬合
- 確保您的模型概括良好
我建議您始終執行資料增強,除非您有明確的理由不執行,
# initialize our initial learning rate, # of epochs to train for,
# and batch size
INIT_LR = 0.01
EPOCHS = 75
BS = 32
# initialize the model and optimizer (you'll want to use
# binary_crossentropy for 2-class classification)
print("[INFO] training network...")
opt = SGD(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
H = model.fit(x=aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS)
首先,我們確定我們的學習率、EPOCHS和批次大小,
然后,我們初始化我們的隨機梯度下降 (SGD) 優化器 ,
最后,我們將評估我們的模型,繪制損失/精度曲線,并保存模型:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
# plot the training loss and accuracy
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy (SmallVGGNet)")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["plot"])
# save the model and label binarizer to disk
print("[INFO] serializing network and label binarizer...")
model.save(args["model"], save_format="h5")
f = open(args["label_bin"], "wb")
f.write(pickle.dumps(lb))
f.close()
我們對測驗集進行預測,然后使用科學學習來計算和列印我們的
$ python train_vgg.py --dataset animals --model output/smallvggnet.model \
--label-bin output/smallvggnet_lb.pickle \
--plot output/smallvggnet_plot.png
Using TensorFlow backend.
[INFO] loading images...
[INFO] training network...
Train for 70 steps, validate on 750 samples
Epoch 1/75
70/70 [==============================] - 13s 179ms/step - loss: 1.4178 - accuracy: 0.5081 - val_loss: 1.7470 - val_accuracy: 0.3147
Epoch 2/75
70/70 [==============================] - 12s 166ms/step - loss: 0.9799 - accuracy: 0.6001 - val_loss: 1.6043 - val_accuracy: 0.3253
Epoch 3/75
70/70 [==============================] - 12s 166ms/step - loss: 0.9156 - accuracy: 0.5920 - val_loss: 1.7941 - val_accuracy: 0.3320
...
Epoch 73/75
70/70 [==============================] - 12s 166ms/step - loss: 0.3791 - accuracy: 0.8318 - val_loss: 0.6827 - val_accuracy: 0.7453
Epoch 74/75
70/70 [==============================] - 12s 167ms/step - loss: 0.3823 - accuracy: 0.8255 - val_loss: 0.8157 - val_accuracy: 0.7320
Epoch 75/75
70/70 [==============================] - 12s 166ms/step - loss: 0.3693 - accuracy: 0.8408 - val_loss: 0.5902 - val_accuracy: 0.7547
[INFO] evaluating network...
precision recall f1-score support
cats 0.66 0.73 0.69 236
dogs 0.66 0.62 0.64 236
panda 0.93 0.89 0.91 278
accuracy 0.75 750
macro avg 0.75 0.75 0.75 750
weighted avg 0.76 0.75 0.76 750
[INFO] serializing network and label binarizer...
CPU 的訓練需要一些時間 - 75 個時代都需要超過一分鐘的時間,訓練需要一個多小時,
GPU 將在幾分鐘內完成整個程序,因為每個時代只需要 2 秒,如所示!
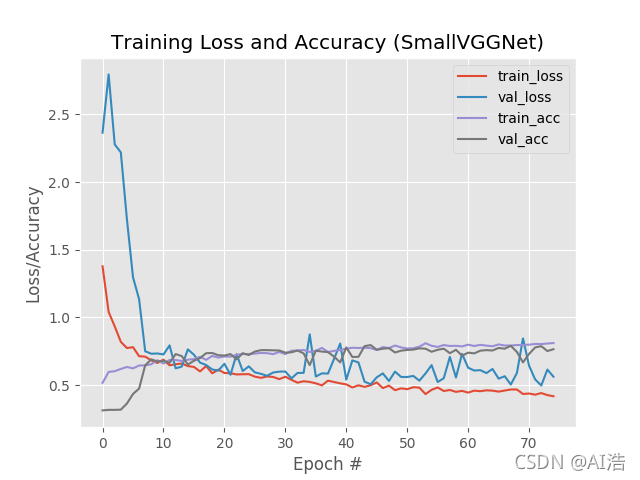
**圖12:**我們對 Keras 準確/損失圖的深入學習表明,我們通過 SmallVGGNet 模型獲得了 76% 的動物資料準確性,
正如我們的結果表明的,你可以看到,我們使用 卷積 神經網路在動物資料集上實作了76% 的準確性,明顯高于之前使用標準全連接網路的 60% 的準確性,
$ python predict.py --image images/panda.jpg --model output/smallvggnet.model \
--label-bin output/smallvggnet_lb.pickle --width 64 --height 64
Using TensorFlow backend.
[INFO] loading network and label binarizer...
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-83GQjkdL-1635420207844)(https://pyimagesearch.com/wp-content/uploads/2018/09/keras_tutorial_smallvggnet_01.jpg)]](https://img.uj5u.com/2021/10/30/2790623009321210.png)
**圖13:**我們通過Keras教程的深入學習,展示了我們如何自信地識別影像中的熊貓,
我們的CNN很有信心,這是一只"熊貓",我也是, 但我只是希望他不要盯著我看!
讓我們試試一只可愛的小獵犬:
$ python predict.py --image images/dog.jpg --model output/smallvggnet.model \
--label-bin output/smallvggnet_lb.pickle --width 64 --height 64
Using TensorFlow backend.
[INFO] loading network and label binarizer...
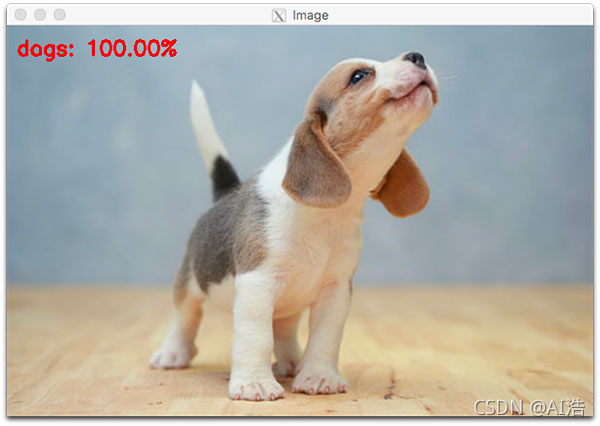
**圖14:**一只小獵犬被確認為使用Keras、TensorFlow和Python的狗,我們的 Keras 教程介紹了深度學習的基礎知識,但剛剛觸及了該領域的表面,
總結
在今天的教程中,您學習了如何從 Keras、深度學習和 Python 開始,
具體來說,您學習了與 Keras 和您自己的自定義資料集合作的七個關鍵步驟:
- 如何從磁盤中加載資料
- 如何創建您的培訓和測驗拆分
- 如何定義您的 Keras 模型架構
- 如何編譯和準備您的Keras模型
- 如何根據您的培訓資料對模型進行培訓
- 如何在測驗資料上評估模型
- 如何使用您訓練有素的 Keras 模型進行預測
從那里,您還學會了如何實作卷積神經網路,使您能夠獲得比標準全連接網路更高的精度,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/341899.html
標籤:python