GroupBy是Pandas提供的強大的資料聚合處理機制,可以對大量級的多維資料進行透視,同時GroupBy還提供強大的apply函式,使得在多維資料中應用復雜函式得到復雜結果成為可能(這也是個人認為在實際業務分析中,資料量沒那么大的情況下,Pandas相較于Excel透視表最有優勢的一點),
也正是因為它如此強大,所以對于很多初涉獵這部分內容的學習者來說,深入理解并熟練掌握GroupBy機制的運用有些困難,這篇文章力求基于我對“老鼠書”的理解,對GroupBy機制做一個初步的梳理,
本文是機制上的理解篇,代碼層面的運用會在運用篇中涉及,
# GroupBy使用的三種基本形式,先看看,結合后面的梳理一起有助于理解 #1 data.groupby([分組鍵1,分組鍵2……]).函式 #2 data.groupby([分組鍵1,分組鍵2……]).agg(引數) #3 data.groupby([分組鍵1,分組鍵2……]).apply(引數)
深入理解GroupBy機制的底層邏輯:“分拆-應用-聚合”
先說結論:(1)“分拆-應用-聚合”是GroupBy機制的核心,其中“應用”又是整個流程的核心;(2)理解“應用”的關鍵在于,腦子里要有對于分拆之后一個個小group的抽象印象,
1、分拆
- 分拆:之所以叫GroupBy,正是因為有“Group”這個概念,我們用到Group,是因為需要按某個屬性(欄位)將資料區分為不同的Group,這個屬性,我們通常稱之為“分組鍵”,對每個Group進行操作(如 求和、求平均),否則直接對整個資料集進行操作就好,干嘛要麻煩到用GroupBy呢?
比如公司到年終要給表現最好的部門發激勵,就需要計算不同部門今年的總收益,這時“部門”就是我們的“分組鍵”,不同的部門及其每個員工的收益就構成了一個個小的group,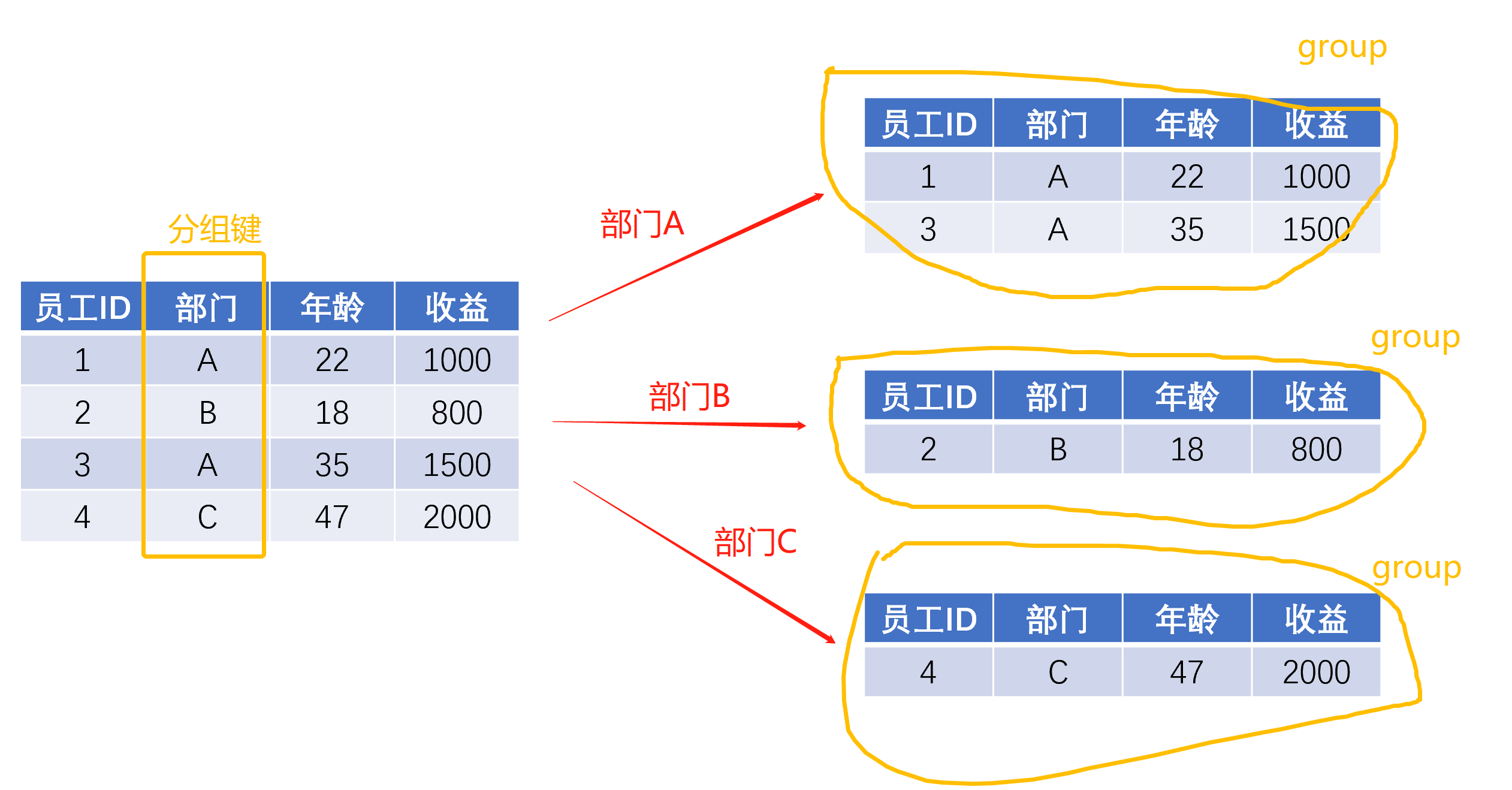
抽象理解的話,代碼中的前半部分,也就是data.groupby([分組鍵1,分組鍵2……]),所起到的作用就是將原資料集data按照你傳入的分組鍵,切分為一個一個小小的group,每一個group都是原資料集的子集,
當看到data.groupby([分組鍵1,分組鍵2……])時,你可以理解為:“分拆”的步驟已經執行好啦,現在我們已經有了一個個小的group(在pandas中,data.groupby([分組鍵1,分組鍵2……])回傳的是一個grouped物件),
2、應用
- 應用:將資料切分為不同的Group并不是最終的目的,我們的目標是針對每個小的group執行一個操作,得到一個結果,這個程序就是"應用",也是整個GroupBy中最復雜、發揮coder聰明才智的空間最大的部分,這里的操作:
- 可以是最簡單的描述性統計和匯總統計,比如 求和、求最大值、求最小值、求平均,得到的結果通常是一個標量值,也就是一個數,
- 還可以加入略復雜的要求,比如 同時回傳每組最大值和最小值,得到的結果可以是一個Series / 串列 / 字典 / DataFrame / 甚至是任意你定義的物件型別了,在“運用篇”中我們會介紹一些看起來頗為復雜的操作,
繼續前面公司年終發獎勵的例子,老板提出了以下要求:(1)看看每個部門的總收益;(2)想看看每個部門的平均年齡和人均收益,
對于總收益,每個部門只回傳一個數字就可以了,但是平均年齡和人均收益,對于每個部門來說,這兩個數字構成的就是一個串列或者一個Series了,很多初學者往往就卡著這個地方,我個人認為還是對groupby的抽象理解不夠,
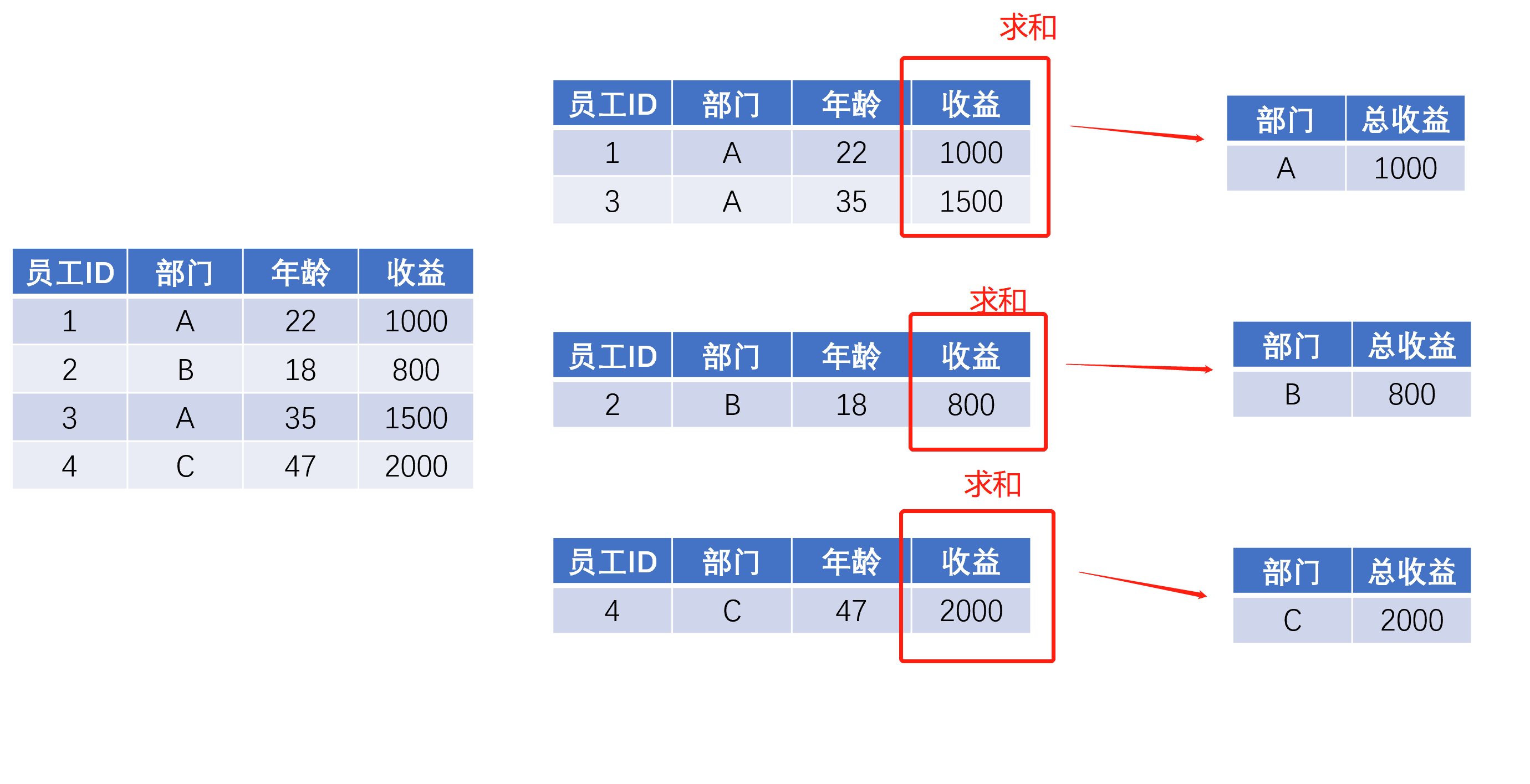
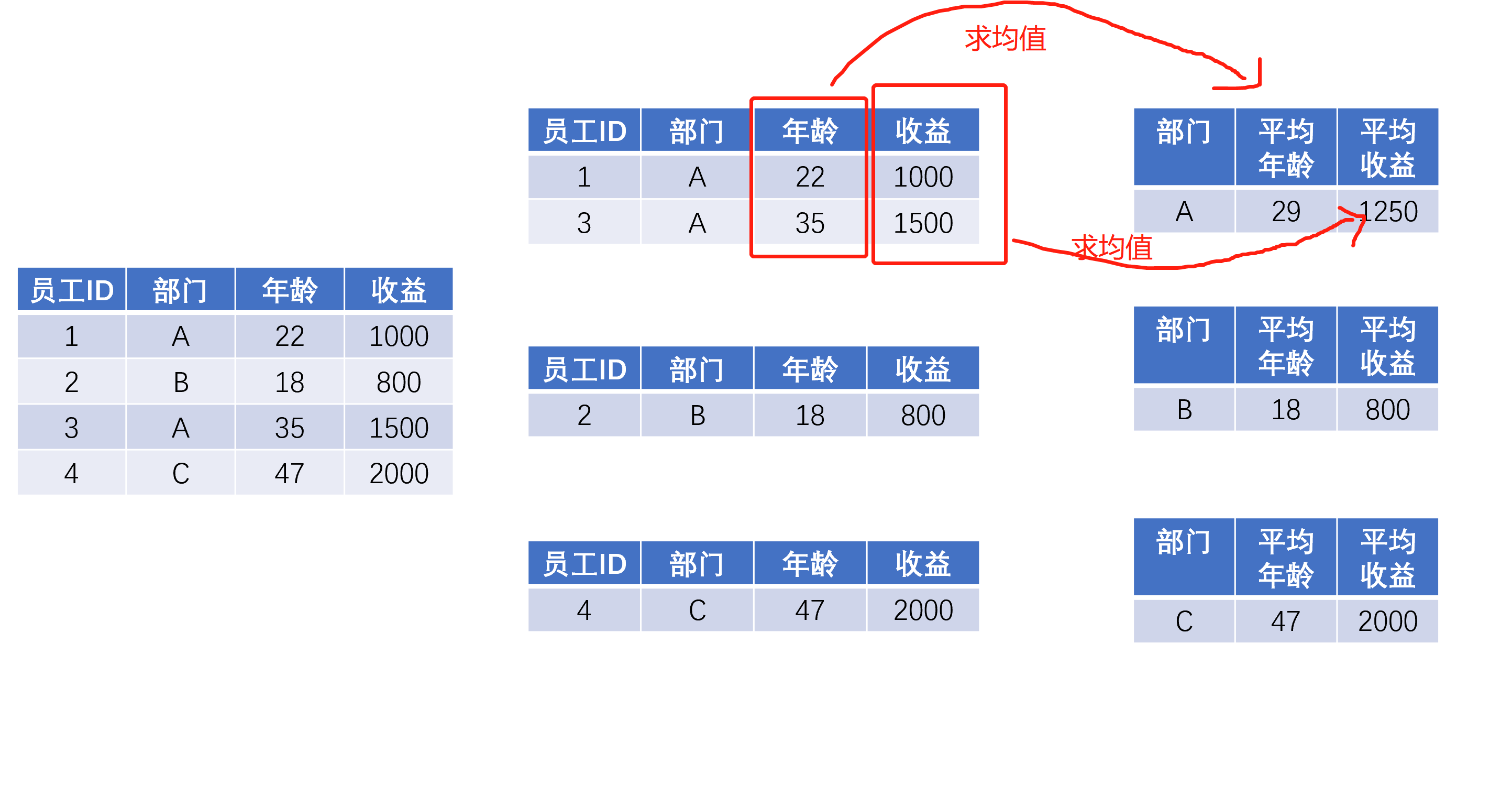
對“應用”操作的理解,如果腦子里有這么一個小group的集合,運用的難度會小很多,同時我們可以發現一些對“分拆”步驟的更深層次理解,能幫助我們更好地掌握“應用”:
- 分拆后的小group的列(columns)和原資料集是一樣的;
- 分拆后的小group的分組鍵對應的列的值都是相等的,比如 第一個小group里面,部門都是A;第二個則部門都是B
- 分拆形成的小group的個數,取決于原資料集中分組鍵對應的列的值去重后的個數,比如 上圖中 原資料集中有4個資料,但是只有A、B、C 3個部門,所以最終拆出來的小group就有3個,
3、聚合
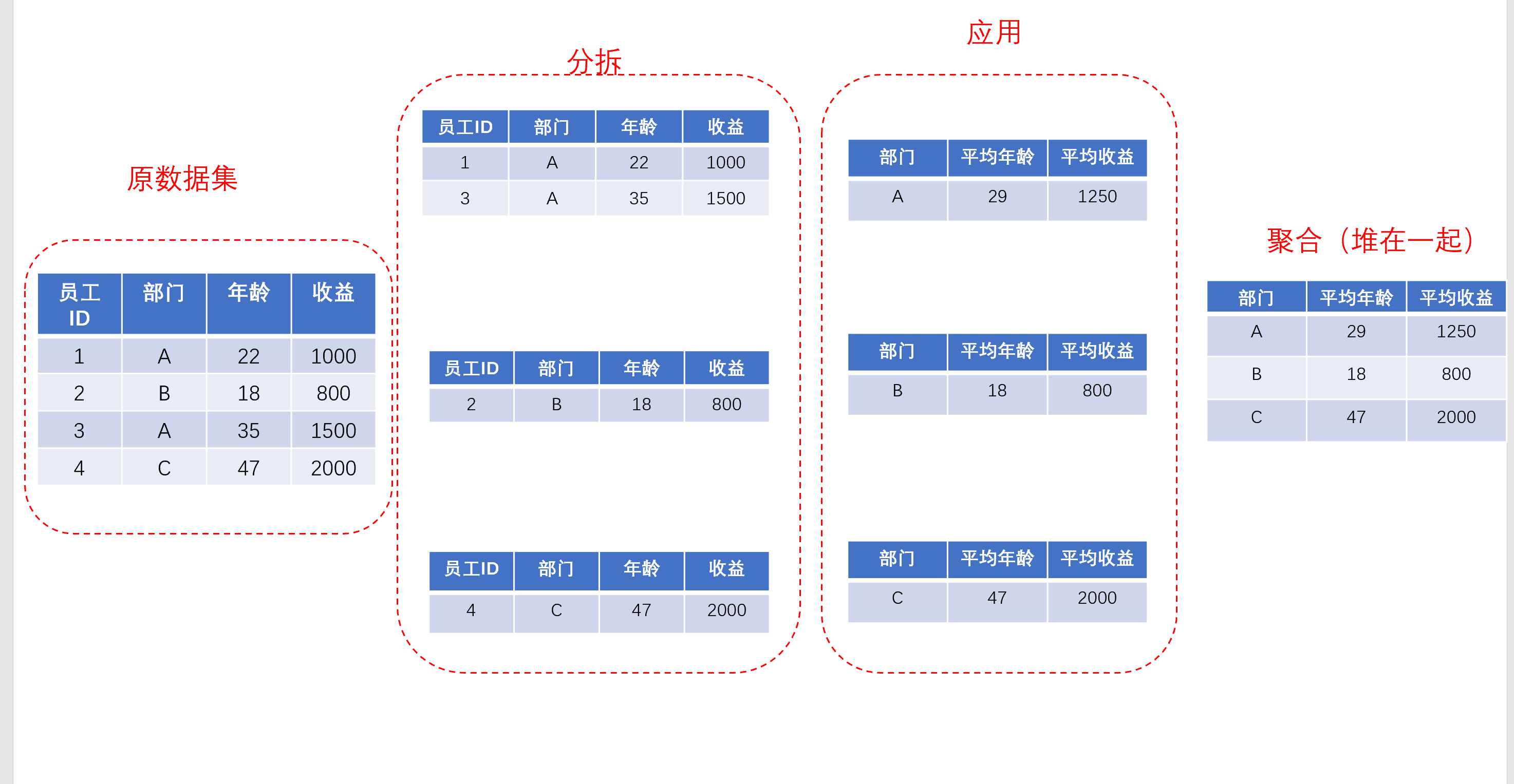
- 聚合:聚合相對來說比較好理解一些了,從前面的圖中我們可以看到,“應用”是對每一個小group執行了一種或簡單或復雜的操作,但是不可能就這么回傳給你,所以需要把這些資料給聚合起來,構成一個可讀性更高的資料形式給你,
簡單來說,你可以認為,在這里,pandas對“應用”完成后的每個小group的操作結果,做了一個concat,也就是軸向上的聚合,也就是從上到下把他們像“堆俄羅斯方塊”一樣堆起來(如果不熟悉pd.concat,先回去復習下吧~)
在pandas中,堆疊起來的資料要么是Series,要么是DataFrame,也就是說,無論中間對每個小group的操作操作有多復雜,最后回傳的結果無外乎就是Series和DataFrame,對于做資料處理的我們還是頗為友好的,
總結
總結一下,從抽象的“道”層面,在不涉及具體代碼的情況下,我們去理解groupby主要是通過“分拆-應用-聚合”三個環節,
在最開始使用groupby的時候,每次能夠先在腦海中將這三個環節模擬一遍,能夠幫助你更快速地掌握“術”層面的代碼語法;
在這三個環節中,最重要的是應用環節,而應用環節的關鍵在于,你要能清楚的感知到你要處理的一個個小的group是什么樣子的;其次是分拆環節,分拆環節是源頭,而且在實際應用的程序中還涉及到多種多樣的生成分組鍵的方式,對于初學者來說也很容易頭皮發麻;最后是聚合,像俄羅斯方塊一樣(準確的來說就是pd.concat)把每一個小group的結果堆起來,
理解篇就先到這里,咱們運用篇再見~~~
現在的想法是 現在的想法是 現在的想法是 現在的想法是 現在的想法是 現在的想法是
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/342101.html
標籤:其他
上一篇:KPM演算法-字符匹配
下一篇:Spring JDBC